ChatGPT o1 full-featured version is launched! Surprisingly, it lost to domestic AI in practical tests?
 12/09 2024
12/09 2024
 870
870
On December 5 local time, OpenAI officially launched two new AI models, ChatGPT's o1 and o1-Pro. The o1 model was actually already used by many before, but it was called o1-preview back then, and only some functions of the o1 model were available. Now that the "preview" tag has been removed, it means the full-featured version of the o1 model has finally been officially launched.
Source: Lei Technology
From simple tests, the full-featured version of the o1 model now supports image and file uploads, whereas before, only text input was allowed, which means multimodal understanding has been added. However, the web search function is still not available, which is somewhat disappointing.
Regarding the improvements of the full-featured o1 version, OpenAI's CEO Altman presented a comparison using a simple bar chart: It can be seen that o1 performs significantly better than o1-preview in the fields of mathematical reasoning and programming, with an improvement of around 50%. However, in scientific research tests, the performance of o1 compared to o1-preview shows limited improvement.
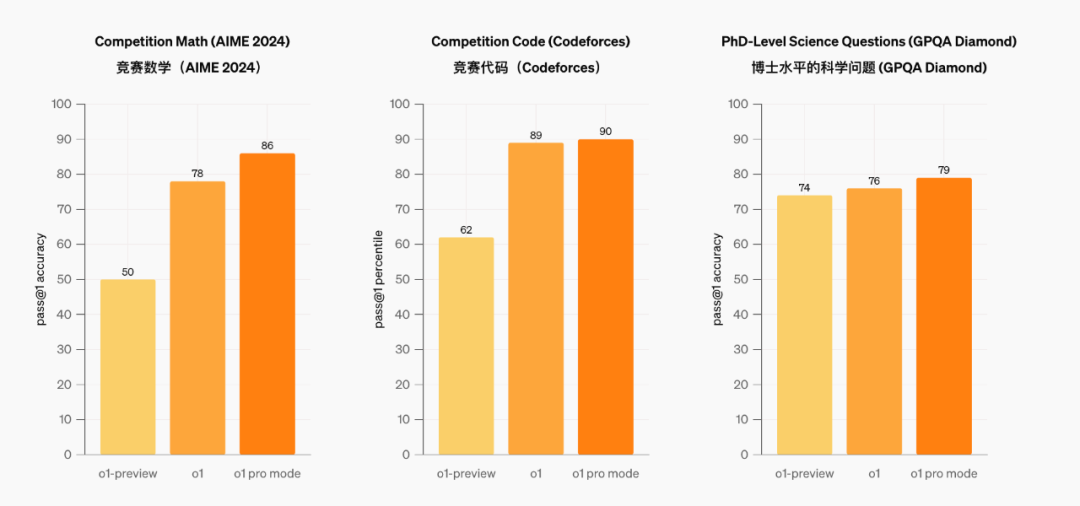
Source: OpenAI
Considering that the o1 model can be used without additional cost, it is still a great deal for users in need. However, OpenAI's true intention is not just the free upgrade to o1; the all-new o1-pro is the main event. To use o1-pro, however, users must subscribe to the new $200 package, which is currently the most expensive subscription option in the AI field for individual users.
From the performance comparison chart provided by OpenAI, it can be seen that o1-pro does show some improvement over o1, but the margin of improvement is not significant. For ordinary users, the o1 model is fully capable of meeting daily needs, and there is no need to subscribe to the $200 package for o1-pro.
Of course, the $200 package offers more than just o1-pro; it also includes unlimited access to the o1 model and advanced voice functions (o1-pro is not included, and there is likely still a usage limit). If you find the question quota for o1 insufficient, the $200 package is the only option for individual users.
Since new models have been launched, testing them is a must. Lei Technology's test this time mainly focused on the multimodal capabilities of the full-featured o1 version, and two domestic AIs, kimi and ERNIE Bot, were also invited to participate as friends.
The full-featured o1 version is not "invincible" in practical tests
The o1 model excels in advanced reasoning in mathematics and other fields, so let's start with its strengths. Here is a relatively easy math problem:
Assume a company produces a certain commodity, and the relationship between production cost and output is C(x) = 3x^2 - 2x + 5 (in ten thousand yuan), where x is the output (in thousands of units). The market price and output relationship is P(x) = 50 - 0.5x (in ten thousand yuan per thousand units). 1. Find the total profit function L(x) for the company when producing x thousand units of the commodity. 2. Determine how many thousand units the company should produce to achieve maximum profit and calculate the maximum profit.
First, let's look at the answers from domestic AIs:

kimi

ERNIE Bot
Both domestic AIs gave the same answer: 1.8814 million yuan. Now let's see ChatGPT-o1's answer.

o1
The answer given by the o1 model is also 1.8814 million yuan, which is consistent with the standard answer to the problem. All three AIs passed the test. However, from the screenshots of their answers, one can see the differences. The o1 model shows a lot of calculation processes, making it easier for users to check the correctness of the reasoning.
This is also related to the primary use of the o1 model, which is essentially designed for scientific research and other purposes. Therefore, when presenting answers, it places more emphasis on the reasoning process and correctness rather than just outputting the correct answer.
Next, let's try asking questions directly with images, allowing us to input some more abstract math problems, such as this Olympiad problem from fourth grade:
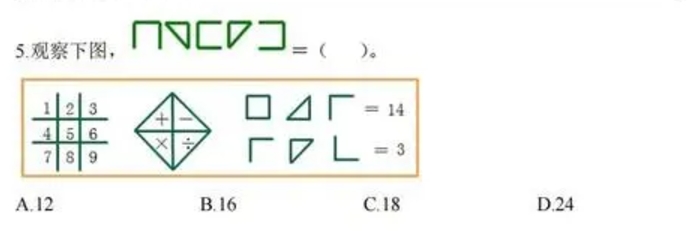
As usual, let's first look at the answers from domestic AIs:
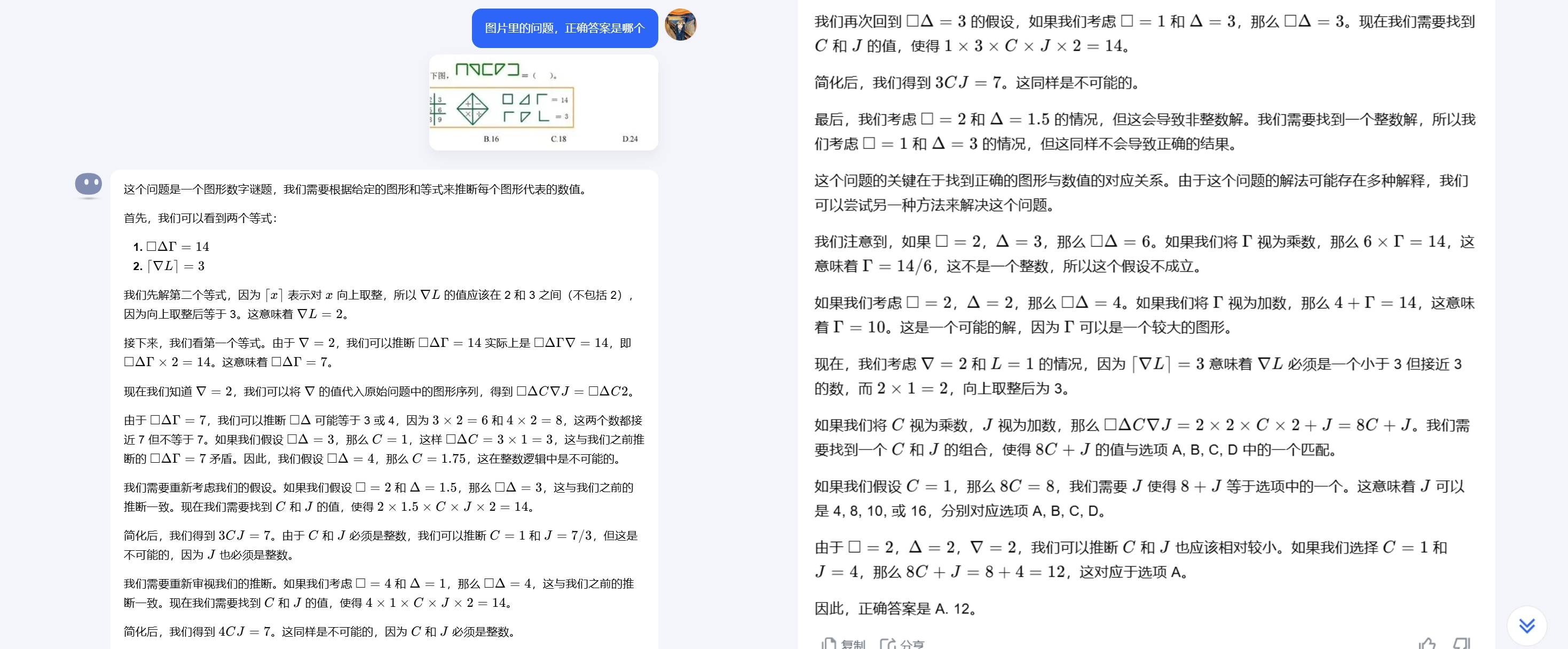
kimi
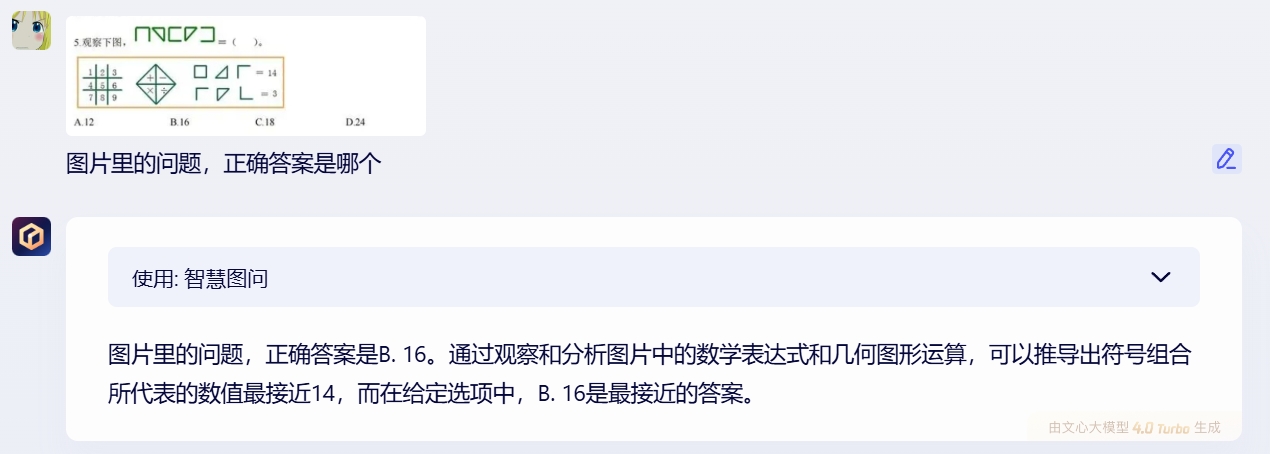
ERNIE Bot
The two domestic AIs gave options A and B, respectively. Kimi's reasoning process is very long, directly analyzing this elementary school Olympiad problem using advanced mathematics.
Now let's see the answer from the o1 model:

o1
The answer given by the o1 model is also B. Does this mean kimi got it wrong? The answer is no; the correct answer to this problem is actually A. In other words, both o1 and ERNIE Bot got it wrong. Since ERNIE Bot did not provide a detailed reasoning process, it is unclear where the error occurred. The o1 model apparently misjudged the number of sets in the image during analysis, ultimately leading to an incorrect answer through reasoning.
In this problem, we can see that large AI models have different approaches to solving similar graphical problems. Both ERNIE Bot and o1 attempt to directly find the pattern in the image to calculate the answer, similar to how humans solve problems. In contrast, kimi directly converts the graphical equation into an algebraic equation for calculation.
In terms of efficiency, the reasoning methods of o1 and ERNIE Bot certainly save computing power. However, if the analytical and breakdown capabilities are not up to par, incorrect answers may result, as in this case. Although kimi's reasoning process consumes more computing power, it ensures the accuracy of the answer.
From a business perspective, adopting a graphical reasoning solution is naturally the best choice to improve reasoning efficiency and reduce costs. However, considering the advanced model attributes of o1 and OpenAI's positioning of it as a research assistant, giving incorrect answers to save computing power may be difficult to justify to users.
Next, let's look at performance in programming. The problem is not difficult:
I want to create a software that checks the computer's network connection status every hour. If the connection is interrupted, it should restart the computer; if the connection is normal, it should maintain the status quo.
Both domestic AIs quickly provided answers:
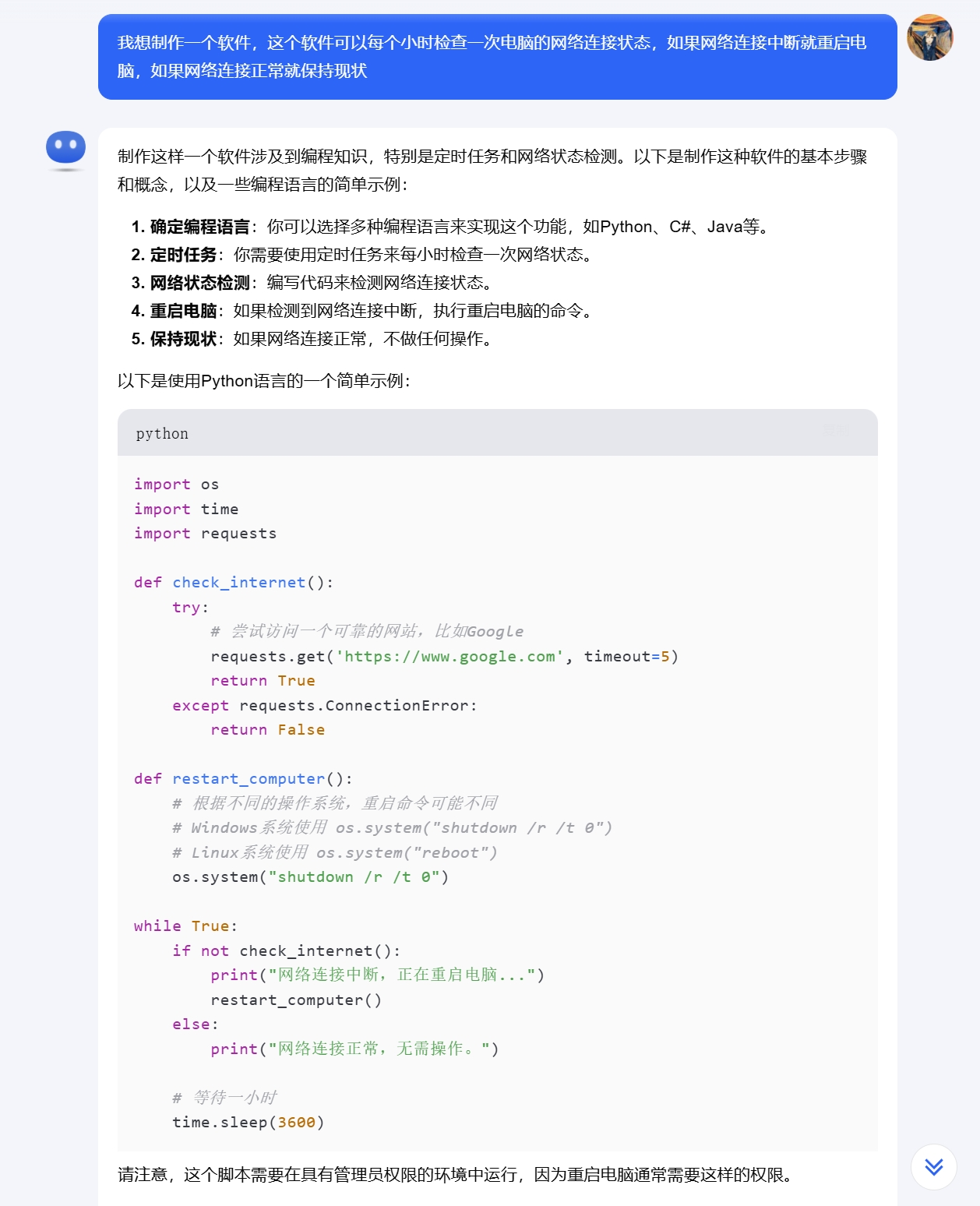
kimi
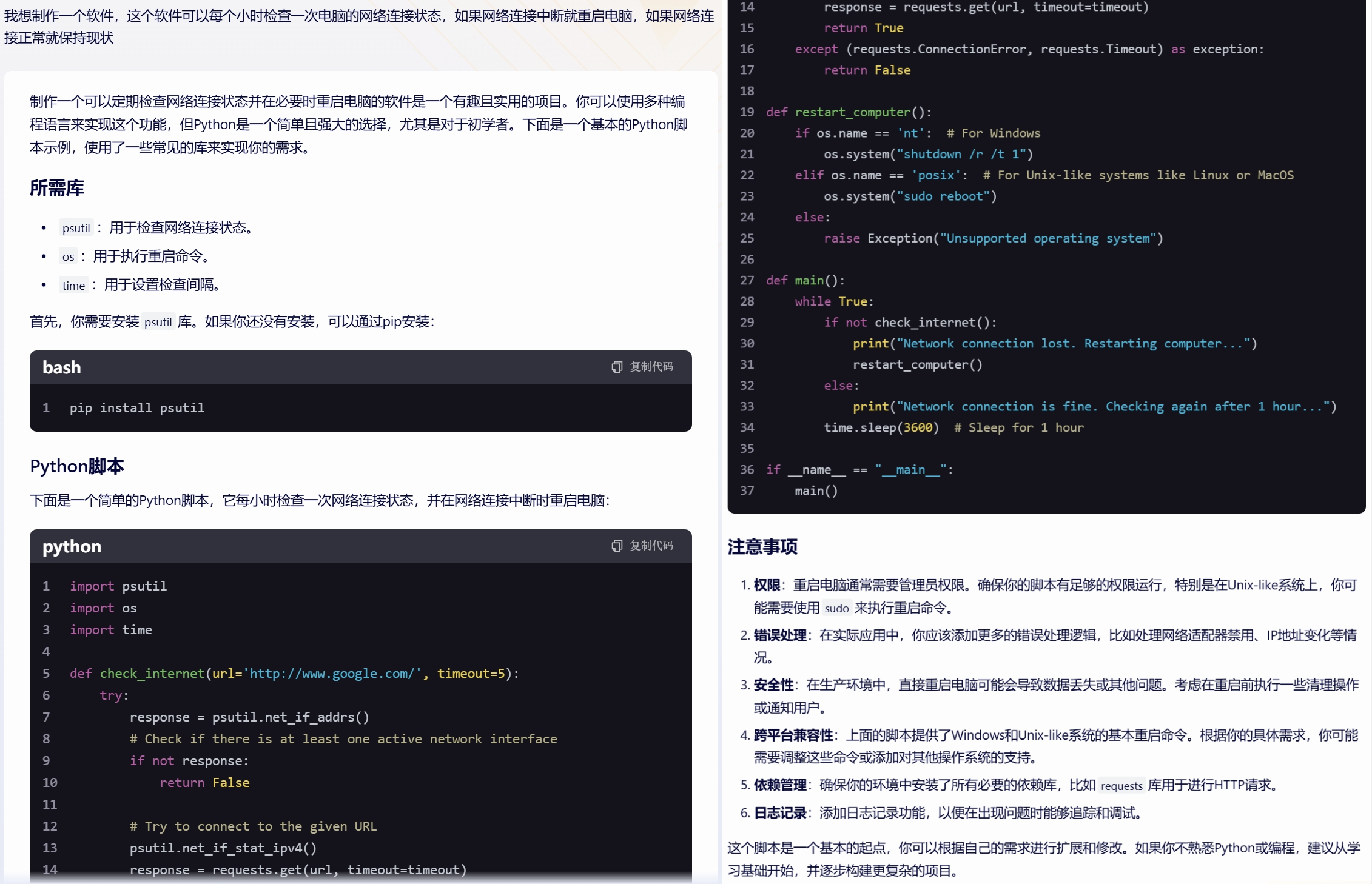
ERNIE Bot
Since the requirements are simple, simple tests showed successful operation in virtual machines. However, there are some differences in the answers from the two domestic AIs. Kimi includes comments in gray font in the code, while ERNIE Bot provides additional reminders and installation instructions for the runtime library, along with more programming suggestions.
What about the o1 model? The answer is as follows:

o1
From the o1 model's answer, it completes the response in three parts: first, it presents the implementation idea; then, it provides sample code with comments; finally, it analyzes the code writing process and provides testing ideas and alternative solutions. This combines the advantages of both AIs and may offer a better experience for beginners.
From a productivity perspective, the o1 model does excel in specific areas, but domestic AIs also perform well. In particular, kimi is impressive, being the only AI to answer all test questions correctly.
The testing could have ended here, but I wanted to see how the o1 model differs from ordinary models in daily scenarios.
Therefore, I added an extra question, searching for a photo of a strawberry pie online and asking the AIs how to make the dessert in the photo.
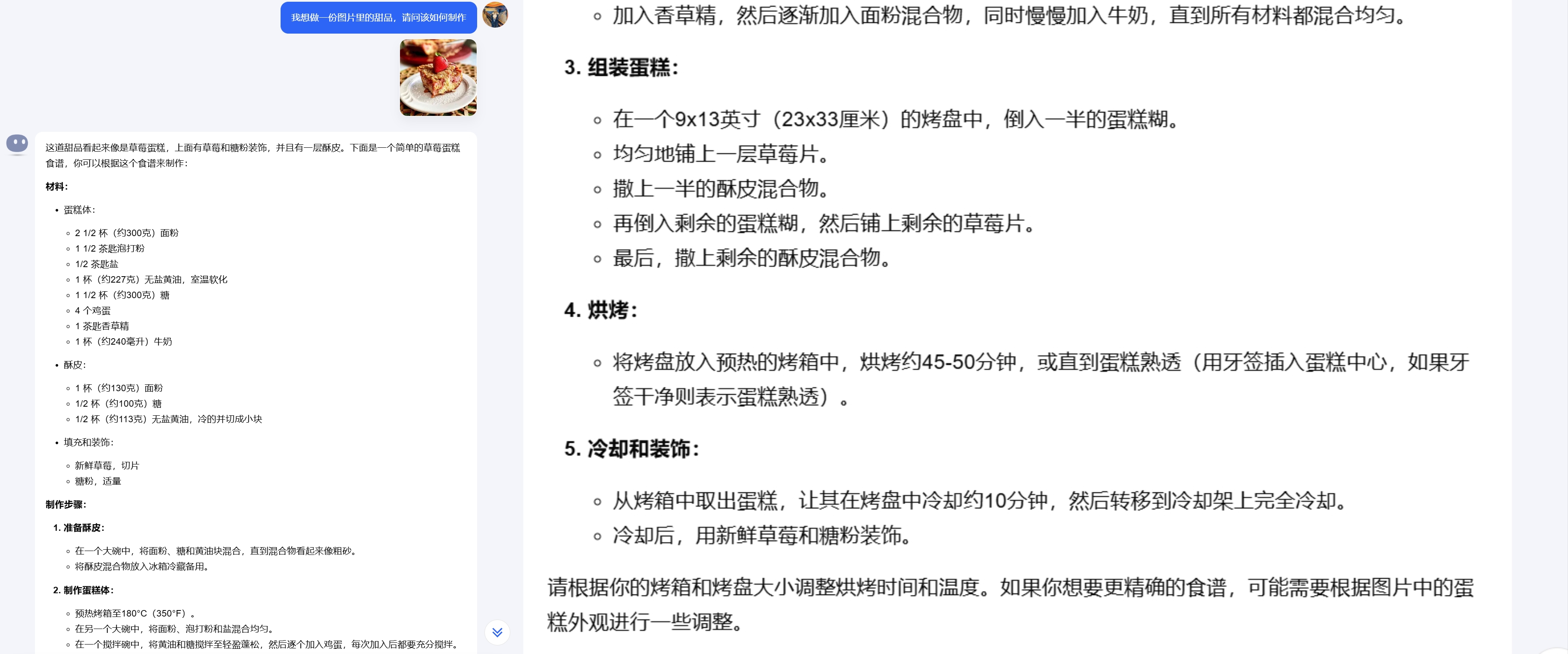
kimi
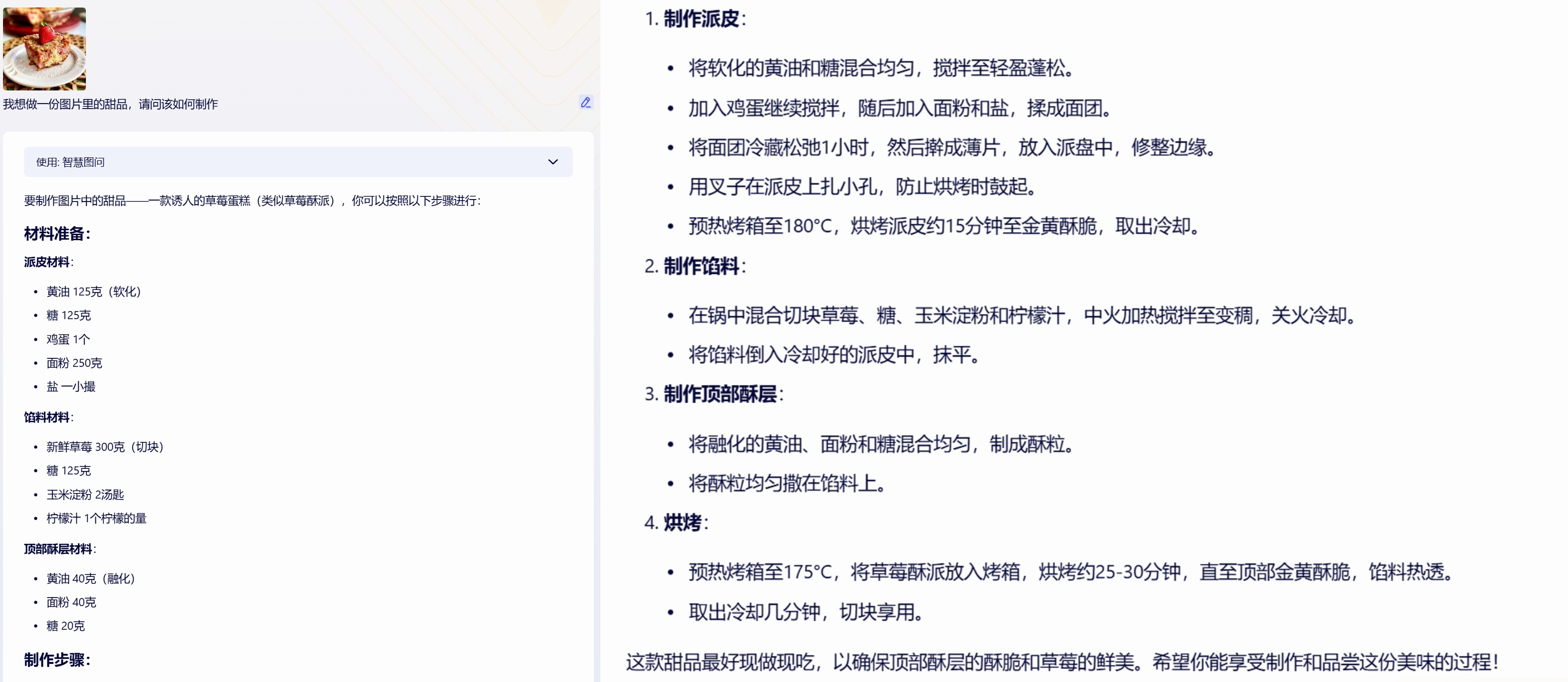
ERNIE Bot

o1
All three AIs easily identified the type of dessert and provided similar recipes. However, the o1 model's answer includes detailed instructions for each step and precautions, while the steps described by domestic AIs are much simpler. For someone with some baking experience, the recipes from domestic AIs are sufficient, but for a beginner, the recipe from the o1 model will likely have a much higher success rate.
The next step for AI is to truly "think"
Overall, the o1 model does have obvious advantages in terms of the detailedness of its answers. The experience is much better in scenarios that require viewing the reasoning process or obtaining more detailed answers. However, in terms of answer accuracy, o1 does not have much of an advantage over current domestic AIs and even performs worse than kimi.
Moreover, domestic AIs can also obtain more detailed answers and reasoning processes through follow-up questions. The o1 model does not have obvious advantages in most scenarios. For example, in my daily use of ChatGPT, ChatGPT-4 is often sufficient, and I only use the o1 model in rare cases.
As a long-time user of ChatGPT, I believe the o1 model is more suitable for professionals such as researchers and financial analysts who use a lot of mathematical tools and conduct multiple reasonings in their daily work. At this time, the multi-step reasoning process of the o1 model, which has undergone targeted training, performs much better than ordinary AIs in solving these problems.
As for o1-pro, based on the test results of other users that I have researched, there is not much difference in answer quality between it and the o1 model. The main difference lies in that o1-pro can call upon more computing power to repeatedly verify the correctness of answers and attempt to provide a more detailed reasoning process.
In fact, as large AI models have developed to this stage, there are signs of segmentation emerging. Previously, many AI companies hoped to create a comprehensive multimodal model but found the cost to be high and the results not very good, with issues like "hallucinations" remaining difficult to resolve.
ChatGPT-o1 undoubtedly provides another solution. When computing power is sufficient, AI can first conduct an in-depth "thought" on the problem and then perform calculations based on the results of that thought. You can understand it this way: o1 first tries to analyze the problem itself and then solves it based on the analysis results, while ordinary AIs directly disassemble the problem's keywords, call corresponding data based on algorithms, and combine them into an answer. Although this method responds quickly, it is difficult to ensure the accuracy of the answer, especially for complex problems.
Therefore, we can see that kimi and ERNIE Bot are also trying to make AI learn to "think" in different ways rather than forcibly combining answers based on algorithms and data. Kimi's performance particularly impressed me, as it was the only one to answer all math test questions correctly and can be used without cost, offering great value for money and experience.
Honestly, if it weren't for the convenience of searching for foreign language materials and staying updated on the cutting edge of AI, the $20 subscription to ChatGPT would not offer good value for money. The free kimi and the versatile ERNIE Bot, which provides multiple agents and official tools, are more cost-effective options.
-
![]()
Cybercab Rolls Off the Line: Is Tesla's Robotaxi a Bubble or the Next Trillion-Dollar Story?
-
![]()
Switch Revolution in the Era of AI Super Nodes
-
![]()
Will the Upcoming Kimi Replicate MiniMax's Trend?
-
![]()
BYD at the Crossroads of Scale and Profitability
-
![]()
Is It Down to a Daily Payment of Just 29 Yuan?!
-
Observing the Fate of Joint Venture Automakers from Skoda's Exit from China
-
![]()
Doubao Boosts Sales, Qianwen Streamlines Mobile Recharges: Large Models Step into the 'Era of Practical Deployment'
-
![]()
Pony.ai Explains Robotaxi 'Profit Replication Strategy': How to Scale from a Vehicle Earning RMB 338 Daily to 20 Cities?