ICCV`25 | Unleash Video Interaction 'At Will'! Fudan & Tongyi Wanxiang Open-Source DreamRelation: Let Imagination Know No Bounds
 11/28 2025
11/28 2025
 736
736
Interpretation: The Future of AI-Generated Content

Highlights
First Relational-Oriented Video Customization Framework: This work is the first attempt to tackle the 'relational video customization' task, which involves generating new videos with specific interaction relationships (e.g., handshakes, hugs) but different subjects, based on a small number of sample videos.
Interpretable Model Design: By analyzing the features of Query (Q), Key (K), and Value (V) in the MM-DiT architecture, we discovered their distinct roles in representing relationships and appearances, leading to the design of an optimal LoRA injection strategy.
Innovative Decoupling and Enhancement Mechanisms: We propose the 'Relation LoRA Triplet' and 'Hybrid Mask Training Strategy' to decouple relationships from appearances, and the 'Spatio-Temporal Relational Contrastive Loss' to enhance dynamic relationship modeling.
Challenges Addressed
Existing video generation and customization methods primarily focus on customizing subject appearances or single-object motions. However, these methods face significant challenges when handling complex interaction relationships (e.g., interactions between two subjects):
Complexity: Relationships involve complex spatial arrangements, layout changes, and subtle temporal dynamics.
Entanglement Issue: Existing models often overfocus on irrelevant visual details (e.g., clothing, background) and fail to accurately capture the core interaction logic.
Poor Generalization: General text-to-video models (e.g., Mochi) struggle to generate counterintuitive interactions (e.g., 'a bear hugging a tiger') even with detailed prompts.
Figure 2. (a) Even with detailed descriptions, general video DiT models like Mochi often struggle to generate unconventional or counterintuitive interaction relationships. (b) Our method can generate videos with new subjects based on specific relationships.
Proposed Solution
This work introduces DreamRelation, which addresses the aforementioned issues through two concurrent processes:
Relational Decoupling Learning: Utilizes the designed 'Relation LoRA Triplet' to separate relational information from subject appearance information. By analyzing the attention mechanism of MM-DiT, the optimal placement of LoRA components is determined.
Relational Dynamics Enhancement: Introduces the 'Spatio-Temporal Relational Contrastive Loss' to force the model to focus on relational dynamics rather than static appearances by bringing dynamic features of similar relationships closer and pushing away single-frame appearance features.
Applied Technologies
MM-DiT Architecture: Based on Mochi (an asymmetric diffusion Transformer) as the foundational model.
Relation LoRA Triplet: A set of composite LoRAs, including Relation LoRAs (injected into Q and K matrices) for capturing relationships and Subject LoRAs (injected into V matrices) for capturing appearances.
Hybrid Mask Training (HMT): Utilizes Grounding DINO and SAM to generate masks, guiding different LoRAs to focus on specific regions.
Space-Time Relational Contrastive Loss (RCL): A contrastive loss function based on InfoNCE that utilizes frame differencing to extract dynamic features.
Achieved Results
Qualitative Effects: Capable of generating videos with specific interaction relationships and successfully generalizing to novel subjects (e.g., 'animals imitating human interactions'), with less background leakage and more accurate relationship expression.
Quantitative Metrics: On a constructed dataset containing 26 types of human interactions, DreamRelation outperforms existing state-of-the-art methods (including the native Mochi model, MotionInversion, etc.) in terms of relational accuracy (Relation Accuracy), text alignment (CLIP-T), and video quality (FVD).
User Evaluation: In human evaluations, DreamRelation received the highest user preference in terms of relational alignment, text alignment, and overall quality.
DreamRelation Architecture and Methodology
This work aims to generate videos that align with textual prompts and contain specified relationships based on a small number of sample videos, as shown in Figure 4.
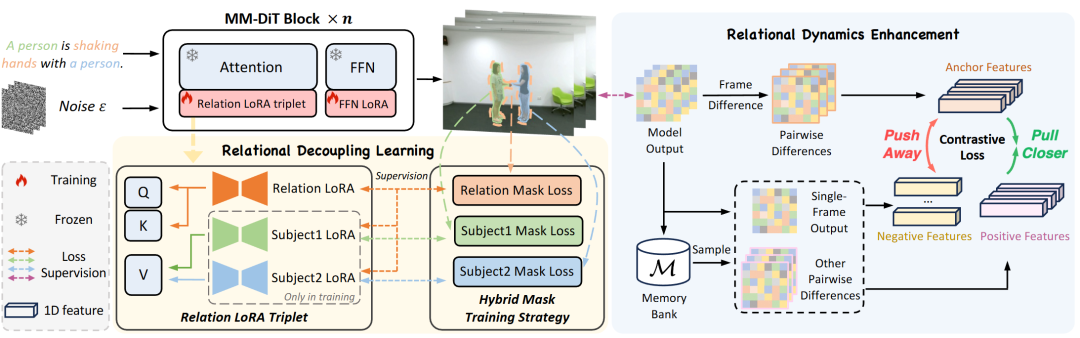
Figure 4. The overall framework of DreamRelation. Our method decomposes relational video customization into two concurrent processes. (1) In relational decoupled learning, the Relation LoRA within the Relation LoRA Triplet captures relational information, while the Subject LoRA focuses on subject appearance. This decoupling process is guided by a hybrid mask training strategy based on corresponding masks. (2) In relational dynamics enhancement, the proposed spatio-temporal relational contrastive loss brings dynamic features of relationships (anchor and positive features) closer from pairwise differences while pushing them away from appearance features (negative features) of single-frame outputs. During inference, Subject LoRAs are excluded to prevent the introduction of unwanted appearances and enhance generalization.
Preliminary Knowledge of Video DiTs
Text-to-video diffusion Transformers (DiTs) have garnered increasing attention due to their ability to generate high-fidelity, diverse, and long-duration videos. Current video DiTs (e.g., Mochi, CogVideoX) primarily adopt the MM-DiT architecture with full attention mechanisms and perform the diffusion process in the latent space of a 3D VAE. Given a latent code (derived from video data) and its textual prompt, the optimization process is defined as:

where is random noise from a Gaussian distribution, and is the noise latent code at time step based on and a predefined noise schedule. This work selects Mochi as the foundational video DiT model.
Relational Decoupled Learning
Relation LoRA Triplet To customize complex relationships between subjects, this work decomposes the relational patterns in sample videos into independent components emphasizing subject appearances and relationships. Formally, given a small number of videos showcasing interactions between two subjects, their relational pattern is represented as a triplet: subject1-relationship-subject2, abbreviated as , where and are the two subjects, and is the relationship.
To distinguish relationships from subject appearances in the relational pattern, this work introduces the Relation LoRA Triplet, a set of composite LoRAs comprising Relation LoRAs for modeling relational information and two Subject LoRAs for capturing appearance information (as shown in Figure 4). Specifically, Relation LoRAs are injected into the Query (Q) and Key (K) matrices of the MM-DiT full attention mechanism. Meanwhile, two Subject LoRAs corresponding to the two subjects involved in the relationship are designed and injected into the Value (V) matrix. This design is supported by empirical findings: Q, K, and V matrices play distinct roles in the MM-DiT full attention mechanism. Additionally, an FFN LoRA is designed to optimize the outputs of Relation and Subject LoRAs and is injected into the linear layer of the full attention mechanism. Note that the text and visual token branches in MM-DiT are processed by different groups of LoRAs.
Hybrid Mask Training Strategy To achieve decoupling of relational and appearance information in the Relation LoRA Triplet, this work proposes the Hybrid Mask Training Strategy (HMT), which utilizes corresponding masks to guide Relation and Subject LoRAs to focus on designated regions. First, Grounding DINO and SAM are employed to extract masks for the two individuals in the video, labeled as subject mask 1 and subject mask 2 . Inspired by representative relationship detection methods that utilize minimum bounding rectangles to delineate subject-object interaction regions, this work defines the relationship mask as the union of the two subject masks to indicate the relational region. Due to the factor compression in the time dimension by the 3D VAE in video DiTs, masks for every frames are averaged to represent the latent mask.
Subsequently, this work devises a LoRA selection strategy and a mask-based enhanced diffusion loss to facilitate better decoupling during training. Specifically, in each training iteration, either Relation LoRAs or one of the Subject LoRAs is randomly selected for updating. When Relation LoRAs are chosen, both Subject LoRAs are trained simultaneously to provide appearance cues, assisting Relation LoRAs in focusing on relational information. This process promotes the decoupling of relational and appearance information. FFN LoRAs participate throughout the entire training process to optimize the outputs of the selected Relation or Subject LoRAs.
Following LoRA selection, the corresponding mask is applied to amplify the loss weight within the region of interest, defined as follows:

where indicates the selected mask type, and is the mask weight. By adopting the LoRA selection strategy and enhanced diffusion loss, Relation and Subject LoRAs are encouraged to focus on their designated regions, thereby promoting effective relational customization and improving generalization capabilities.
Inference Phase During inference, to prevent the introduction of unwanted appearances and enhance generalization capabilities, this work excludes Subject LoRAs and injects only Relation LoRAs and FFN LoRAs into the foundational video DiT to preserve the learned relationships.
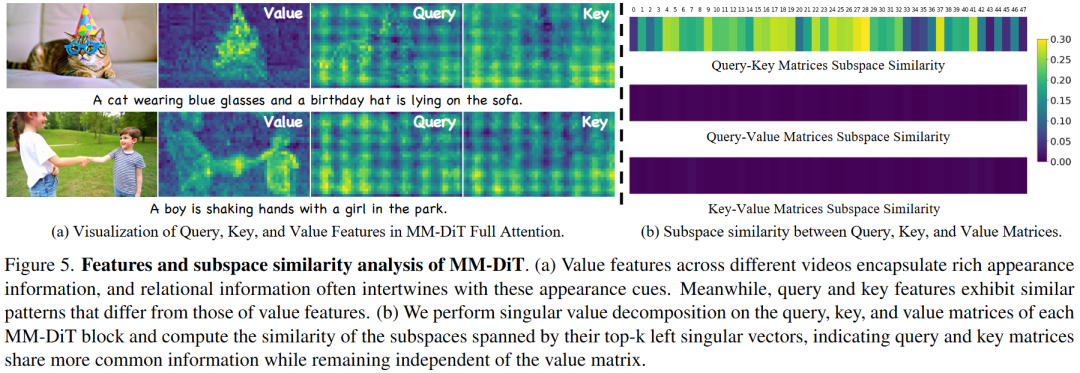
Analysis of Query, Key, and Value Features
To determine the optimal model design, this paper analyzes the query, key, and value features and matrices in the MM-DiT full attention mechanism through visualization and singular value decomposition (SVD), revealing their impact on relational video customization.
Visualization Analysis. This paper begins with two types of videos: a single-subject video containing multiple attributes and a dual-subject interaction video, as shown in Figure 5(a). The average features of queries, keys, and values associated with visual tokens across all layers and attention heads at the 60th time step are computed. These features are then reshaped into a format, and the features of all frames are averaged to visualize feature maps of shape . Based on the observations in Figure 5(a), two conclusions are drawn:
1) Value features in different videos contain rich 'appearance information,' while 'relational information' is often intertwined with these appearance cues. For example, in the single-subject video, high Value feature responses appear at locations such as 'blue glasses' and 'birthday hat.' In the dual-subject video, high values are observed in both relational regions (e.g., handshakes) and appearance regions (e.g., faces and clothing), indicating that relational information is entangled with appearance information in the features.
2) Query and Key features exhibit highly abstract yet similar patterns, distinctly different from Value features. Unlike the obvious appearance information in Value features, Query and Key features demonstrate homogeneity across different videos, clearly distinguishing them from Value features. To further validate this viewpoint, this paper quantitatively analyzes the query, key, and value matrices.
Subspace Similarity Analysis. This paper further analyzes the similarity of subspaces spanned by the query, key, and value matrix weights and their singular vectors from the foundational video DiT model, Mochi. This similarity reflects the degree of information overlap between two matrices. For the query and key matrices, left singular unitary matrices and are obtained through singular value decomposition. Following literature [32, 52], the first singular vectors of and are selected, and their normalized subspace similarity is measured based on the Grassmann distance, calculated as . Other similarity calculations follow a similar approach. The results in Figure 5(b) indicate that the subspaces of the query and key matrices are highly similar, while their similarity with the value matrix is extremely low. This suggests that the query and key matrices in MM-DiT share more common information while largely maintaining independence from the value matrix. In other words, the query and key matrices exhibit a strong non-overlapping relationship with the value matrix, which is conducive to the design of decoupled learning. This observation aligns with the visualization results in Figure 5(a). To further validate the generalizability of this finding, this paper conducts similar analyses on various models, such as HunyuanVideo and Wan2.1. The results in Figure 5(b) demonstrate that the high similarity between query and key matrices is consistently present across different MM-DiT models and other DiT architectures (e.g., cross-attention-based DiTs).
Based on these observations, this paper empirically posits that the query, key, and value matrices play distinct roles in relation-based video customization tasks, which is the motivation for designing the
Relational Dynamic Enhancement
To explicitly enhance the learning of relational dynamics, this paper proposes a novel
Subsequently, we sample 1D relational dynamic features from other videos exhibiting the same relation as positive samples . For each frame in , we sample 1D features from the single-frame model output as negative samples , which capture appearance information but exclude relational dynamics.
Our objective is to learn representations that incorporate relational dynamics by bringing the pairwise differences of videos depicting the same relation closer together while pushing them away from the spatial features of single-frame outputs to mitigate appearance and background leakage. Following the InfoNCE loss, we formalize the proposed loss as:
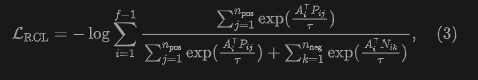
where is a temperature hyperparameter.
Additionally, we maintain a memory bank to store and update positive and negative samples, which are randomly selected from the 1D features of the current batch of videos and previously seen videos. This online dynamic update strategy can expand the number of positive and negative samples, enhancing the effectiveness of contrastive learning and training stability. In each iteration, we store all current anchor features and the 1D features of in the memory bank . The memory bank is implemented using a First In, First Out (FIFO) queue.
Overall, the training loss is composed of a reconstruction loss and a contrastive learning loss, defined as follows:

where is a loss balancing weight.
Experiments
Experimental Setup
Dataset: 26 types of human interaction relations (e.g., handshaking, hugging) were selected from the NTU RGB+D action recognition dataset.
Evaluation Protocol: 40 textual prompts involving unusual subject interactions (e.g., "a dog shaking hands with a cat") were designed to assess the model's generalization ability to new domains.
Baseline Models:
Mochi (base model).
Direct LoRA finetuning.
ReVersion (relational image customization method adapted/reproduced for video tasks). MotionInversion (motion customization method adapted for the Mochi architecture).
Evaluation Metrics:
Relational Accuracy: An advanced VLM (Qwen-VL-Max) was used to judge whether the generated videos conform to the specified relations.
Text Alignment: Image-text similarity was computed.
Temporal Consistency. Video Quality (FVD).
Experimental Results
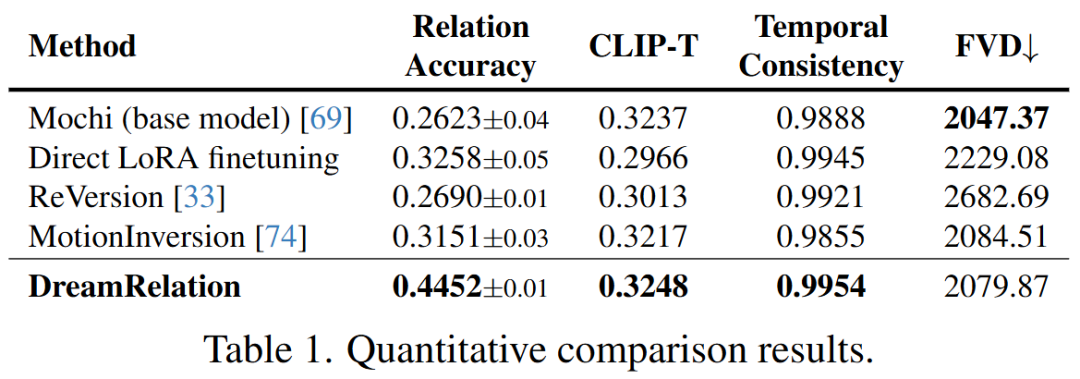
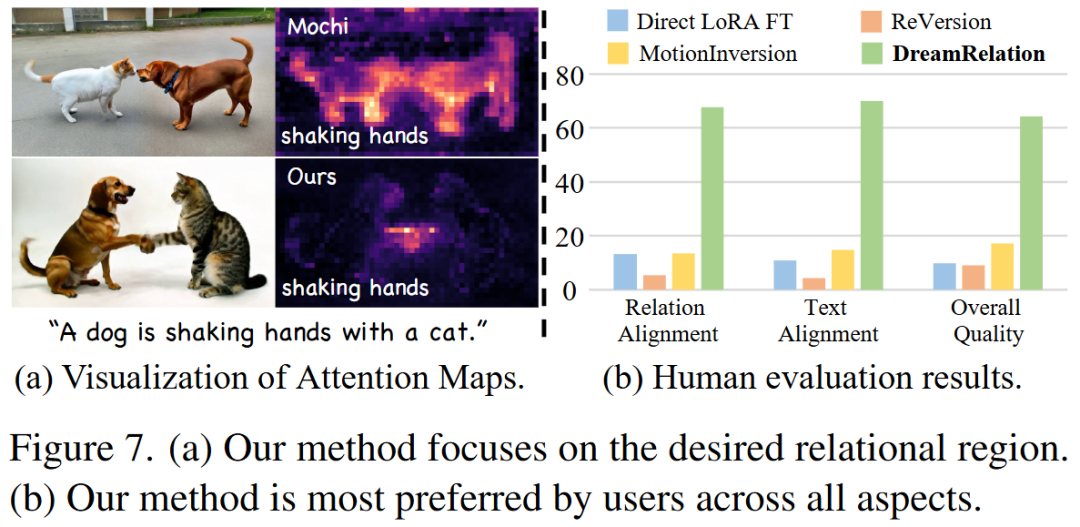
Quantitative Comparison: DreamRelation outperforms baseline methods on all metrics. In particular, relational accuracy reaches 44.52%, significantly higher than MotionInversion (31.51%) and ReVersion (27.14%). The FVD score is the lowest (lower is better), indicating the best video quality.
Qualitative Comparison: Mochi and ReVersion tend to generate static scenes or incorrect interactions and often exhibit severe subject appearance confusion. MotionInversion suffers from noticeable background and appearance leakage issues. DreamRelation can generate natural, accurate interactions and successfully transfer relations to entirely different subjects (e.g., animals).
Attention Map Visualization: DreamRelation's attention maps clearly focus on interaction regions (e.g., hand contact points), while the base model's attention maps are more cluttered.
User Study: Blind testing was conducted by 15 evaluators on 180 video pairs, showing that DreamRelation is most favored by users in terms of relational alignment, text alignment, and overall quality.
Ablation Experiments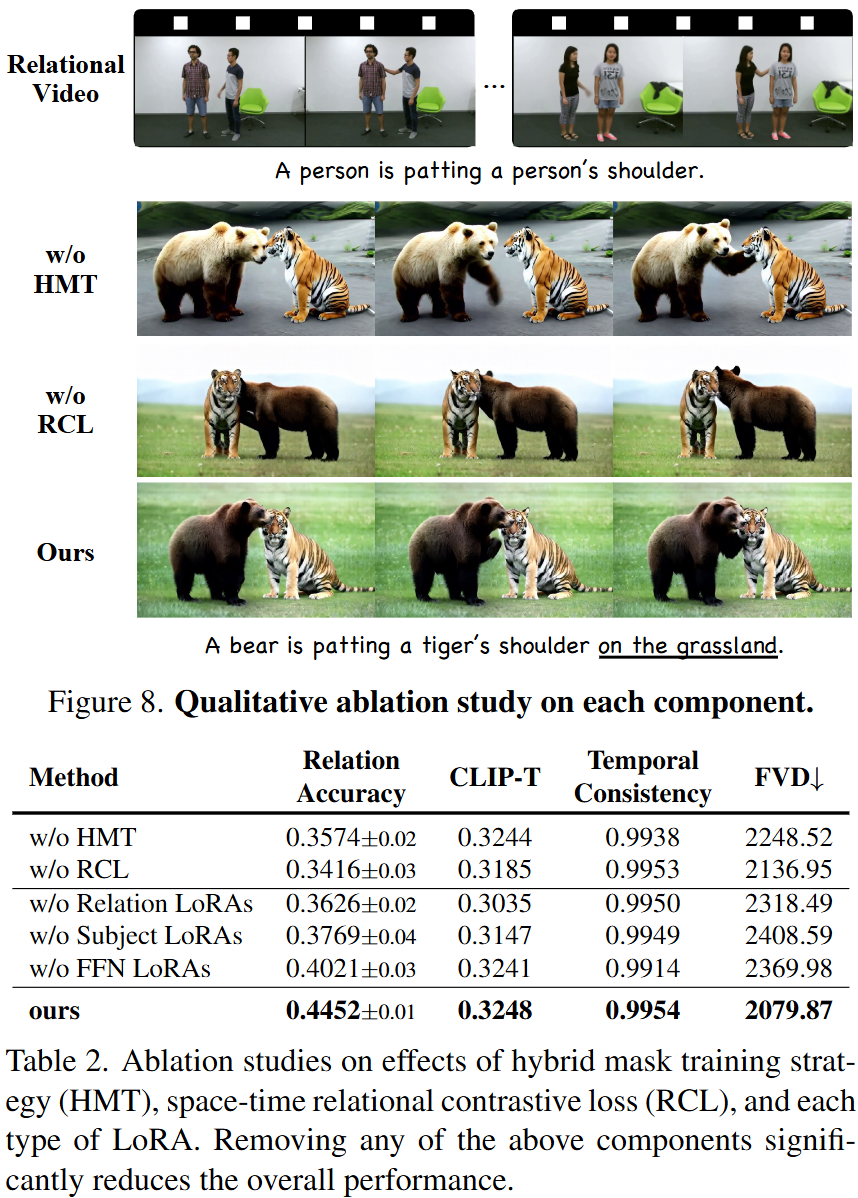
Component Effectiveness: Removing the Hybrid Mask Training strategy (HMT) leads to background leakage; removing the Space-Time Relational Contrastive Loss (RCL) reduces relational accuracy. The combination of both yields the best results.
LoRA Placement: Experiments confirm that placing Relation LoRAs in the Q and K matrices works best. Placing them in the V matrix significantly decreases accuracy, confirming the hypothesis that the V matrix primarily contains appearance information.
RCL Generalizability: Applying RCL to the MotionInversion method also improves its performance, demonstrating the universal value of this loss function.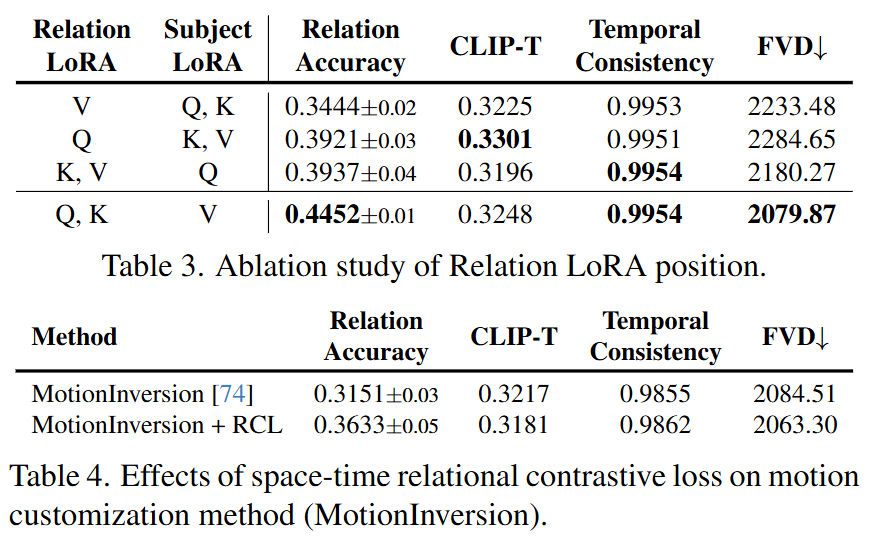
Conclusion
DreamRelation, a novel relation-based video customization method, can accurately model complex relations and generalize them to new subjects using a small number of sample videos. Through analysis based on the MM-DiT architecture, this work reveals the distinct roles of Query, Key, and Value matrices, guiding the design of the
References
[1] DreamRelation: Relation-Centric Video Customization
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






