Revealing Xiaopeng's 'Foundation Model' and 'VLA Large Model' for Autonomous Driving
 09/12 2025
09/12 2025
 830
830
At the 2025 CVPR Autonomous Driving Workshop, Mr. Liu Xianming from Xiaopeng Motors delivered a speech titled 'Scaling up Autonomous Driving via Large Foundation Models'.
Previously, there was a lot of information online about Xiaopeng's VLA speech at CVPR, but those were promotional posts intended to be seen. This article delves deeply into Xiaopeng's methodology for assisted/autonomous driving 'foundation models' and VLA large models based on Liu Xianming's speech content.
Introducing the Concept of a Foundation Model
At the beginning, Mr. Liu Xianming cited the three-stage concept of the software era proposed by Andrej Karpathy, the former AI Director of Tesla and researcher at OpenAI (for specifics, click on the content shared in the previous article 'Tesla's Former AI Leader Andrej Karpathy's Latest Speech on AI and LLM'), leading to the introduction of Xiaopeng's VLA foundation model concept.
The era of autonomous driving software 1.0 models was a decade ago when everyone was busy with scenarios like T-junctions, relying mainly on point clouds and cluster processing on CPUs to detect obstacles and writing numerous hard-coded heuristic rules for manipulation. In this context, the entire stack was defined by simple rules.
Around six or seven years ago, software 2.0 began. As detection and vision technologies matured, people started replacing perception and prediction parts with machine learning models. However, most of the stack still contained hard-coded rules.
Now, we are in the 3.0 era, known as 'AI models as software.' Autonomous driving can iterate software with data, converting the entire software into AI models and iterating based on a data-centric approach. 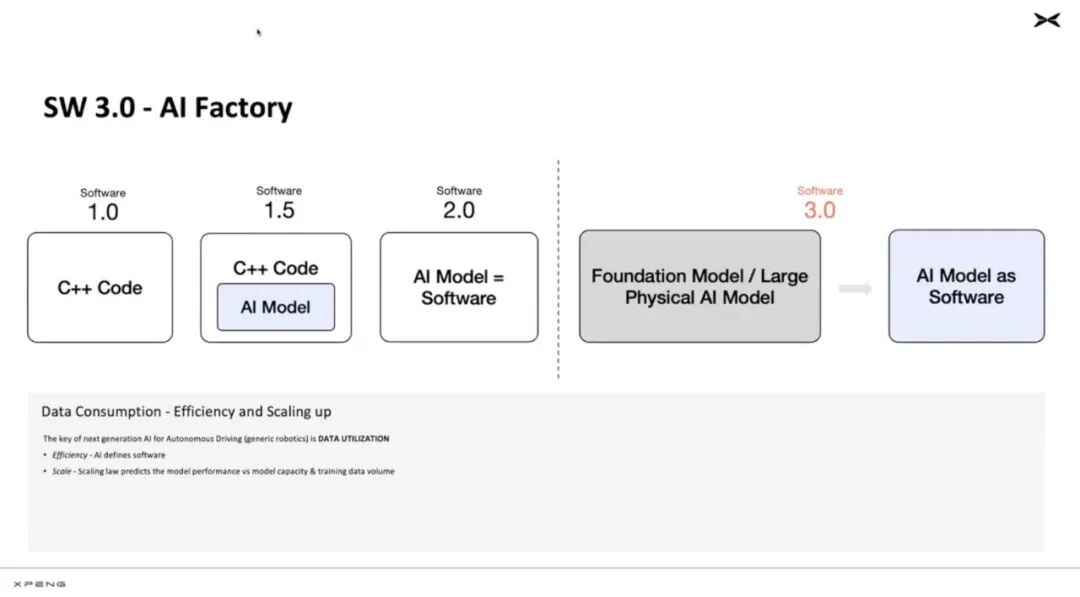
Liu Xianming stated that currently, Xiaopeng is in the stage of constructing the entire autonomous driving software stack as an end-to-end AI model for driving cars.
In the next stage, Xianming indicated that they need to explore future development based on the 'scaling law.' However, the scaling law requires a large amount of data, but Xiaopeng stated that for the autonomous driving field, they are not constrained by data as Xiaopeng can collect vast amounts of data daily from hundreds of thousands of real-world vehicles.
Therefore, Xiaopeng will use this data to train a very large visual model as a 'factory.' Once this model is available, it can be distilled to smaller hardware and deployed in vehicles.
Xiaopeng defines this prototype as 'Software 3.0.' The overall concept is that a foundation model built with big data can disregard prior knowledge and spatial issues in three-dimensional space, somewhat akin to the concept of a world model, and then this model can be deployed to the vehicle end.
Of course, this involves deep pruning, quantization, and distilling the foundation model to enable deployment on smaller vehicle-end hardware. This is Xiaopeng's vision for the next generation of autonomous driving.
Internal and External Loops for Achieving Autonomous Driving
After establishing the theoretical foundation of the foundation model, Xiaopeng created an 'internal loop' concept, creating training streams for each model to facilitate data expansion, followed by retraining and SFT (Supervised Fine-Tuning) to continuously enhance model performance. Finally, the foundation model is distilled, compressed into a smaller version, and deployed in cars. 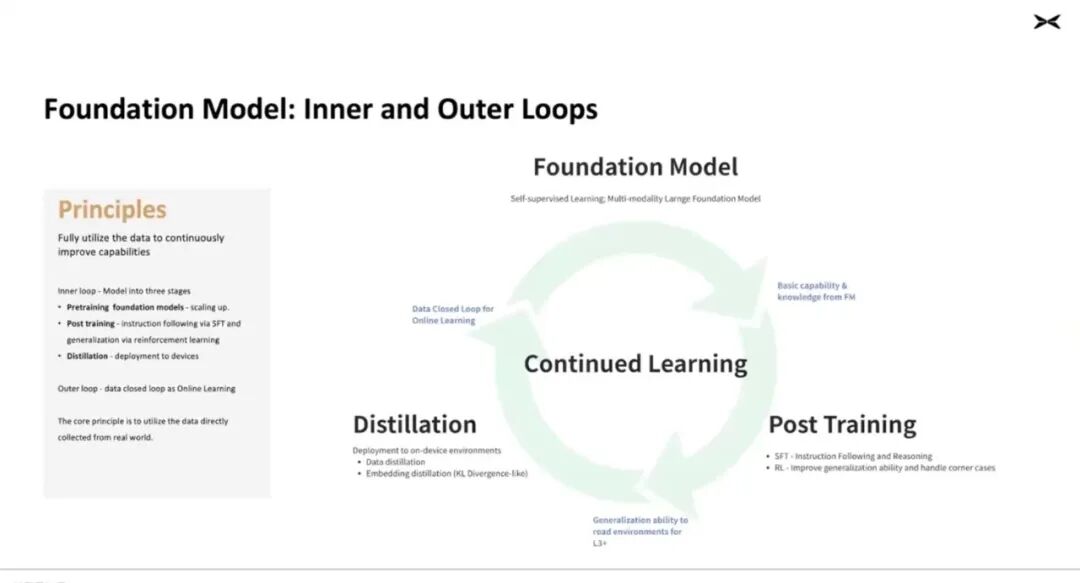
The 'external loop' refers to data-driven operations. Once the model is deployed on devices, hundreds of thousands of cars become data samplers in the real world, continuously sampling data for training.
This external loop involves continuous training based on returned data, or as some call it, 'co-training.' The process is repeated continuously until the performance is good enough to achieve Level 4 autonomous driving. 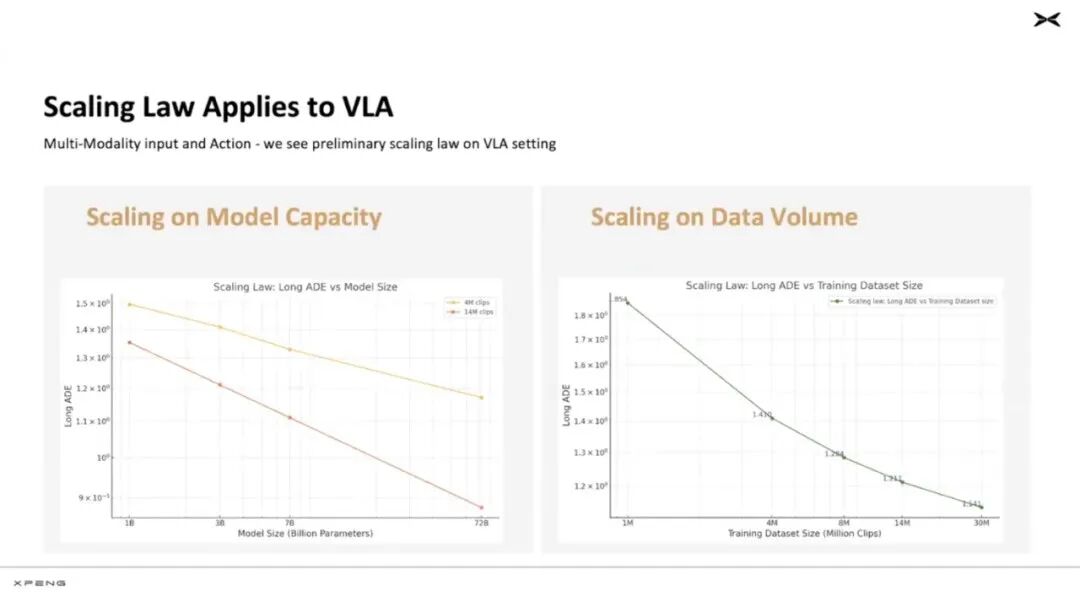
Recently, at IAA 2025 Munich Auto Show (for information on the 2025 Munich Auto Show, click on 'IAA 2025 Munich Auto Show: Chinese Automakers Go from 'Trade Exports' to 'Unstoppable''), He Xiaopeng also expressed the ambition to achieve mass production of Level 4 intelligent driving models by 2026, presumably based on this methodology.
Model Training Methods
Eagle-eyed friends may notice from the speech PPT that Xiaopeng was heading towards a VLA model architecture in the first half of the year. 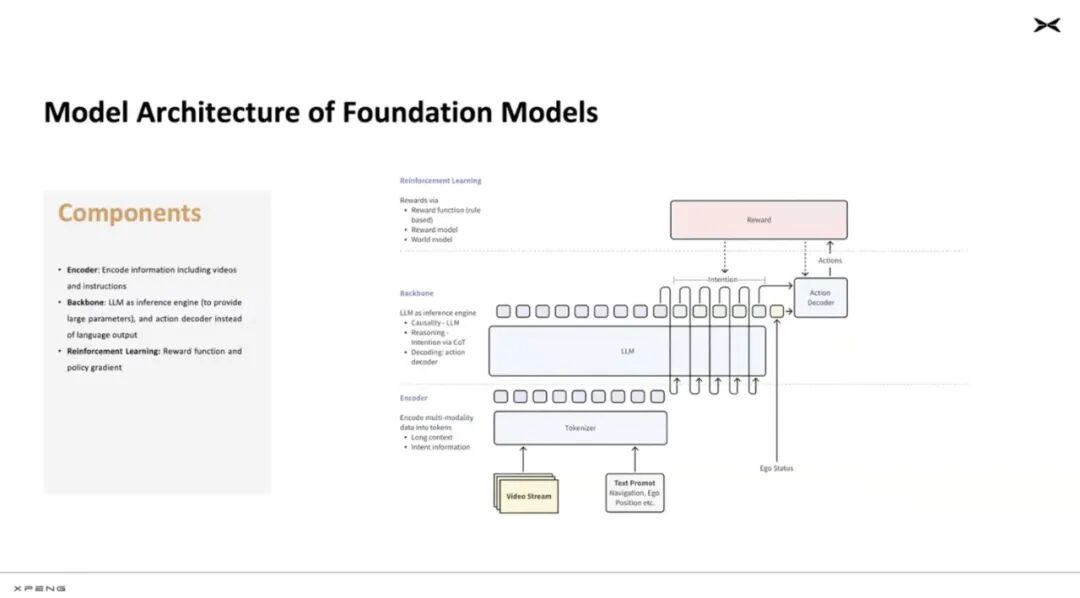
So, the training method for this model is as follows:
First, take a VLM model. It's clear in the industry that basically, this original VLM model is Alibaba's Qwen.
Then, based on this model, pre-train and align it using driving data organized by Xiaopeng, which is the pre-training of the visual model.
The following image shows Xiaopeng's pre-trained data categorized, revealing that traffic data is divided into:
Static traffic elements, such as roads
Dynamic traffic participants, like cars
Point-to-point trajectory data
Occupancy, presumably data used to train the Occ network
Traffic Light TSL, traffic signals
Traffic Flow TFL, vehicle flow information 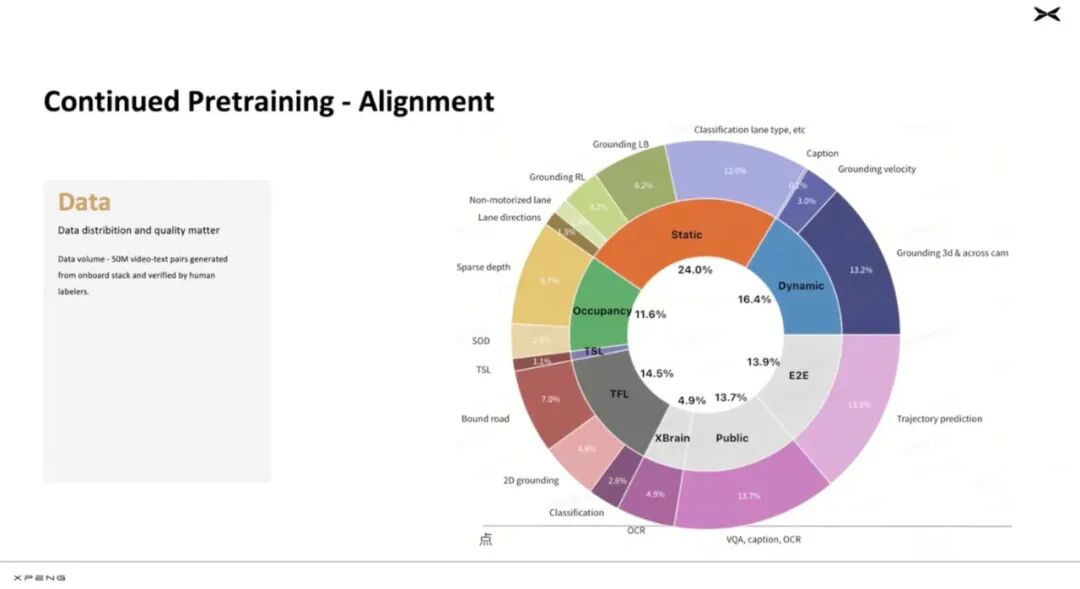
Below is an example of Traffic Flow TFL data, where image information essentially semantizes traffic information, meaning what this image represents in a traffic scenario. 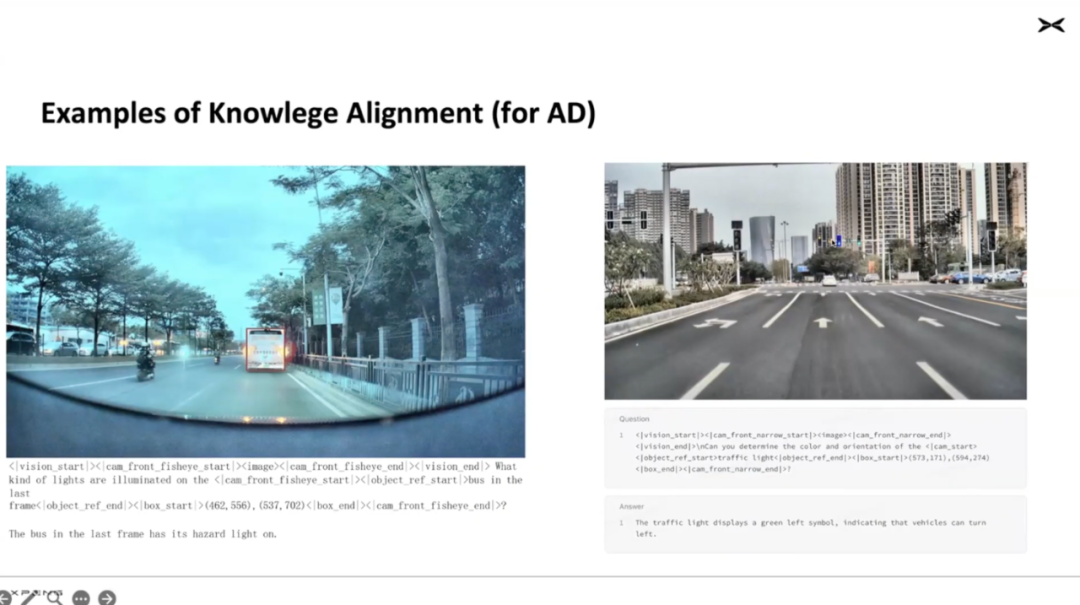
With an understanding of traffic flow, the next step is CoT (Chain-of-Thought), reasoning based on an understanding of the scenario flow. Xiaopeng took four steps:
Alignment, providing basic driving knowledge, such as stopping at red lights
CoT SFT (Supervised Training).
Reinforcement Learning CoT.
CoT SFT considering latency. 
The final point is that all thought chains ultimately result in output actions. Actions are not some form of language or text output but are described in the form of 'action tokens.' Xiaopeng decomposes actions into longitudinal and lateral actions, including acceleration, stopping, etc. 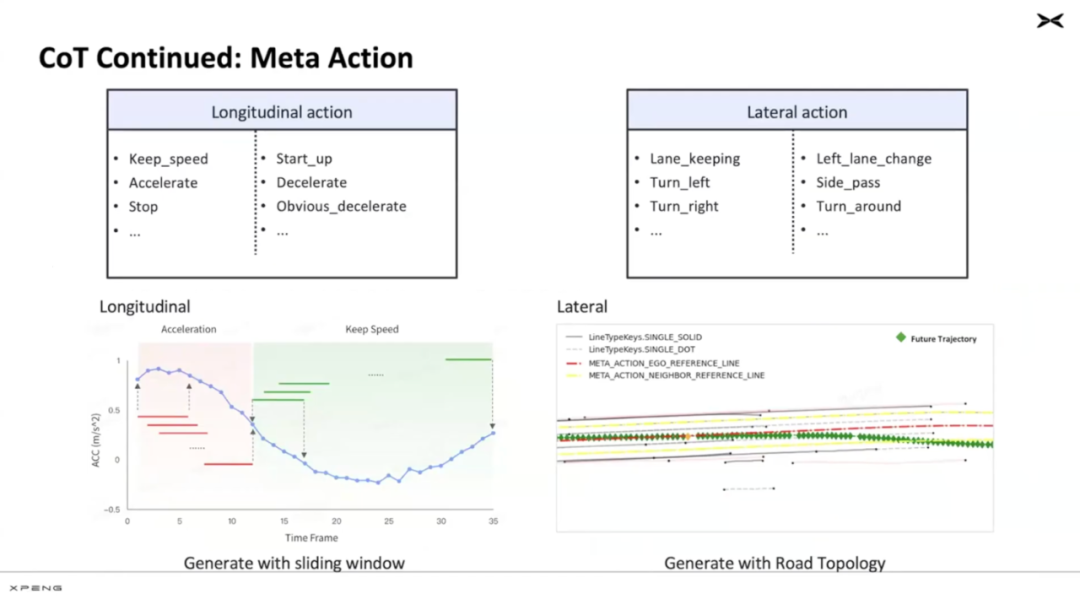
Ultimately, the VLM identifies the scene, reasons, and generates actions for vehicle movement.
Therefore, it can be considered that this pre-training is professional traffic training for a generic VLM, enabling the model to input views and output actions, training a VLA model usable for Xiaopeng's intelligent assisted driving.
The second part, after basic action training, involves Supervised Fine-Tuning (SFT). Because deep learning only handles statistical averages of data. However, driving involves many specialized instructions, such as navigation or performing very comfortable braking. Therefore, Xiaopeng models SFT as an 'instruction-following' task, organizing and filtering out good case data, and using this data for specialized instruction training. This part essentially outputs a usable VLA model. 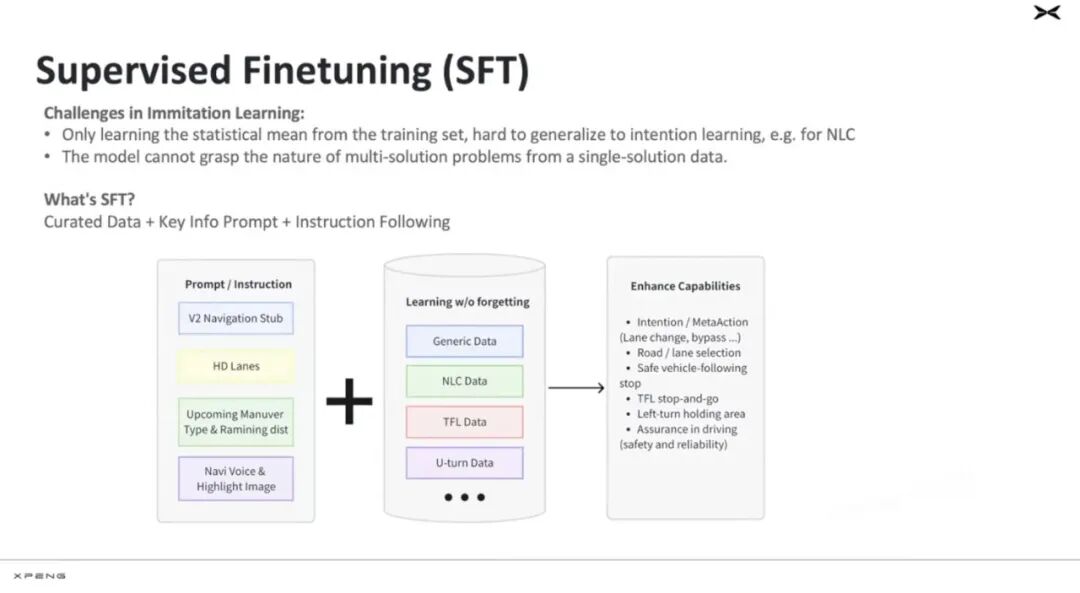
Following that is post-training, a fine-tuning function for instruction following or reflection. It mainly addresses long-tail cases, using reinforcement learning as the method. 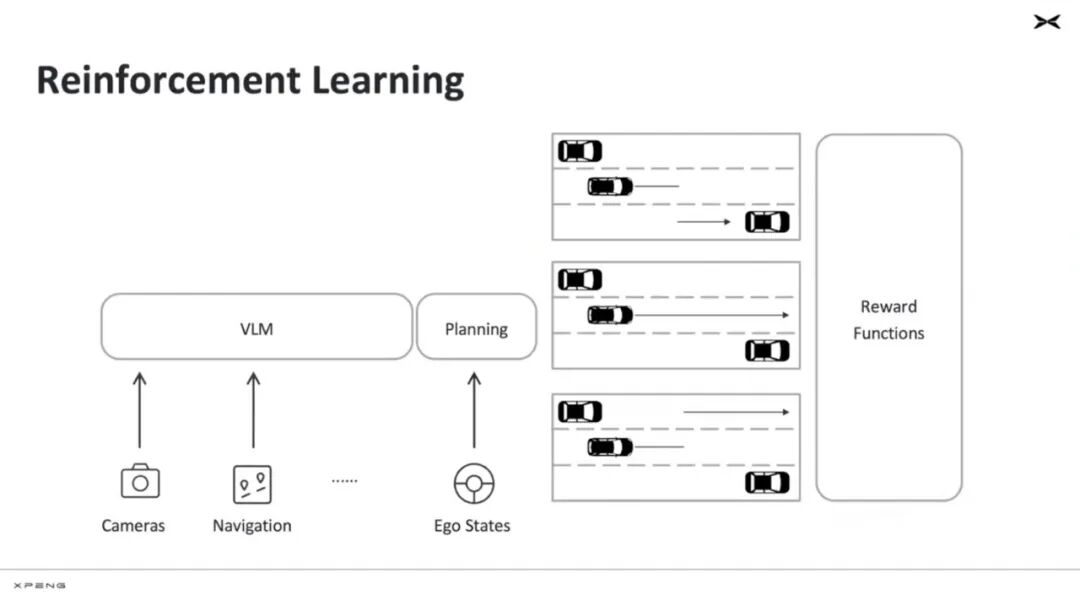
Reinforcement learning involves establishing a reward model and then rewarding it so that models follow the same actions. Ultimately, for autonomous driving, reinforcement learning makes driving safer. To drive more safely, Xiaopeng designed three rewards: safety, avoiding collisions; secondly, efficiency, avoiding stalls; and finally, compliance, adhering to traffic rules, such as traffic lights.
Ultimately, after going through three overall stages, from VLM alignment pre-training to VLM+actions and supervised fine-tuning to form a usable VLA, and finally, reward-based reinforcement learning to generate a usable VLA. 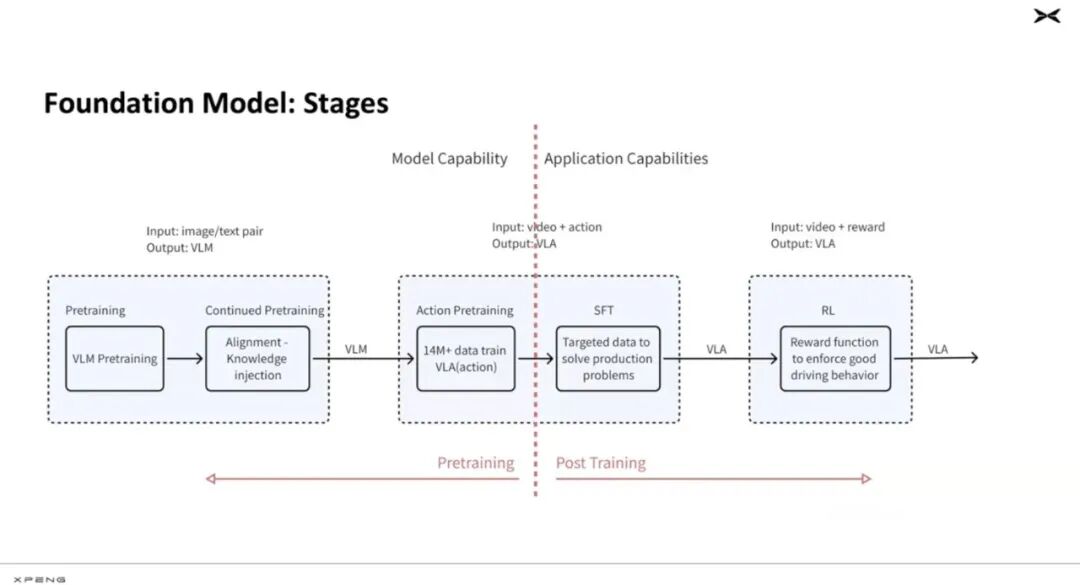
Conclusion
Xiaopeng's approach to assisted/autonomous driving is to build a VLA foundation model in the cloud, followed by distillation, pruning, and fine-tuning training for deployment to the vehicle end.
In fact, this paper reveals two approaches: one is the idea of distilling the foundation model for vehicle deployment. This approach seems quite ingenious, as it can accelerate development and enable rapid deployment across different computational platforms. However, the prerequisite is having significant computational power and high-quality data.
The other approach is VLA. The concept of VLA has truly become overused. From this article, it can be seen that VLA must initially have a mature foundation LLM as its base, and then it is trained for traffic driving behavior based on that.
In fact, these two approaches reveal that for the autonomous driving industry, the underlying algorithms and architectures are interconnected. The only factors that differentiate everyone are high-quality data, significant computational power, and the ability to productize and engineer powerful algorithms.
*Unauthorized reproduction and excerpting are strictly prohibited-
-
![]()
Enflame Tech's IPO Journey: Navigating Over 5.9 Billion Yuan in Losses and Soaring Debt in Q1 This Year
-
![]()
Trillion-Yuan Giant Li Shufu 'Streamlines': Could Levc Be the Casualty?
-
![]()
AI Competes for Electricity and Generates Power in the Gobi Desert
-
![]()
The First Batch of Victims of the AI Bubble: Programmers
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'






