Qwen3-VL-Flash Sees a 13.62% Performance Leap! Zhejiang University and Collaborators Introduce CoV: A Pioneering Multi-Step Reasoning Framework for Embodied Question Answering, Boosting Universal Perf
 01/14 2026
01/14 2026
 511
511
Interpretation: The AI-Powered Future Unfolds 
Key Highlights
- CoV Framework: Introduces 'Chain-of-View Prompting' (Chain-of-View, CoV), a training-free, test-time framework for embodied question answering agents.
- Active Visual Reasoning: Transforms passive visual language models (VLMs) into active viewpoint explorers, enabling them to navigate and perceive environments dynamically, akin to human behavior.
- Validates Test-Time Scaling: Demonstrates that increasing the 'action budget' during reasoning (i.e., allowing more steps and viewpoints) can continuously enhance model performance without retraining.
- Significant Universal Improvements: Shows notable performance gains across multiple mainstream VLMs (e.g., GPT-4o, Gemini, Qwen), proving its model-agnostic nature.
From Unitree's robots stealing the spotlight at the Spring Festival Gala to the inaugural 'World Humanoid Robot Olympics' captivating global audiences, 'embodied intelligence' has emerged as a defining trend in this year's AI landscape. Artificial intelligence is transitioning from the digital realm into the physical world, and embodied question answering (EQA) tasks have become increasingly critical. The core challenge of EQA lies in an agent's ability to locate critical information and generate accurate answers within complex physical spaces, mirroring human cognitive capabilities.
Traditional methods often rely on limited, fixed-perspective image inputs, making it difficult for VLMs to gather sufficient visual cues relevant to the questions. In complex EQA scenarios, answers are rarely straightforward; most require multi-step reasoning to resolve.
For example, when faced with a question like, 'Where can I find soda?', the scene may not directly display the beverage. The agent must not only draw upon common-sense knowledge—such as 'soda is usually stored in the refrigerator'—but also autonomously plan a path to locate the refrigerator within the environment. Answering such questions depends on the VLM's capacity for sustained reasoning within a rich, contextual framework, which cannot be achieved through a single generative step.
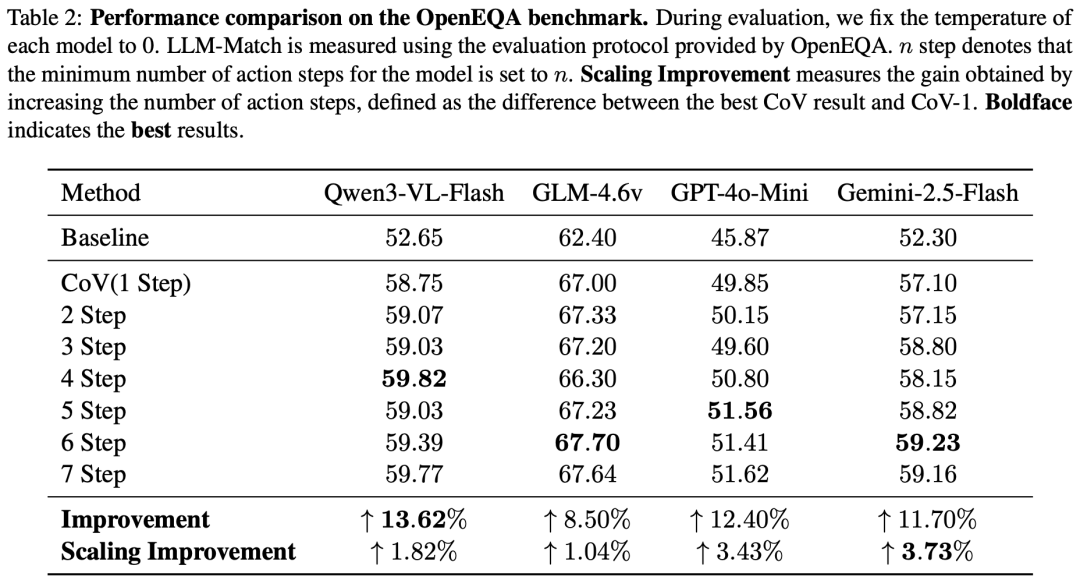
Researchers have proposed a multi-step reasoning framework for embodied question answering agents: Chain of View (CoV), designed to transition from passive observation to iterative, autonomous exploration. After applying the CoV framework, overall model performance improved by an average of 10.82% on the latest EQA benchmark tests, with the Qwen3-VL-Flash model achieving a remarkable 13.62% boost.
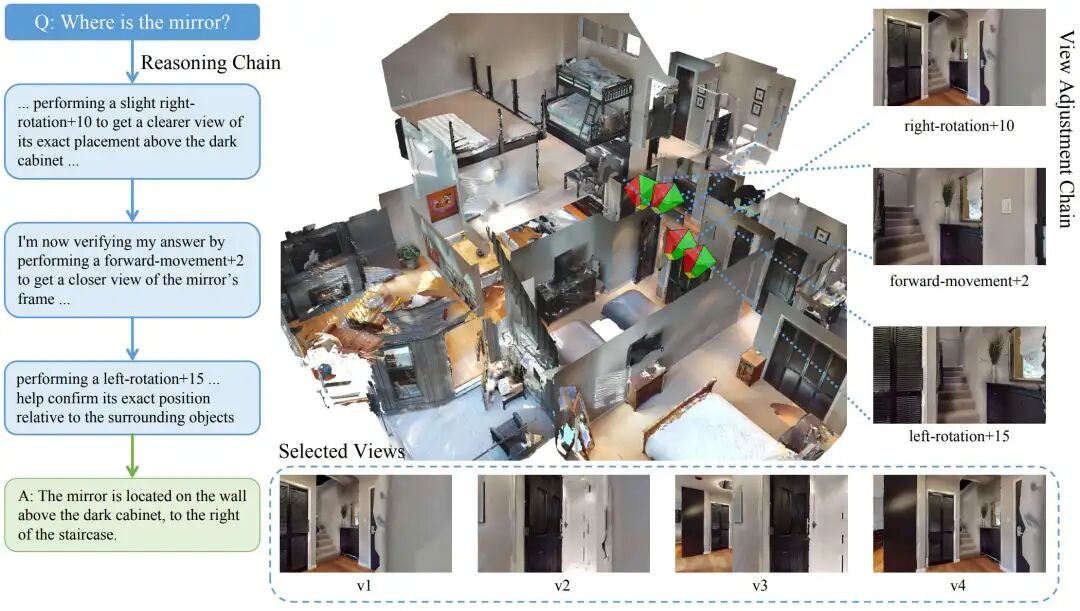
Coarse-Grained Screening for Rapid Viewpoint Anchor Determination
The CoV framework operates in two stages: Coarse-Grained Viewpoint Selection and Fine-Grained Viewpoint Adjustment.
In real-world scenarios, agents typically receive visual input from continuous video streams, which often contain redundant information. For any given question, only a few frames are truly relevant. Excessive irrelevant visual data can interfere with the model's judgment.
To address this, CoV introduces a coarse-selection agent tasked with proactively filtering out the most pertinent key viewpoints from the raw perspectives, providing a question-relevant foundation for subsequent reasoning steps.
Fine-Grained Adjustment for Precise Problem-Related Viewpoint Locking
Previous methods typically confined agents to a passive role, limiting them to answering questions from a predefined, limited set of fixed images. This 'one-step generation' approach abandons the potential for further environmental exploration, thereby restricting the model's ability to engage in deep, multi-step thinking.
Inspired by the Chain of Thought (CoT) methodology, researchers propose a fine-grained viewpoint adjustment mechanism. This approach dynamically supplements the model with environmental information relevant to the question, enabling the agent to progressively approach the answer through sustained observation and contemplation. Based on the visual anchors identified during coarse-grained selection, the VLM plans and executes a series of viewpoint adjustment actions, including panning, rotating, and switching between viewpoints.
This sequence of adjustments empowers the agent to proactively and purposefully modify its observation position and orientation, acquiring crucial environmental details essential for answering the question and enhancing EQA performance. Once the agent deems it has gathered sufficient information, it ceases adjustments and provides the final answer based on a carefully constructed visual context.

Setting New Records in EQA Benchmark Tests
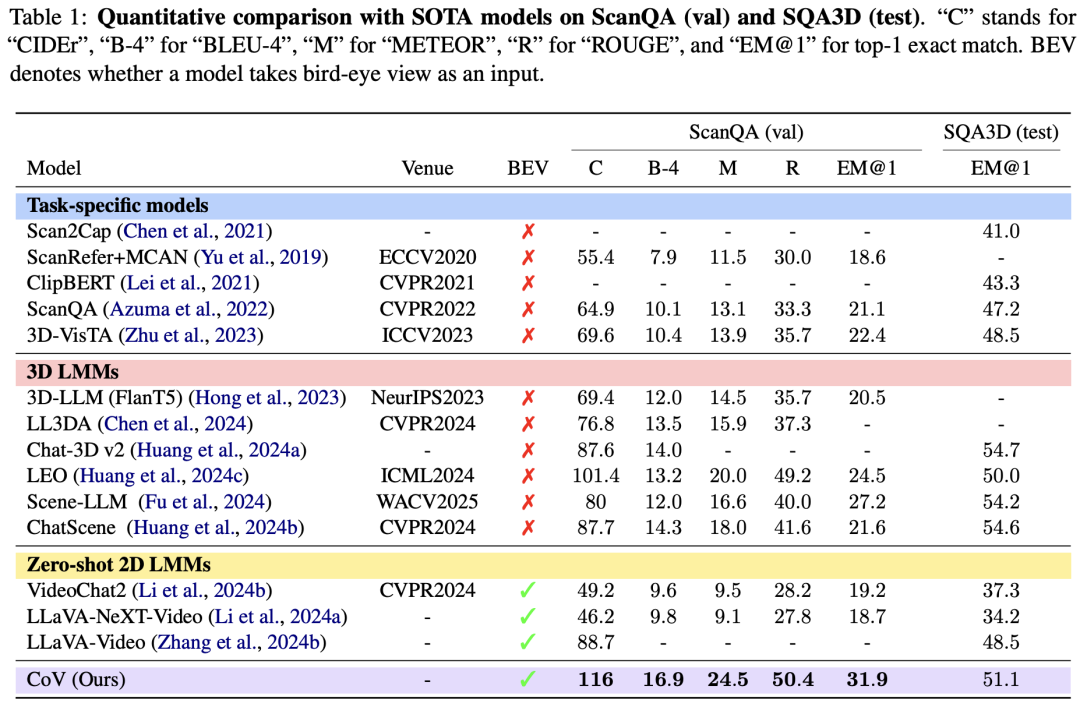
Researchers conducted extensive experiments on the latest EQA benchmarks, including OpenEQA, ScanQA, and SQA3D. On the CIDEr metric, which measures the similarity between generated text and human answers, CoV scored 116; on the ScanQA dataset, the first-attempt answer accuracy rate (EM@1) reached 31.9%. After applying the CoV framework, VLMs saw an average performance improvement of 10.82% on the OpenEQA benchmark.
Robust Test-Time Scaling Performance 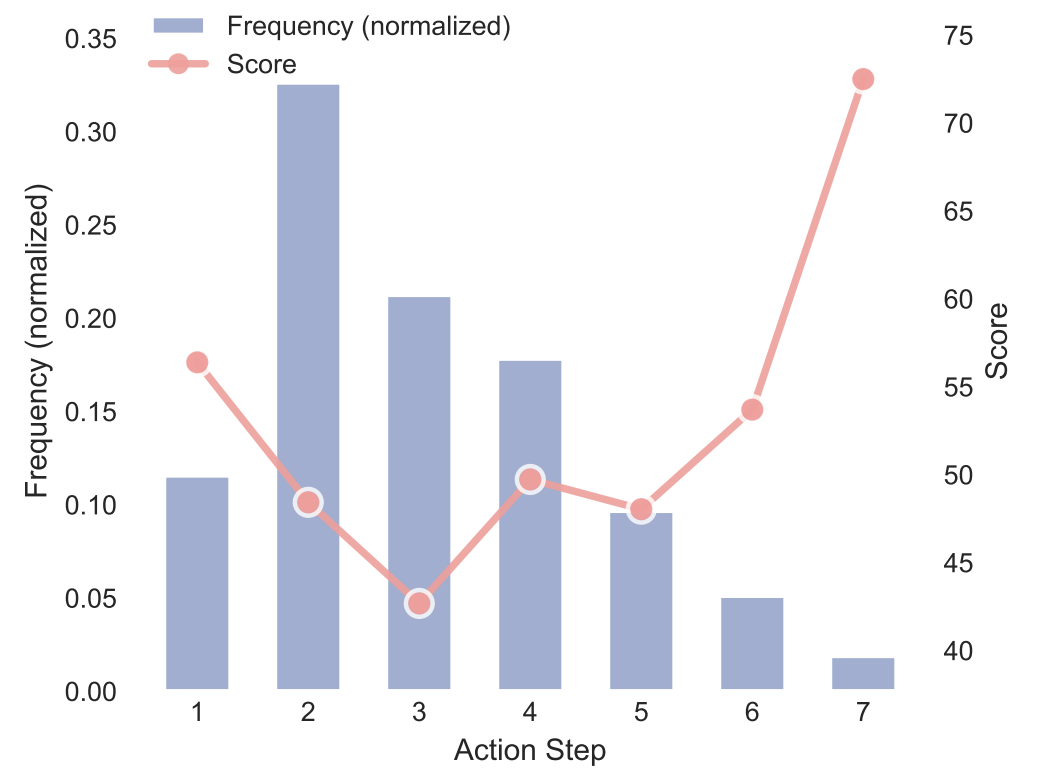
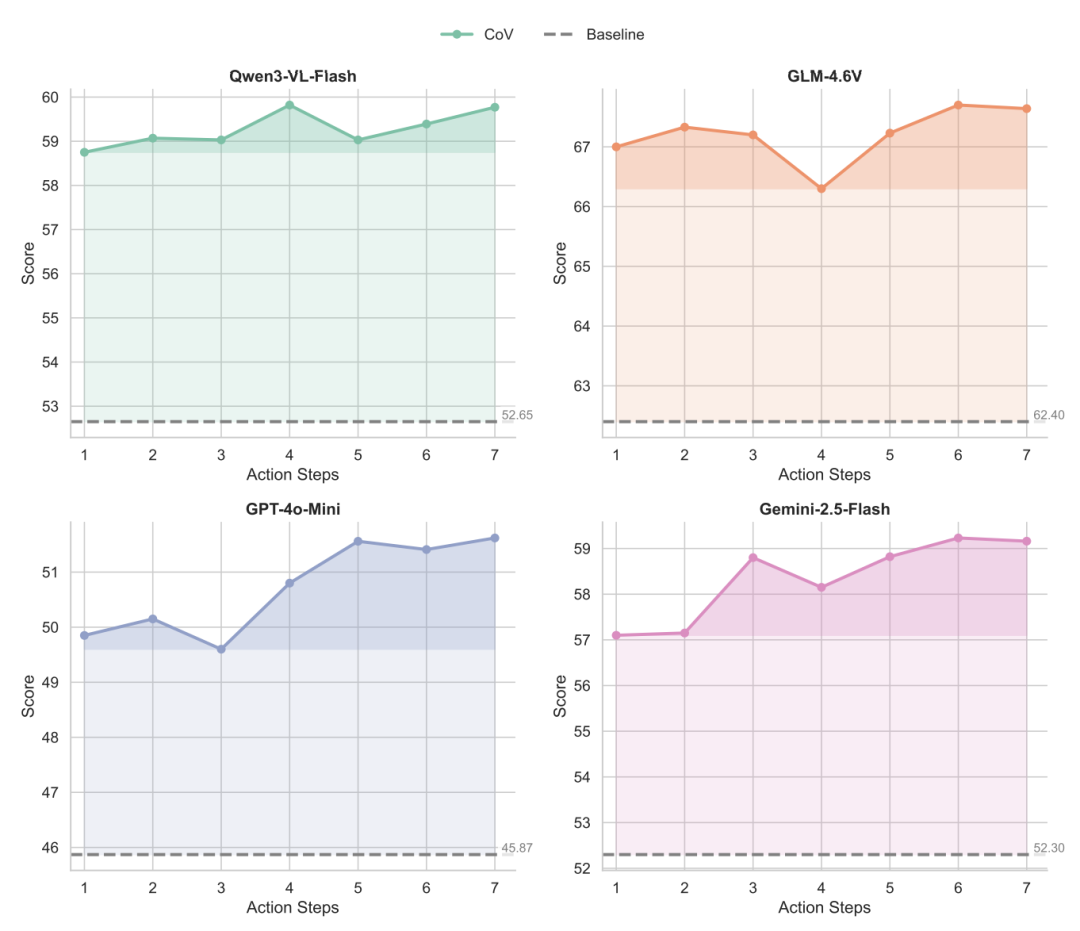
Researchers also found that as the agent takes more autonomous steps and gathers additional information, its EQA task performance improves. When steps are unrestricted, most questions require a relatively small number of steps, typically ranging from 1 to 3. As the number of action steps increases, model scores on corresponding questions show a noticeable upward trend.
By setting a minimum number of action steps in the prompt, compared to a single-step action setting, raising the step limit results in an average performance improvement of 2.51% for the VLM. This finding underscores that multi-step reasoning can significantly enhance an agent's performance in embodied question answering tasks. Without requiring additional training, CoV achieves performance gains solely by increasing action steps, demonstrating substantial 'training-free, test-time scaling' potential.
In summary, CoV represents a multi-step reasoning framework for embodied question answering agents, enabling VLMs to autonomously acquire more relevant viewpoints. This work effectively enhances VLM performance on EQA tasks and exhibits test-time scaling potential, offering new avenues for developing embodied intelligent systems capable of navigating, adapting, and exploring complex spaces.
References
[1] CoV: Chain-of-View Prompting for Spatial Reasoning
-
![]()
Jitian Xingzhou: A Pioneer in Optical Payloads Secures Hundreds of Millions in Series B Funding!
-
![]()
Orders Secured Through to the Second Half of the Year! The Rationale Behind the 'Surge' in Demand for This Company’s Optical-Grade Base Films
-
![]()
Beyond Patents: The Retail Rivalry of Insta360 and DJI Unfolds
-
![]()
180 Billion Market Cap Vanished! How Did Seres Fall So Far?
-
![]()
Blockbuster! Domestic storage takes the global double crown for the first time, from an AI company
-
![]()
China Spearheads Formulation! World's Pioneering Global Technical Regulation for Automated Driving Systems Greenlit and Unveiled
-
![]()
Farewell to Pulsed Support Policies: Three Major Auto Policy Directions from Multiple Departments Take Effect on the Same Day
-
![]()
Embercore AI’s Accelerated Funding: The Robot Industry’s Shift Toward ‘Learning Systems’