The Past, Present, and Future of End-to-End Autonomous Driving: Both VLA and WM World Models Demand a World Engine
 09/10 2025
09/10 2025
 781
781
At the 2025 CVPR Autonomous Driving Workshop, Li Hongyang from the University of Hong Kong delivered an insightful opening speech titled "End-to-End Methods for Autonomous Driving: Current Status and Future Prospects."
In his speech, Li provided a clear definition of end-to-end systems, delved into their historical evolution and challenges, and culminated with the introduction of the "World Engine" concept. He also discussed its latest advancements, including three specific projects, and highlighted the key challenges in the field.
Drawing on Li Hongyang's speech and the current landscape of autonomous driving development and applications, this article offers conceptual summaries. Combining his insights on the two branches in the "End-to-End 1.5 Era," we boldly propose conceptual definitions for the current VLA and WM approaches, ultimately echoing Li Hongyang's core message: all end-to-end systems necessitate a world engine.
Definition of End-to-End Autonomous Driving
End-to-end autonomous driving is defined as the process of "learning a single model that directly maps raw sensor inputs to driving scenarios and outputs control commands." It replaces the traditional modular pipelines with a unified function.
Here, "function" implies that given observations (such as images, point clouds, or vehicle information) or goals, the model directly outputs control commands (like steering, braking, or acceleration).
The training process is straightforward, leveraging supervised learning (SL) with extensive annotations, imitation learning (IL), or reinforcement learning (RL) with designed rewards. 
Thus, end-to-end represents the broadest concept in autonomous driving algorithms, encompassing both current VLA and world model approaches.
Development Roadmap for End-to-End Autonomous Driving
The journey began over 20 years ago with simple black-and-white image inputs.
Over the years, numerous methods have emerged, categorized into conditional imitation learning, generalization, Andrew Gigard's team's interpretable networks (utilizing multimodality), and pre-training efforts such as PPJL, Soft ACT, and ACO.
Recently, explicit methods with clearly designed modules have surfaced, incorporating object tracking, mapping, and motion planning, marking the era of modular end-to-end planning and foundation models. 
We are now at the tail end of the "1.5th generation" of end-to-end autonomous driving. Dubbed the "1.5th generation," we have entered the Foundation Models era and are addressing long-tail problems (corner cases). In the 1.5 end-to-end era, we have two distinct branches:
One branch involves diffusion or diffusion pipelines and world models, as seen in projects like Drive Dreamer, Cosmos Predict One, and navigation world models. Gaia 2, a video generation model, aims to facilitate safer assisted and automated driving. These models leverage multi-view images and diverse actions to predict various video types, generating realism and diversity. This branch can be summarized as the world model branch.
The other branch is grounded in large language models (LLMs). For instance, Java LM introduces a "sketch wiki" approach to better comprehend driving scenarios. Lingo Tool and earlier work like Job VRM, considered a very early effort in autonomous driving dual systems, leverage the higher accuracy of foundation models but suffer from higher latency. Thus, smaller models can predict most scenarios and collaborate with foundation models. This can be viewed as the current VLM/VLA branch. 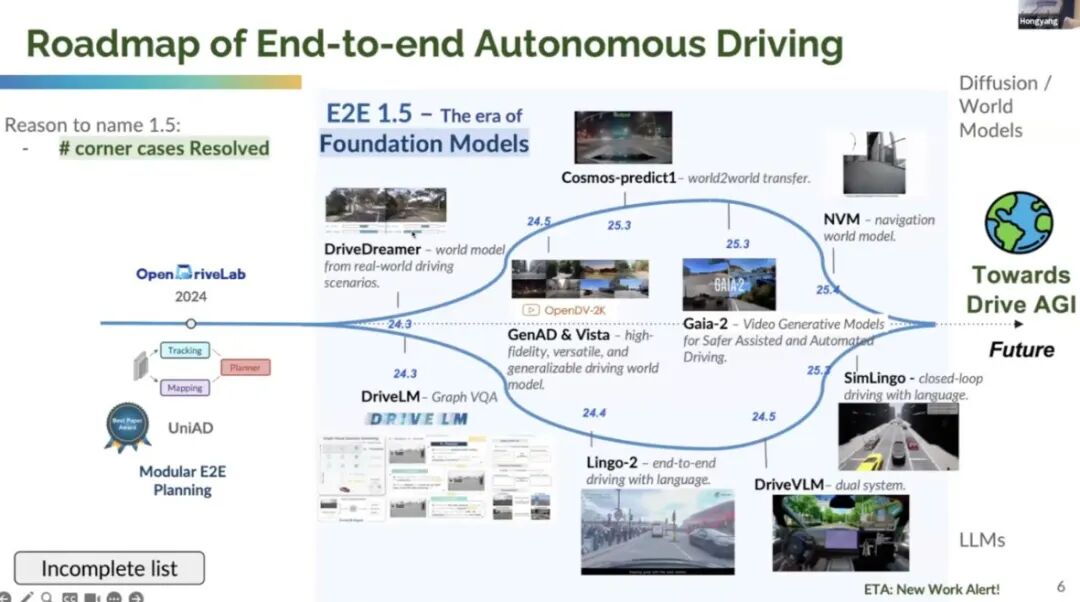
With these two methodologies, Li Hongyang believes end-to-end systems are transitioning into the second generation. Currently, autonomous driving research has entered its second phase, necessitating extensive production and engineering efforts.
With end-to-end architectures in place, the next step is to train models with vast amounts of data. The figure below illustrates a typical training and deployment pipeline, encompassing data collection (usually by expert drivers), training (on fixed logs and replay data), and evaluation and feedback from inference, followed by collecting more intervention and adverse data. 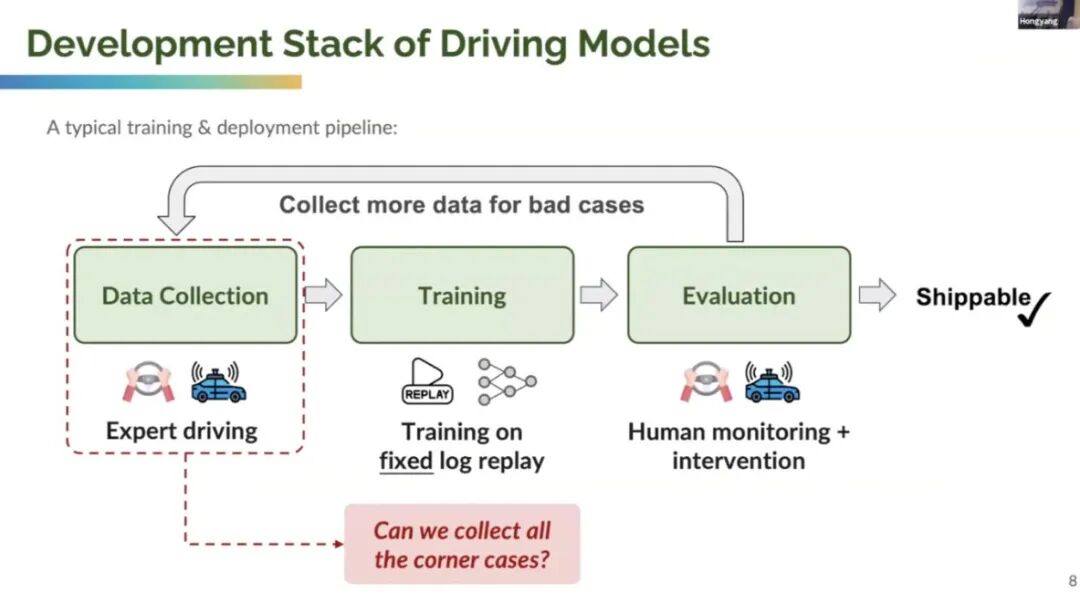
Challenges in Real-World Deployment
Can we collect all scenarios or extreme cases and ultimately translate them into L4 or L5 products?
Li Hongyang cited a website he favors—the Tesla FSD Tracker—which gathers extensive customer data from North American cities. The website's real-time graph displays the annual changes in Tesla FSD's "miles per intervention" (MPI) metric across different versions, indicating an increase in MPI—a promising sign that more data can bring end-to-end models closer to full autonomy.
However, challenges persist.
On the right side of the figure, the X-axis represents normal driving and safety-critical or near-accident events. As driving mileage accumulates, accidents may occur.
The Y-axis features two curves: the black curve represents the probability of hazardous situations per mile, and the red curve represents deployment costs. As most perception problems are resolved, the probability of encountering challenging cases diminishes. However, deployment costs skyrocket, requiring a massive fleet to collect all hazardous cases.
The remaining 20% of long-tail problems demand vast amounts of data because valuable extreme cases become increasingly rare, and collecting hazardous driving data may endanger lives. 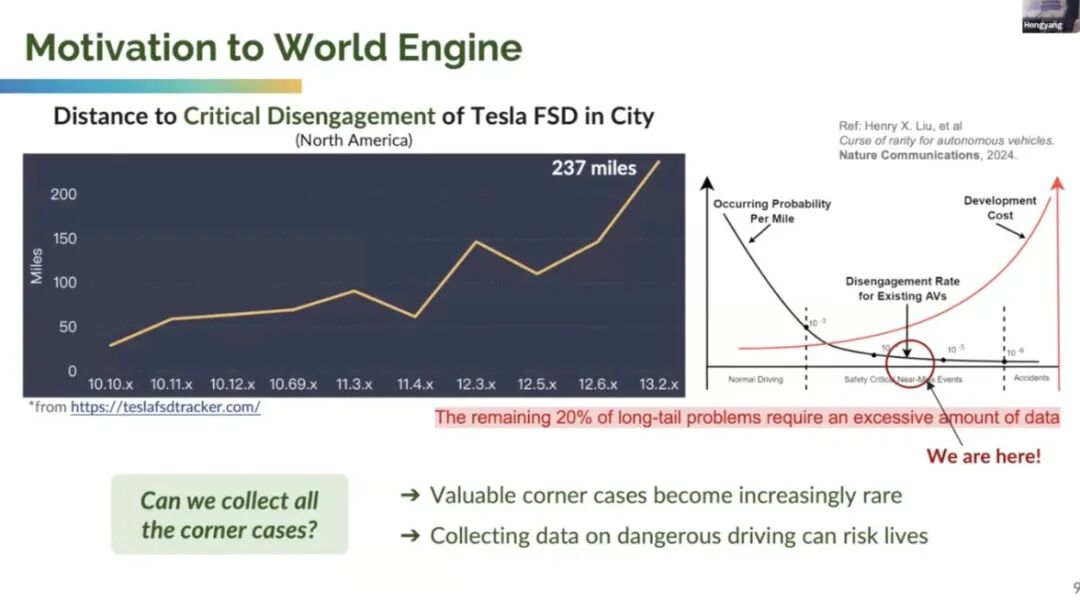
Thus, Li Hongyang proposed the "World Engine" concept to address these challenges.
Its core idea is to learn from human expert driving. The strategy remains an arbitrary end-to-end planning algorithm, such as UniAD or V-AD. By interacting with the environment (termed world models or environmental interaction), given current prompts or actions (e.g., turning right), we aim to learn from failures and adapt the current end-to-end planner to production environments. The key challenge is generating these valuable extreme cases, primarily composed of two parts:
Extreme scenario generation (creating safety-critical scenarios from source scenes in raw data), significantly reducing costs without a massive fleet.
This involves behavior-level modeling of the model, meaning that given a trajectory, the subsequent behavior between the environment and the self-vehicle must be modeled. Then, once the trajectory is established, rendering these elements is necessary, which is known as generating or rendering videos, i.e., sensor simulation. 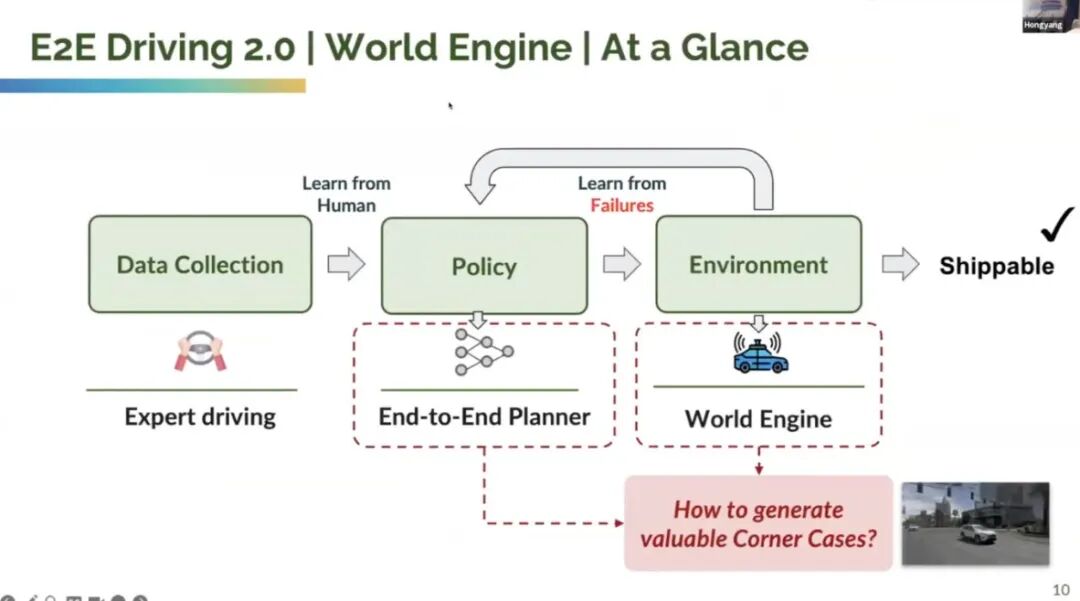
With such a data engine, numerous extreme scenarios can be generated for training.
Li Hongyang also proposed an algorithm engine, not depicted here as it is still under development.
Together, the data and algorithm engines form the entire pipeline of the "World Engine," which can then be utilized to improve and train any end-to-end algorithm, facilitating autonomous driving.
Final Thoughts
Recently, VLA and WM world models have garnered significant attention. Honestly, from a conceptual standpoint, WM is a broader term that can encompass more ideas, but it also lends itself to more ambiguity.
Jack believes VLA is currently a more practical and visible approach, while WM should be the ultimate goal. However, many domestic companies proposing WM seem more interested in occupying linguistic and user mindshare high ground, often exaggerating the capabilities of their solutions.
References and Images
*Unauthorized reproduction or excerpting is strictly prohibited.
-
![]()
Enflame Tech's IPO Journey: Navigating Over 5.9 Billion Yuan in Losses and Soaring Debt in Q1 This Year
-
![]()
Trillion-Yuan Giant Li Shufu 'Streamlines': Could Levc Be the Casualty?
-
![]()
AI Competes for Electricity and Generates Power in the Gobi Desert
-
![]()
The First Batch of Victims of the AI Bubble: Programmers
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'






