Exploring Xiaomi's End-to-End Approach to Modeling the Physical World for Autonomous Driving
 03/26 2025
03/26 2025
 767
767
Xiaomi's intelligent driving technology has emerged as one of the fastest-growing segments in China's smart car industry, mirroring its impressive sales performance. From its inception in 2021 to the launch of the Xiaomi Su 7 with highway pilot features on March 28, 2024, Xiaomi continued to innovate, introducing its urban pilot in September of the same year and commencing internal testing of valet parking intelligent driving by 2025. Despite its current status, Xiaomi's rapid advancement in intelligent driving capabilities is undeniable.
At the recent GTC 2025 conference, Yang Kuiyuan from Xiaomi's Autonomous Driving and Robotics Department revealed that Xiaomi had achieved significant progress in intelligent driving in 2024, evolving from a high-precision map-based modular architecture to a non-high-precision map modular architecture, and ultimately to an end-to-end architecture. He further elaborated on Xiaomi's practices in end-to-end technologies. Drawing from Yang Kuiyuan's speech, this article delves into how the physical world is modeled in end-to-end algorithms and discusses the current stages in intelligent driving end-to-end systems.
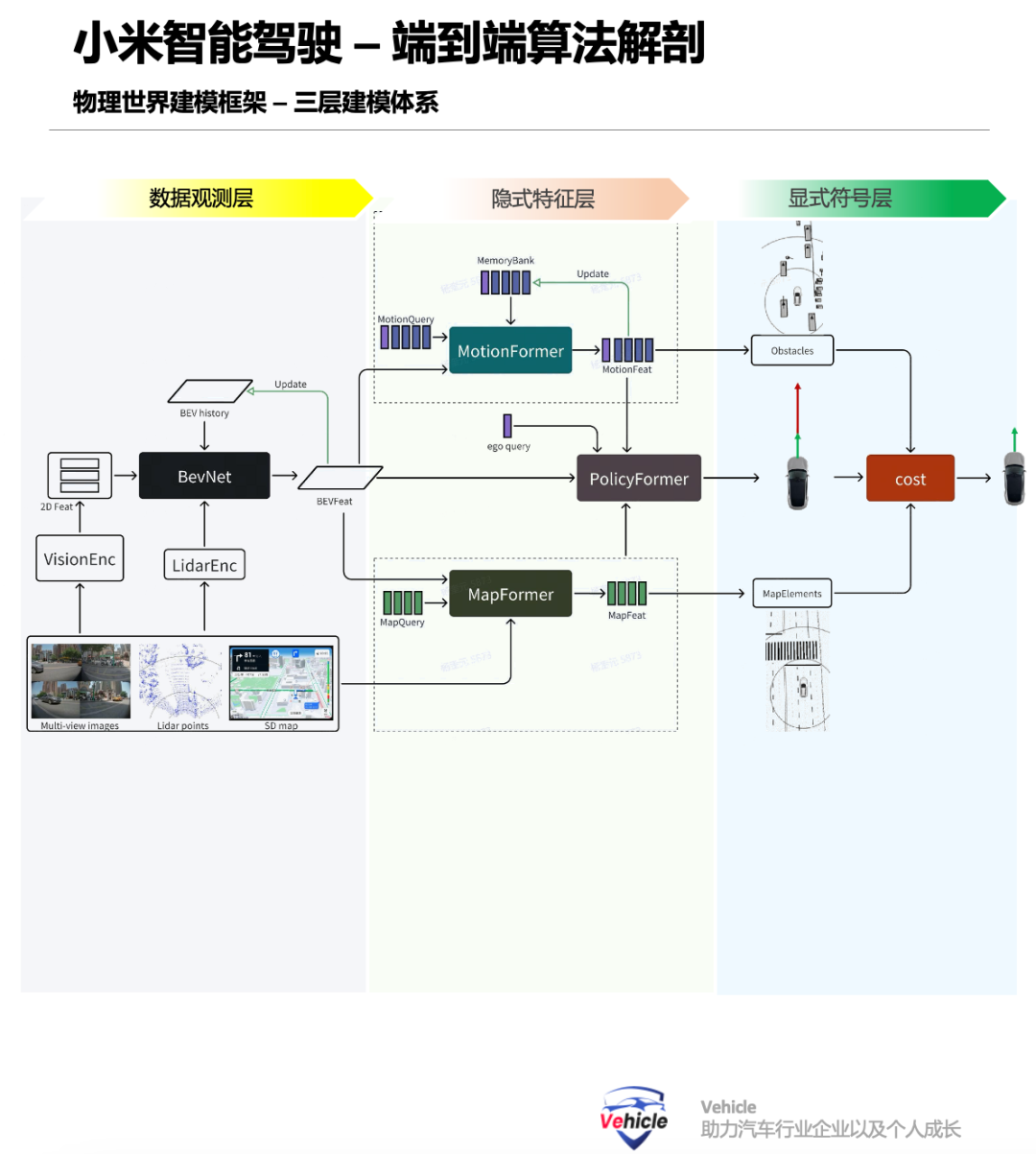
The 'Three-Tier Modeling' architecture for the physical world model comprises three layers: the data observation layer (Ot), the implicit feature layer (Zt), and the explicit symbol layer (St). The data observation layer serves as the input layer of the neural network, receiving sensor inputs such as images, LiDAR point clouds, and navigation information essential for pilot functions. The implicit feature layer processes this input to obtain implicit feature representations through a BEV encoding network, which can then be decoded into dynamic elements, other traffic participants, static elements like road signs, facilities, and obstacles, and the future trajectory of the ego vehicle using various decoders. The explicit symbol layer decodes the model into explicit symbol representations for human understanding and integration with predefined rules and codes, such as static lane lines, zebra crossings, dynamic pedestrians, and vehicles.

This 'Three-Tier Modeling' facilitates understanding of the current scene for future decision-making and planning. However, it represents a coarse-grained division, and each layer can be further refined. For instance, multi-layer resolution images in an image pyramid or different hidden layers in a deep neural network can be utilized. Ultimately, the vehicle's output trajectory is decoded and generated after comprehensively considering dynamic and static information, constrained by artificially designed costs like collision costs with other obstacles, deviation costs from lane lines, and comfort costs based on longitudinal and lateral jerk.
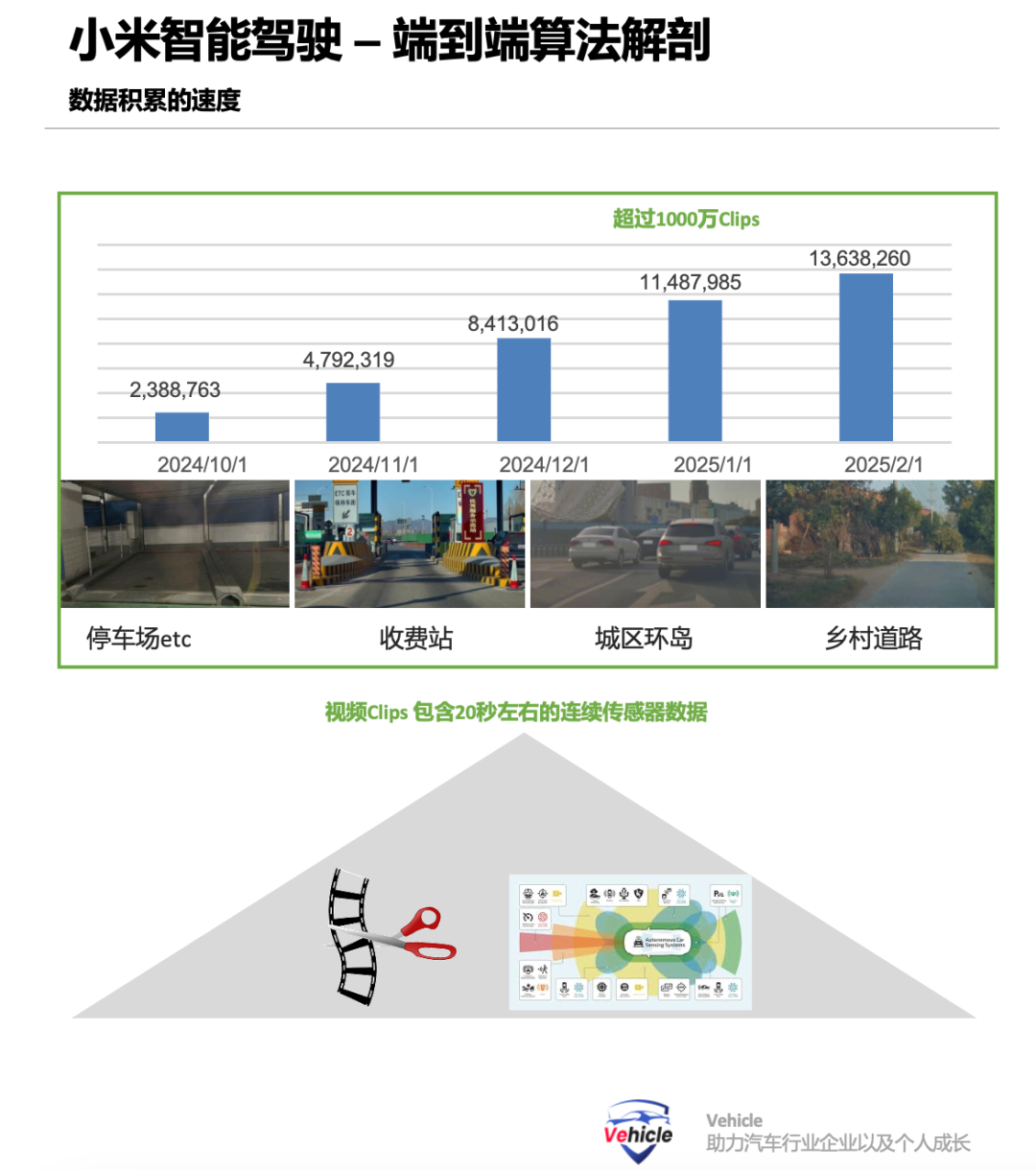
The training of the entire neural network is governed by the loss curvature of the final layer, encompassing discrepancies between static and dynamic elements and ground truth, deviations between the ego vehicle's trajectory and a reference trajectory, and multiple artificially designed costs. The modeling method for the physical world model sets the model architecture, establishing a data-driven pathway that enables the model to automatically output true and required conclusions, forming a data-driven loop. For the multi-stage end-to-end data observation layer where each tier is modeled separately, typical inputs are video clips. However, generated data training is necessary for corner cases or long-tail scenarios, along with closed-loop simulation evaluation for perception loop creation. Currently, advanced AI technologies such as 3DGS reconstruction and diffusion auto-regression generation can be leveraged, with tools like OpenAI's Sara, DeepMind's Journey, and NVIDIA's Cosmos being prominent visual generation models.
By fitting the probability distribution of raw data and utilizing control conditions like counterclockwise image privacy features and explicit symbols, raw signal generation can be achieved. These models currently generate data relatively slowly, primarily in cloud simulations of the physical world. They typically employ implicit features but focus on recovering sensor detail signals, with suboptimal performance in understanding tasks. Therefore, recent research has explored implicit feature spaces suitable for both generation and understanding. In the field of intelligent driving, there is no mature base model for the implicit feature layer that can generate stable feature representations.
The explicit symbol layer, akin to natural language expression, allows direct human coding and manipulation. By integrating rule-based codes and models, such as kinematic models (e.g., constant velocity, constant acceleration) commonly used in mutual assistance, and trajectory sampling, search, and optimization methods prevalent in rule-based control, continuous modeling can be achieved. In the end-to-end paradigm, the explicit symbol layer can also define costs corresponding to rewards in reinforcement learning-driven policy learning. Additionally, inspired by the scaling law of large models, works like State Transformer by Professor Zhao Hang of Tsinghua University in collaboration with Li Auto, and Apple's self-play (despite previous rumors of abandonment, Apple continues to pursue autonomous driving) have verified the effectiveness of scaling law for autonomous driving tasks by increasing data volume at the explicit symbol layer.
For the one-stage end-to-end approach where the three layers are jointly and continuously modeled, during cloud-based model training, inputting future frame data from recorded vehicle sensors provides self-supervised signals for model training. Extending the intermediate implicit feature layer to future frames along the temporal dimension forms a comprehensive spatio-temporal neural network model learned uniformly and data-driven, combined with the explicit symbol layer model, to form a one-stage model. However, due to the differing temporal changes of dynamic and static elements in the autonomous driving environment—static elements change primarily in relation to the ego vehicle's motion, while dynamic elements' changes are determined by their own and the ego vehicle's motions—it is speculated that this one-stage, three-tier joint modeling may result in separate models for dynamic and static objects. The above is a theoretical modeling summary, but actual engineering implementation is more intricate, necessitating considerations like computing platform optimization and model simplification. Therefore, Yang Kuiyuan also shared engineering practices such as cloud training acceleration and NVIDIA platform optimization (Inference Pipeline reconstruction increasing utilization by 100%, CV library optimization boosting GPU utilization by 30%), model architecture simplification leveraging data sparsity and 2D-3D geometric relationships, vehicle-end deployment optimization and heterogeneous computing (migrating image preprocessing to Vic SP/NV Encode units), operator acceleration optimizing time-consuming operators by 20-40% and doubling performance on the Orin platform, among other practices. Finally, the above is speculative based on Xiaomi's Yang Kuiyuan's speech on one-stage and multi-stage end-to-end systems, and there may be errors. Expert comments and discussions are welcome. Unauthorized reproduction and excerpts are strictly prohibited. - Reference Material: End-to-End Full-Scenario Intelligent Driving - Xiaomi, Yang Kuiyuan, GTC 2025 Speech PDF
-
![]()
How do Autonomous Driving Physical AI and End-to-End Systems Work Together?
-
![]()
June's New Energy Vehicle Sales Rankings Unveiled! Leapmotor Surpasses Tesla in a Stunning Comeback, Marking the Start of the Automakers' Knockout Phase
-
![]()
Global Agents Embrace 'Loop Engineering': AI's Self-Sufficient Work, Supervision, and Revision
-
Post-90s Straight-A CEO Propels Jihao Technology Toward IPO, Despite Over 90% Revenue Reliance on Smartphones
-
AI 'Dissolves' Visual China's Copyright Moat—What Story Can It Tell to List in Hong Kong?
-
![]()
The AI Industry Chain: A Tale of Fire and Ice - Upstream Thrives, Downstream Struggles
-
![]()
Masayoshi Son Confronts Elon Musk: The Essence of the Space Computing Power Battle is a Clash of Two Business Mindsets
-
![]()
Market Value Exceeds Trillion, 'Pouring Cold Water' on Itself: Cambricon Loses Over 140 Billion Yuan in Two Days