From Perception to Prediction: How World Models Break Through the Bottleneck of Experienced Drivers in Autonomous Driving
 07/18 2025
07/18 2025
 1008
1008
When Waymo's driverless cars complete an average of 14,000 rides per day on the streets of San Francisco, drivers' evaluations always carry a hint of sarcasm – "This car is a bit slow-witted." It can accurately stop at red lights but fails to understand the intention of a delivery man suddenly changing lanes; it can identify lane lines in heavy rain but can't fathom the emergency behind the flashing hazard lights of the car in front. Autonomous driving technology seems to be approaching practical thresholds but is always separated by a layer of "common sense." Behind this layer is the evolutionary path of AI models from "seeing" to "understanding" to "imagining," and the emergence of world models is accelerating the progression of autonomous driving towards the intuitive thinking of "experienced drivers."
From "Modular Assembly Line" to "Cognitive Closed Loop"
The mainstream architecture of currently mass-produced autonomous driving systems resembles a precisely operating "modular assembly line." Cameras and LiDAR disassemble the real world into 3D point clouds and 2D semantic labels, prediction modules estimate the next actions of targets based on historical trajectories, and finally, the planner calculates steering wheel angles and throttle inputs. This segmented design of "perception - prediction - planning" is like equipping a machine with high-precision eyes and limbs but forgetting to give it a thinking brain.

In complex traffic scenarios, the shortcomings of this system are exposed. When a cardboard box is swept up by a gust of wind, it cannot predict the landing point; when children chase a ball on the roadside, it cannot imagine the possibility of them dashing across the zebra crossing. The core of the problem lies in the lack of the machine's cognitive ability to "limited observation → complete modeling → future simulation," akin to that of the human brain. Human drivers automatically slow down when seeing a puddle-covered road, not because they recognize the "puddle" label, but based on the physical common sense that "water film reduces the friction coefficient" – this intrinsic understanding of the operating laws of the world is precisely what current AI lacks the most.
The groundbreaking significance of world models lies in their construction of a "digital twin brain" capable of dynamic simulation. Unlike traditional models that only process single-time perception-decision making, world models can simulate a miniature world internally: input current road conditions and hypothetical actions, and it can generate visual streams, laser point cloud changes, and even fluctuations in tire-to-ground friction coefficients for the next 3-5 seconds. This ability to "rehearse in the mind" allows machines to possess human-like "prejudgment intuition" for the first time. For example, the MogoMind large model launched by Mushroom Auto has demonstrated this characteristic in intelligent connected vehicle projects in multiple cities in China as the first physical world cognitive AI model – by perceiving real-time global traffic flow changes and predicting intersection conflict risks 3 seconds in advance, it improves traffic efficiency by 35%.
Evolutionary Tree of AI Models
Pure Vision Models: "Primitive Intuition" through Violent Fitting
The emergence of NVIDIA Dave-2 in 2016 kicked off the era of pure vision-based autonomous driving. This model, which uses CNN to directly map camera pixels to steering wheel angles, is like a baby just learning to walk, mimicking human operations through "muscle memory" from millions of driving clips. Its advantage lies in its simple structure – requiring only cameras and low-cost chips, but its fatal flaw is that it "knows what it has seen and is confused by what it hasn't." When encountering scenarios outside the training data, such as overturned trucks or motorcycles driving against traffic, the system instantly fails. This "data dependency" keeps pure vision models stuck in the "conditioned reflex" stage.
Multi-modal Fusion: "Wide-angle Lens" for Enhanced Perception
After 2019, BEV (Bird's Eye View) technology became the new darling of the industry. LiDAR point clouds, millimeter-wave radar signals, and high-precision map data are uniformly projected onto a top-down view and then fused across modalities using Transformers. This technology addresses the physical limitation of "camera blind spots" and can accurately calculate the spatial position of "a pedestrian 30 meters ahead on the left." However, it is essentially still "perception enhancement" rather than "cognitive upgrade." It's like equipping a machine with a 360-degree surveillance camera without teaching it to think about "a pedestrian carrying a bulging plastic bag, who might obscure the line of sight next."
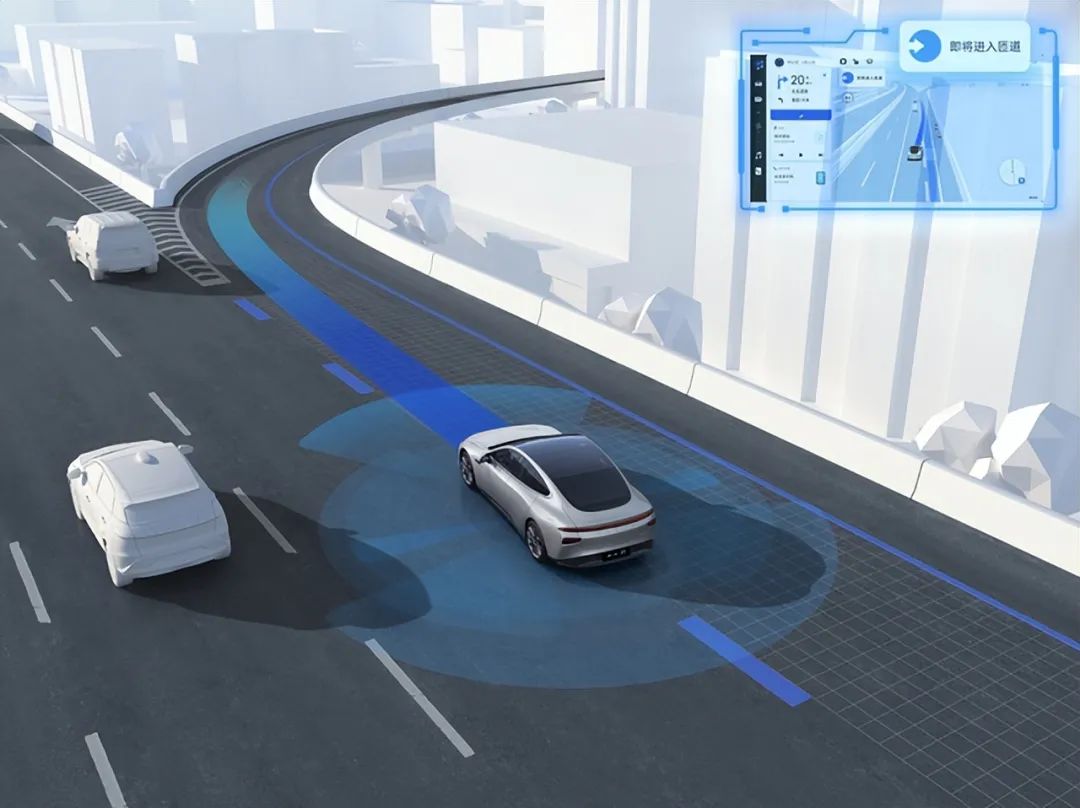
Vision-Language Models: A "Speaking" Sensor
The rise of vision-language large models (VLMs) such as GPT-4V and LLaVA-1.5 allows AI to "describe images" for the first time. When seeing a car in front brake suddenly, it can explain "because a cat darted out"; when recognizing road construction, it will suggest "take the left lane to bypass." This ability to convert visual signals into language descriptions seems to equip machines with "understanding" capabilities, but there are still limitations in autonomous driving scenarios.
Language, as an intermediate carrier, inevitably loses physical details – internet image-text data does not record specialized parameters like "the friction coefficient of a wet manhole cover decreases by 18%." More crucially, VLMs reason based on text correlation rather than physical laws. They may make correct decisions because "heavy rain" and "slow down" are highly correlated in the corpus, but they cannot understand the underlying fluid mechanics principles. This characteristic of "knowing how but not why" makes it difficult for them to handle extreme scenarios.

Vision-Language-Action Models: The Leap from "Speaking" to "Doing"
The VLA (Vision-Language-Action) models that debuted in 2024 took a crucial step forward. NVIDIA VIMA and Google RT-2 can directly convert language commands like "pass me the cup" into joint angles for robotic arms; in driving scenarios, they can generate steering actions based on visual input and voice navigation. This "end-to-end" mapping skips complex intermediate logic, evolving AI from "being able to say" to "being able to do."
However, the shortcomings of VLA are still evident: it relies on internet-scale image-text-video data and lacks a differential understanding of the physical world. When faced with scenarios such as "triple the braking distance on icy roads," data-statistics-based models cannot derive precise physical relationships and can only rely on experience transfer from similar scenarios. In the ever-changing traffic environment, this "empiricism" can easily fail.

World Models: A "Imagining" Digital Brain
The essential difference between world models and all the above models lies in their realization of closed-loop simulation for "prediction - decision making." Its core architecture, V-M-C (Vision-Memory-Controller), forms a cognitive chain similar to the human brain:
The Vision module uses VQ-VAE to compress 256×512 camera frames into 32×32×8 latent codes, extracting key features like the human visual cortex; the Memory module stores historical information and predicts the next frame latent code distribution through GRU and Mixture Density Networks (MDN), similar to how the hippocampus processes sequential memory; the Controller module generates actions based on current features and memory states, akin to the decision-making function of the prefrontal cortex.

The most ingenious aspect of this system is the "dream training" mechanism. After the V and M modules are trained, they can be detached from real vehicles and simulated in the cloud at 1000 times real-time speed – equivalent to the AI "racing" 1 million kilometers a day in a virtual world, accumulating extreme scenario experience at zero cost. When encountering similar situations in the real world, the machine can make optimal decisions based on the "dream" rehearsal.
Equipping World Models with "Newton's Laws Engine"
For world models to truly excel in autonomous driving, they must solve a core problem: how to make "imagination" conform to physical laws? NVIDIA's concept of "Physical AI" is injecting a "Newton's Laws Engine" into world models, enabling virtual simulations to transcend "fantasy" and possess practical guiding significance.
The neural PDE hybrid architecture is a key technology. By approximating fluid mechanics equations using Fourier Neural Operators (FNO), the model can calculate physical phenomena in real-time, such as "the trajectory of tire splash in the rain" and "the influence of crosswind on vehicle attitude." In test scenarios, the prediction error for "braking distance on wet roads" was reduced from 30% to within 5% with this technology.
The physical consistency loss function acts like a strict physics teacher. When the model "imagines" a scenario like "a 2-ton SUV laterally translating 5 meters in 0.2 seconds," which violates the law of inertia, it is severely penalized. Through millions of similar corrections, world models gradually learn to "keep their feet on the ground" – automatically adhering to physical laws in their imagination.
The multi-granularity token physics engine takes it a step further by decomposing the world into tokens with different physical properties such as rigid bodies, deformable bodies, and fluids. When simulating a scenario like "a mattress falling from the car in front," the model simultaneously calculates the rigid body motion trajectory of the mattress and the thrust of the airflow field, ultimately generating an aerodynamically compliant drifting path. This refined modeling improves prediction accuracy by over 40%.
The combined effect of these technologies endows autonomous driving with "counterfactual reasoning" ability – precisely the core competitiveness of human experienced drivers. When encountering unexpected situations, the system can simulate multiple possibilities such as "collision if not slowing down" and "rollover if swerving sharply" within milliseconds, ultimately choosing the optimal solution. Traditional systems can only "react afterwards," while world models can "foresee the future." Mushroom Auto's MogoMind has practical applications in this regard, with its real-time road risk warning function alerting drivers to the risk of water accumulation on the road ahead 500 meters in advance during heavy rain, a typical case of the combination of physical law modeling and real-time reasoning.
Three-Stage Leap for World Models to Land
For world models to transition from theory to mass production, they must overcome the three major hurdles of "data, computing power, and safety." The industry has formed a clear roadmap for implementation and is steadily advancing along the path of "offline enhancement - online learning - end-to-end control."
The "offline data augmentation" phase, initiated in the second half of 2024, has already demonstrated practical value. Leading domestic automakers are using world models to generate videos of extreme scenarios such as "pedestrians crossing in heavy rain" and "obstacles spilled from trucks" for training existing perception systems. Measured data shows that the false alarm rate for such corner cases has dropped by 27%, equivalent to giving the autonomous driving system a "vaccine."
2025 will enter the "closed-loop shadow mode" phase. Lightweight Memory models will be embedded in mass-produced vehicles to "envision" road conditions for the next 2 seconds at a frequency of 5 times per second. When the "imagination" deviates from the actual plan, the data will be transmitted back to the cloud. This crowdsourced learning mode of "dreaming while driving" allows world models to continuously accumulate experience through daily commutes, similar to human drivers. Mushroom Auto's holographic digital twin intersections deployed in Tongxiang provide a real data foundation for online learning of world models by collecting traffic dynamics within a 300-meter radius of intersections in real-time.
The "end-to-end physical VLA" phase in 2026-2027 will achieve a qualitative leap. When onboard computing power exceeds 500 TOPS and algorithm latency drops below 10 milliseconds, the V-M-C full link will directly take over driving decisions. By then, vehicles will no longer distinguish between "perception, prediction, planning" but will "see the whole picture at a glance" like experienced drivers – automatically slowing down when seeing children coming out of school and changing lanes in advance when detecting abnormal road conditions. NVIDIA's Thor chip is already prepared for this hardware-wise, with its 200 GB/s shared memory specifically designed for the KV cache of the Memory module, efficiently storing and retrieving historical trajectory data. This "hardware-software collaboration" architecture makes the onboard deployment of world models go from "impossible" to "achievable."
"Growing Pains" of World Models
The development of world models has not been smooth sailing and is facing multiple challenges such as "data hunger," "computing power black hole," and "safety ethics." The solutions to these "growing pains" will determine the speed and depth of technology implementation.
The data bottleneck is the most pressing issue. Training physical-level world models requires video data labeled with "speed, mass, friction coefficient," etc., which is currently only held by giants like Waymo and Tesla. The open-source community is attempting to replicate the "ImageNet moment" – the Tsinghua University MARS dataset has opened up 2000 hours of driving clips with 6D poses, providing an entry ticket for small and medium-sized enterprises.
The high cost of computing power is also daunting. Training a world model with 1 billion parameters requires 1000 A100 cards running for 3 weeks, costing over a million dollars. However, technological innovations such as mixed-precision training and MoE architecture have reduced computing power requirements by 4 times; 8-bit quantized inference further controls onboard power consumption at 25 watts, paving the way for mass production.
The controversy over safety and interpretability touches on deeper trust issues. When the model's "imagination" does not match reality, how to define responsibility? The industry consensus is to adopt a "conservative strategy + co-driving" approach: when the predicted collision probability exceeds 3%, the system automatically degrades to assisted driving, reminding humans to take over. This "leave room" design builds a safety defense before technology is perfected.
The discussion of ethical boundaries carries a more philosophical significance. If a model "runs over" a digital pedestrian during virtual training, will it develop a preference for violence? The "Digital Twin Sandbox" developed by MIT is attempting to address this issue by rehearsing extreme scenarios such as the "Trolley Problem" in a simulated environment, ensuring the model's moral bottom line through value alignment algorithms.
Redefining Intelligence through World Model Reconstruction
Autonomous driving is merely the first battleground for world models. When AI can accurately simulate physical laws and deduce causal chains in the virtual world, its impact will radiate across various fields such as robotics, the metaverse, and smart cities.
In household service scenarios, robots equipped with world models can anticipate that "knocking over a vase will break it," thereby adjusting the magnitude of their movements. In industrial production, systems can simulate in advance the "thermal deformation of a robotic arm grasping high-temperature parts," preventing accidents. The essence of these capabilities lies in the evolution of AI from a "tool executor" to a "scene understander."
A more profound impact lies in the redefinition of "intelligence." From CNN's "recognition" to Transformer's "association," and now to world models' "imagination," AI is continuously breaking through along the evolutionary path of human cognition. When machines can "rehearse the future in their minds" like humans, the boundaries of intelligence will be completely rewritten.
Perhaps one day in five years, when your car plans a "zero red light" route three intersections in advance, or when a robot proactively helps you steady a coffee cup about to tip over, we will suddenly realize that world models bring not just technological advancements, but a cognitive revolution on "how machines understand the world."
-
![]()
Laying Off Hundreds of Thousands: Can European Automakers Triumph?
-
![]()
Seres: Navigating Beyond the 'Realm'
-
![]()
iFLYTEK Anticipates RMB 200 Million Loss, Embracing 'Subtraction' and 'Addition': Abandoning Low-Margin Businesses and Betting on AI's Future
-
![]()
ByteDance’s ‘Most Loyal’ U.S. Investor Exits, Notching 15,000-Fold Returns
-
![]()
DeepSeek’s Liang Wenfeng Becomes World’s Wealthiest in AI, Net Worth Skyrockets to $36 Billion
-
![]()
How Can Embodied AI Overcome the Data Challenge of 'Being Able to Work'? Solutions from Five Leading Players
-
![]()
Half-Year Pre-Tax Loss Hits 4.5 Billion, Full-Year Net Cash Outflow Reaches 16.2 Billion! GAC Incurs 8,000 Yuan Loss per Vehicle Sold
-
![]()
In a Bid to Propel Towards a $10 Billion IPO, Jieyue Xingchen Weaves a Hardware Fairy Tale: A 'Chinese Version of Apple + OpenAI'?







