Are Video Models Truly Engaging in Genuine Reasoning, or Are They Just “Acting” the Part? CUHK and Other Institutions Propose a New Benchmark to Probe: Is Chain-of-Frame Truly Authentic?
 11/13 2025
11/13 2025
 537
537
Interpretation: The Future Landscape of AI-Generated Content
Introduction
In recent times, video generation models such as Veo and Sora have showcased remarkable generative prowess, synthesizing highly realistic and temporally seamless dynamic scenes. These advancements hint that beyond mere visual content creation, models might have started to develop an implicit understanding of the physical world's structure and underlying laws.
Remarkably, Google's latest research reveals that models like Veo-3 are exhibiting 'emergent abilities' that go beyond simple generation. These include perceptual modeling, dynamic prediction, and reasoning capabilities.
This has given rise to a novel concept akin to the language model's 'Chain-of-Thought' (CoT) — namely, Chain-of-Frame (CoF).
The central tenet of CoF is that video models construct coherent visual evolutions through frame-by-frame generation, thereby embodying the process of thought and reasoning. However, a pivotal question remains unanswered: Do these models genuinely possess zero-shot reasoning capabilities, or are they merely mimicking superficial patterns gleaned from training data?
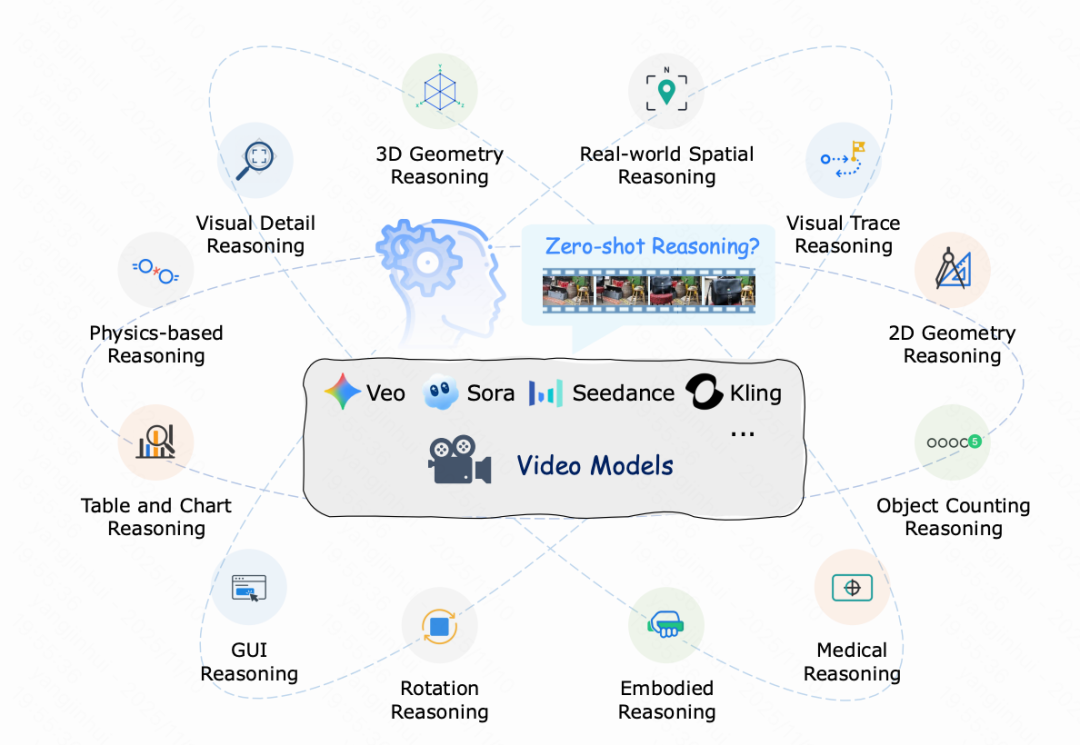
To delve into this, researchers from institutions including the Chinese University of Hong Kong, Peking University, and Northeastern University embarked on systematic studies. They conducted a comprehensive evaluation of the zero-shot reasoning potential of models like Veo-3 and introduced a comprehensive benchmark — MME-CoF — encompassing 12 dimensions such as space, geometry, physics, and time.
What is Chain-of-Frame (CoF)?
'Chain-of-Frame (CoF)' can be likened to the visual counterpart of the language-based 'Chain-of-Thought (CoT)':
CoT: Demonstrates thinking and reasoning paths through step-by-step text generation.
CoF: Presents reasoning and decision-making processes through dynamic frame-by-frame visual evolution.
This approach empowers models to not only produce results but also 'showcase' their thinking trajectories along the generative timeline.
Overview of 12 Reasoning Challenges
The research team devised systematic tests around 12 reasoning dimensions and empirically evaluated the Veo-3 model. Below are summaries of some typical tasks.
Visual Detail Reasoning
Objective: Assess the model's proficiency in maintaining fine-grained visual attributes (color, texture) and spatial relationships.
Performance: Performs admirably with prominent, easily recognizable objects.
Limitations: Prone to deviation from task objectives or stylistic biases when targets are small, occluded, or situated in complex backgrounds.
Visual Trace Reasoning
Objective: Evaluate the model's ability to uphold causal continuity in action sequences.
Performance: Generates coherent short-term temporal paths in straightforward tasks.
Limitations: Struggles to maintain coherent causal relationships in long-term or highly logically dependent tasks.
Physics-based Reasoning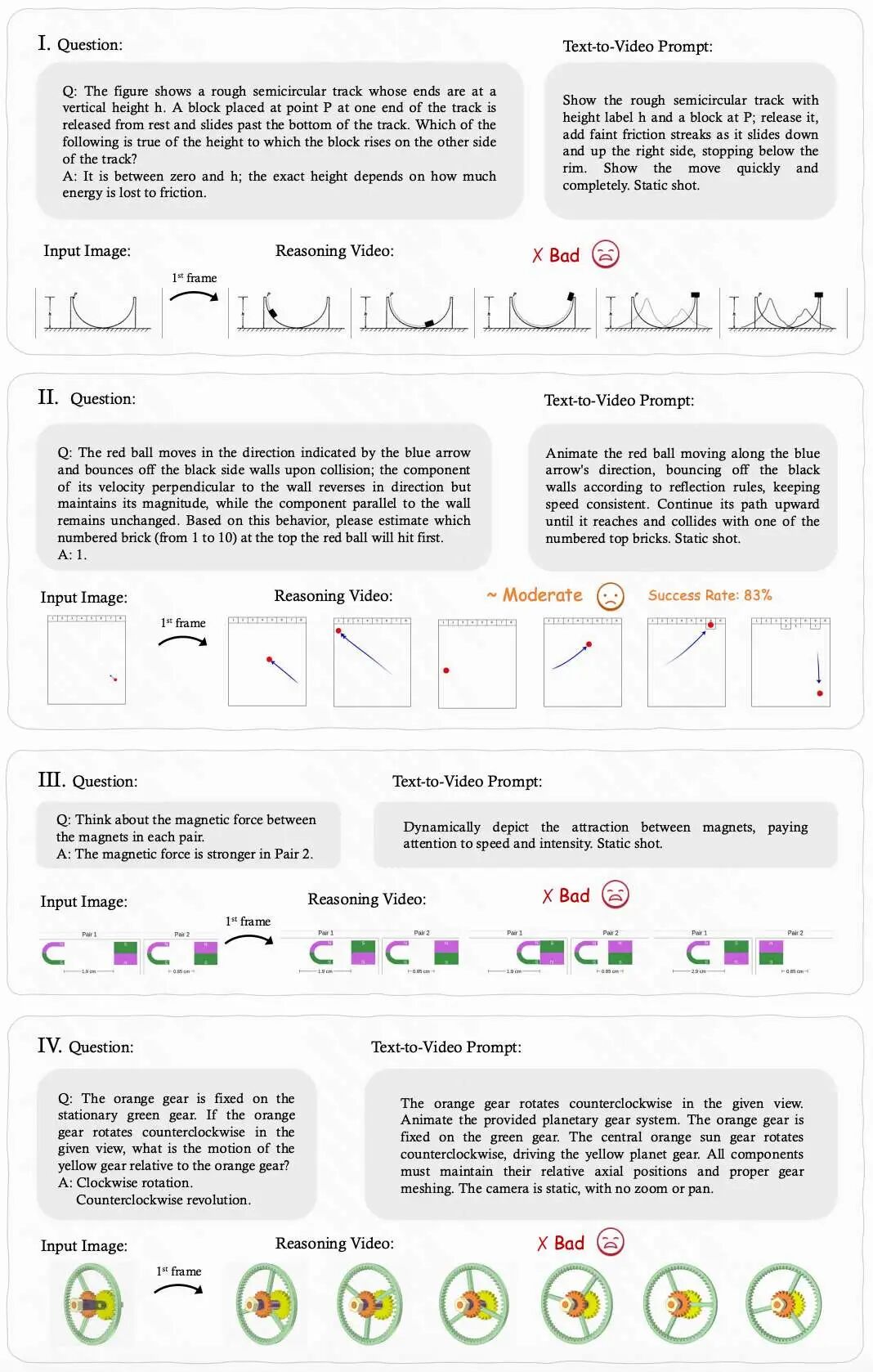
Objective: Test whether the model comprehends physical laws such as gravity, collision, and friction.
Performance: Generates short-term plausible dynamic scenes.
Limitations: Frequently violates physical constraints (e.g., energy conservation), merely 'mimicking' physics rather than truly engaging in reasoning.
Real-World Spatial Reasoning
Objective: Test the model's capacity to maintain spatial consistency under perspective changes.
Performance: Maintains basic orientation and spatial structure in simple scenes.
Limitations: Prone to spatial misalignment or drift in complex multi-perspective tasks.
3D Geometry Reasoning
Objective: Evaluate the model's structural understanding in tasks involving 3D folding, rotation, and reconstruction.
Performance: Demonstrates some 3D perception in single-step operations.
Limitations: Prone to collapse during complex combinatorial transformations, lacking stable geometric consistency.
2D Geometry Reasoning
Objective: Examine the model's precision in planar composition and shape relationships.
Performance: Can identify and draw basic geometric relationships.
Limitations: More inclined to generate 'aesthetically pleasing' shapes rather than 'correct' geometries, prone to logical sequencing errors.
Overview of the Other Six Reasoning Dimensions
In addition to the aforementioned six, the remaining six dimensions also unveil limitations in Veo-3:
Rotation Reasoning: Approximates small-angle rotations but collapses at larger angles.
Table & Chart Reasoning: Mimics local visual patterns but lacks true comprehension of numerical relationships.
Object Counting Reasoning: Performs well in static scenes but often misses or duplicates counts in dynamic environments.
GUI Reasoning: Can generate click or drag actions but lacks awareness of operational purpose and logic.
Embodied Reasoning: Can identify object positions and actions but does not adhere to environmental rules, occasionally generating 'cheating' outputs.
Medical Reasoning: Demonstrates superficial ability in zooming or observing local details but fails to maintain image logic consistency, prone to structural errors.
MME-CoF: The First Video Reasoning Benchmark
Based on these findings, the research team introduced MME-CoF, the first standardized evaluation system specifically crafted to quantify the reasoning capabilities of video models. Its key features include:
The inaugural systematic video reasoning evaluation framework; encompasses 12 dimensions; transforms abstract reasoning processes into video generation challenges, compelling models to visually demonstrate 'Chain-of-Frame thinking.'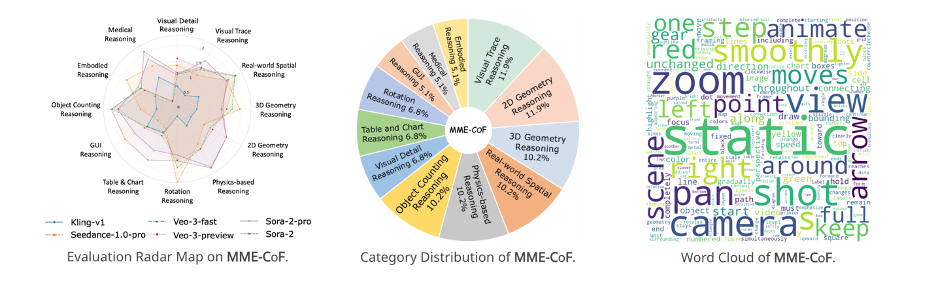
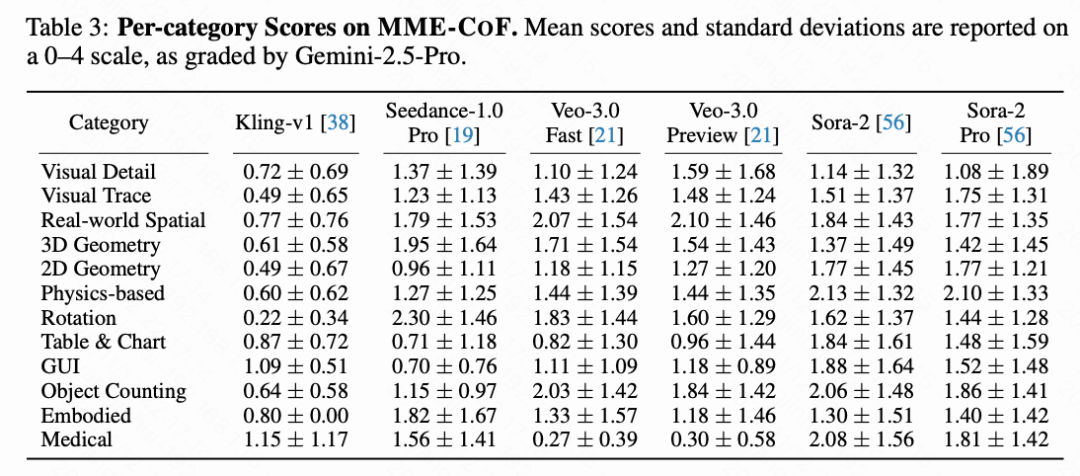
Utilizing the MME-CoF benchmark, the research team conducted quantitative evaluations of multiple mainstream models (scored by Gemini-2.5-Pro, out of 4 points). The results revealed:
Overall low performance: Most models averaged below 2 points, indicating limited reasoning capabilities.
Significant advantage differences: Sora-2 performed relatively well in physical, embodied, and medical reasoning; Veo-3 excelled in real-world spatial reasoning; Seedance-1.0-Pro slightly outperformed in rotation and 3D geometry tasks.
General trend: Each model exhibited preferences in specific directions but remained at the 'pattern reproduction' level, lacking true logical reasoning abilities.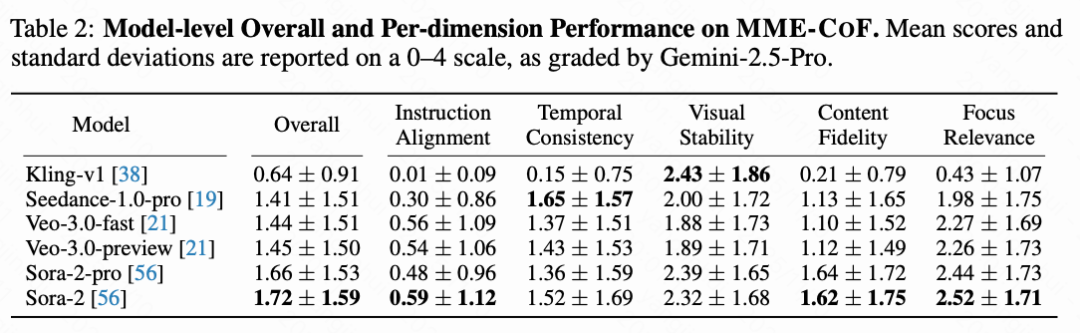
Conclusion: Reasoning or Performance?
Through empirical analysis of models like Veo-3, the research team arrived at the following conclusions:
Lack of genuine zero-shot reasoning: Current video models rely more on data patterns than autonomous logical deduction.
Strong generation ≠ Strong reasoning: High-quality visuals do not imply deep understanding.
Focus on appearance, neglect causality: Generated results may 'look reasonable' but often violate logic or physical laws.
Video models can serve as crucial modules for visual reasoning systems, potentially advancing multimodal intelligence toward true 'general understanding' when integrated with language or logical models.
Overall, this study provides the academic community with a systematic and verifiable empirical evaluation framework, clearly revealing the core bottlenecks that video generation models must overcome to transition from 'content generation' to 'logical reasoning' and ultimately achieve true 'general visual intelligence.'
References
[1] Are Video Models Ready as Zero-Shot Reasoners? An Empirical Study with the MME-CoF Benchmark
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






