Google's Embodied AI VLA Model RT-H: Revolutionizing Robotics with Language-based Action Hierarchy
 07/10 2025
07/10 2025
 533
533
In March 2024, Google DeepMind unveiled the end-to-end framework RT-H, a robot Transformer with an action hierarchy that leverages language motion as an intermediary between high-level task descriptions and low-level actions, effectively structuring actions through linguistic constructs.
So, what exactly is Language Motion, and what benefits does it bring to constructing an action hierarchy?
Language Motion represents a semantic unit that delineates robot behavior in natural language. Serving as an intermediary abstraction layer between high-level tasks and low-level robotic actions, it generates interpretable action sequences by breaking down task intentions, preserving the modularity of language and human intervention, without directly controlling robot action execution.
For instance, the task "picking up a soda can" can be decomposed into more granular behaviors such as "moving the arm forward," "grasping the can," and "moving the arm upward." These granular behaviors are referred to as Language Motions.
Advantages of Constructing an Action Hierarchy:
(1) Efficient Cross-task Data Sharing at the Language Motion Level
Language Motions' combinatorial generalization capabilities significantly enhance the utilization of multi-task datasets. For example, while "pouring the contents of a cup" and "picking up a soda can" have distinct task semantics, the language motion sequence before picking up the object is identical ("approach object → locate grasp → close gripper"), enabling cross-task reuse at the action level.
(2) Language Motion as an Intelligent Primitive for Dynamic Scene Adaptation
Language Motion is not static but dynamically generated based on the current task context and visual observations. For example, the phrase "move the robotic arm forward" does not specify speed and direction vectors; these parameters are interpreted dynamically based on task goals (e.g., "avoid fragile objects") and environmental states (obstacle positions).

RT-H Action Hierarchy Architecture
In the figure above, given a task described in language, such as "close the pistachio jar," and a scene image, RT-H employs a visual language model (VLM) to predict Language Motions like "move the arm forward" and "rotate the arm to the right." Based on these Language Motions, it then predicts specific execution actions (Robot Action) for the robot.
This action hierarchy enables the model to learn tasks with vastly different language descriptions but shared structures. Compared to RT-2, which directly maps tasks to actions, these Language Motions facilitate better data sharing across diverse multi-task datasets.
Moreover, this hierarchy allows humans to selectively provide Language Motion corrections to the robot, preventing task failure, and subsequently using these new Language Motions to predict improved actions. After human intervention, RT-H continues predicting Language Motions as before.
However, as tasks become more semantically diverse (e.g., "picking up a soda can" and "pouring the contents of a cup"), data sharing between tasks becomes more challenging, and learning the mapping from high-level tasks to specific action instructions requires substantial demonstration data.
To bridge this gap, DeepMind's solution equips robots with the ability to 'semantize actions'—using atomic action phrases (like "move the robotic arm forward" or "close the gripper") to describe low-level movements. By using Language Motion prediction as an intermediary between high-level tasks and low-level execution, the policy model learns the shared low-level motion structures among seemingly disparate tasks. Critically, policies based on Language Motion conditions can be corrected in real-time during execution through human-specified semantic instructions.
I. RT-H: Constructing Action Hierarchy Using Language
RT-H's reasoning process comprises two key stages:
1) Language Motion Query: Based on visual observations and high-level task descriptions, RT-H predicts the current Language Motion, enabling fine-grained reasoning about task execution.
2) Robot Action Query: Using visual observations, task descriptions, and the inferred Language Motion, RT-H jointly predicts the current specific execution action, where the Language Motion provides crucial contextual supplementation for accurate action prediction.
RT-H employs a visual language model (VLM) as its backbone network and follows RT-2's training procedure. Similar to RT-2, through training on internet-scale data, the model accesses vast prior knowledge in natural language processing and image understanding.
To integrate this prior knowledge into each level of the action hierarchy, RT-H uses a single VLM to simultaneously learn Language Motion queries and Robot Action queries.
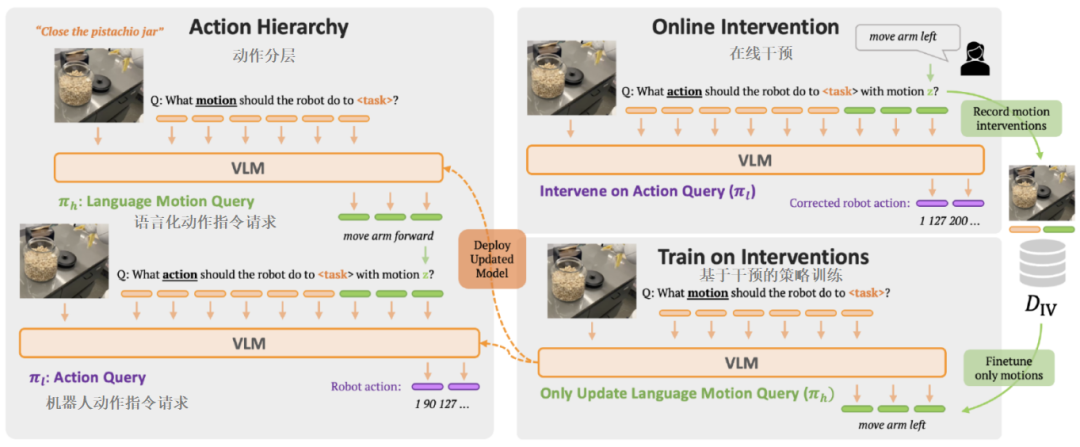
RT-H's Reasoning Process
Left side of the figure:
RT-H constructs a hierarchical policy learning architecture using language, splitting action prediction into Language Motion queries (π) and Robot Action queries (π). Where:
π: Predicts fine-grained Language Motions (e.g., "move the arm forward") based on image tokens and task description tokens.
π: Decodes the Language Motion into specific robot action instructions, combining the visual context of the scene.
Right side of the figure:
Users can directly intervene in Robot Action queries, providing Language Motion corrections for robot behavior, such as changing "move the arm forward" to "move the arm to the left." To learn from these corrections, only the Language Motion query needs updating with the newly annotated Language Motion correction. Subsequently, the updated model is redeployed into the action hierarchy.
RT-H learns to predict Language Motion queries and Robot Action queries in an end-to-end manner, enabling corrections in the Language Motion space and efficient learning from these corrections.
When the learned policy struggles to execute a task successfully, Language Motions come into play again: they provide an intuitive interface for online human corrections, tied to specific scenarios. Policies trained on Language Motions naturally follow human low-level correction instructions and complete tasks successfully with correction data. Furthermore, the policy can be trained on language correction data, further enhancing performance.
1. RT-H Model Training
RT-H uses a single VLM pre-trained jointly on multi-modal internet data to learn the high-level task policy π and the low-level robot control policy π.
RT-H instantiates the VLM using the same PaLI-X 55B architecture as RT-2. This model processes images into image tokens using a ViT encoder, jointly processed by an encoder-decoder Transformer alongside natural language instruction tokens to output discrete action tokens.
The generation of these action tokens follows RT-2's discretization mechanism: each action dimension is discretized into 256 bins, encoded as integer values. Each action includes the position/axis-angle rotation changes of the end effector, gripper opening/closing instructions, and a task termination flag.
Subsequently, RT-H uses the same PaLI-X training mixture data as RT-2 for joint training, starting from a pre-trained checkpoint. During this process, the visual Transformer (ViT) encoder is frozen. RT-H replaces Robot Action queries in RT-2 with Language Motion queries and Robot Action queries at the same sampling rate. Using a single model simplifies training and allows both queries to benefit from the extensive prior knowledge embedded in the PaLI-X data.
2. Extraction of Language Motions
To extract reliable Language Motions at each timestep in each clip cost-effectively, DeepMind developed an automatic annotation scheme relying on the robot's proprioceptive information.
First, each dimension of the robot's end effector pose change is associated with a spatial dimension (e.g., the z-axis of position change corresponds to up-down direction). After processing all 9 action dimensions, the robot's primary spatial motions are determined, such as "arm moving up and to the right," "closing the gripper," "arm rotating counterclockwise," or "base turning to the left." Then, dimensions below a "small motion" threshold are filtered out, and motions are combined by motion magnitude.
For example, if the robot is primarily moving its arm forward while starting to close its gripper, researchers extract the Language Motion "move the arm forward and close the gripper." This compositionality allows extracting over 2,500 Language Motions from a simple set of known actions.
Since these Language Motions are derived directly from actions, they have strong predictive power for actions when executing Robot Action queries in RT-H.
However, there's a fundamental trade-off in choosing the abstraction level of Language Motions: finer granularity makes Language Motion prediction more challenging but provides stronger guidance for Robot Action queries, and vice versa.
II. RT-H: Reasoning and Correction
During testing, RT-H first runs the Language Motion query (π) to derive a Language Motion sequence, input into the Robot Action query (π) to generate specific execution action parameters.
Since both queries must be executed sequentially at each timestep, this doubles the reasoning time. While minimal for smaller models, for RT-H's large 55B-parameter model, it leads to request processing delays.
To address this, Google DeepMind proposes two Language Motion reasoning modes:
(1) Asynchronous Query: Only train the Language Motion query (π) in RT-H to predict the next step action. During testing, the Language Motion from the previous timestep executes the current Robot Action query, while the next timestep's Language Motion is predicted in parallel. This achieves nearly the same request latency as RT-2 through batched queries.
(2) Fixed Frequency: Execute the Language Motion query every H steps to distribute delay pressure.
In experiments, DeepMind chose the asynchronous query scheme because Language Motions often need precise timing changes and cannot adapt to fixed frequency constraints.
Conclusion
RT-H maps language-described tasks to Language Motions through training and uses these inferred Language Motions to predict specific action instructions. Its advantages include:
(1) Learning Shared Structures Across Tasks: Facilitates efficient integration of multi-task datasets by capturing commonalities in task structures among disparate tasks, significantly improving cross-task data reuse and enabling efficient absorption of large-scale multi-task datasets.
(2) Supporting Scene- and Task-Context-Adapted Language Motion Corrections: Allows humans to adjust underlying execution strategies in real-time through semantic instructions while maintaining task goals, enabling dynamic behavior optimization.
Experiments demonstrate that the RT-H model efficiently utilizes multi-task datasets via this language-action hierarchy, learning more robust and adaptable strategies. The study also found that this strategy not only responds to language instruction interventions but continuously learns from them, outperforming methods based on teleoperation demonstration interventions.
References:
Paper Title: RT-H: Action Hierarchies Using Language
Paper URL: https://arxiv.org/pdf/2403.01823
-
![]()
Internet Valuation Logic Shifts: From Scale Narrative to Profit Accountability
-
VOYAH Struggles to Find Its Niche in the Competitive Auto Market
-
![]()
Maxwell Technologies Gains Indirect Stake in Precision Optics via New Venture
-
![]()
Raising 1.8 Billion! This Domestic Optical Inspection 'Little Giant' is Going Public
-
China's AI 'Normandy Moment': The Explicit and Implicit Threads of BATL
-
![]()
Starting at 4999 Yuan! Nubia RedMagic Gaming Tablet 5 Pro Review: Impressive Performance, But Hefty Price Tag
-
![]()
ByteDance Initiates First Major Management Reform
-
![]()
AI is Quietly Destroying a Trillion-Dollar Industry