Ethernet Revolutionized: Tomahawk Ultra Redefines AI Interconnect Infrastructure
 07/18 2025
07/18 2025
 731
731
Produced by Zhineng Zhixin
Broadcom's Tomahawk Ultra heralds a transformative shift in Ethernet for high-performance computing (HPC) and AI cluster interconnectivity.
This 51.2Tbps switch chip eschews the pursuit of maximum throughput in favor of core capabilities such as low latency, small packet processing, in-network computing, and lossless transmission. Its aim is to supplant traditional InfiniBand and NVLink architectures, laying the groundwork for Scale-Up Ethernet (SUE).

Part 1
The Technical Heart of Tomahawk Ultra:
The Ultimate Goal of Low Latency and Lossless Transmission for Small Packets
Traditional Ethernet switches have prioritized high throughput under large packet conditions, but this approach encounters limitations in HPC and AI cluster interconnects.
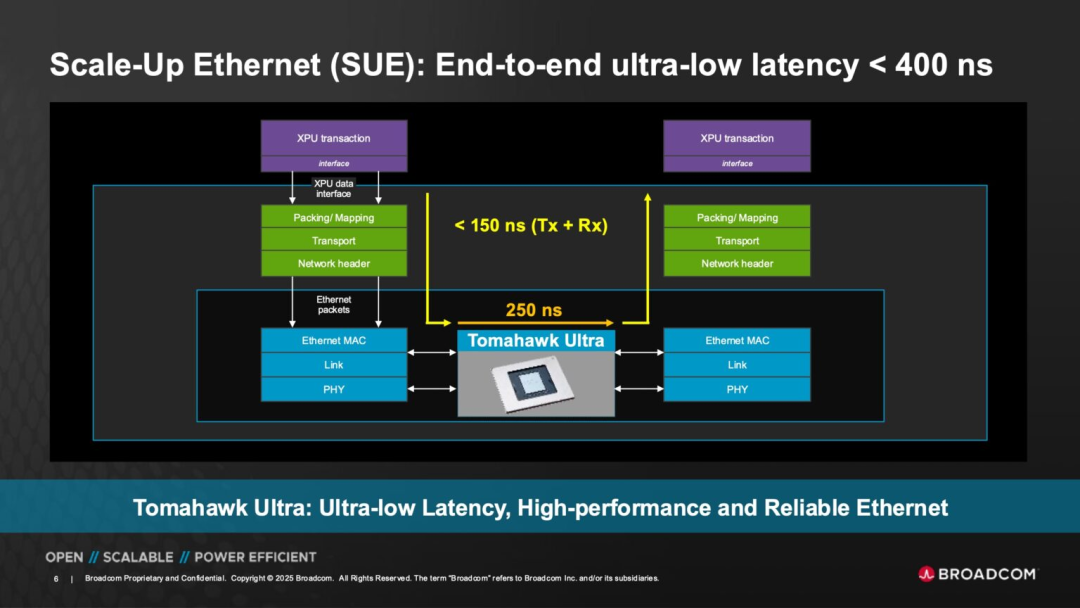
Tomahawk Ultra reverses this trend by design, supporting 51.2Tbps throughput for 64-byte small packets while maintaining latency within 250 nanoseconds. This grants it a significant latency edge over standard Ethernet switch chips in environments involving frequent transmission of numerous fine-grained messages.

To achieve this, Broadcom employs several key technologies:
◎ Optimized Ethernet Header: Traditional Ethernet headers consume a substantial portion. Tomahawk Ultra reduces this from 46 bytes to 10 bytes, significantly decreasing control overhead without violating standard protocols.
This significantly boosts the payload ratio for small packet communication scenarios, maximizing the effective utilization of communication bandwidth.


◎ Link Layer Reliability (LLR) and Forward Error Correction (FEC): Tomahawk Ultra shifts error detection to the link layer and rectifies errors through FEC mechanisms at this level, eliminating the need for complex retransmission logic at upper-layer protocols.
This not only shortens the error handling path but also enhances overall latency performance.
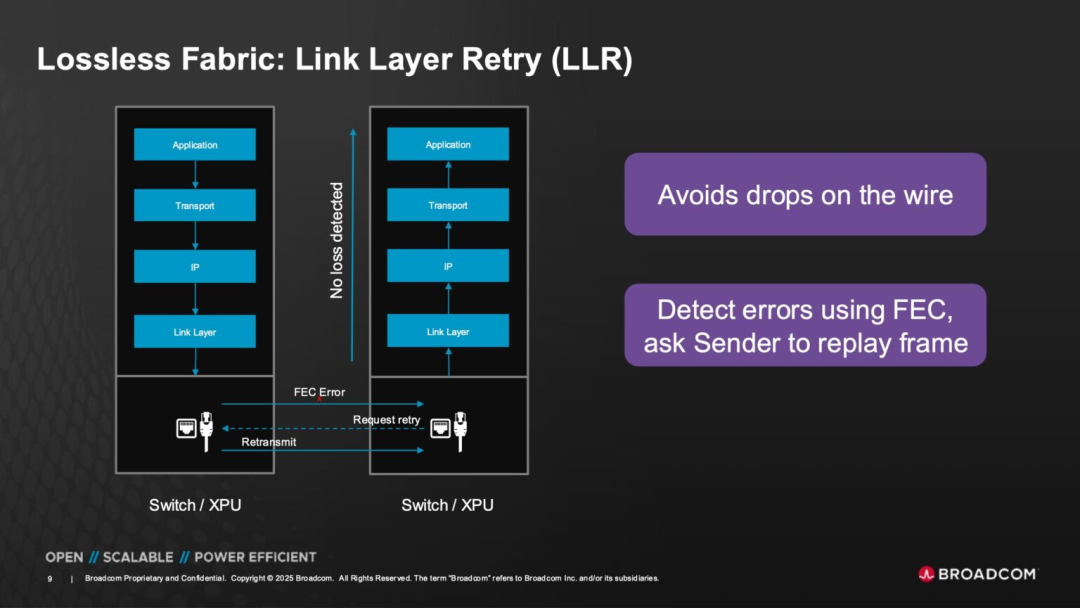
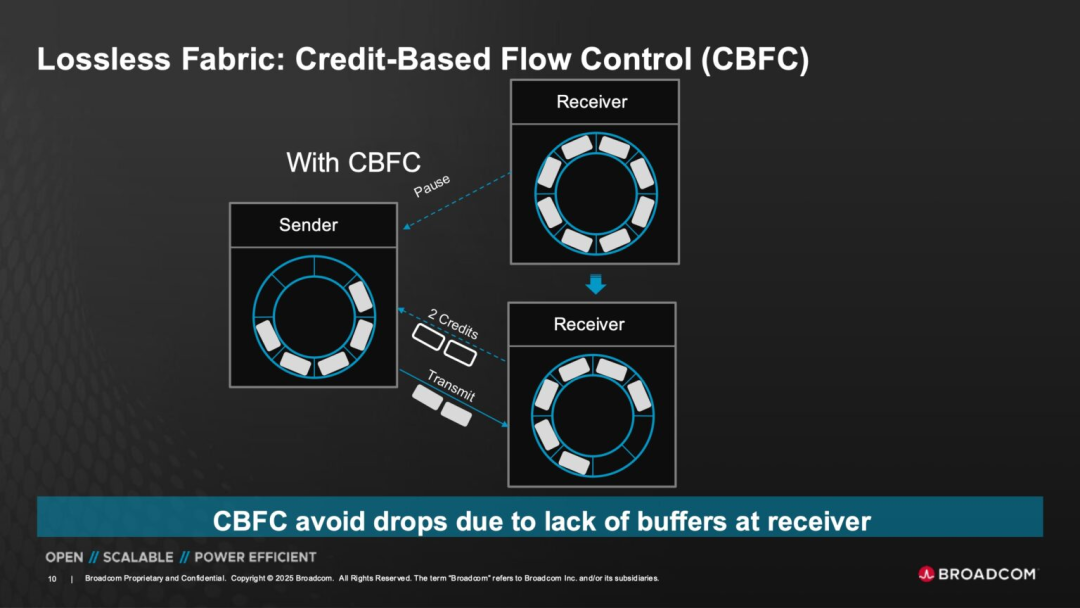
◎ Credit-Based Flow Control (CBFC) Mechanism: Unlike traditional Ethernet congestion control, Tomahawk Ultra employs a method where "sending is limited by the receiving end's buffer capacity." Credit signals are released to the sender only when the receiver has the capacity to receive.
This design effectively prevents packet loss and congestion due to buffer overflow in the network, establishing a foundation for a switch network closer to lossless transmission.
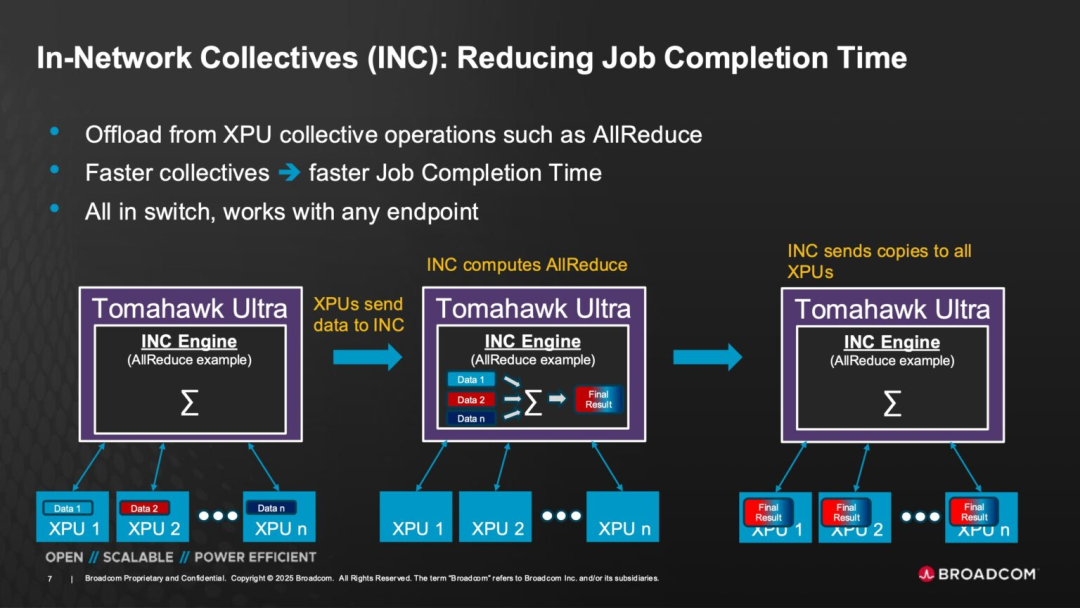
◎ In-Network Collective (INC) Support: Similar to NVIDIA Quantum InfiniBand switches' In-Network Collective logic, Tomahawk Ultra also possesses this capability, enabling aggregation, forwarding, and simplification of multi-node communications at the switch layer.
This allows collective operations (such as AllReduce) originally requiring multiple point-to-point communications between node CPUs to be completed at the switch chip level, substantially reducing synchronization bottlenecks in AI training.
These optimizations not only address the physical transmission link but also involve a comprehensive overhaul of the processing logic at the switch layer. The goal is to reposition Ethernet from its traditional "high throughput, weak real-time" perception to a real-time, computationally synergistic underlying communication platform in HPC and AI fields.

Part 2
Implementing the Scale-Up Ethernet (SUE) Architecture:
Challenging InfiniBand and NVLink
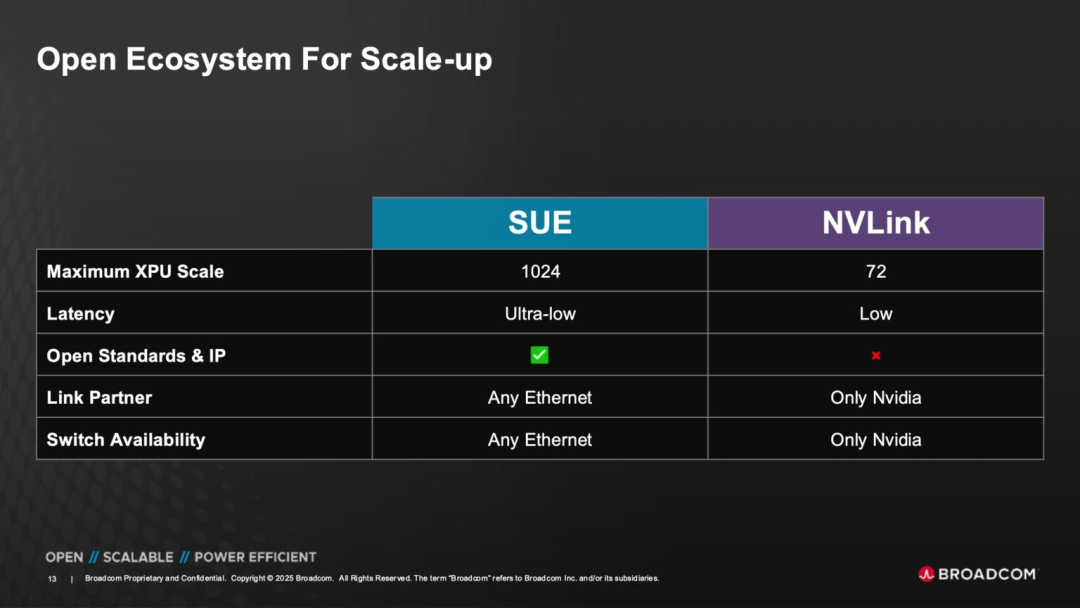
Tomahawk Ultra's strategic positioning transcends merely launching a new Ethernet switch chip; it challenges proprietary interconnect technology systems dominated by vendors like NVIDIA through the novel "Scale-Up Ethernet" (SUE) communication architecture.
Currently, NVLink, Quantum InfiniBand, and upcoming UALink, widely used in AI and HPC systems, are non-standard or semi-standardized technologies with issues like ecological isolation, poor interoperability, and high customization costs.
Under the SUE architecture, Broadcom has designed two tiers:
◎ Full SUE Version: Supports a comprehensive set of advanced features like in-network computing, credit flow control, header compression, etc., building a switching backbone for ultra-large-scale GPU/AI clusters.
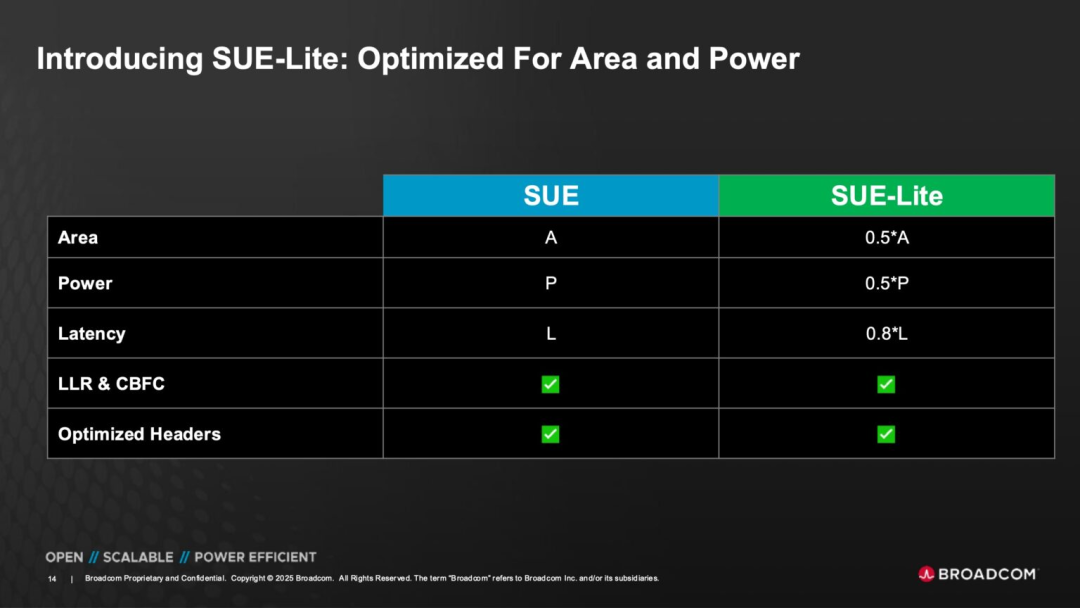
◎ SUE-Lite Version: Provides a lighter-weight option for scenarios that prioritize certain features but face resource constraints, facilitating broader Ethernet scenario adoption.
At the deployment level, Tomahawk Ultra is pin-compatible with Broadcom's existing Tomahawk 5 and has been launched in tandem with the Tomahawk 6 series (102.4T version).
The latter continues to focus on the "Scale-Out Ethernet" direction, catering to the extreme bandwidth demands of traditional ultra-large data centers. Tomahawk Ultra, however, shifts towards the "Scale-Up" direction, addressing the tight interconnection needs between GPUs and XPUs. This dual-pronged strategy positions Broadcom at the forefront of the transition from traditional data centers to AI-native networks.

In terms of interface protocol standards, Tomahawk Ultra retains full Ethernet compatibility, meaning it can operate on standardized operating systems, driver stacks, and TCP/IP protocols without relying on custom systems like InfiniBand or NVLink. For AI system developers, this offers greater accessibility and a wider choice of hardware ecosystems.

Broadcom has further optimized the packet path, enabling the XPU end to "send packets" faster, and the switch chip can transfer, aggregate, and resend data with near-zero latency, maintaining overall link latency at 250ns. This performance rivals the best InfiniBand configurations but at significantly lower costs and deployment complexities.
Summary
Tomahawk Ultra embodies Broadcom's deepened understanding of the Ethernet architecture. Instead of prioritizing maximum throughput, it forges a new path for AI and HPC clusters centered around small packet processing, low-latency communication, in-network computing, link layer reliability, and lossless mechanisms.
Compared to proprietary interconnect protocols, Ethernet inherently excels in versatility, compatibility, and maintainability. Tomahawk Ultra aims to evolve Ethernet from a "general-purpose network suitable for large data flows" to a "computational-grade communication structure supporting small packets, low latency, and high synergy."
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






