Top Journal TPAMI 2025! One Model for All! The 'All-Rounder' of Multimodal Tracking, UM-ODTrack, Makes Its Debut
 11/10 2025
11/10 2025
 530
530
Interpretation: The AI-Generated Future 

Highlights
1. It provides the first universal video-level modality perception tracking model for the visual tracking field. UM-ODTrack only needs to be trained once and can then perform multi-task inference using the same architecture and parameters, including RGB-T/D/E tracking tasks.
2. For video-level association, two types of temporal token propagation attention mechanisms are introduced to compress the target's discriminative features into a token sequence. This token sequence serves as a prompt to guide inference in future frames, thereby avoiding complex online update strategies.
3. For multimodal perception, two novel gated perceivers are proposed, which can adaptively learn cross-modal latent representations, facilitating unified training and inference for multiple tasks in our model. 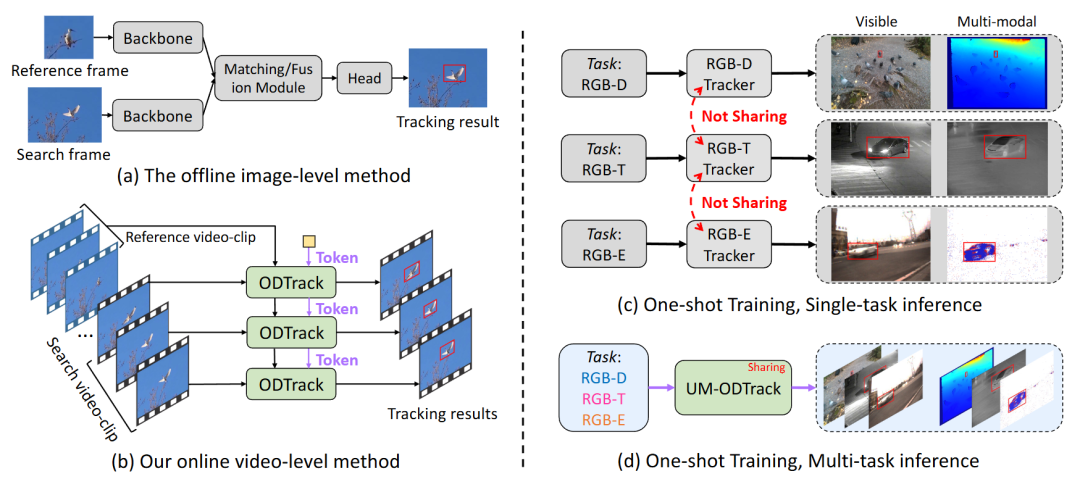
Figure 1. Comparison of Tracking Methods. (a) Offline image-level tracking method based on sparse sampling and image pair matching. (b) Online video-level tracking method based on video sequence sampling and temporal token propagation. (c) Multimodal tracking method based on single-training and single-task inference (i.e., one model for one task, one-to-one) [62], [64]-[66]. (d) Universal modality perception tracking model based on single-training and multi-task inference (i.e., one model for multiple tasks, one-to-many).
Summary Overview
Problems Addressed
1. Sampling Sparsity: Traditional trackers mainly adopt a sparse sampling strategy of 'image pairs' (one reference frame and one search frame), which fails to fully utilize the rich temporal context information in videos and makes it difficult to accurately analyze the dynamic motion states of targets.
2. Association Limitations: Traditional feature matching/fusion methods focus on the appearance similarity of targets and lack continuous, dense cross-frame associations. Even when existing methods introduce multiple frames, their spatio-temporal relationships are limited to the selected frame range and fail to achieve video-level information association.
3. Model Specificity: Existing multimodal tracking methods generally adopt a learning paradigm of 'one model for one task' (one-to-one). This leads to the need to train and maintain multiple independent models for different modality combinations (e.g., RGB-T, RGB-D), resulting in a heavy training burden and a lack of compatibility and generalization ability among models.
Proposed Solution
A universal video-level multimodal perception tracking model, UM-ODTrack, is proposed, with core innovations including:
1. Video-Level Sampling: Extending the model input from 'image pairs' to the 'video sequence' level, enabling the model to understand video content from a more global perspective.
2. Online Dense Temporal Token Learning: Redefining target tracking as a token sequence propagation task, two simple and effective online dense temporal token association mechanisms are designed to propagate the appearance and motion trajectory information of targets in a video stream in an autoregressive manner.
3. Modality-Scalable Perception: A universal modality perception tracking process is designed, which utilizes gated attention mechanisms to adaptively learn cross-modal representations through two novel gated perceivers.
One-Time Training Paradigm: Adopting a one-time training scheme to compress the learned latent representations of multiple modalities into the same set of model parameters, enabling a single model to support inference for multiple tracking tasks (RGB, RGB-T, RGB-D, RGB-E).
Applied Technologies
1. Video Sequence Modeling: Treating video sequences as continuous sentences and borrowing ideas from language modeling for contextual understanding.
2. Temporal Token Association Attention Mechanisms: Two mechanisms, namely concatenated temporal token attention and separated temporal token attention, are proposed for online propagation and association of temporal information.
3. Gated Attention Mechanisms: Applied in conditional gated perceivers and gated modality-scalable perceivers to adaptively fuse and learn cross-modal features.
4. One-Time/Unified Multi-Task Learning: Enabling a single model to learn a shared visual-semantic feature space through one-time training while respecting the heterogeneity of different tasks, achieving multi-task inference.
Achieved Effects
1. Performance Improvement: Extensive experiments have been conducted on seven visible light tracking benchmarks and five multimodal tracking benchmarks, and the results show that UM-ODTrack achieves the latest state-of-the-art (SOTA) performance.
2. Information Utilization Optimization: The purified token sequence can serve as a temporal prompt for subsequent video frame inference, guiding future inference using past information and achieving effective information transmission and utilization.
3. Model Efficiency and Generalization: The one-time training scheme not only reduces the training burden but also enhances the model's representational capability through parameter sharing and cross-task learning, achieving a paradigm shift from 'one-to-one' to 'one-to-many' and making the model more versatile and flexible.
Method
A. Architecture Design
UM-ODTrack, a universal video-level modality perception framework, supports various tracking tasks, including RGB, RGB+thermal imaging, RGB+depth, and RGB+event tracking.
Figures 2 and 3 below provide an overview of the UM-ODTrack framework for video-level multimodal tracking. The entire video is modeled as a continuous sequence, and the localization of target instances is decoded frame by frame in an autoregressive manner. First, a novel video sequence sampling strategy is proposed, specifically designed to meet the input requirements of video-level models (Principle 1: Video-Level Sampling). Then, a novel modality tokenizer is proposed to tokenize different modality sources in a shared encoding manner. Subsequently, to capture the spatio-temporal trajectory information of target instances in video sequences, two simple yet effective temporal token association attention mechanisms are introduced (Principle 2: Video-Level Association). In addition, two powerful gated perceivers are introduced to adaptively learn universal visual representations across modalities, thereby improving the model's generalization ability in different tracking scenarios (Principle 3: Modality Scalability).
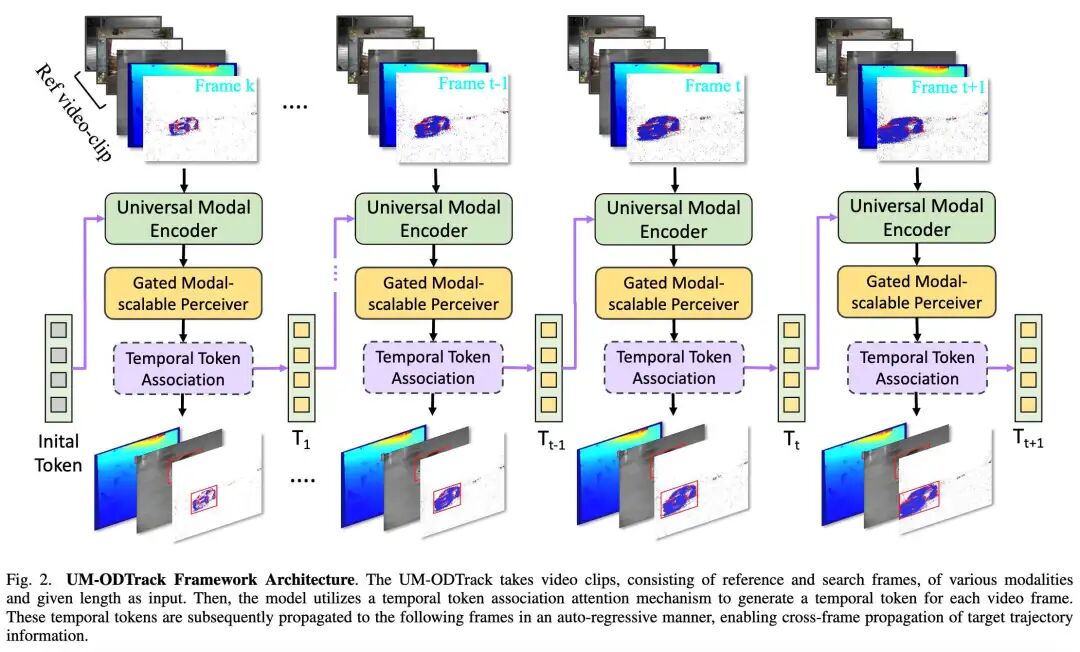
Based on the aforementioned modeling techniques, a universal modality perception tracking model will be obtained, which can simultaneously infer multiple sub-tracking tasks using the same model architecture and parameters. The following sections will provide detailed descriptions.
B. Formulation of Video-Level Multimodal Tracking
This paper focuses on constructing a universal video-level multimodal tracking framework. To fully understand the UM-ODTrack framework, it is necessary to describe the concept of video-level multimodal tracking. First, let's review the previously mainstream image pair matching tracking method. Given a pair of video frames, namely a reference frame and a search frame , the mainstream visual tracker is formulated as

where represents the predicted bounding box coordinates of the current search frame. If is a traditional convolutional siamese tracker, it will go through three stages, namely feature extraction, feature fusion, and bounding box prediction. If is a transformer tracker, it only contains a backbone network and a prediction head network, where the backbone network integrates the processes of feature extraction and fusion.
A transformer tracker receives a series of non-overlapping image patches (each with a resolution of ) as input. This means that a two-dimensional reference-search image pair needs to go through a patch embedding layer to generate multiple one-dimensional image token sequences , where is the token dimension, , and . Then, these one-dimensional image tokens are concatenated and loaded into a -layer transformer encoder for feature extraction and relationship modeling. Each transformer layer contains a multi-head attention mechanism and a multi-layer perceptron. Here, we formulate the forward process of the -th transformer layer as follows: 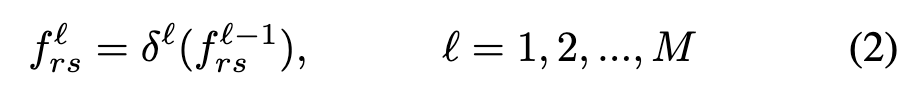
where represents the concatenated token sequence of the reference-search image pair generated by the -th transformer layer, and represents the token sequence generated by the current -th transformer layer.
Using the aforementioned modeling method, we can construct a concise and elegant tracker to achieve frame-by-frame tracking. However, this modeling method has two obvious drawbacks:
1. The constructed tracker only focuses on intra-frame target matching and lacks the ability to establish cross-frame associations, which is necessary for tracking objects across video streams.
2. The constructed tracker is limited to single-modality tracking scenarios and lacks the ability to quickly extend to multimodal tracking due to domain-specific knowledge bias. Therefore, these limitations hinder the research on video-level multimodal tracking algorithms.
In this work, we aim to alleviate these challenges and propose a new design paradigm for universal video-level modality perception tracking algorithms. First, we extend the input of the tracking framework from the image pair level to the video level for temporal modeling. Then, we introduce a temporal token sequence aiming to propagate the appearance, spatio-temporal position, and trajectory information of target instances in video sequences. Formally, we formulate video-level tracking as follows:
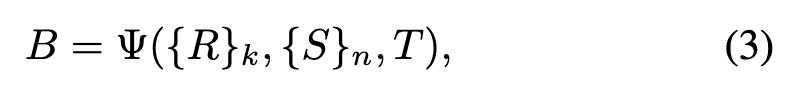
where represents an RGB reference frame sequence of length , and represents an RGB search frame sequence of length . With this setup, we construct a video-level tracking framework that receives video clips of arbitrary length to model the spatio-temporal trajectory relationships of target objects.
Furthermore, to enhance the universal modality perception capability of the video-level tracker, we extend it to the multimodal tracking domain. First, we extend the input from the single-modality range to the multimodal range. Then, we use a shared universal modality encoder consisting of an RGB encoder and a D/T/E encoder to extract and fuse RGB video clips and auxiliary video clips, respectively. Subsequently, two novel gated perceivers are designed to learn universal latent representations across modalities. It is defined as follows:
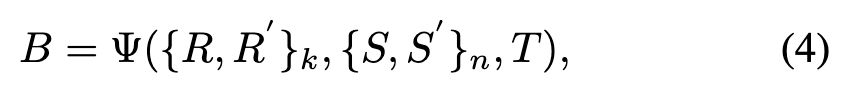
where represents a reference frame sequence of length from an auxiliary modality, and represents a search frame sequence of length from an auxiliary modality. is the temporal token from the auxiliary modality. We will describe the proposed core modules in more detail in the next section.
C. Video Sequence Sampling Strategy
Most existing trackers usually sample single-modality image pairs over a short time interval (e.g., 50, 100, or 200 frame intervals). However, this sampling method brings a potential limitation, as these trackers cannot capture the long-term motion changes of the tracked targets, thereby limiting the robustness of the tracking algorithm in long-term scenarios. At the same time, they cannot perceive the real-time state of targets from the perspective of multiple modalities. To obtain richer multimodal spatio-temporal trajectory information of target instances from long-term video sequences, we deviate from the traditional short-term image pair sampling method and propose a new video sequence sampling strategy. Specifically, during the training phase, we establish a larger sampling interval and randomly extract multiple video frames within this interval to form video clips of any modality and any length (, ). Although this sampling method may seem simple, it enables us to approximate the content of the entire video sequence. This is crucial for video-level multimodal tracking modeling.
D. Modality Tokenizer
Intuitively, considering the variability of input frames from different modalities (i.e., depth, thermal infrared, and events), the traditional approach is to design separate tokenizers for each modality. This allows different input frames to be converted into token vectors with the same sequence format. Instead, considering the potential shared semantic information among different modalities, we treat depth, thermal infrared, and event data as unified visual representations. We design a shared modality tokenizer to uniformly convert data from different modalities into the same one-dimensional sequence. For visual input containing multiple modality information such as depth, thermal infrared, and events, we adopt a single two-dimensional convolutional layer as a unified tokenizer. Subsequently, a transformer-based universal modality encoder is used to process these tokens.
E. Gated Perceivers
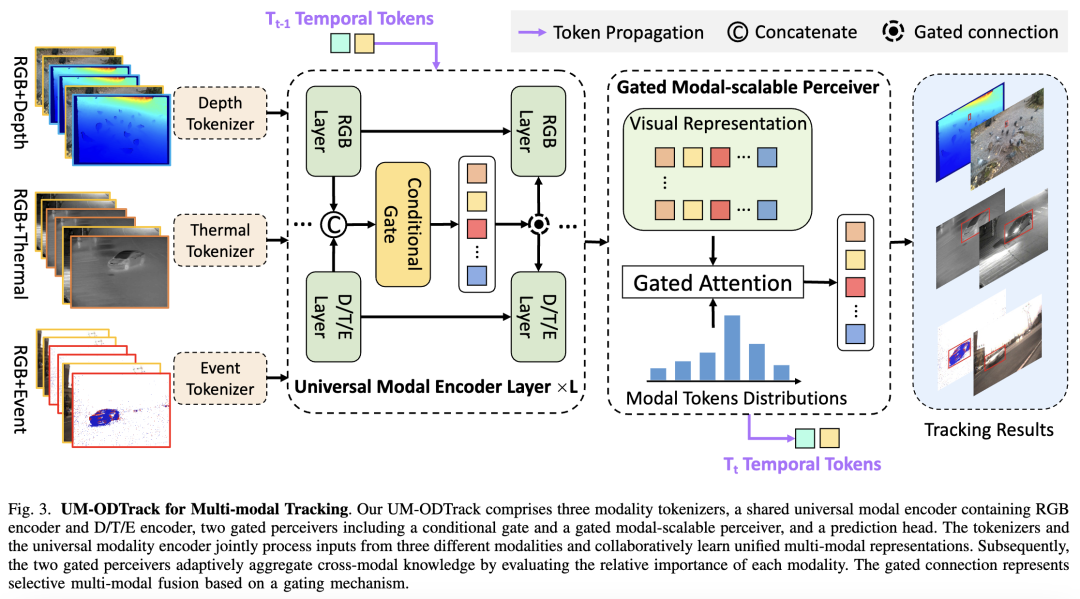
Due to the limited modality perception capability of the basic visual tracker, once trained on RGB tracking benchmarks, it cannot easily adapt to complex multimodal tracking scenarios. Therefore, we design two simple yet effective modules, namely conditional gating and gated modality-scalable perceivers, as shown in Figure 3, to adaptively learn universal cross-modal representations.
Conditional Gating. To achieve multimodal representation learning in the shared universal modality encoder, we add conditional gating modules in a residual manner between each encoder layer. In the conditional gating module, visible light features and corresponding auxiliary features (i.e., depth, thermal, and events) are aligned across modalities along the channel dimension to supplement rich details from other modalities. Then, the aligned multimodal representations are gated by the conditional gating module to facilitate cross-modal learning.
The conditional gating module can be formalized as the following equation:
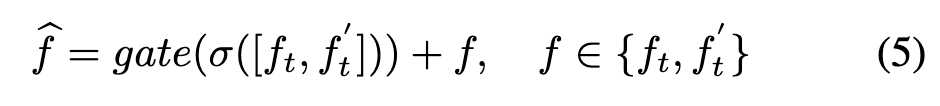
Here, and denote the visible modality feature and auxiliary modality feature extracted from the t-th video frame under a specific modality, respectively. represents an embedding layer used for dimensional scaling. denotes a gating network. It dynamically controls the representation learning of multimodal tracking based on the quality between modality sources, which is evaluated through a two-layer perceptron and a gating activation function. represents the output feature of the conditional gating module. It is noteworthy that the learning parameters of the last conditional gating network layer are initialized to zero, enabling its output to match that of the base visual tracker, thereby contributing to improved training stability.
Gated Modality-Extensible Perceptron. After performing the universal modality encoder, a visible feature , an auxiliary feature , a visible temporal token sequence , and an auxiliary modality temporal token sequence can be obtained. The feature space distributions of the two temporal tokens from different modalities reflect the appearance and motion trajectory information of the same target object across multiple modality sources. Therefore, we design a novel modality-extensible perceptron based on a gated attention mechanism to further enhance perception in multimodal tracking scenarios. Specifically, the learned multimodal representations undergo cross-attention computation with two temporal modality tokens to construct universal modality-dependent relationships from multiple views. This multimodal relationship can be expressed as the following formula:
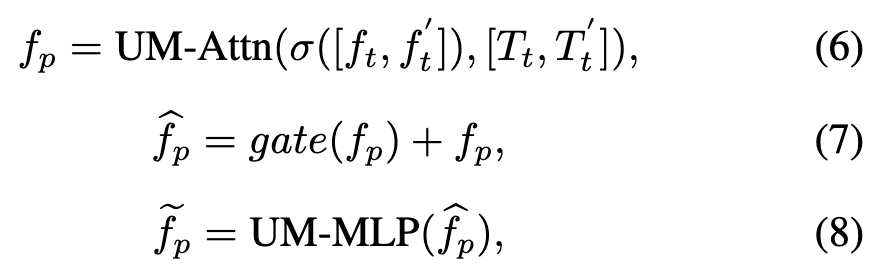
Here, denotes a multimodal cross-attention layer, taking the previous input as the query and the latter as the key and value. represents a multimodal feedforward network layer. is the output feature of the UM-Attn operation in the GMP module. is the output feature of the gating operation in the GMP module. represents the output feature of the GMP module. By adopting this novel gated attention mechanism, our UM-ODTrack can adaptively aggregate multimodal information into a shared visual-semantic feature space, effectively improving the modality perception capability of our tracker and thus achieving, for the first time, truly universal modality tracking.
F. Temporal Token-Associated Attention Mechanism
Instead of employing complex video transformers as the foundational framework for encoding video content, we design from a novel perspective using a simple 2D transformer architecture, namely 2D ViT. To construct an elegant instance-level inter-frame association mechanism, it is essential to extend the original 2D attention operation to extract and integrate video-level features. In our approach, we design two types of temporal token attention mechanisms based on the concept of compression-propagation, namely the concatenated token attention mechanism and the separated token attention mechanism, as illustrated in Figure 4 (left). The core design lies in injecting additional information, such as more video sequence content and temporal token vectors, into the attention operation, enabling them to extract richer spatiotemporal trajectory information of target instances.
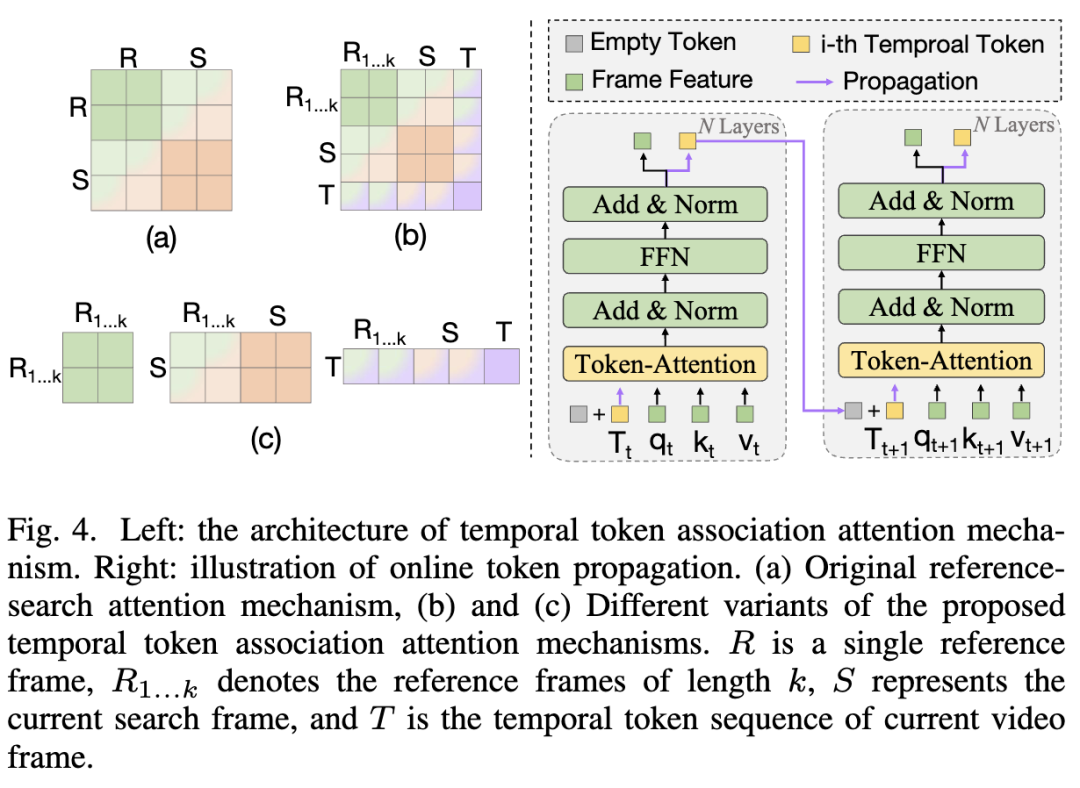
In Figure 4(a), the original attention operation typically takes image pairs as input, where the process of modeling their relationships can be represented as . Under this paradigm, the tracker can only interact independently within each image pair, establishing limited temporal correlations. In Figure 4(b), the proposed concatenated token attention mechanism extends the input to the aforementioned video sequence, enabling dense modeling of spatiotemporal relationships across frames. Inspired by how language forms contextual characteristics through concatenation, we similarly apply concatenation operations to establish context for video sequences. Its formula can be expressed as:
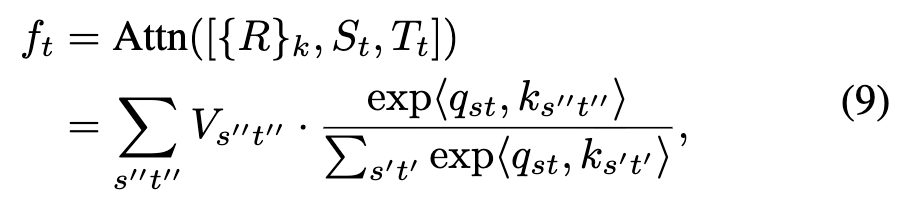
Here, is the temporal token sequence of the i-th video frame. denotes the concatenation operation between tokens. , , and are the spatiotemporal linear projections of the concatenated feature tokens.
On the other hand, the current temporal token-associated attention mechanism is equally applicable when performing multimodal tracking tasks. Specifically, similar to the visible temporal tokens, the multimodal temporal tokens are vectors initialized with zeros, used to extract the appearance and spatiotemporal localization information of target instances in multimodal tracking scenarios. The formula is expressed as follows:
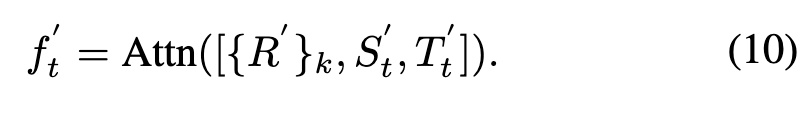
It is noteworthy that this paper introduces a temporal token for each video frame, aiming to store the target trajectory information of the sampled video sequence. In other words, we compress the current spatiotemporal trajectory information of the target into a token vector, which is then propagated to subsequent video frames.
Once the target information is extracted by the temporal tokens, the token vectors are propagated from the i-th frame to the j-th frame in an autoregressive manner, as shown in Figure 4 (right). First, the temporal token of the i-th frame is added to the empty token of the j-th frame, yielding the updated content token of the j-th frame, which is subsequently propagated as input to subsequent frames. Formally, the propagation processes for visible and multimodal tracking are:
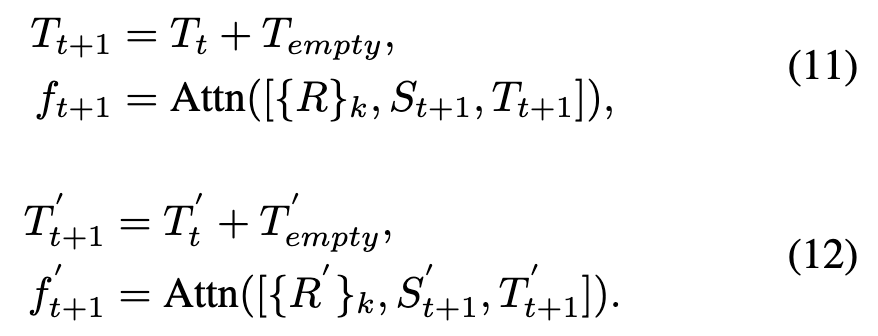
It is noteworthy that we introduce a temporal token for each video frame, aiming to store the target trajectory information of the sampled video sequence. In other words, we compress the current spatiotemporal trajectory information of the target into a token vector, which is then propagated to subsequent video frames.
Once the target information is extracted by the temporal tokens, we propagate the token vectors from the i-th frame to the j-th frame in an autoregressive manner, as shown in Figure 4 (right). First, the temporal token of the i-th frame is added to the empty token of the j-th frame, yielding the updated content token of the j-th frame, which is subsequently propagated as input to subsequent frames. Formally, the propagation processes for visible and multimodal tracking are:
Here, is the temporal token sequence of the auxiliary modality video frame at the i-th frame. is the empty token of the auxiliary modality video frame at the j-th frame.
In this new design paradigm, temporal tokens can be used as cues to infer the next frame, utilizing past information to guide future inferences. Additionally, our model implicitly propagates the appearance, localization, and trajectory information of target instances through online token propagation. This significantly enhances the tracking performance of the video-level framework.
On the other hand, as shown in Figure 4(c), the proposed separated token attention mechanism decomposes the attention operation into three subprocesses: self-information aggregation between reference frames, cross-information aggregation between reference and search frames, and cross-information aggregation between temporal tokens and video sequences. This decomposition improves the computational efficiency of the model to a certain extent, while token association follows the aforementioned process.
Discussion on Online Updating: Most previous tracking algorithms incorporate online updating methods to train spatiotemporal tracking models, such as adding additional score quality branches or IoU prediction branches. These typically require complex optimization processes and updating decision rules. In contrast to these methods, we avoid complex online updating strategies by leveraging the online iterative propagation of token sequences, enabling us to achieve more efficient model representation and computation.
G. One-Shot Training and Universal Inference
Prediction Head. For the design of the prediction head network, traditional classification and bounding box regression heads are employed to achieve the desired results. The predicted classification score map , bounding box dimensions , and offset dimensions are obtained through three sub-convolutional networks, respectively.
One-Shot Training. If a single neural network model can perform inference across multiple tasks simultaneously, it will present significant advantages. This not only reduces the need for handcrafting models with appropriate inductive biases for each domain but also increases the quantity and diversity of available training data.
For RGB tracking tasks, this paper uses training datasets including LaSOT, GOT-10k, TrackingNet, and COCO to train our base video-level tracking model. In terms of input data, we use video sequences containing three 192 × 192 pixel reference frames and two 384 × 384 pixel search frames as input to the model.
For multimodal tracking tasks, in contrast to tracking algorithms trained independently on single downstream datasets, such as [62], [64], [66], [74], our goal is to jointly train multiple tracking tasks (i.e., RGB-T tracking, RGB-D tracking, and RGB-E tracking) simultaneously. We train our universal modality-aware tracking model in a one-shot training manner on joint thermal infrared (i.e., LasHeR, aligning RGB and infrared data), depth (i.e., DepthTrack, aligning RGB and depth data), and event (i.e., VisEvent, aligning RGB and event data) datasets, and supervise its predicted bounding boxes using the same loss function.
Specifically, focal loss is adopted as the classification loss , and L1 loss and GIoU loss are used as the regression losses. The total loss can be formulated as:
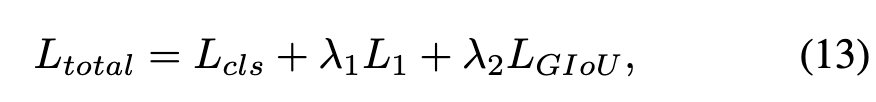
Here, and are regularization parameters. Since we use video clips for modeling, the task loss is computed independently for each video frame, and the final loss is averaged over the length of the search frames.
Universal Inference. Algorithm 1 summarizes the inference process of our model. For RGB tracking, we follow the same tracking procedure as other transformer trackers. Benefiting from our one-shot training scheme and gated modality-extensible perceptron module, for RGB-D, RGB-T, and RGB-E tracking tasks, we seamlessly perform inference for any tracking task using the same set of model parameters without the need for additional multiple fine-tuning techniques. In terms of input data, to maintain consistency with the training setup, we incorporate three equally spaced reference frames into our tracker during the inference phase. Meanwhile, the search frames and temporal token vectors are input frame by frame.

Experiment A. Implementation Details
This paper employs the ViT-Base model as the visual encoder, with its parameters initialized using MAE pre-trained parameters. AdamW is utilized to optimize the network parameters, with an initial learning rate of for the backbone network and for the remaining parts, and a weight decay set to . During each epoch, 60,000 image pairs are randomly sampled. For RGB tracking tasks, we set the training epochs to 300. The learning rate is reduced to one-tenth of its original value after 240 epochs. For multimodal tracking tasks, we set the training epochs to 15. The learning rate is reduced to one-tenth of its original value after 10 epochs. The model runs on a server equipped with two 80GB Tesla A100 GPUs, with a batch size set to 8.
B. Comparison with SOTA
We compare our ODTrack and UM-ODTrack with state-of-the-art trackers on seven visible light benchmarks (including LaSOT, TrackingNet, GOT10K, LaSOText, VOT2020, TNL2K, and OTB100) and five multimodal tracking benchmarks (including LasHeR, RGBT234, DepthTrack, VOT-RGBD2022, and VisEvent). Our ODTrack and UM-ODTrack demonstrate superior performance on these datasets.
GOT10K. GOT10K is a large-scale tracking dataset containing over 10,000 video sequences. The GOT10K benchmark proposes a protocol requiring trackers to be trained using only its training set. We adhere to this protocol to train our framework. The results are recorded in Table I. Among previous methods, ARTrack384, which does not employ a video-level sampling strategy, achieves state-of-the-art performance in terms of AO (Average Overlap), SR0.5, and SR0.75 (Success Rate at thresholds of 0.5 and 0.75) metrics. Benefiting from the proposed new video-level sampling strategy, our ODTrack384 attains a new state-of-the-art level, achieving 77.0%, 87.9%, and 75.1% on the AO, SR0.5, and SR0.75 metrics, respectively. The results indicate that one advantage of our ODTrack stems from the video-level sampling strategy aimed at unleashing the model's potential.
LaSOT. LaSOT is a large-scale long-term tracking benchmark comprising 1,120 training sequences and 280 test sequences. As shown in Table I, it can be observed that our ODTrack384 achieves favorable tracking results through the intriguing temporal token attention mechanism. Compared to the latest ARTrack performance, our ODTrack384 realizes improvements of 0.6%, 1.5%, and 1.5% in terms of AUC, P Norm, and P score, respectively. The results indicate that the spatiotemporal features with target association dependencies learned by the tracker can provide reliable target localization. Furthermore, since our temporal tokens are designed to associate target instances to enhance robustness and accuracy under various tracking challenges (i.e., fast motion, background interference, viewpoint changes, and scale variations, etc.). Therefore, as illustrated in Figure 5, which presents attribute evaluations on the LaSOT dataset, our token association mechanism significantly enhances target localization in long-term tracking scenarios by helping the tracker learn spatiotemporal trajectory information about target instances.
TrackingNet. TrackingNet is a large-scale short-term dataset that provides a test set comprising 511 video sequences. As reported in Table I below, by achieving cross-frame association of target instances, ODTrack384 attained a success score (AUC) of 85.1%, a normalized precision score (P Norm) of 90.1%, and a precision score (P) of 84.9%, outperforming the previous high-performance tracker SeqTrack without token association by 1.2%, 1.3%, and 1.3%, respectively. Meanwhile, compared to the recent video-level tracker VideoTrack without temporal token association, ODTrack surpasses it by 1.3%, 1.4%, and 1.8% on the AUC, P Norm, and P metrics, respectively. This indicates that our temporal tokens can effectively associate target objects across search frames, and this novel association method can enhance the generalization ability of our ODTrack in multiple tracking scenarios.
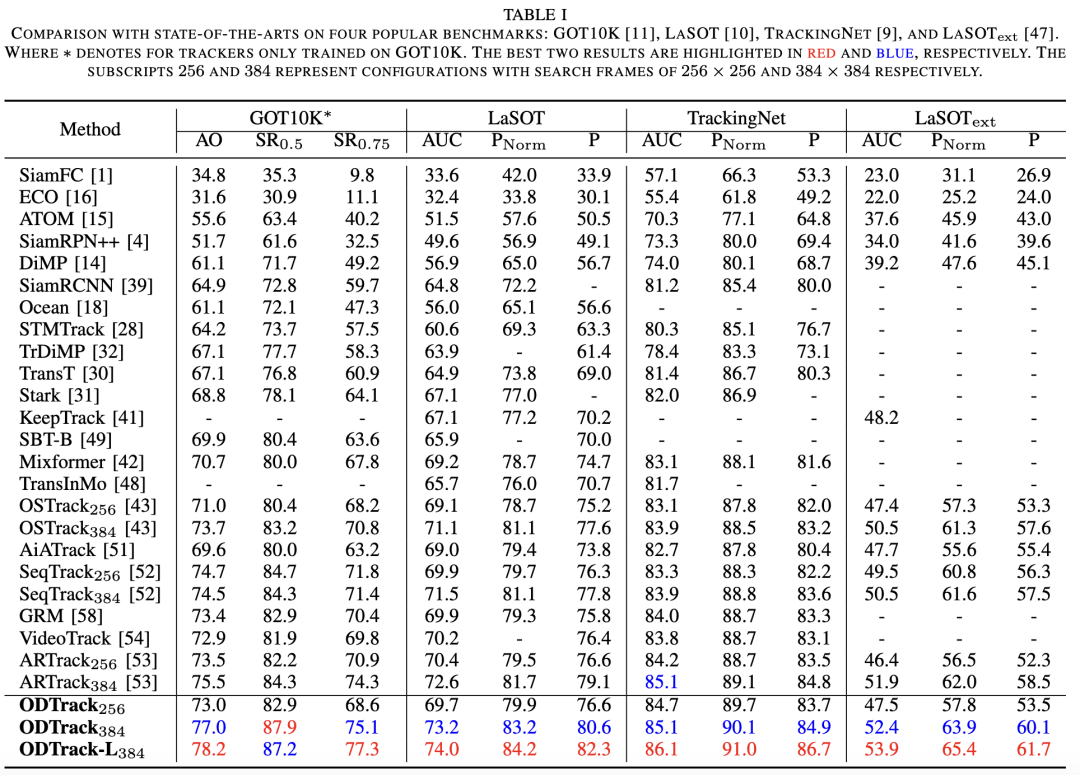
LaSOText. LaSOText is an extended version of LaSOT, containing 150 long-term video sequences. As reported in Table I, our method achieved favorable tracking results, outperforming most compared trackers. For instance, our tracker attained an AUC of 52.4%, a P Norm score of 63.9%, and a P score of 60.1%, surpassing ARTrack by 0.5%, 1.9%, and 1.6%, respectively. Additionally, our ODTrack outperforms the advanced image-pair matching-based tracker OSTrack by 1.9% in terms of success score. The results align with our expectations that video-level modeling exhibits more stable target localization capabilities in complex long-term tracking scenarios.
VOT2020. VOT2020 comprises 60 challenging sequences and uses binary segmentation masks as ground truth. We employed Alpha-Refine as the post-processing network for ODTrack to predict segmentation masks. The Expected Average Overlap (EAO) metric was used to evaluate the proposed tracker and other advanced trackers. As shown in Table III, our ODTrack384 and -L384 achieved the best results in mask evaluation, with EAO scores of 58.1% and 60.5%, respectively. Compared to trackers that did not explore temporal relationships (i.e., SBT and Ocean+), ODTrack outperformed them by 6.6% and 9% on the EAO metric, respectively. These results indicate that by injecting temporal token attention, our ODTrack exhibits robustness in complex tracking scenarios.
TNL2K and OTB100. Our tracker was evaluated on the TNL2K and OTB100 benchmarks, which contain 700 and 100 video sequences, respectively. The results in Table II show that ODTrack384 and -L384 achieved the best performance on both the TNL2K and OTB100 benchmarks. For example, our ODTrack384 obtained AUC scores of 60.9% and 72.3% on the TNL2K and OTB100 datasets, respectively. On the TNL2K dataset, ODTrack outperformed ARTrack by 1.1%. Meanwhile, compared to the non-autoregressive tracker Mixformer, our ODTrack achieved a 2.3% higher AUC score on the OTB100 dataset. It can be observed that by adopting an interesting autoregressive modeling method to capture temporal context, our ODTrack can reduce model complexity and improve performance.
DepthTrack. DepthTrack contains 150 training and 50 testing RGB-D long-term video sequences. As shown in Table IV below, we compared our model with existing state-of-the-art (SOTA) RGB-D trackers on this dataset. Under the same image resolution settings, our UM-ODTrack256 outperformed ViPT by 1.1%, 2.6%, and 1.8% in tracking precision (Pr), recall (Re), and F-score, respectively. Additionally, due to the proposed efficient gated attention mechanism, our UM-ODTrack384 achieved SOTA performance in the RGB-D tracking field. Notably, when the input size increased from 256 to 384, UM-ODTrack achieved a significant performance boost. This indicates that our temporal association method combined with a large input resolution is particularly important in multimodal long-term tracking scenarios.

VOT-RGBD2022. VOT-RGBD2022 is a short-term tracking dataset containing 127 RGB-D video sequences. As reported in Table V below, our tracker achieved new state-of-the-art results compared to most other tracking algorithms. Specifically, our UM-ODTrack256 obtained scores of 78.0%, 81.4%, and 94.8% on the EAO, accuracy, and robustness metrics, respectively. Compared to the latest unified tracker Un-Track, our UM-ODTrack256 achieved improvements of 5.9% and 7.9% in Expected Average Overlap (EAO) and robustness score, respectively. This indicates that our unified modeling technique is more effective for general feature learning and can provide a suitable and stable feature space for each modality (i.e., depth modality).

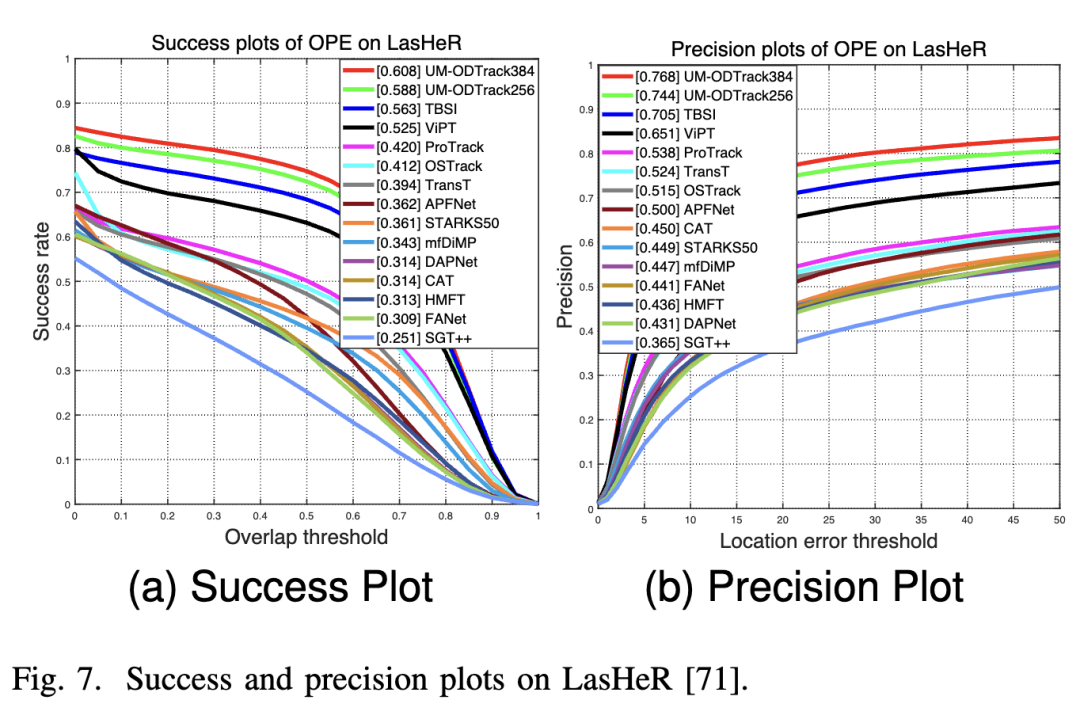
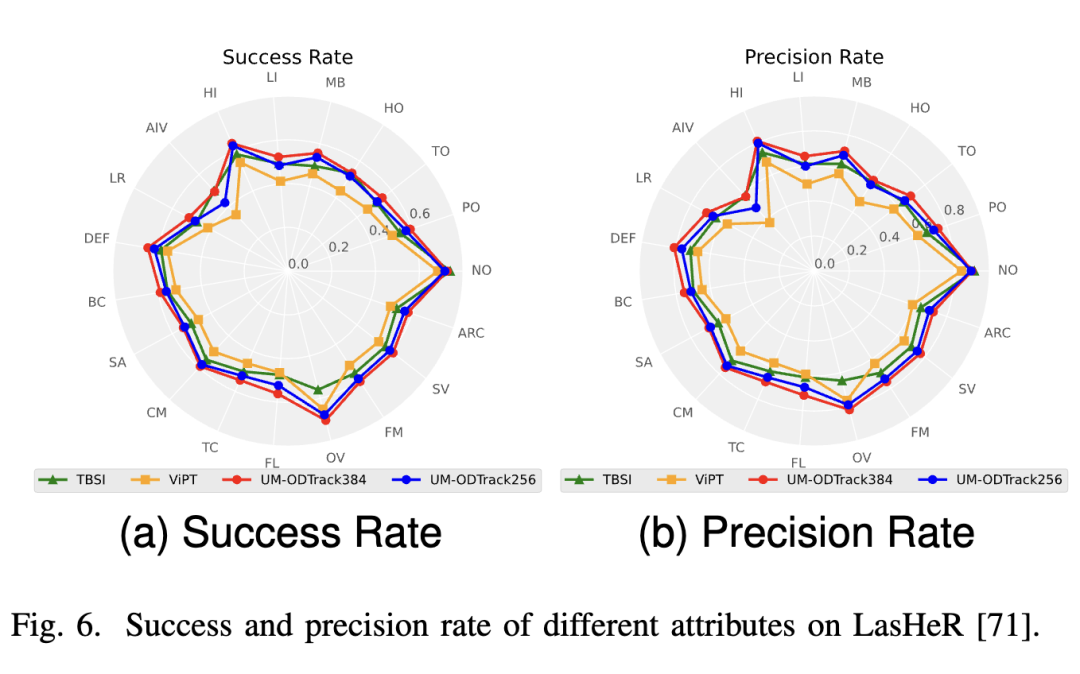
LasHeR. LasHeR is a large-scale RGB-T tracking dataset containing 245 short-term test video sequences. The results are reported in Figure 7 below, where our UM-ODTrack achieved surprising results, significantly outperforming the previous SOTA RGB-T tracking algorithms by 4.5% and 6.3% on the success and precision plots, respectively. These results align with our expectations that feature learning based on the gated attention mechanism can adaptively extract and fuse features from different modalities to improve multimodal tracking performance. Meanwhile, to verify that our gated perceptron can effectively address various challenges, including occlusion (NO), partial occlusion (PO), total occlusion (TO), low illumination (LI), low resolution (LR), deformation (DEF), background clutter (BC), motion blur (MB), thermal crossover (TC), camera motion (CM), fast motion (FM), scale variation (SV), transparent occlusion (HO), high illumination (HI), abrupt illumination variation (AIV), similar appearance (SA), aspect ratio change (ARC), out-of-view (OV), and frame loss (FL), we present the attribute evaluation results on the LasHeR dataset. As shown in Figure 6, our UM-ODTrack performed well on each attribute. Therefore, it can be demonstrated that our video-level multimodal modeling scheme with a gated perceptron can effectively unify and fuse multimodal features, enabling our tracker to handle complex tracking scenarios effectively.
RGBT234. RGBT234 contains 234 RGB-T tracking videos, comprising approximately 116.6K image pairs. As shown in Figure 6 below, UM-ODTrack256 obtained scores of 69.2% and 91.5% on the SR and PR metrics, respectively. Compared to the high-performance RGB-T expert tracker BAT, our method achieved favorable tracking results, outperforming it by 5.1% and 4.7% on the success and precision plots, respectively. This implies that our GMP module can effectively aggregate target information from the thermal infrared modality, enabling robust multimodal tracking.
VisEvent. VisEvent is the largest RGB-E tracking benchmark, containing 320 test videos. The comparison results are shown in Figure 8. Our UM-ODTrack384 achieved new state-of-the-art tracking results, with success and precision scores of 62.4% and 81.3%, respectively. It can be seen that our UM-ODTrack equipped with the gated modality scalable perceptron (GMP) module also achieved accurate tracking in event scenarios. This aligns with our intuition that the GMP module can be easily extended to different modality tracking scenarios and effectively improve the representation of multimodal features.
C. Ablation Studies
Effectiveness of Token Association. To investigate the effect of token association in Equation 11, we conducted experiments with and without propagating temporal tokens in Table VII. 'w/o Token' represents the experiment using a video-level sampling strategy but without token association. From the second and third rows, it can be observed that the lack of a token association mechanism led to a 1.2% decrease in the AUC score. This result indicates that token association plays a crucial role in cross-frame target association. Additionally, we conducted experiments in Table VII to verify the effectiveness of the two proposed token association methods in the video-level tracking framework. We observed that both the separation and concatenation methods achieved significant performance improvements, with the concatenation method showing slightly better results. This proves the effectiveness of both attention mechanisms.
Length of Search Video Clips. The impact of the length of search video sequences on tracking performance was ablated as shown in Table VIII below. When the video clip length increased from 2 to 3, the AUC metric improved by 0.3%. However, a continuous increase in sequence length did not bring further performance improvements, indicating that overly long search video clips impose a learning burden on the model. Therefore, an appropriate length of search video clips should be selected. Additionally, to evaluate the impact of sequence length on multimodal tracking performance, comparative experiments were conducted on the LasHeR, DepthTrack, and VisEvent benchmarks, as shown in Table XVI. The choice of video sequence length is crucial for leveraging temporal information. When the sequence length increased from 2 to 3, our tracker achieved improvements of 0.7%, 0.2%, and 1.6% in SR and F-score on the LasHeR, DepthTrack, and VisEvent benchmarks, respectively. These gains stem from effectively modeling target appearance changes and motion trajectories through multi-frame information. However, when the sequence length exceeded 3, performance tended to stabilize or slightly decline due to the accumulation of cross-modal temporal noise. This confirms that an appropriately chosen sequence length can provide complementary information, while overly long sequences are more likely to introduce redundant or noisy contextual signals. Therefore, our UM-ODTrack adopts a sequence length of 3 as the optimal setting to capture contextual information within a suitable time span.

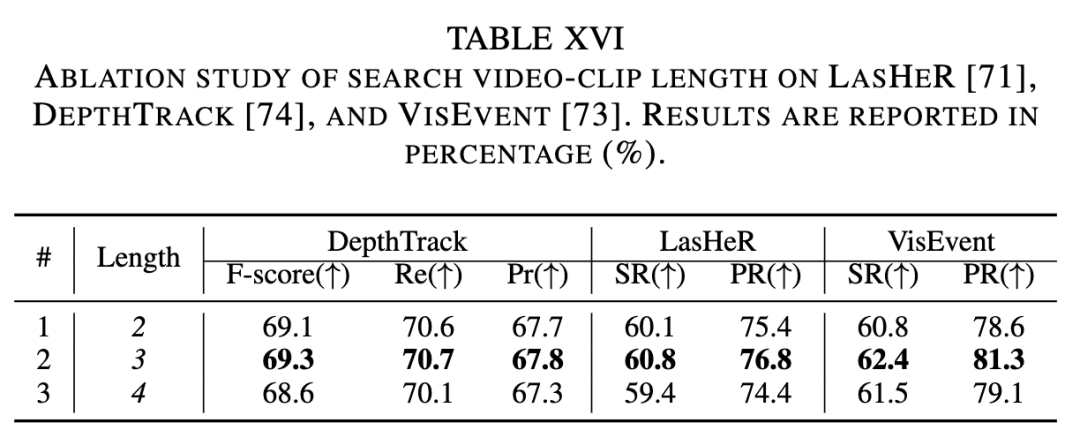
Sampling Range. To verify the impact of the sampling range on algorithm performance, experiments were conducted on the sampling range of video frames, as shown in Table IX below. When the sampling range expanded from 200 to 1200, there was a significant improvement in the performance of the AUC metric, indicating that the video-level framework can learn target trajectory information from a larger sampling range.
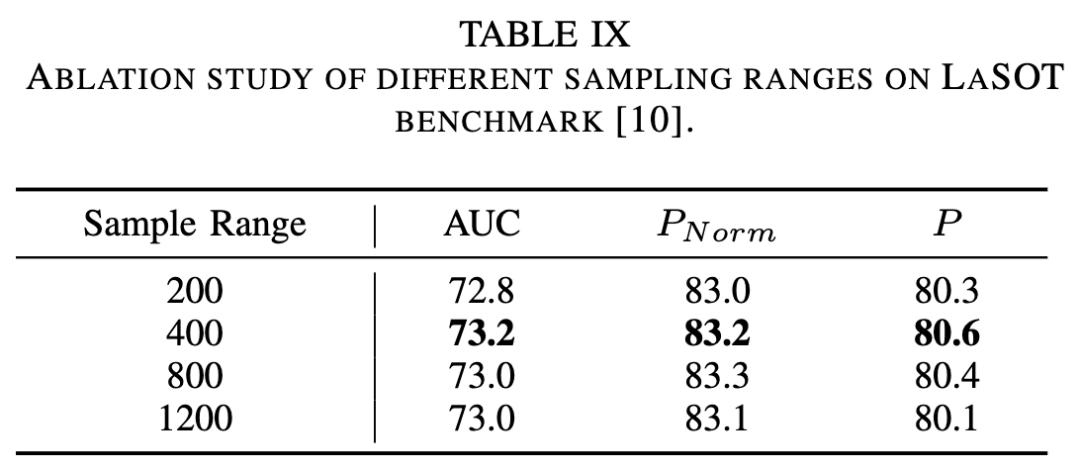
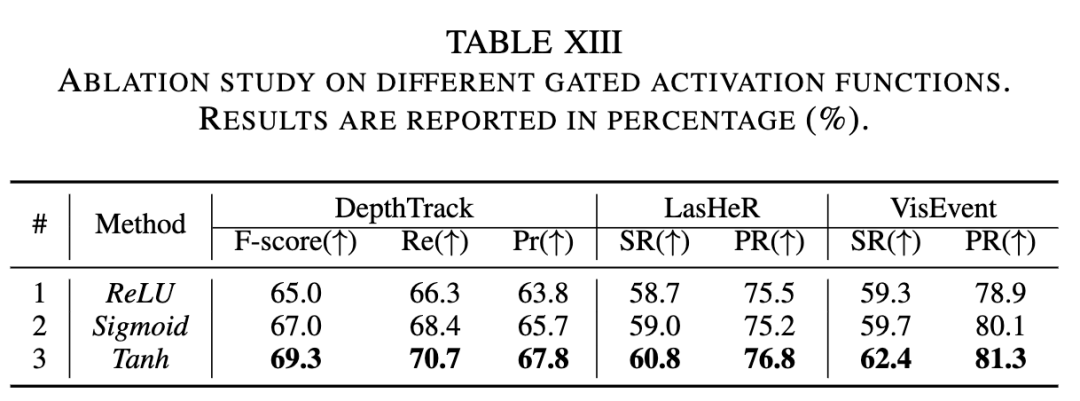
Effectiveness of Gated Perceptron and Gated Activation Function. We conducted experiments to verify the effectiveness of the two proposed components, namely conditional gating and the gated modality scalable perceptron (GMP), under the universal modality-aware tracking framework, as shown in Table X below. The baseline method refers to the dual-stream version of ODTrack. By adding the conditional gating module to the baseline, the performance of our tracker improved on three downstream tracking datasets. For example, the tracker equipped with conditional gating achieved a 1.3% improvement in the F-score metric on the DepthTrack benchmark. Additionally, by incorporating GMP into our model, its performance further improved. This proves the effectiveness of our two proposed gating modules. Furthermore, to investigate the effect of the gated activation function, experiments were conducted using different gated activation functions in Table XIII. Compared to ReLU and sigmoid, the tanh activation function performed the best. This result indicates that the tanh gating function is more suitable for learning and representing universal multimodal tracking tasks in our gated perceptron, potentially providing better generalization capabilities.

Number of Layers for Conditional Gating and GMP. We compared the effects of the number of layers of conditional gating and GMP on the model, respectively. The experimental results are recorded in Tables XI and XII. For conditional gating, as the number of layers increases, the performance of our tracker improves accordingly. This implies that integrating more layers in the universal modality encoder facilitates learning multimodal representations. On the other hand, when using three or six layers in the GMP module, our UM-ODTrack achieves favorable tracking results. To balance speed and performance, we opted for a three-layer configuration.
The Importance of Multimodal Cues. To verify the effectiveness of fusing RGB frames with other modality frames in visual tracking, we reported the tracking results of UM-ODTrack using only RGB data and bimodal data. As shown in Table XIV (#1 and #5), when using only RGB frames, our tracker exhibits significant performance degradation on three downstream benchmarks. For example, in the LasHeR dataset, the SR and PR metrics decreased by 6.3% and 7.2%, respectively, indicating that the injection of multimodal cues (or multimodal fusion) is notably effective and crucial for multimodal tracking.
The Importance of Shared Modality Tokenizer. We compared the impact of shared and non-shared tokenizers on multimodal tracking performance. In the experiments, we encoded multimodal data using shared and non-shared tokenizers and input the encoded data into the tracking model for training and inference. A shared tokenizer refers to using a unified tokenizer to encode data from all modalities, whereas a non-shared tokenizer involves using different tokenizers for each modality. As shown in Table XIV (#2 and #5), we found that the shared tokenizer exhibits superior tracking performance. This suggests that the shared tokenizer can more effectively capture the correlations among multimodal data, thereby enhancing the overall performance of our tracker.
Full Fine-Tuning vs. Adapter/Prompt Fine-Tuning. As shown in Fig. 12, experiments exploring the use of different training strategies (e.g., adapter fine-tuning and full fine-tuning) to train our model were conducted. The experimental results are recorded in Table XIV (#3 and #5). It can be observed that both adapter fine-tuning and full fine-tuning strategies achieve favorable performance improvements, with full fine-tuning showing slightly better results. Theoretically, adapter fine-tuning, which involves fewer learnable parameters, can save more GPU resources. However, in practice, the training resources are not significantly reduced and are comparable to the full fine-tuning scheme because other model parameters retain gradients during training. Therefore, we selected full fine-tuning, which involves more learnable parameters, as our training strategy.
Multi-Task One-Time Training vs. Single-Task Independent Training. To evaluate the benefits of multi-task unified (one-time) training for our final model, we independently trained expert models for the three sub-tracking tasks, as shown in Table XIV. The comparison results between #4 and #5 indicate that our one-time training scheme brings significant performance improvements. For example, the model trained solely on the DepthTrack dataset achieved an F-score of 67.8%, whereas the model jointly trained on DepthTrack, LasHeR, and VisEvent achieved a higher F-score of 69.3%, an improvement of 1.5%. This improvement is attributed to the increased quantity and diversity of training data available for each modality tracking task, as well as the effectiveness of the designed gating perceptron in aggregating multimodal features. These factors collectively enhance the robustness and generalization ability of our unified multimodal tracking model in various tracking scenarios.
Modality Weight Ratio. We conducted a comparative study, as shown in Table XV, to evaluate the impact of different modality weights on model performance. As the results show, the variants of the tracker perform consistently well under different weight schemes. For example, with a weight configuration of depth: infrared: event = 2:1:1, our model achieved F-score and SR values of 69.1%, 60.4%, and 61.7% on the DepthTrack, LasHeR, and VisEvent datasets, respectively. These findings indicate that our method is not highly sensitive to the specific weights of modalities. Therefore, an equal-weight scheme (depth: infrared: event = 1:1:1) can effectively balance the contributions of each modality and serve as a robust default configuration for our model.
D. Qualitative Analysis
Analysis of Speed, FLOPs, and Number of Parameters. Comparative experiments were conducted in terms of the number of model parameters, FLOPs, and inference speed, as shown in Table XVII. On the same test machine (i.e., 2080Ti), ODTrack achieved faster inference speed compared to the latest tracker, SeqTrack. Our tracker operates at a speed of 32 fps.
Visualization. For RGB tracking tasks, to intuitively demonstrate the effectiveness of our method, especially in complex scenarios containing similar distractors, the tracking results of ODTrack and three advanced trackers were visualized on LaSOT. As shown in Fig. 9, owing to its ability to densely propagate the trajectory information of the target, our tracker significantly outperforms the latest tracker, SeqTrack, on these sequences.
For multimodal tracking tasks, we visualized the multimodal tracking results of our UM-ODTrack and other SOTA trackers on the LasHeR, DepthTrack, and VisEvent datasets, respectively, as shown in Fig. 11. Benefiting from the gating perceptron's universal perception capability for any modality, our UM-ODTrack can accurately locate the target in complex sequences compared to other multimodal trackers. Meanwhile, we compared the feature representations with and without the gating modality scalable perceptron (GMP). As shown in Fig. 13, without the GMP module, the model lacks the ability to capture inter-modality correlations, resulting in learned representations that often focus on distractors similar to the target. In contrast, when equipped with the GMP module containing an attention-based gating mechanism, our tracker effectively suppresses such distractions in complex multimodal tracking scenarios, enabling the model to focus more accurately on the target object.
Furthermore, the attention maps of the temporal token attention operation were visualized, as shown in Fig. 10. We can observe that the temporal tokens continuously propagate and focus on the motion trajectory information of the object, which aids our tracker in accurately locating the target instance.
Conclusion
This work explores an intriguing video-level visual object tracking framework called ODTrack. It redefines visual tracking as a token propagation task to densely associate contextual relationships across video frames in an autoregressive manner. Additionally, to extend from unimodal perception to multimodal perception, we propose UM-ODTrack, a universal video-level modality-aware visual tracking framework that effectively aggregates multimodal temporal information of target instances by designing a gating attention mechanism. Specifically, a video sequence sampling strategy and two temporal token propagation attention mechanisms are designed, enabling the proposed framework to simplify video-level spatiotemporal modeling and avoid complex online update strategies. Furthermore, two gating modality scalable perceptrons are proposed to aggregate target spatiotemporal information from various modalities. Finally, our model can simultaneously infer different multimodal tracking tasks using the same set of model parameters through a one-time training scheme. Extensive experiments demonstrate that UM-ODTrack achieves excellent results on seven visible light tracking and five multimodal tracking benchmarks. It is expected that ODTrack and UM-ODTrack can serve as powerful baselines for universal video-level modality-aware tracking, inspiring further research in the fields of visible light tracking and multimodal tracking.
References
[1] Towards Universal Modal Tracking with Online Dense Temporal Token Learning
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






