On the Eve of DeepSeek-V4's Release, A 'Key Step' Forward Paves the Way for Accelerated Agent Performance
 03/02 2026
03/02 2026
 475
475
DeepSeek has made another move.
However, this release is still not the long-awaited DeepSeek-V4.
But that doesn't stop it from being a major debut—DeepSeek, in collaboration with Tsinghua University and Peking University, has jointly launched a brand-new inference system called DualPath.

More importantly, this system is not designed for conventional dialogue. Instead, it targets the core challenges in today's more complex and popular agent scenarios.
By restructuring data loading, DualPath significantly boosts GPU utilization, enabling agents to operate more smoothly and practically in real-world scenarios with long contexts and multi-round interactions.
As a technical achievement jointly released by three top institutions, the paper is naturally filled with professional jargon that can be overwhelming.
But don't worry—this article avoids the technical slang and explains things in plain language. Let’s break down what DualPath is and why it's so powerful.
01
Agent Inference: Compute Power Takes a Backseat
You may have noticed that the AI landscape has shifted—from 'large models' to 'agents.'
In the past, interacting with large models was simple: you input a prompt, the model processed it for a few rounds, and then gave you an answer.
In the age of agents, things get more complicated. The parties involved are no longer just 'human' and 'machine,' but also 'machine' and 'machine.' The model must not only understand your words but also call up a browser, open a code interpreter, and interact with the external environment. The number of interactions has skyrocketed from a few to dozens or even hundreds.
In this process, the input-output generated by each tool call in an agent is quite short—perhaps just a few hundred tokens. The problem, however, is that as interaction rounds increase, the context grows like a snowball, eventually piling up into a massive block of hundreds of thousands of tokens.
In other words, agent tasks exhibit a unique characteristic: multi-round, long-context, and short-append.
The direct consequence of this pattern is that the hit rate of KV-Cache often exceeds 95%.
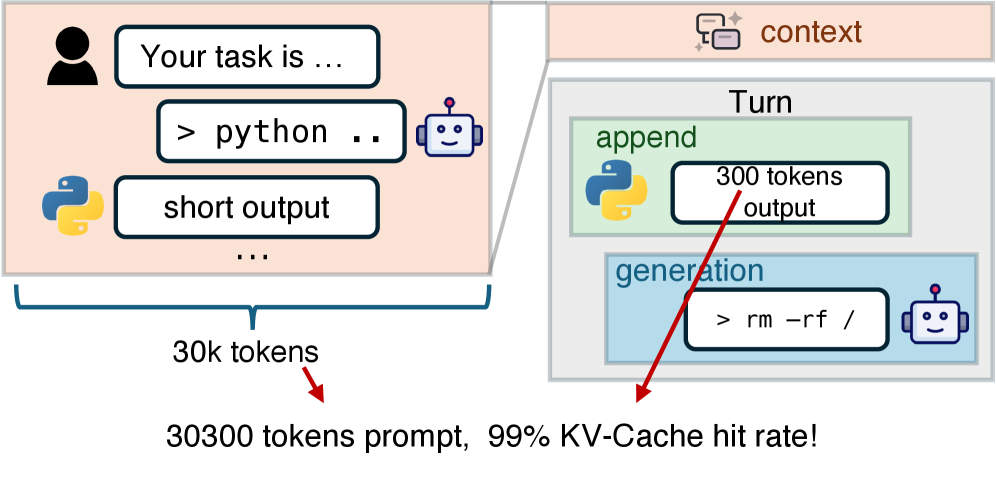
What is KV-Cache? A TV series analogy makes it clear:
Imagine the inference process of a large model is like watching a TV series that’s just updated to Episode 20.
Episode 20 is composed of the plot background from the first 19 episodes (the context) plus the new plot of Episode 20 (the new input).
Without KV-Cache, it’s like having amnesia—every time you watch a new episode, you have to rewatch all the previous 19 episodes from start to finish to understand Episode 20.
With KV-Cache, it’s like you’ve memorized the first 19 episodes perfectly—you only need to watch the new episode to seamlessly continue binge-watching.
For Transformer-based models, the principle is the same.
When an agent completes an interaction and prepares for the next task, the vast majority of the context it needs has already been computed in previous interactions. It can simply read from the cache—only a tiny amount of new content needs recalculation.
So, for computers, a higher KV-Cache hit rate is better because it means 'less work.'
But behind this 'efficiency' lies a new problem:
A powerful GPU can compute a new round of interaction with a few hundred tokens in less than 1 millisecond. But before that, it needs to retrieve the 'memory' of those hundreds of thousands of tokens—that is, tens of GB of KV-Cache data.
To use KV-Cache efficiently, this data must be transferred from the hard drive or distributed storage into the GPU's memory.
It’s like a top chef who can stir-fry a dish in 1 second but whose assistant takes 10 seconds to buy the ingredients.

Thus, the biggest bottleneck in agent inference is no longer compute power but the input-output speed of KV-Cache data.
02
Existing Architecture: PD Separation
To improve inference performance, the industry commonly adopts an architecture called 'prefetch-decode separation,' or PD separation for short.
Simply put, under this architecture, the GPU cluster is divided into two departments:
One is the prefetch engine, responsible for processing massive input text—a compute-intensive task that excels at batch processing. The other is the decode engine, responsible for generating responses one character at a time, extremely sensitive to latency but constrained by memory.
In this setup, the prefetch engine constantly loads massive amounts of KV-Cache data from external storage, and its storage network interface card (NIC) is almost always oversaturated, causing congestion.
Meanwhile, the decode engine runs normally, but its storage NIC is mostly idle.
It’s like a warehouse where the receiving door is blocked while the shipping door stands empty—the entire logistics line grinds to a halt.

In today’s world of high compute costs, leaving hardware resources idle in a high-performance chip cluster is a tremendous waste.
The most intuitive solution is to widen the receiving door—adding bandwidth to the prefetch engine. But in practice, this is neither realistic nor cost-effective.
A smarter approach: let the shipping door help with receiving—that is, have the idle decode engine handle some of the data-pulling tasks.
03
DualPath: A Covert Operation
The research team from DeepSeek, Tsinghua, and Peking Universities drew inspiration from studies of modern AI data centers.
Similar to NVIDIA’s AI supercomputer DGX SuperPOD, the architecture generally features an important hardware trait: network isolation.
Each GPU typically comes with two sets of NICs:
1. Compute NIC: Dedicated to cross-node communication between GPUs, usually equipped with multiple cards offering extremely high total bandwidth.
2. Storage NIC: Used for reading and writing data from hard drives or distributed storage, typically equipped with just one card and relatively lower total bandwidth.
Building on this, the research team sought to fully leverage network transmission performance and proposed the idea of dual-path KV-Cache loading.
The previous architecture used a single path: the prefetch engine directly pulled KV-Cache data from the hard drive or distributed storage via its own storage NIC.
DualPath, however, has the idle decode engine use its storage NIC to pull KV-Cache data into its memory, then uses the high-bandwidth compute network to rapidly transfer the data to the prefetch engine.
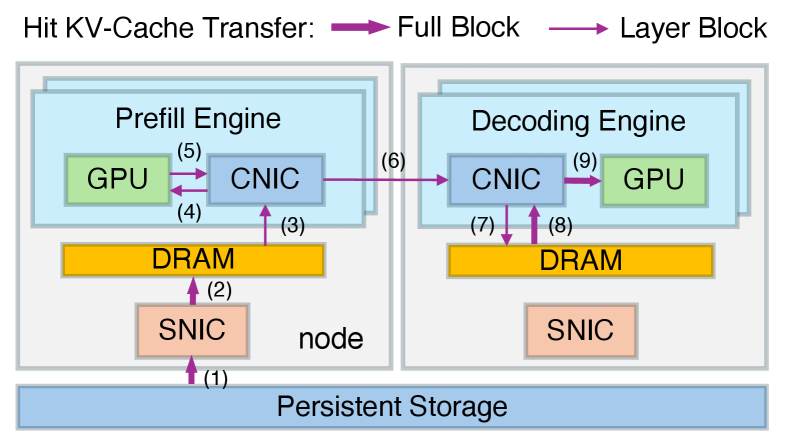
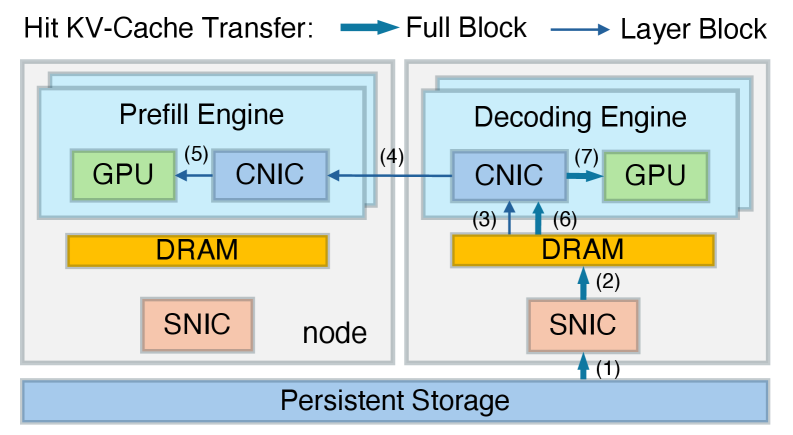
Of course, DualPath doesn’t blindly have the decode engine help—it monitors congestion at both 'doors' in real time.
This way, when the receiving door is blocked and there’s no outgoing traffic, the shipping door starts receiving too. The storage NIC bandwidth of all engines is effectively utilized, and the problem of asymmetric bandwidth saturation is resolved.
Through rigorous bandwidth analysis, the research team proved that under common prefetch-to-decode node ratios, DualPath saturates storage NIC bandwidth without making compute NIC bandwidth a new bottleneck, covering most real-world deployment scenarios.
04
Traffic Scheduling and Priority Negotiation
While the data flow takes a longer route, actual inference efficiency improves significantly—a seemingly ideal outcome.
But implementing this in a system operating at microsecond levels presents substantial challenges:
1. Chaos from massive data inflow:
Having the decode engine help pull historical memory data (KV-Cache) is a great idea but comes with significant risks.
During GPU inference, frequent 'collective communication' with other GPUs in the cluster is required to synchronize data and exchange results—a process extremely sensitive to latency. Even slight delays are unacceptable.
If the decode engine starts downloading several GB of KV-Cache data, the resulting data flood could clog network bandwidth. If GPU-to-GPU collective communication gets blocked, inference still stalls.
To address this chaos, the research team installed a high-speed 'traffic cop' at the NIC level:
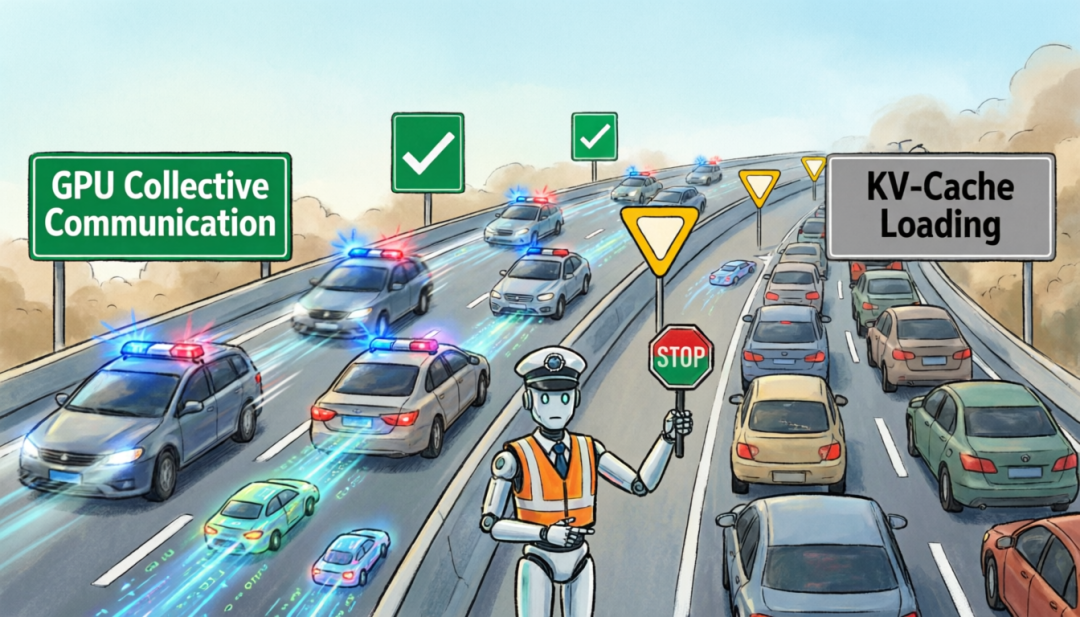
GPU-to-GPU communication must have the highest priority—it gets VIP lane access and must operate smoothly without congestion at all costs.
KV-Cache pulling tasks have only ordinary priority—they can only proceed when the VIP lane is clear and must immediately yield if GPU communication tasks arise.
This 'traffic cop,' played by the compute NIC (CNIC), must completely isolate the two data flows to ensure that data pulling by the decode engine never interferes with GPU-to-GPU collective communication.
2. Dynamic task allocation:
Diverse user demands mean that agent inference tasks are always dynamically changing—sometimes requests are heavy, sometimes light; some are long, some are short.
If the 'traffic cop' misdirects, it could backfire. For example, forcing the decode engine to pull data even when the prefetch engine’s bandwidth isn’t saturated.
How to dynamically allocate tasks in real time through load balancing is the mathematical challenge this 'traffic cop' must solve.
To address this, the research team designed an adaptive request scheduler that dynamically selects the optimal data-loading path during runtime based on storage NIC queue length, GPU compute load, and request characteristics.
Between engines, it monitors not only each GPU’s current compute load (i.e., the number of tokens awaiting processing) but also the disk read queue length at each node in the underlying distributed storage.
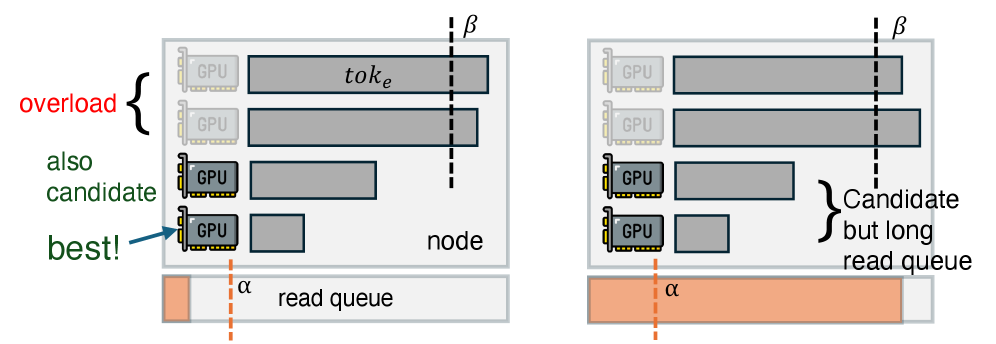
This way, new requests are intelligently assigned to the engine with the shortest read queue and the least busy GPU for loading.
Within an engine, since multiple GPUs work together, all GPUs must finish their tasks simultaneously to proceed to the next step—this is synchronization in the attention mechanism.
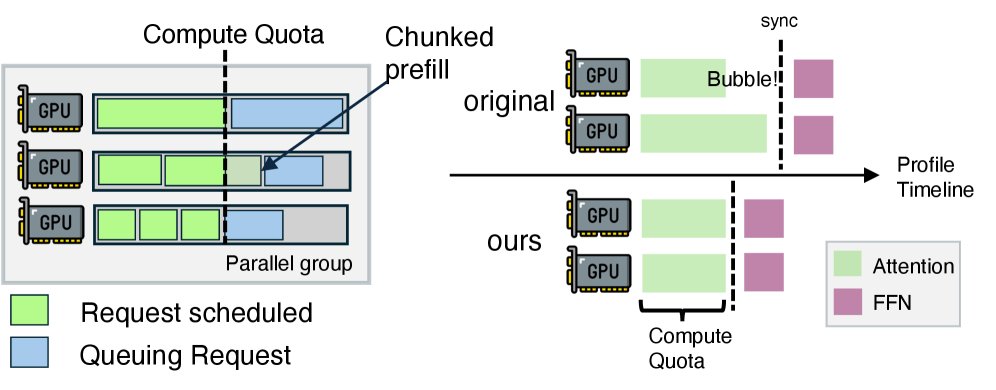
To prevent GPUs handling short tasks from 'waiting' for those handling long tasks, it uses a compute-quota-based batch selection algorithm to split long tasks into shorter ones, aligning the attention mechanism computation times across multiple GPUs and expediting progress to the next step.
At this point, all challenges faced by DualPath have been resolved.
05
Real-World Testing: Throughput Doubles!
Now it’s time to put the technical achievements to the test.
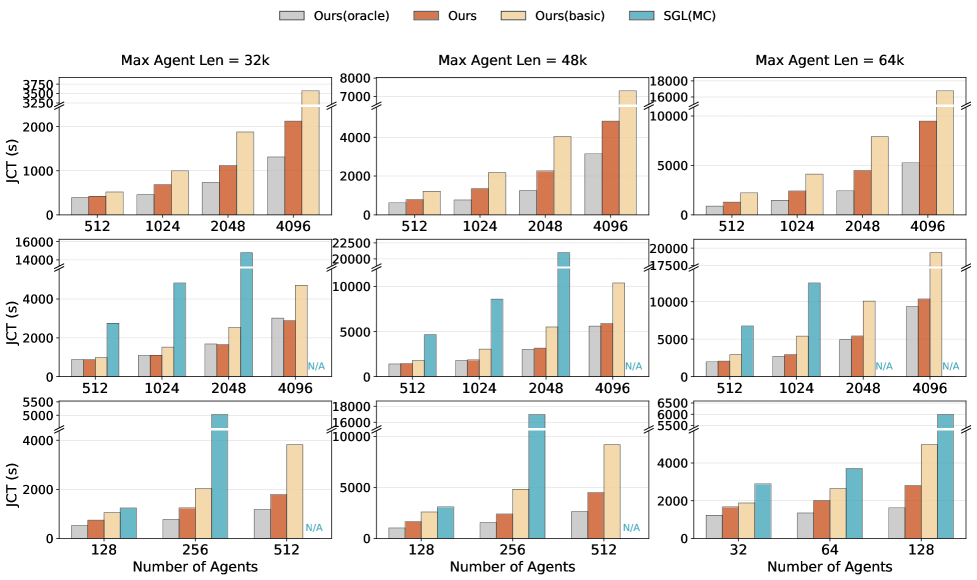
The research team tested three models—DeepSeek-V3.2 (660B parameters), a simplified 27B-parameter version, and Qwen2.5-32B—on an NVIDIA Hopper GPU cluster with InfiniBand high-speed interconnects, evaluating them based on real agent reinforcement learning training trajectories.
In offline batch inference tasks, for the DeepSeek-V3.2 660B model, DualPath significantly reduced task completion time, boosting system throughput by up to 1.87x and approaching the ideal performance of zero I/O latency.
In online service inference tasks, simulated real users continuously flood in, and the system needs to handle as many requests as possible while ensuring that the delay for outputting the first character does not exceed 4 seconds.
The results show that the DualPath system can handle an average of 1.96 times the number of concurrent requests compared to the baseline system, and even up to 2.25 times under specific load conditions.
In a large-scale experiment expanding the GPU cluster to 1,152 units, DualPath demonstrated a near-linear speedup ratio with extremely low performance degradation, undoubtedly providing strong persuasion for its practical deployment.
Reviewing the development history from 'large models' to 'agents,' we can see a clear path:
The earliest challenge was computing power; how to compute neural network matrices faster was the top priority.
Subsequently, memory took center stage, with model weights and KV-Cache occupying network transmission bandwidth.
Now, with the explosion of agents and exponentially growing contexts, the challenges have shifted to the input/output and network levels.
DeepSeek, Tsinghua University, and Peking University jointly proposed DualPath, successfully overcoming this threshold by breaking the conventional data flow and fully utilizing idle resources.
It is no exaggeration to say that this is yet another textbook-level demonstration of hardware-software co-design.
As the underlying infrastructure for agents, the internal computational logic of large models is quietly undergoing significant changes.
Distributed architectures like DualPath, which break traditional boundaries and maximize the I/O potential of hardware clusters, are destined to become standard in next-generation AI infrastructure.
There is no need to regret the delayed release of new products, as technology has become the most solid foundation, and the long-awaited DeepSeek-V4 is just around the corner.
-
![]()
The World's First Trillionaire Emerges: Is SpaceX's $2 Trillion Valuation Justified?
-
Volkswagen to Implement 19,000 Job Cuts in Germany This Year
-
![]()
Tremble, Humans: AI Continues to Accelerate at Breakneck Speed
-
![]()
A Strategic Vision: Taking a Leaf Out of Apple’s Book in China’s Operation-Intensive Auto Market
-
![]()
Yu Chengdong Declares, ‘Only First Place Exists in My Lexicon.’ Is This Bold Claim or a Promise of Excellence?
-
![]()
Agent OS is Here! HarmonyOS 7 Unveiled, Huawei Redefines OS
-
![]()
Agent OS is Here! Huawei Unveils HarmonyOS 7, Redefining Operating Systems
-
DingTalk’s Evolution and the Dilemma Facing Alibaba