Blockbuster! Alibaba DAMO Academy Releases RynnVLA-002, the First Unified Architecture for VLA and World Models: 97.4% Success Rate Reshapes Cognition
 11/25 2025
11/25 2025
 626
626
Interpretation: AI Generates the Future


Highlights
Unified Architecture: RynnVLA-002 is an 'Action World Model' that integrates visual-language-action (VLA) models and world models into a single framework.
Bidirectional Enhancement: It achieves complementarity between VLA and world models—world models optimize action generation using physical laws, while VLA enhances visual understanding for more accurate image predictions.
Hybrid Action Generation Strategy: Addresses error accumulation in discrete action generation with an 'Action Attention Mask' strategy and introduces a continuous Action Transformer head for smoothness and generalization in real-world operations.
Exceptional Performance: Achieves a 97.4% success rate in LIBERO simulation benchmarks without pre-training; integrates world models to boost overall success rates by 50% in real-world LeRobot experiments.
Addressed Challenges
This work primarily improves upon the following limitations of existing architectures:
Deficiencies in VLA Models:
Insufficient Action Understanding: Actions exist only as outputs, lacking internal explicit representation.
Lack of Imagination: Unable to predict world state evolution post-action execution, lacking foresight.
Lack of Physical Common Sense: Unable to internalize physical dynamics such as object interactions, contacts, or stability.
Deficiencies in World Models: Unable to directly generate action outputs, creating a functional gap that limits their application in explicit action planning scenarios.
Deficiencies in Autoregressive Action Generation: Discrete action generation is prone to error propagation and exhibits jitter and poor generalization on real robots.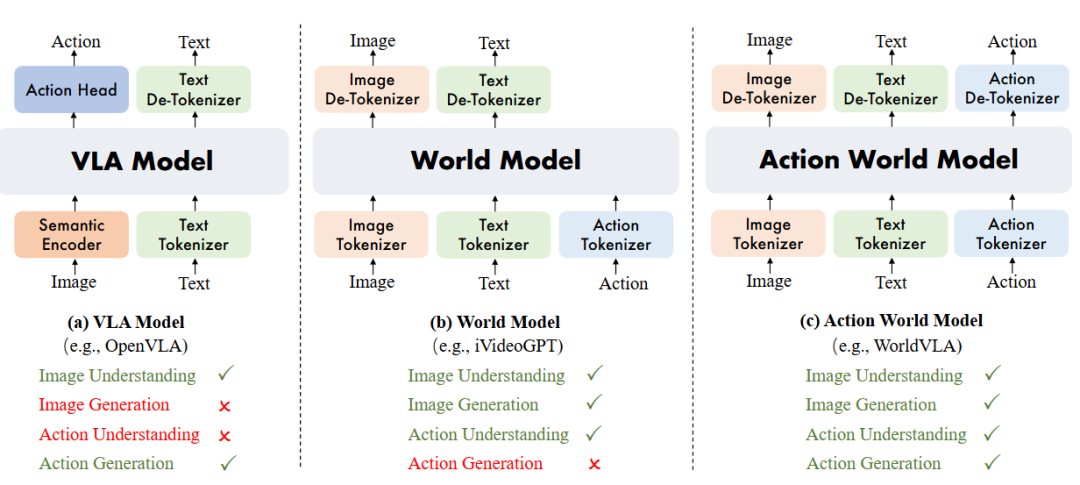 Figure 1(a) VLA models generate actions based on image understanding; (b) World models generate images based on image and action understanding; (c) Action world models unify image and action understanding with generation.
Figure 1(a) VLA models generate actions based on image understanding; (b) World models generate images based on image and action understanding; (c) Action world models unify image and action understanding with generation.
Proposed Solution
This work introduces RynnVLA-002, an autoregressive action world model.
Unified Vocabulary: Uses three independent Tokenizers to encode images, text, and actions, sharing a common vocabulary for unified understanding and generation across modalities within the same LLM architecture.
Joint Training: The model can function as a VLA to generate actions based on observations or as a world model to predict future images based on actions.
Hybrid Generation Mechanism: Retains discrete joint modeling while incorporating a continuous Action Transformer head to meet real-world continuous control demands.
Applied Technologies
Basic Architecture: Initialized from the Chameleon model (a unified model for image understanding and generation).
Tokenization:
Images: Utilizes VQ-GAN with a compression rate of 16 and a codebook size of 8192.
Text: Employs BPE Tokenizer.
Actions/States: Discretizes continuous dimensions into 256 bins.
Action Attention Masking: In discrete action generation, modifies the Attention Mask to ensure current actions depend solely on text and visual inputs, blocking error accumulation in the autoregressive process.
Action Transformer: Introduces a continuous action head (similar to ACT) to generate smooth action trajectories through parallel decoding, addressing overfitting and jitter in discrete models.
Achieved Results
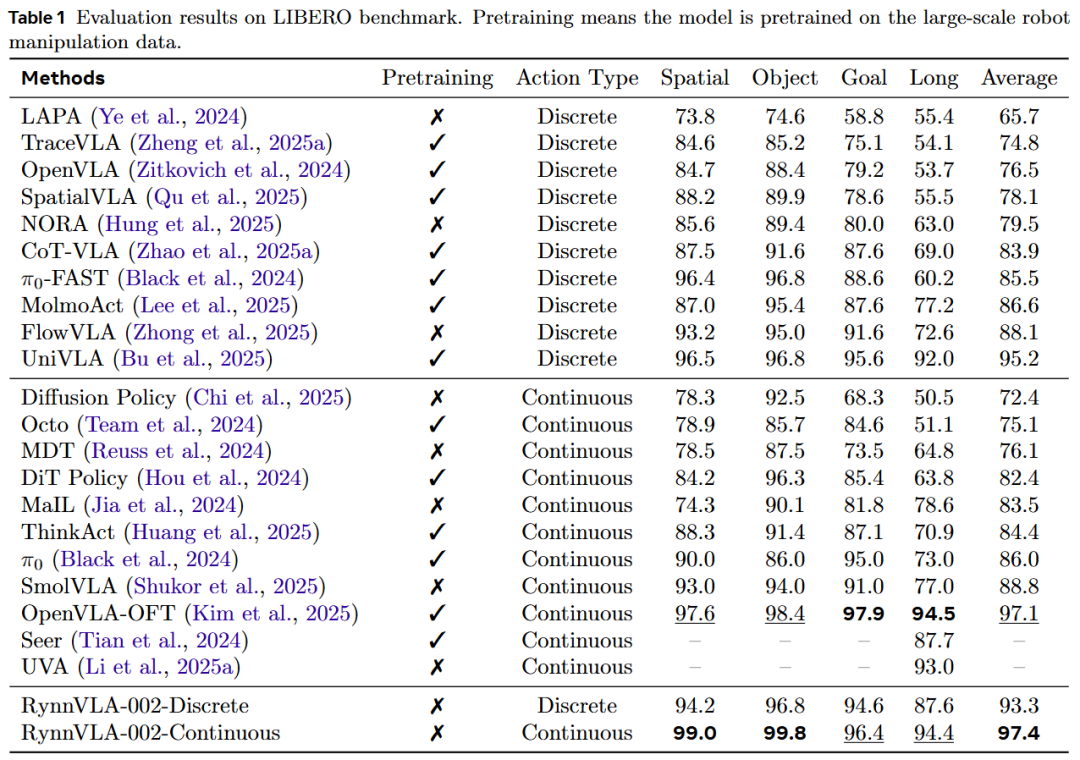
Simulation Experiments (LIBERO): RynnVLA-002-Continuous achieves a 97.4% average success rate, excelling in Spatial, Object, Goal, and Long tasks. Outperforms strong baselines like OpenVLA and SpatialVLA without requiring large-scale robotic operation pre-training data.
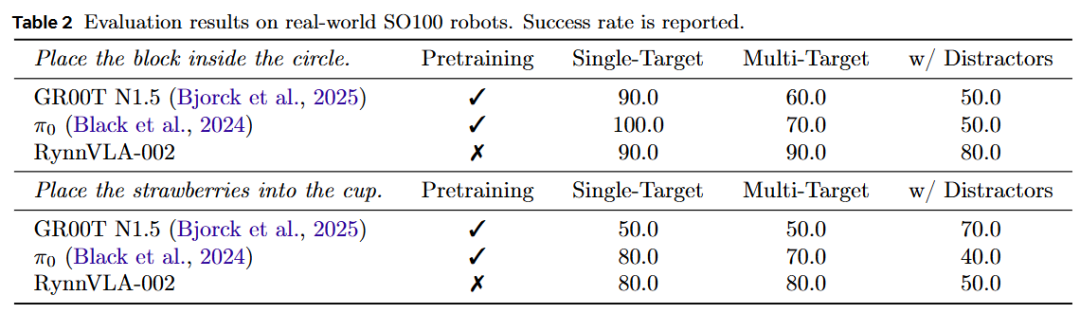
Real-World Experiments (LeRobot SO100): Demonstrates strong robustness in distractor and multi-target scenarios. Outperforms GR00T N1.5 and others by 10% to 30% in complex scenarios.
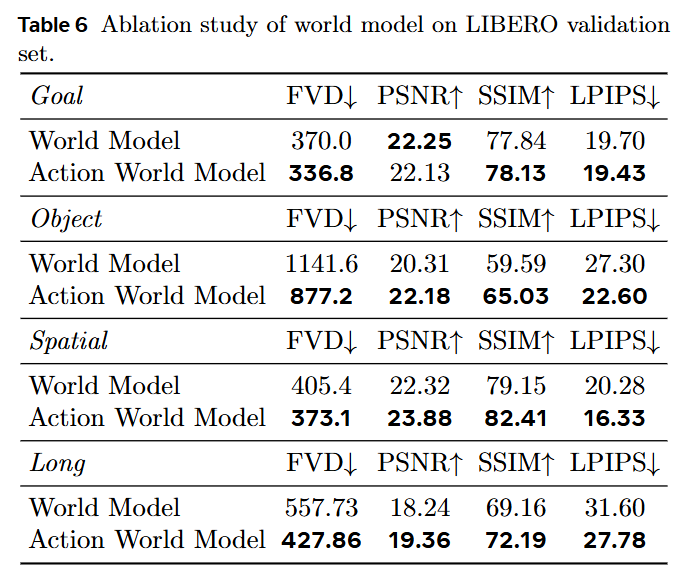
Complementary Verification: Ablation experiments prove that world model data training significantly enhances VLA operational success rates (especially grasping tasks), while VLA data improves world model video generation quality.
Methodological Framework
Overview
RynnVLA-002's overall architecture aims to unify two foundational models of expressive AI:
VLA Model: Strategy generates actions based on language goals , proprioceptive states , and historical observations :
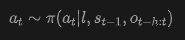
World Model: Model predicts next observation based on past observations and actions :

This work combines VLA model data and world model data to train RynnVLA-002, an integrated model sharing parameter groups . This dual nature enables the model to flexibly operate as a VLA or world model based on user queries.
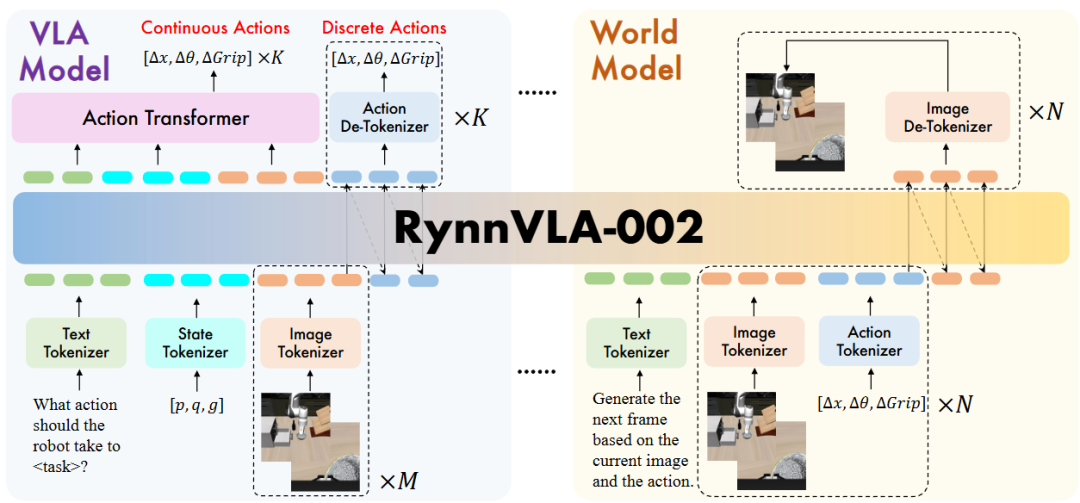 RynnVLA-002 Overview. RynnVLA-002 involves VLA model data and world model data during training.
RynnVLA-002 Overview. RynnVLA-002 involves VLA model data and world model data during training.
Data Tokenization
Tokenizers: Model initialized from Chameleon. Involves four Tokenizers: image, text, state, and action.
Images: Uses VQ-GAN with added perceptual losses for specific regions (e.g., faces, salient objects). Images are encoded as discrete Tokens (256 Tokens per image).
Text: BPE Tokenizer.
States & Actions: Discretizes each continuous dimension of robot proprioceptive states and actions into one of 256 bins.
Vocabulary: All modality Tokens share a vocabulary of size 65536. Continuous actions are generated as raw values via Action Transformer without Tokenization.
VLA Model Data Structure:
Token sequence: {text} {state} {image-front-wrist} {action}. The model generates action chunks based on instructions, states, and historical images.
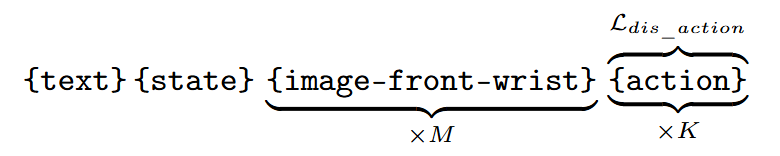
World Model Data Structure: Token sequence: {text} {images-front-wrist} {action} {images-front-wrist}. Task: generate next frame based on current image and action. Text prefix: 'Generate the next frame based on the current image and the action.'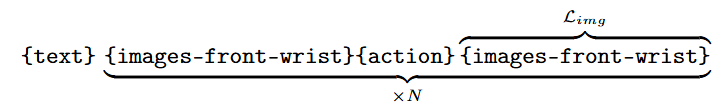
Training Objective: Combines two data types for training; total loss function: .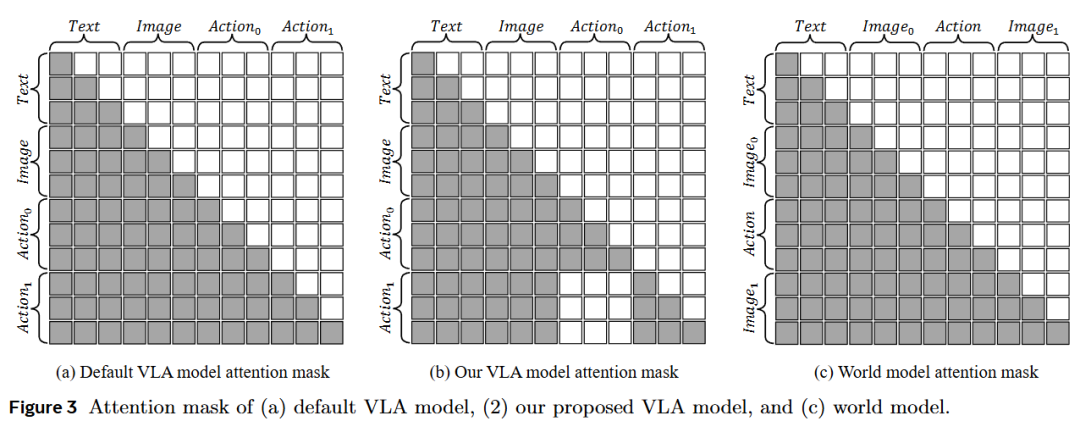
Action Chunk Generation
Attention Mask for Discrete Action Chunks: To enhance efficiency and success rates, the model generates multiple actions. Traditional autoregressive methods cause error propagation, where early action errors affect subsequent ones. This work designs a specific Action Attention Mask (Figure 3(b)) that ensures current action generation depends solely on text and visual inputs, prohibiting access to prior action Tokens. This design enables independent generation of multiple actions, effectively mitigating error accumulation.
Action Transformer for Continuous Action Chunks: While discrete models perform adequately in simulations, they struggle in real-world scenarios with dynamic variables like lighting and object positions, exhibiting poor performance and non-smooth actions. This work introduces an Action Transformer module:
Principle: Processes complete context (language, image, state Tokens) and utilizes learnable Action Queries to output entire action chunks in parallel.
Advantages: More compact architecture, less prone to overfitting on limited data; parallel generation of all actions significantly faster than sequential autoregressive baselines; generates smoother, more stable trajectories.
Loss Function: Uses L1 regression loss .
Final Total Loss Function:

Experiments
Metrics: This work's evaluation is divided into two parts. To assess VLA models, it measures success rates across 50 deployment rollouts per task, each initialized in different states. To evaluate world models, it uses four standard metrics to measure video prediction accuracy on a held-out validation set: Fréchet Video Distance (FVD), Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS).
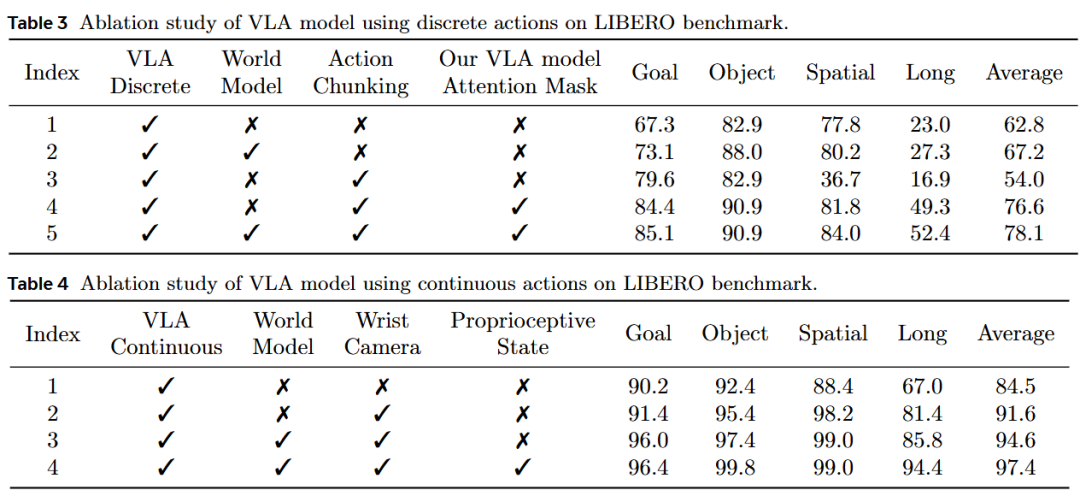
Benchmark Results: This work evaluates discrete and continuous action performance separately. As shown in Table 1, RynnVLA-002 achieves a high success rate of 93.3% with discrete actions and 97.4% with continuous actions, proving the effectiveness of its core design principles: joint learning of VLA and world modeling, the attention mask mechanism for discrete action generation, and the added continuous Action Transformer. Surprisingly, even without pre-training, RynnVLA-002 performs comparably to strong baseline models pre-trained on LIBERO-90 or large-scale real robot datasets.
Real-World Robot Results
Datasets:
This work compiles a new real-world manipulation dataset using the LeRobot SO100 robotic arm. All trajectories are expert demonstrations obtained through human teleoperation. It defines two grasping and placement tasks for evaluation: (1) Place a square inside a circle: Emphasizes basic object detection and grasping execution (248 demonstrations); (2) Place a strawberry into a cup: Requires fine-grained localization and grasping point prediction (249 demonstrations).
Baselines:
This work compares against two strong open-source baselines: GR00T N1.5 and . For both methods, it initializes from official pre-trained checkpoints and fine-tunes them on the same SO100 dataset used for its model. It adopts the same fine-tuning recipes from the official codebases of these baselines.
Evaluation (Evaluation)
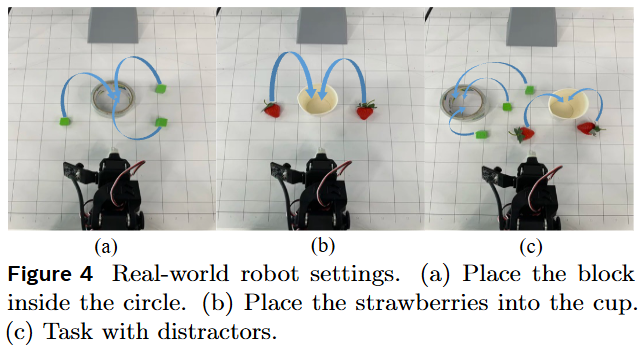
As shown in Figure 4, the evaluation in this work covers three scenarios:
Single-target Operation (Single-target): There is only one target object on the desktop;
Multi-target Operation (Multi-target): There are multiple target objects;
Instruction-following with Distractors (Instruction-following with distractors): Both target objects and distractors appear simultaneously.
A trial is considered successful if the robot places at least one target object into the designated position within a predefined time budget. A trial fails if any of the following occur: (1) Exceeding the time limit; (2) The robot accumulates more than five consecutive failed grasping attempts on a single target; (3) In the instruction-following with distractors setting, the agent attempts to manipulate any distractor object. Each task is tested 10 times, and this work reports the success rate.
Results
Table 2 below shows the experimental results for real-world robots. Without pre-training, RynnVLA-002 achieves competitive results with GR00T N1.5 and other baselines. Notably, RynnVLA-002 outperforms the baselines in cluttered environments. For example, in the multi-target task and the scene filled with distractors for the 'block placement' task, RynnVLA-002 achieves a success rate exceeding 80%, surpassing the baselines by 10% to 30%.
Ablation Experiments

World Model Feeding Back to VLA: On LIBERO, after incorporating world data, the average success rate for discrete actions increased from 62.8% to 78.1%. For real robots, the absence of world data resulted in a success rate dropping below 30%. Visualization revealed that after joint training, the robotic arm would 'proactively retry' grasping, indicating a higher focus on object dynamics.
VLA Feeding Back to World Model: The world model trained with mixed data performed equally or better than the pure World model in terms of FVD, PSNR, SSIM, and LPIPS. Video visualization showed that the baseline world model often missed predicting key frames of 'the bowl being successfully grasped,' while our model accurately generated the contact and lifting process during grasping.
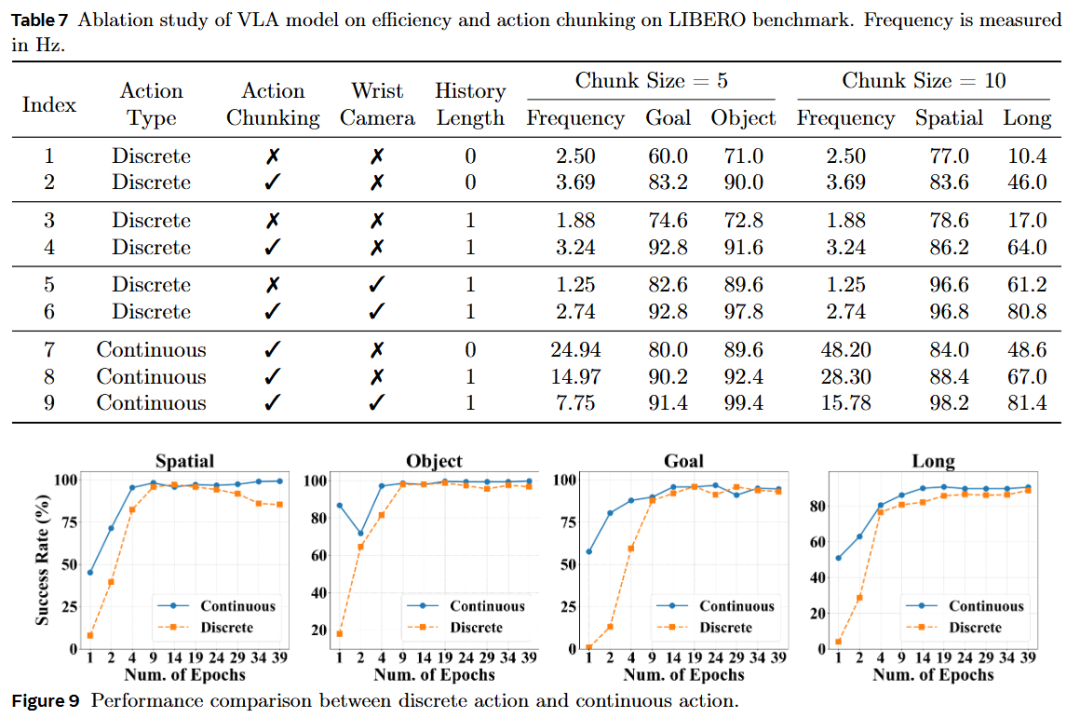
Pre-training Effect of Discrete Action Tokens: Using discrete action tokens as auxiliary input to the continuous head significantly accelerated convergence (Figure 8).
Wrist Camera & Body State: Both are indispensable in real-world scenarios; the absence of either component leads to incorrect grasping timing or complete failure.
Efficiency and Chunk Length: The frequency of continuous action inference grows almost linearly with chunk length, maintaining a 97% success rate at 48 Hz. Discrete actions can also be increased from 2.5 Hz to 3.7 Hz per step through chunking.
World Model Pre-training: Pre-training purely with world data in Stage 1 before switching to the VLA task improved the success rate for 'Goal' tasks from 67.3% to 73.1%, validating the effectiveness of 'physical knowledge cold start' for subsequent policy learning.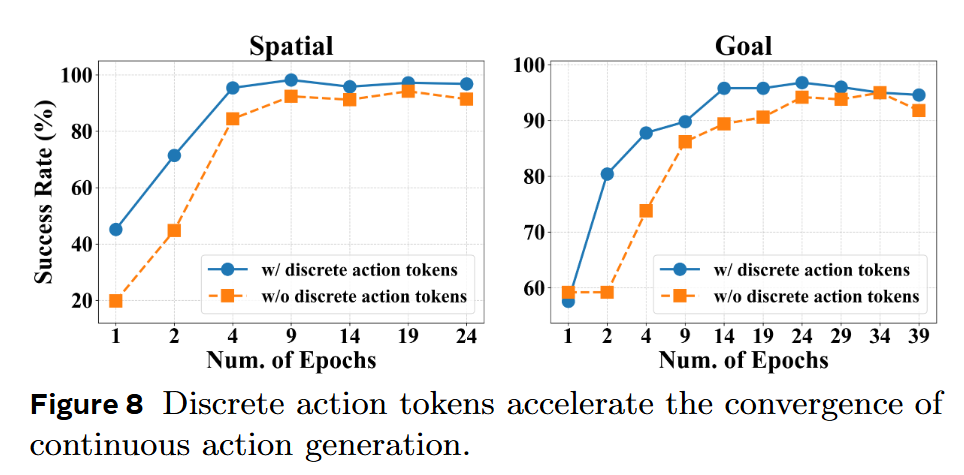

Conclusion
RynnVLA-002, a unified framework that integrates VLA and world models, demonstrates their mutual enhancement. Through this contribution, this work aims to provide the Embodied AI research community with a concrete methodology to achieve synergy between VLA and world models. Furthermore, this work believes that this research helps lay a unified foundation for multimodal understanding and generation across text, vision, and actions.
References
[1] RynnVLA-002: A Unified Vision-Language-Action and World Model
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






