Challenges in Deploying World Models for Autonomous Driving
 04/10 2026
04/10 2026
 547
547
World models have recently emerged as a focal point of discussion within the autonomous driving sector. Essentially, a world model endows an autonomous vehicle with a "visionary" brain. It goes beyond merely detecting immediate traffic signals and pedestrians; it also forecasts potential shifts in the traffic environment over the next few seconds based on current conditions. This predictive capability is crucial for autonomous decision-making in complex scenarios, yet several hurdles must be overcome during actual deployment.
How Can the Complex World Be Encapsulated in Algorithms?
To enable algorithms to comprehend the real world, the initial challenge lies in data compression and feature extraction. The real-world environment is brimming with information, with cameras, LiDAR, and millimeter-wave radar generating gigabytes of data per second. Processing these raw pixels or point clouds directly would impose an unimaginable computational load. Hence, the first step for a world model is to construct a latent space, condensing intricate visual information into a set of refined mathematical vectors.
However, this compression process is susceptible to losing vital details. For instance, the color of a distant traffic light, subtle ice patches on the road, or a pedestrian's fleeting glance may be discarded as "noise" during significant data dimensionality reduction. In autonomous driving, these seemingly minor details often dictate the success or failure of decision-making. The primary technical challenge is to accurately capture minute features that impact driving safety while preserving model computational efficiency.
Moreover, the state representation within the latent space must exhibit robust generalization capabilities. If the model is trained solely under sunny conditions on spacious highways, its compression logic may falter when confronted with heavy rain, snow, or congested urban intersections. The depth of understanding of unknown environments directly determines whether the world model can, akin to a human driver, make swift and reasonable judgments on unfamiliar roads.
How Should One Respond to Uncertainty?
The core function of a world model is to predict the future, yet the future is inherently multi-modal—a concept technically known as multi-modal prediction. When a vehicle approaches an intersection, pedestrians on the left may either continue straight or abruptly halt. If the model provides only a single deterministic prediction, the system will be perplexed if reality deviates from this forecast.
The current challenge is to strike a balance in probabilistic distributions. Overly divergent predictions may render the vehicle excessively cautious, considering all potential dangers and hesitating even at deserted intersections. Conversely, overly concentrated predictions may overlook low-probability but high-risk extreme scenarios. Modeling future possibilities necessitates the model to learn not only the physical laws governing object motion but also, to some extent, comprehend social contracts and traffic psychology—clearly surpassing the scope of mere image recognition.
In long-sequence predictions, the issues stemming from uncertainty escalate exponentially. As the prediction timeline extends, minor initial errors are continuously magnified. The predicted future images become blurred and may even exhibit physically implausible hallucinations, such as vehicles vanishing into thin air or buildings deforming. Ensuring that the model maintains logical consistency and physical realism in predictions spanning several seconds or more into the future is a formidable obstacle that developers must surmount.
Can Computing Power Truly Keep Pace with Real-Time Response?
Autonomous driving demands near-stringent real-time performance, as any delay in decision-making can have dire consequences. Currently, mainstream world models, particularly those based on diffusion models or autoregressive architectures, require substantial computational resources. Generating high-quality future scene predictions with these models typically involves extensive iterative computations, which may be feasible on cloud servers but pose significant power consumption and heat dissipation challenges on in-vehicle computing platforms.
High-resolution video generation and multi-sensor fusion processing impose extremely stringent demands on memory bandwidth and processor performance. If the world model's reasoning speed cannot match the vehicle's actual speed, its predictive value becomes negligible.
Presently, the industry is experimenting with various pruning, quantization, and model distillation techniques to reduce model parameter sizes while preserving prediction accuracy. However, this optimization involves a trade-off: reducing model size diminishes its comprehension of complex environments, while maintaining size makes achieving millisecond-level response speeds arduous.
Furthermore, training these models is a costly endeavor. World models necessitate massive amounts of high-quality annotated video data for reinforcement learning, and the process of collecting, cleaning, and training this data consumes significant electricity and hardware resources, imposing a heavy burden on most companies. How to achieve few-shot or self-supervised learning through more efficient algorithmic architectures, thereby reducing reliance on top-tier computing power, is pivotal for the technology's widespread adoption.
How Does Prediction Error Snowball?
Given that world models employ an autoregressive approach in prediction—where the outcome of one prediction serves as input for the next—error accumulation is inevitable, a problem vividly termed "exposure bias." In real driving, even if each prediction error is merely 1%, after dozens of consecutive feedback loops, the final judgment may be entirely off, leading the vehicle to execute completely incorrect evasive maneuvers.
This cumulative error is particularly pronounced in sudden situations. For example, if the vehicle ahead suddenly brakes and the model fails to accurately capture the subtle change in brake light activation in the first frame, all subsequent reasoning will be predicated on the incorrect assumption that "the leading vehicle is moving at a constant speed." This instability in closed-loop systems necessitates the model to possess robust real-time error correction capabilities.
To mitigate this issue, the current strategy involves continuously introducing real observational data for calibration during prediction. However, this introduces new contradictions: if the system relies excessively on real-time observations, the predictive value of the world model is diminished, reducing it to a traditional perception system. Conversely, if it relies too heavily on internal reasoning, it may become disconnected from reality. Finding the optimal balance between predictive reasoning and real-time perception while effectively curbing the snowball effect of errors remains one of the most cutting-edge and challenging topics in the field of autonomous driving.
-- END --
-
![]()
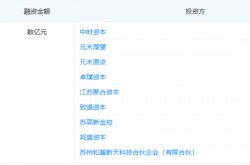
Jitian Xingzhou: A Pioneer in Optical Payloads Secures Hundreds of Millions in Series B Funding!
-
![]()
Orders Secured Through to the Second Half of the Year! The Rationale Behind the 'Surge' in Demand for This Company’s Optical-Grade Base Films
-
![]()
Beyond Patents: The Retail Rivalry of Insta360 and DJI Unfolds
-
![]()
180 Billion Market Cap Vanished! How Did Seres Fall So Far?
-
![]()
Blockbuster! Domestic storage takes the global double crown for the first time, from an AI company
-
![]()
China Spearheads Formulation! World's Pioneering Global Technical Regulation for Automated Driving Systems Greenlit and Unveiled
-
![]()
Farewell to Pulsed Support Policies: Three Major Auto Policy Directions from Multiple Departments Take Effect on the Same Day
-
![]()
Embercore AI’s Accelerated Funding: The Robot Industry’s Shift Toward ‘Learning Systems’