GPT-4o mini Hands-on Review: Small Models Are Also Good, and Low Prices Are the Ultimate Weapon
 07/21 2024
07/21 2024
 594
594
It will appear on iOS 18.
On the evening of July 18, Beijing time, OpenAI rarely launched a "small model" — GPT-4o mini.
As the name suggests, GPT-4o mini is an attempt by OpenAI based on GPT-4o. The official stated that GPT-4o mini surpasses GPT-3.5 Turbo in text intelligence and multimodal reasoning benchmarks, and even outperforms GPT-4 on the LMSYS "chatbot battle" rankings.
Moreover, GPT-4o mini supports a long context window of 128K Tokens and an output of up to 16K Tokens per request. In short, GPT-4o mini can remember much longer content and conversations than GPT-3.5 Turbo and provide longer answers in a single output.
However, the core of GPT-4o mini is to provide better cost-effectiveness.
According to OpenAI, GPT-4o mini not only boasts stronger performance but also comes at a "dirt-cheap" price. Specifically, GPT-4o mini is priced at 15 cents (approximately RMB 1.09) per million input Tokens and 60 cents (approximately RMB 4.36) per million output Tokens:
Over 60% cheaper than GPT-3.5 Turbo.
For average users, what's more important is that GPT-4o will fully replace GPT-3.5 Turbo in ChatGPT, making it accessible to free users. As of this morning (July 19), LeiTech has already seen GPT-4o mini instead of GPT-3.5 in ChatGPT.
Photo/LeiTech
Separately, according to VentureBeat's interview, Olivier Godement, Head of Product and API at OpenAI, stated that GPT-4o mini will be available on Apple's mobile devices and Macs via Apple Intelligence this fall.
However, there may be a misunderstanding here. Although GPT-4o mini is much smaller than large models like GPT-4o, its scale is still much larger than the end-side large models (basically not exceeding 7b) found on mobile phones. Therefore, GPT-4o mini will still be provided as a cloud service rather than locally on systems like iOS 18.
GPT-4o mini: A Better and Cheaper GPT
After OpenAI released GPT-4o mini, many people's first concern might be: How does GPT-4o mini compare to GPT-4 and GPT-4o in terms of usability?
To illustrate simply, let's ask ChatGPT the same question using these three models: "Introduce OpenAI's newly released GPT-4o mini model."
In terms of generated results, GPT-4o mini's answer does not contain any data and is relatively vague, but the relevant description is basically correct. Considering that OpenAI stated that GPT-4o mini only has knowledge up to October 2023 and does not support internet connectivity in ChatGPT, it can be inferred that GPT-4o mini made a "guess" based on the name.

GPT-4o mini, Photo/LeiTech
In contrast, GPT-4 (without internet search) told me that "OpenAI has not released a model named 'GPT-4o mini,'" and only began introducing it after being prompted to search the internet. However, even then, GPT-4 did not significantly exceed the answer generated by GPT-4o mini, and even when explicitly asked about its cost, it failed to provide a satisfactory answer.
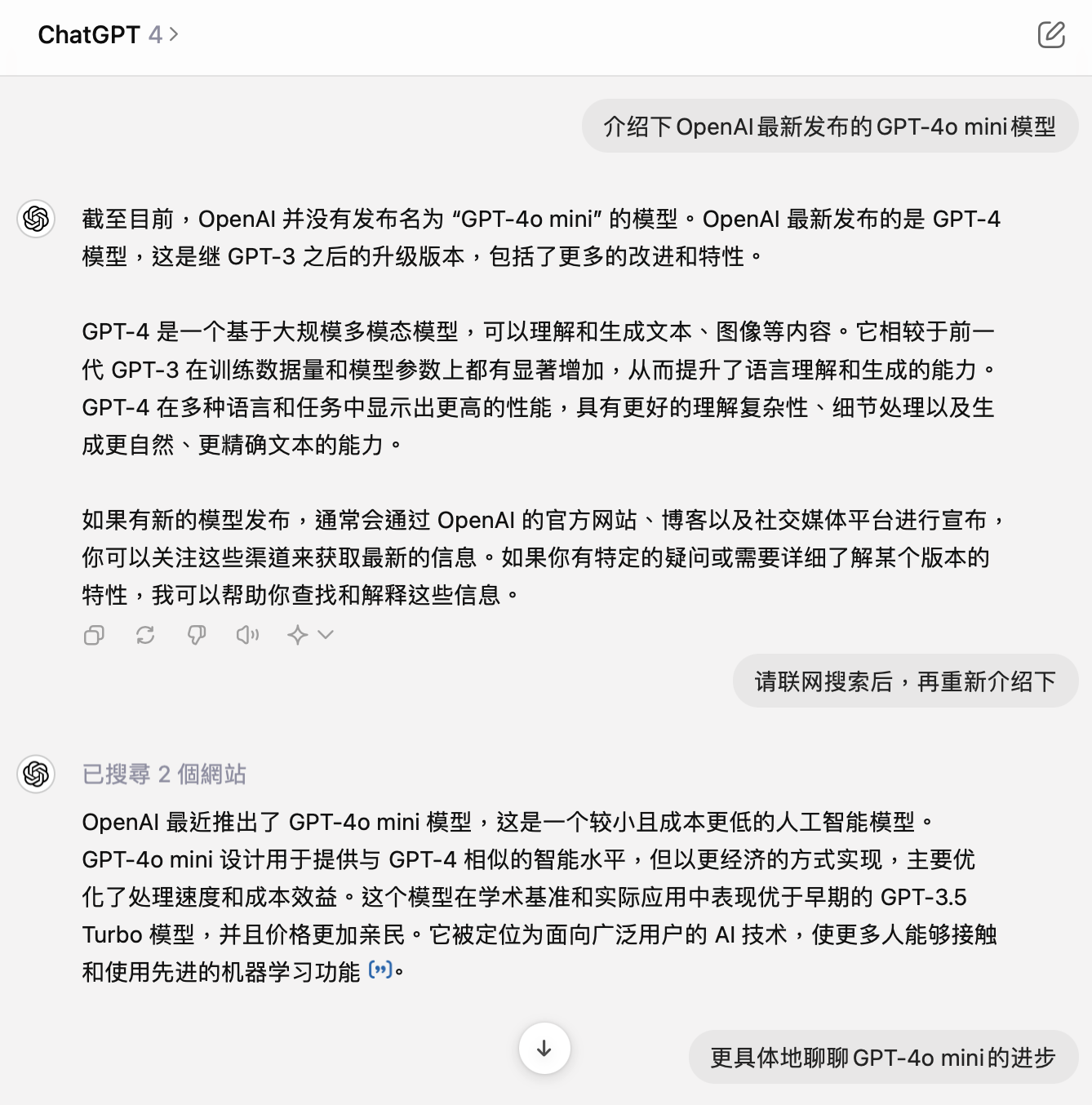
GPT-4, Photo/LeiTech
As for GPT-4o (with automatic internet search), as the most powerful model under OpenAI and even globally, its performance is undoubted. More detailed introductions, more conclusive data, and cited references all contribute to its continued position as the top large model.

GPT-4o, Photo/LeiTech
In summary, GPT-4o mini shows significant improvements over the previous GPT-3.5 and even has certain advantages over GPT-4. Although my current simple tests generally align with the conclusions given by OpenAI and the LMSYS rankings, it's still too early to draw a final conclusion. If you have a need, you can conduct a more comprehensive comparison later.
Additionally, OpenAI has also released GPT-4o mini's "benchmark scores" under different benchmarks for reference:
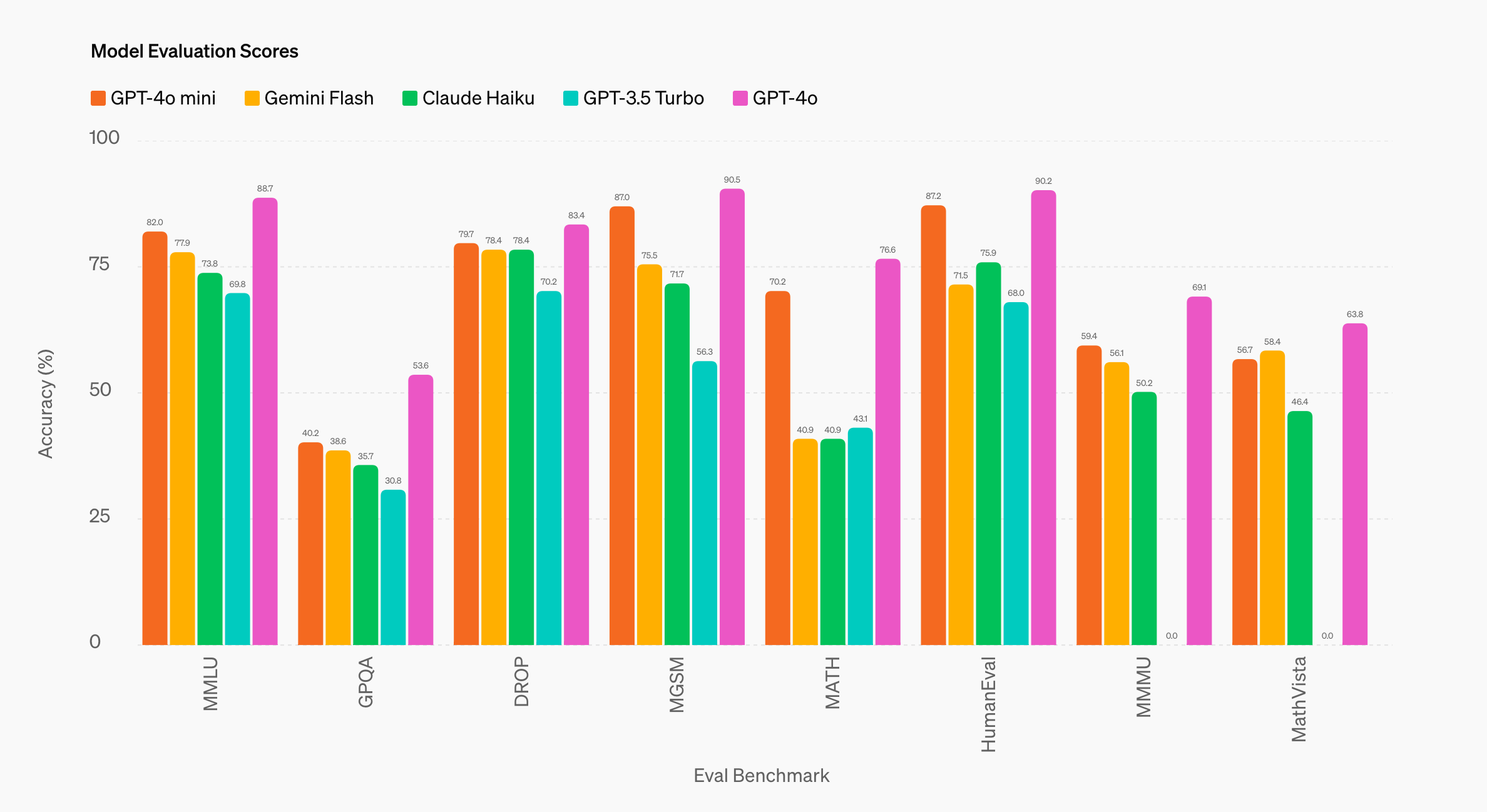
Photo/OpenAI
Overall, compared to Gemini 1.5 Flash and Claude 3 Haiku, which also focus on "cost-effectiveness" (derived from very large models), GPT-4o mini has more obvious advantages, especially in areas such as MGSM (mathematical reasoning), MATH (math problem-solving), and HumanEval (code generation).
Meanwhile, OpenAI also stated that GPT-4o mini supports text in the API and will gradually add support for input and output of images, videos, and audio. Thanks to the improved Token generator shared with GPT-4o, processing non-English text is now more economical and efficient.
Immediately after the launch of GPT-4o mini, overseas and domestic developers began planning to switch to GPT-4o mini for testing, such as former iFanr Vice President and Chief Design Officer @Ping., who developed the AI voice note app "闪念贝壳":
Photo/X@Ping.
In fact, for GPT-4o mini, the most core and important users at this stage are developers who use the API, rather than average users of ChatGPT.
Why Did OpenAI Launch GPT-4o mini?
For OpenAI, launching GPT-4o mini is somewhat unusual, as before this, from GPT-1/2/3, GPT-3.5 to GPT-4 and GPT-4o, OpenAI has been launching ever-stronger large models, pushing the ceiling of machine intelligence. Even the Turbo series optimized speed and cost under equivalent performance.
However, with GPT-4o mini, OpenAI chose to reduce model size and performance to achieve a more cost-effective generative AI model.
The question is that before OpenAI, many large model vendors had adopted a strategy of advancing "large, medium, and small models" simultaneously. Even Google's Gemini and Anthropic's Claude have launched Gemini 1.5 Flash and Claude 3 Haiku, respectively.
Olivier Godement explained that OpenAI focuses on creating larger, better models like GPT-4, which requires significant human and computational resources. However, over time, OpenAI noticed that developers were increasingly eager to use smaller models, so the company decided to invest resources in developing GPT-4o mini and launch it now.
"Our mission is to use cutting-edge technology to build the most powerful and useful applications. We certainly want to continue developing frontier models to drive technological progress," Olivier Godement said in the interview. "But we also want to have the best small models, which I believe will be very popular."

Photo/OpenAI
In short, it's a matter of priority. But behind the priority is the growing preference for small and medium-sized generative AI models among companies.
A recent report by the WSJ cited several company executives and Oliver Parker, Vice President of Global Generative AI Product Launch Strategy at Google Cloud, pointing out that over the past three months, companies are collectively turning to smaller parameter-scale generative AI models.
Cost is undoubtedly the core reason.
According to the "Comparison of Domestic and Foreign AI Large Language Model API Prices" maintained by AIGCRank:
- GPT-4o is priced at $5 (approximately RMB 36.3) per million input Tokens and $15 (approximately RMB 109) per million output Tokens;
- Baidu Wenxin 4.0 Turbo is priced at RMB 30 for input and RMB 60 for output;
- Claude 3 Haiku is priced at $0.25 (approximately RMB 1.81) per million input Tokens and $1.25 (approximately RMB 9.08) per million output Tokens.
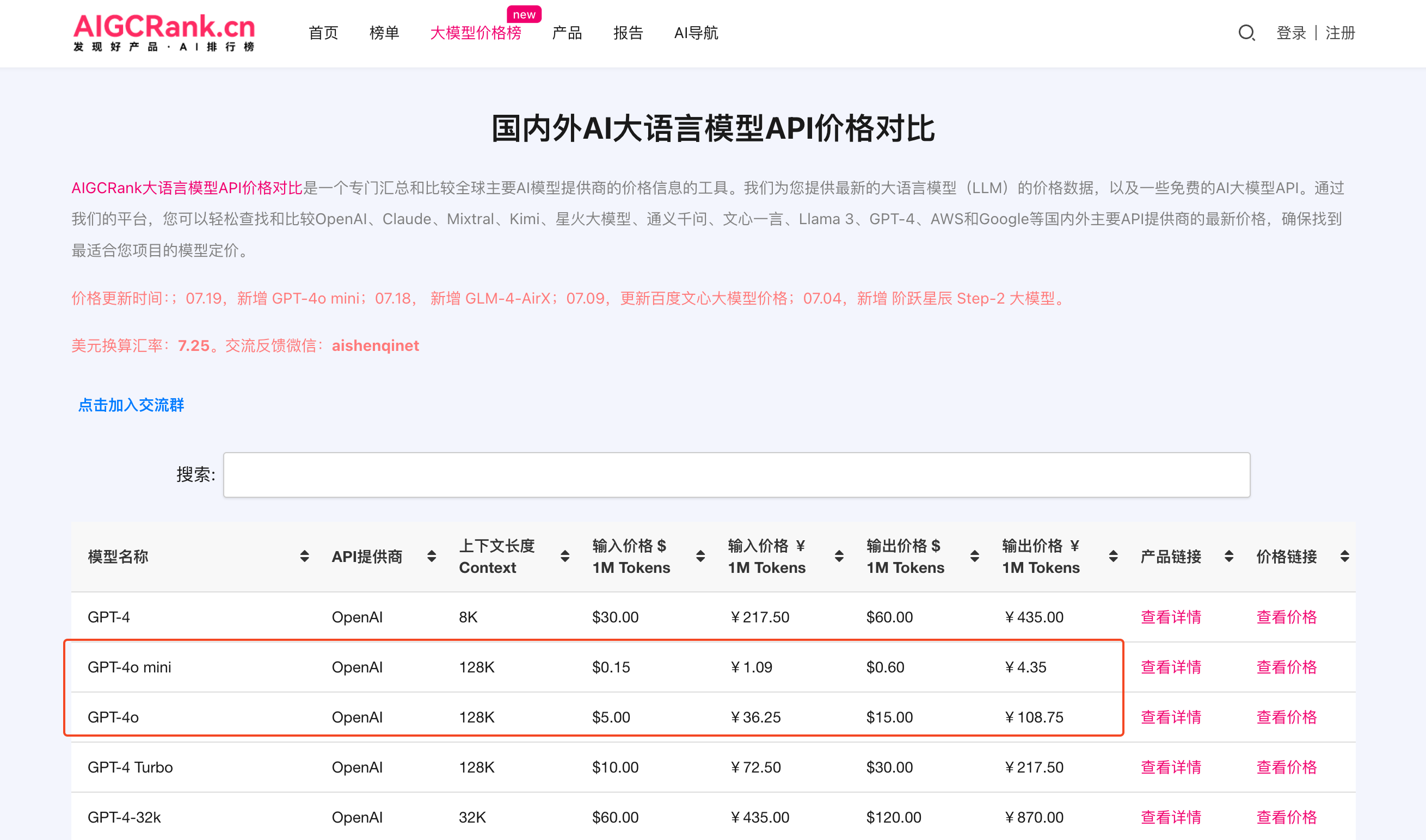
Price Gap, Photo/LeiTech
Under the premise of ensuring performance meets requirements, the cost advantage of Claude 3 Haiku's "small" model is self-evident.
DeepSeek, considered the "instigator" of collective price reductions among domestic large models, can offer API pricing (per million) of RMB 1 for input and RMB 2 for output, comparable to Gemini 1.5 Flash's comprehensive performance. Ali Tongyi Qianwen's Qwen-Long even achieves RMB 0.5 for input and RMB 2 for output.
For developers, "cost" and "effectiveness" are the two core points in large model applications. Lower prices for large models undoubtedly help more enterprises and individual developers introduce generative AI into more scenarios and applications, facilitating the popularization of AI in ordinary people's lives and work, as Oliver Parker emphasized:
I believe GPT-4o Mini truly embodies OpenAI's mission to make AI more accessible. If we want AI to benefit every corner of the world, every industry, and every application, we must make AI more affordable.
But Are Smaller Models Good Enough?
At Baidu AI Developer Conference held in April this year, Robin Li pointed out that in some specific scenarios, fine-tuned small models can perform comparably to large models.

Photo/LeiTech
Subsequently, Jia Yangqing, former CTO of Ali Group, agreed on WeChat Moments: "I think Robin's point is very valid. After the initial application attempts, model specialization will be a more sensible choice in terms of both effectiveness and cost-effectiveness."
This is not just a consensus in the domestic large model industry.
"Giant large language models trained across the entire internet may be severely overqualified," said Robert Blumofe, CTO of Akamai, a cybersecurity, content delivery, and cloud computing company. For enterprises, "you don't need an AI model that knows all the actors in 'The Godfather,' knows all the movies, knows all the TV shows."
In short, large models have gone too far in the direction of "generalization," and many application scenarios actually do not require the "versatility" of large models.
To make every parameter more valuable, large model vendors are continuously researching more efficient model compression methods such as distillation and pruning, attempting to transfer the "knowledge" of large language models to smaller, simpler medium and small language models.
Data is even more crucial.

IEEE Spectrum, Photo/LeiTech
IEEE Spectrum, a magazine under the Institute of Electrical and Electronics Engineers (IEEE), cited experts who pointed out that large language models are directly trained using highly diverse and massive text from the internet, but models like Microsoft's Phi or Apple's Intelligent are trained using richer and more complex datasets, which have a more consistent style and higher quality, making them easier to learn from.
To put it another way, large models rely on their immense memory and computing power to learn from the internet, which is a mix of high-quality and low-quality information. In contrast, current small models learn directly from filtered and refined "textbooks," making the learning process more straightforward.
Interestingly, last year, the industry believed that the true application of small models was on device-side, such as smartphones and laptops, but more vendors and developers still prioritized large models in the cloud.
However, over the past few months, while small models have yet to truly take off on device-side, they have become a trend in the cloud as well.
At its core, this is due to the mismatch between "cost" and "effectiveness" in the practical application of large models, and while "effectiveness" still needs to be explored and tried, "cost" has become the primary challenge that must be addressed.
Final Thoughts
Large models are no longer "parameter-driven."
At the WIRED25 event held in April this year, OpenAI CEO Sam Altman stated that the progress of large models will not come from increasing their size. "I think we're at the end of the era of giant models," he said.

Photo/OpenAI
To some extent, Sam Altman hinted that the long-brewing GPT-5 will not continue to expand in terms of parameters but will further enhance the "intelligence" of large models through algorithms or data, thereby leading to AGI (Artificial General Intelligence).
As for the newly launched GPT-4o mini, it represents another path, one that will bring AI to the world more quickly.
However, to successfully navigate this path, the core issue is to minimize "cost" while ensuring "effectiveness," allowing more developers to use AI and create more innovative and practically valuable applications that benefit more users.
And this may be what domestic vendors excel at.
Source: LeiTech
-
![]()
Total Investment Hits Nearly 3.28 Billion! Goertek Launches Mass Production of 12-Inch Transparent Substrate Wafer for AR Glasses’ Micro-Nano Optical Components
-
![]()
Why Is This Precision Optical Film Leader Worth Reevaluating with a Tens of Millions Procurement?
-
![]()
AI Costs Plummet by 90% Over Nine Years: Key Insights from Davos You Shouldn’t Miss
-
Doubao, Your Late-Night AI Companion, Now Eyes Profitability
-
![]()
SRC Empowers SEER Intelligence to Reach a Market Cap of Tens of Billions, Yet Fails to Sustain Profitability
-
![]()
China’s Embodied AI Industry Faces Fierce Domestic Competition, Making Overseas Expansion Essential for Survival
-
![]()
32.8 Billion Yuan Investment! Goertek’s 12-Inch AR Glasses Optical Wafer Base in Lingang Begins Operations
-
![]()
How Far is the All-New Li Auto L8 from Being the Best Five-Seat SUV with In-House Full-Stack Development?






