3.55 million equivalent H100 chips this year flowing to the top five AI leaders
 12/03 2024
12/03 2024
 679
679

This article is compiled by Semiconductor Industry Insights (ID: ICVIEWS) from lesswrong
How many NVIDIA GPUs do the top five AI giants have in 2024?
It is difficult to accurately obtain data on AI infrastructure. Many reports mention things like "Company X spent Xbn on infrastructure this quarter," "Company Y purchased 100,000 H100s," or "Company Z owns a cluster of 100,000 H100s." However, when attempting to estimate the computing resources available to a particular company, consistent data is hard to come by.
Here, I attempt to gather information from various sources to roughly estimate two points: first, how much computing power is expected to be owned by each party as of 2024; second, what changes are anticipated for 2025. Subsequently, I will briefly discuss the implications of these estimates for the availability of training computations in leading-edge laboratories. Before diving into the discussion, I want to highlight a few points.
These numbers are my estimates based on publicly available data within a limited timeframe and may contain errors or omit important information.
Paid providers likely have more precise estimates. They can spend more time analyzing details such as the number of fabs, production content of each fab, data center locations, and the number of chips in each data center, resulting in much more accurate figures. For readers seeking highly precise estimates, I recommend purchasing relevant data from one of these providers.
NVIDIA Chip Production
Let's start with NVIDIA, the leading data center GPU manufacturer. As of November 21, after NVIDIA released its fiscal Q3 2025 earnings report, it is estimated that the company's data center revenue for the fiscal year will be approximately $110 billion. This represents an increase from $42 billion in 2023 and is projected to reach $173 billion in 2025 (based on an estimated $177 billion for fiscal year 2026).
Most of the data center revenue comes from chip sales. Chip sales are projected to reach 6.5 to 7 million GPUs in 2025, almost entirely Hopper and Blackwell models. Based on the expected ratio of CoWoS-S and CoWoS-L manufacturing processes and the anticipated mass production rate of Blackwell, I estimate that there will be 2 million Hopper and 5 million Blackwell chips.
2024 Production
There are few and often contradictory sources for 2024 production figures, but Hopper GPU production in Q4 2024 is estimated at 1.5 million units (though this includes some H20 chips, so it's an upper limit). Additionally, the ratio of data center revenue across quarters suggests a production cap of 5 million units (assuming a revenue of approximately $20,000 per H100 equivalent).
This conflicts with earlier estimates of 1.5 to 2 million H100s produced this year. Whether this discrepancy can be reasonably attributed to factors like the H100 vs. H200, scaling, or others is unclear. Since it doesn't align with their revenue figures, I've chosen to use the higher number.
Previous Production
To assess who currently and prospectively holds the most computing resources, pre-2023 data has a limited impact on the overall landscape. This is primarily due to the inherent performance improvements in GPUs and the significant growth in production volumes evident from NVIDIA's sales data. Estimates suggest that Microsoft and Meta each acquired around 150,000 H100 GPUs in 2023. Combined with NVIDIA's data center revenue, total production of H100 and equivalent products in 2023 was likely around 1 million units.
GPU/TPU Count by Organization
I attempt to estimate how many chips in H100 equivalents Microsoft, Meta, Google, Amazon, and XAI will have by the end of 2024 and the relevant numbers for 2025.
Many sources claim that "46% of NVIDIA's revenue comes from four customers," but this can be misleading. Reviewing NVIDIA's 10-Q and 10-K filings reveals that they distinguish between direct and indirect customers, with the 46% figure referring to direct customers. However, most direct customers are intermediaries like SMC, HPE, and Dell, who purchase GPUs and assemble servers for indirect customers, including public cloud providers, consumer internet companies, enterprises, public sectors, and startups. The companies I focus on fall under "indirect customers."
Information disclosure about indirect customers is relatively loose and may be unreliable. In fiscal year 2024 (roughly 2023, the context discussed here), NVIDIA's annual report disclosed that "an indirect customer who primarily purchases our products through system integrators and distributors accounts for an estimated approximately 19% of total revenue." As required, they disclose customer information with revenue shares exceeding 10%. Therefore, either their second-largest customer is at most half the size of the largest, or there is a measurement error. This largest customer could be Microsoft, with sporadic information suggesting that the second-largest customer briefly exceeded 10% quarterly, but this was not consistent and did not cover the entire year of 2023 or the first three quarters of 2024.
Estimating H100 Equivalent Chip Counts by End of 2024
Microsoft, Meta
Considering Microsoft is one of the largest public clouds and the primary computing provider for OpenAI, lacks the large-scale custom chip installations of Google and possibly Amazon, and seemingly has a special relationship with NVIDIA compared to peers (e.g., they apparently received Blackwell chips first), I speculate that the two largest customers are likely both Microsoft. NVIDIA's revenue share in 2024 is not as precise as in 2023, with mentions of 13% of H1 revenue in Q2 and Q3 and "over 10%" in Q3 only, but 13% serves as a reasonable estimate, indicating a decrease in Microsoft's share of NVIDIA sales compared to 2023.
Other estimates of customer sizes show Microsoft accounting for 15% of NVIDIA's revenue, followed by Meta Platforms at 13%, Amazon at 6%, and Google at around 6%, but the corresponding years for these data are difficult to ascertain from sources. Reports on the number of H100 chips owned by these cloud providers as of the end of 2023 (150,000 each for Meta and Microsoft, 50,000 each for Amazon, Google, and Oracle) align more closely with the above data.
A key data point is Meta's claim that it will have 600,000 H100-equivalent computing power by the end of 2024. This reportedly includes 350,000 H100s, with the rest likely being H200s and a small number of Blackwell chips arriving last quarter.
If we take this 600,000 as accurate and scale based on revenue figures, we can estimate Microsoft's available computing power to be 25% to 50% higher, or 750,000 to 900,000 H100 equivalents.
Google, Amazon
I note that Amazon and Google are often perceived as being lower in their contribution to NVIDIA's revenue. However, their situations are entirely different.
Google already has a significant number of custom TPUs, which are the primary chips relied upon for its internal workloads. For Amazon, its internal AI workloads appear to be much smaller than Google's, and the substantial number of NVIDIA chips it owns are primarily to meet external GPU demands through its cloud platform, most notably from Anthropic.
Starting with Google. As mentioned, TPUs are its primary chips for internal workloads. Semianalysis, a leading subscription service providing data in this field, claimed at the end of 2023 that "Google is the only company with a strong internal chip," "Google has a nearly unparalleled ability to reliably deploy AI at scale with low cost and high performance," and called it "the company with the richest computing resources in the world." Google's infrastructure spending has remained high since these claims.
I estimate a 2:1 spend ratio for TPUs to GPUs (perhaps a conservative estimate), assuming each dollar of TPU performance is equivalent to Microsoft's GPU spend, resulting in a range of 100,000 to 1.5 million H100 equivalents by the end of 2024.
While Amazon has its custom chips Trainium and Inferentia, they started much later than Google's TPUs and seem to lag behind the cutting edge in their development. Amazon even offered $110 million in free credits to attract trial users, suggesting its chips haven't adapted well so far. Semianalysis noted, "Our data shows that Microsoft and Google's 2024 AI infrastructure spending plans will enable them to deploy far more computing power than Amazon," and "Moreover, Amazon's upcoming internal chips Athena and Trainium2 are still significantly behind."
However, by mid-2024, the situation may have changed. During the Q3 2024 earnings call, Amazon CEO Andy Jassy mentioned Trainium2, stating, "We've seen strong interest in these chips, and we've communicated with manufacturing partners multiple times, with production far exceeding initial plans." But since they "only started ramping up production in the following weeks," large-scale availability in 2024 seemed unlikely.
XAI
The final significant player I introduce here is XAI. It has grown rapidly, owns some of the largest clusters in the field, and has ambitious development plans. It revealed a cluster with 100,000 H100s in operation by the end of 2024, but there seem to be issues with providing sufficient power to the site.
Blackwell Chip Predictions for 2025
I noticed the 2024 AI State of the Art Report's estimates of Blackwell purchases by major vendors, mentioning that "large cloud companies are buying these GB200 systems in large quantities: Microsoft between 700,000 and 1.4 million, Google at 400,000, and AWS at 360,000. Rumors say OpenAI has at least 400,000 GB200s." Since these numbers are total chip counts, there's a risk of double-counting Blackwell purchases in 2024, so I applied a 15% discount.
Based on Microsoft's estimates, Google and AWS purchasing around 1 million NVIDIA chips aligns with their typical proportions relative to Microsoft. This would also put Microsoft's share of NVIDIA's total revenue at 12%, consistent with its slight decline in NVIDIA revenue share in 2024.
Meta wasn't given any estimates in this report, but it expects "significant acceleration" in AI-related infrastructure spending next year, implying its share of NVIDIA spending will remain high. I assume Meta's spending will be about 80% of Microsoft's by 2025.
For XAI, not mentioned in the chip-related content, Elon Musk claimed they would have a 300,000 Blackwell cluster by summer 2025. Considering Musk's occasional exaggerations, XAI seems likely to have 200,000 to 400,000 such chips by the end of 2025.
What is the H100 value of a B200? This is a crucial question for measuring capacity growth. The numbers cited for training and inference differ, with the best estimate currently (November 2024) for training being 2.2 times.
For Google, I assume NVIDIA chips continue to account for one-third of its total marginal computing. For Amazon, I assume 75%. These figures have significant uncertainties, and estimates are sensitive to them.
Notably, many H100s and GB200s are unaccounted for and may cluster significantly elsewhere, especially below NVIDIA's 10% reporting threshold. Cloud service providers like Oracle and others may hold them.
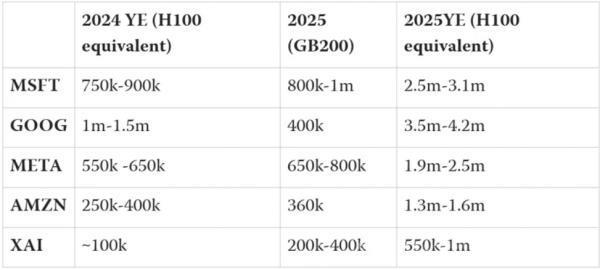
Summary of Chip Count Estimates
Model Training Considerations
The numbers I mention here are estimates of the total available computing power. However, many may be more interested in the portion used for training the latest cutting-edge models. Next, I will focus on OpenAI, Google, Anthropic, Meta, and XAI. It's important to note that everything here is speculative since these companies are either private or so large that they don't need to disclose such cost details. For Google, this is just a small part of its business.
OpenAI's training costs in 2024 are estimated at $3 billion, with inference costs at $4 billion. According to a source, Anthropic "expects to lose about $2 billion this year with revenues in the hundreds of millions." This means Anthropic's total computing costs are $2 billion more than OpenAI's $7 billion. Since Anthropic's revenue primarily comes from APIs and should have a positive gross margin, its inference costs will be significantly lower, implying that most of the additional $2 billion is for training, around $1.5 billion. Even with two disadvantages in training costs compared to OpenAI, this doesn't seem to hinder Anthropic's competitiveness. This seems plausible since Anthropic's primary cloud provider is AWS, which, as we know, typically has fewer resources than Microsoft, which provides computing resources to OpenAI. The previously mentioned AI State Report rumored that Microsoft would provide 400,000 GB 200 chips to OpenAI, exceeding AWS's rumored entire GB 200 capacity, potentially making OpenAI's training capability much higher than Anthropic's.
The author finds that the situation at Google is not entirely clear. The training computation of the Gemini Super 1.0 model is approximately 2.5 times that of GPT-4, but nine months after its release, it is only 25% more than the latest Llama model. As we understand, Google may have more available computing power than its peers. However, being both a major cloud provider and a large enterprise, it also has more internal demands. Google's computing capacity is stronger than that of Anthropic or OpenAI, and even stronger than Meta, considering that Meta also has numerous internal workflows independent of cutting-edge model training, such as recommendation algorithms for social media products. Llama 3 is computationally smaller than Gemini, even though it was launched eight months after Gemini, indicating that Meta has allocated slightly fewer resources to these models compared to OpenAI or Google.
Turning to XAI, it is reported to have used 20,000 H100 GPUs to train Grok 2 and anticipates using up to 100,000 H100 GPUs for Grok 3. Given that GPT-4 is reported to have been trained on 25,000 NVIDIA A100 GPUs for 90-100 days, and the performance of H100 is approximately 2.25 times that of A100, the computational demand for Grok 2 will be twice that of GPT-4, with Grok 3 anticipated to increase by another five times, bringing it close to industry-leading levels.
It's important to note that not all of XAI's computing resources come from their own chips; it is estimated that they have rented 16,000 H100 GPUs from Oracle Cloud. If XAI can allocate a portion of its computing resources to training similarly to OpenAI or Anthropic, the author speculates that its training scale might be comparable to Anthropic, slightly lower than OpenAI and Google.
*Disclaimer: This article is originally created by the author. The content represents their personal views, and our republication is solely for sharing and discussion purposes. We do not necessarily endorse or agree with the views expressed. For any objections, please contact our backend support.
-
![]()
139 Institutions Conduct Research as Robotec Promptly Secures a Major Order Worth 129 Million Yuan!
-
![]()
Zeiss Boosts Investment to Expand 25,000-sqm Optical Plant, Elevating Its Exclusive EUV Optical Manufacturing Capabilities!
-
![]()
SAIC’s Four Key Divisions See Leadership Overhaul: Lu Xiao Moves to Passenger Cars, Xu Ping Takes Charge of GM, Wu Yun Leads Volkswagen
-
![]()
Nearly a Year On, Traffickers Still Reap Tens of Thousands by Selling Zeekr 9X in Russia
-
![]()
Apple’s New Business Model: Pay $39 a Month, But at What Cost to Your Wallet?
-
![]()
Tencent Places Its Bets on WorkBuddy: The Next Frontier in AI-Driven Office Solutions, Vying for the Smart Gateway
-
![]()
Apple Reclaims Global Market Cap Crown: Is a Strong Device the True Path for AI?
-
![]()
Apple Regains Global Market Cap Leadership: Are Smart Devices the Future of AI?