The Evolutionary Trajectory of Autonomous Driving: From Modular Design to the Unified One Model
 11/24 2025
11/24 2025
 649
649
If we envision an autonomous vehicle as a machine endowed with the capabilities to 'perceive, deliberate, and act,' its foremost task is to comprehensively sense its surroundings through sensors. Subsequently, it 'deliberates' upon this information, making predictions and decisions that are ultimately translated into precise control commands for execution. The operational logic underlying autonomous driving is already well-established; however, the technological pathways for its implementation have been undergoing continuous refinement and evolution along a discernible trajectory. Starting from perception modeling focused on 'understanding,' progressing to planning and control modeling that imparts 'deliberative' capabilities, and culminating in synergistic multi-module end-to-end systems, the ultimate destination is inevitably the One Model end-to-end paradigm.
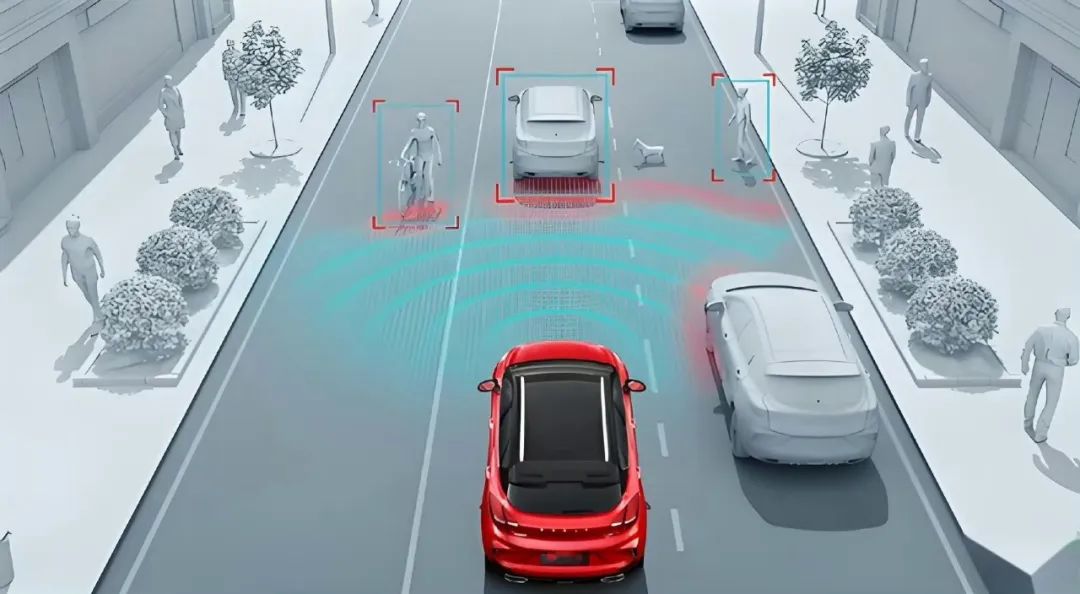
Image Source: Internet

Perception Modeling: Focused on 'Comprehensive Understanding'
The initial phase of autonomous driving primarily emphasizes achieving a comprehensive understanding of the environment. During this stage, the perception system assumes paramount importance, with its implementation heavily reliant on the front-end fusion of multiple sensors (cameras, millimeter-wave radars, LiDAR). The Bird's Eye View (BEV) space and Transformer architecture have emerged as the primary tools for this endeavor, as they enable uniform processing of features from diverse sources and establish global associations. Through the integration of hardware and software, the reliability of target detection, map segmentation, and trajectory tracking can be significantly enhanced. At this juncture, considerations encompass perception accuracy, low false alarm rates, robustness to lighting and weather variations, as well as ensuring real-time performance and deployability.

Image Source: Internet
During this phase, the boundaries of autonomous driving modules are clearly defined, and engineering responsibilities are well-delineated, facilitating verification and deployment. The perception module outputs explicit intermediate results, such as 2D/3D bounding boxes of targets, lane lines, and semantic maps, which can be directly utilized by the upper-level prediction and planning modules. This arrangement simplifies safety checks and anomaly handling.
The independent perception module renders the data annotation and training process relatively manageable. However, it also introduces challenges such as discrete information and lossy transmission between modules. Results abstracted through human-defined interfaces (e.g., target categories, bounding boxes) fail to retain all the intricate details present in the raw sensor data. While this information loss may be tolerable in most scenarios, it can severely impede the system's ability to make optimal decisions in complex situations requiring fine-grained environmental understanding, long-term dependency analysis, or cross-modal information fusion, thereby limiting its performance potential.
Planning and Control Modeling: Neuralizing 'Deliberation' and 'Action'
In the planning and control modeling stage, functions such as prediction, decision-making, and planning commence to be implemented using neural networks, while the system retains two relatively independent models for 'perception' and 'planning and control.' In essence, the perception component of the system generates a clear and interpretable semantic representation of the world, whereas the prediction and planning tasks within the planning and control component are accomplished by deep learning networks, eschewing reliance on traditional rules or optimizers. This architecture extends learning capabilities to higher levels, enabling behavioral strategies to glean more complex patterns from data while preserving the controllability afforded by modularization.

Image Source: Internet
Planning and control modeling indeed has the potential to render autonomous vehicles more intelligent. Given that perception and planning and control are distinct modules, issues are more readily identifiable and debuggable. However, precisely because they are separate entities, the information transmitted between them is akin to passing notes, invariably resulting in some loss of detail. A subtle action perceived by the perception module may be pivotal for decision-making, yet it could be compressed or discarded during transmission, preventing the decision-making model from fully leveraging all available information. Moreover, since the two modules undergo independent training, even if the perception module achieves perfect scores, it does not necessarily imply that the information it provides to the planning and control module is most conducive to the final decision, thereby failing to enhance the overall performance of autonomous driving.
This stage essentially represents a compromise in the development of autonomous driving. Driven by the desire for greater intelligence in the upper layers while reluctant to relinquish the interpretability and verification convenience afforded by modularization, this choice is made. Many leading companies are also exploring the integration of more learning capabilities into the planning and control end while mitigating information loss issues by designing richer intermediate perception representations and tighter feature interfaces.
Multi-Module End-to-End: Facilitating More Complete Information Transmission
The crux of multi-module end-to-end systems lies in the transformation of interface forms. Information is no longer transmitted between perception and planning through human-designed semantic labels or bounding boxes but is instead connected using implicit feature vectors. In other words, while the system logically retains 'modular' divisions such as perception, prediction, and planning, the information transmitted between these modules comprises high-dimensional continuous features, enabling gradients to propagate backward across modules. This approach allows the training process to simultaneously influence all modules, achieving cross-module joint optimization and thereby a global optimal solution. Architectures like UniAD exemplify this approach, placing tasks such as detection, tracking, prediction, and planning under the same framework for joint training, with tasks sharing feature representations to mutually reinforce each other.

Image Source: Internet
The advantage of multi-module end-to-end systems lies in the more complete preservation of information, enabling the network to learn intermediate representations most valuable for downstream tasks without relying on human-preset formats. Given that modules still exist, certain boundaries can be maintained during deployment, facilitating gradual replacement or rollback and reducing risks. This architecture also significantly enhances training efficiency. By sharing features and joint loss functions, the model can more fully exploit data, achieving better generalization capabilities even in scarce scenarios through joint training.
However, the introduction of the multi-module end-to-end design also significantly escalates system complexity. This not only necessitates more data and computational power for training but also renders the entire process more sensitive to hyperparameter and loss weight settings. It is also accompanied by a decline in model interpretability. When the learning objectives of different tasks (e.g., detection and planning) are inconsistent, debugging becomes considerably more challenging. Due to the deep integration of modules, if the system fails in a specific scenario, pinpointing the exact cause becomes arduous, substantially slowing down the certification process. Additionally, while gradients can flow across modules to seek a global optimum, it also introduces risks of training instability and gradient conflicts, which must be managed through specialized training strategies and balancing mechanisms to maintain stability.

One Model End-to-End: The Ultimate Paradigm for Autonomous Driving
One Model end-to-end represents a more thorough end-to-end approach, wherein the objective is to accomplish all tasks, from raw sensor signals (e.g., image pixels, radar point clouds) to final control commands or trajectories, utilizing a single unified deep learning model. Traditional module divisions such as perception, prediction, and planning are no longer present; instead, the model internally forms all the necessary intermediate representations and processing paths to complete tasks through self-learning. This architecture can fully exploit every piece of information from the sensors, avoiding information bottlenecks caused by human-defined interfaces, thereby achieving higher performance and better generalization capabilities in complex scenarios.
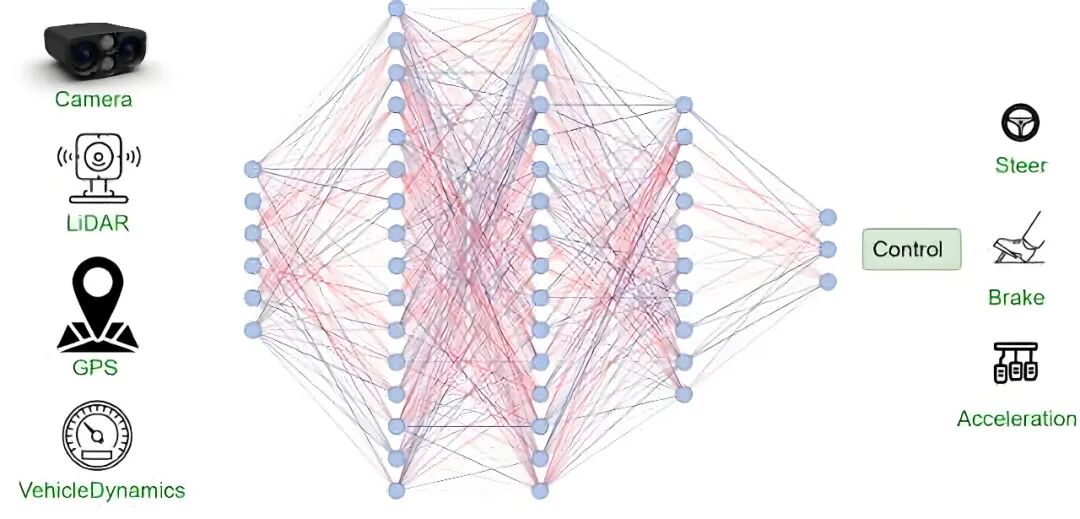
Image Source: Internet
One Model end-to-end necessitates substantial data and computational power support to encompass a sufficient number of driving scenarios and edge cases. Model capacity, training sample coverage, and the design of supervision signals (e.g., hybrid strategies such as behavioral cloning, inverse reinforcement learning, and reinforcement learning) will directly influence the final performance. Given that this type of model aligns more closely with the 'large model' paradigm, strategies from natural language processing or visual large models, such as pre-training with massive unlabeled or weakly labeled data followed by fine-tuning with a small amount of high-quality decision-making data, can be adopted.
In this architecture, issues of interpretability and verifiability also emerge due to the integrated nature of the model. When there are no clear module boundaries within the system, constructing safety arguments and passing regulatory or industry certifications become formidable challenges. To comply with regulations, autonomous driving models need to elucidate why they take certain actions in specific situations, yet the 'integrated' black-box model struggles to meet this requirement. The robustness and controllability of this approach are also concerns. If the system makes errors in rare scenarios, how can it be swiftly located, repaired, and rolled back? Traditional modularization allows for the replacement of a single module, whereas a 'large model' may necessitate retraining or significant fine-tuning. In safety-critical systems, redundant designs (e.g., dual-channel independent perception links) are commonplace, but devising redundancy for an 'integrated' model and determining how to degrade when some sensors fail are difficult problems that must be addressed.
Although many consider One Model end-to-end as the 'ultimate form' of autonomous driving, it is more likely to serve as a research frontier or a trial solution for specific scenarios (e.g., closed campuses, low-speed environments) in the near term. There is still a considerable journey ahead before it can be truly implemented.
Final Thoughts
Viewing the four stages collectively, autonomous driving systems can be understood as following a technological evolution path from 'interpretable and controllable' to 'information-complete and potentially higher-performing.' Perception modeling is suitable for achieving ultimate clarity in perception; planning and control modeling renders 'deliberation' and 'action' more intelligent; multi-module end-to-end strikes a balance between efficiency and completeness; while One Model end-to-end represents the theoretical performance ceiling but comes with significant challenges in verification, explanation, and deployment. Regardless of the chosen architecture, the ultimate goal of autonomous driving remains to serve people. Only by maximizing technological utilization while ensuring safety can it be deemed a truly beneficial technological architecture.
-- END --
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






