GLM-5 Architecture Details Revealed: DeepSeek Remains a Key Benchmark
 02/11 2026
02/11 2026
 555
555
With the Spring Festival just a week away, past trends indicate that the coming days will see a flurry of new AI product launches in China.
Kimi K2.5 has already made its debut on OpenRouter, while Minimax has subtly hinted at the upcoming release of version M2.2 on its official website.
All eyes are now on Zhipu and DeepSeek—will they make significant announcements before the holiday?
Indeed, within a mere 48 hours, three independent tech platforms sequentially unveiled clues about Zhipu's new model, GLM-5, piecing together a comprehensive information chain.
01 Clues Surface: Traces of GLM-5 Across Three Platforms
On February 7, the OpenRouter platform quietly introduced a model codenamed "pony-alpha."
Based on actual testing, its thought process closely mirrors that of Zhipu's GLM series. For instance:
When tackling standard questions, it begins with "Hmm,..."
For knowledge retrieval tasks, it outlines steps like "1. Analyzing the request:..."
When handling coding tasks, it clearly marks "User requested..."
After the tech community deployed this model in real-world development, they found it excelled in complex code generation tasks, such as those in Snake and Minecraft, but lacked support for multimodal inputs like images.

The following day, February 9, the vLLM inference framework repository saw a pull request (No. 34124) that explicitly featured the "GLM-5" identifier in the code for the first time.
More notably, the code revealed that its implementation logic directly reused DeepSeek's Sparse Attention (DSA) mechanism, employed by the DeepSeek-V3 series, and integrated Multi-Token Prediction (MTP) technology.
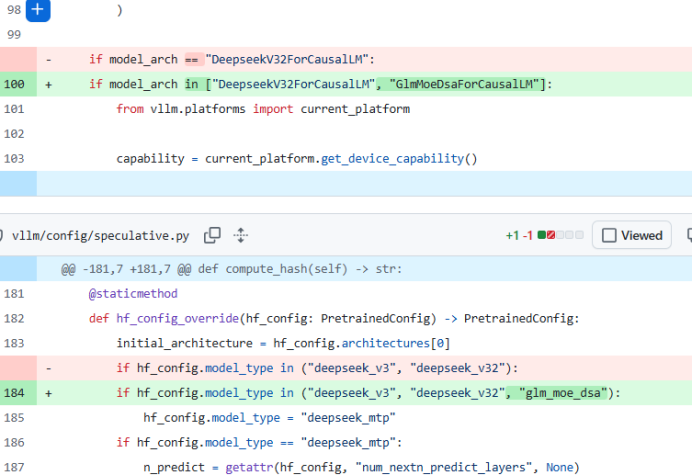
Almost simultaneously, the Hugging Face Transformers repository merged pull request No. 43858, officially introducing Zhipu's GlmMoeDsa architecture.
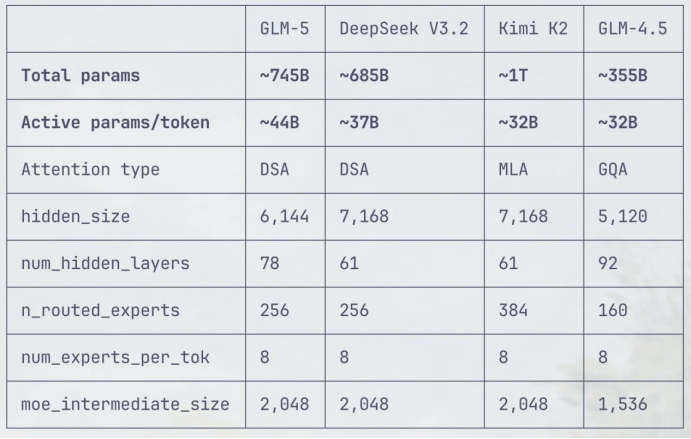
The code disclosed that GLM-5 adopted a 78-layer Transformer decoder, with the first three layers featuring a dense structure and the fourth layer onward utilizing a Mixture of Experts (MoE) architecture. It was configured with 256 expert networks, activating eight for processing a single token, supplemented by one shared expert to ensure stable foundational capabilities.
GLM-5's context window was expanded to 202K, with a vocabulary size of 154,880, representing only modest improvements over its predecessor, GLM-4.7.
02 Architecture Analysis: Balancing Efficiency and Scale
Over the past two years, the validity of the Scaling Law has been thoroughly tested.
The widely acclaimed Kimi-K2.5, with its rare 1T parameter count among domestic models, exemplified the "bigger is better" approach.
However, at the 2026 AGI Next Summit, Zhipu's founder, Tang Jie, offered a contrasting viewpoint:
While scaling models is indeed effective for enhancing intelligence, it is, in essence, "humanity's easiest way to be lazy."
Considering the upcoming GLM-5, based on community-revealed information, its technical approach clearly prioritizes "efficiency first" over merely stacking parameters.
First is the Mixture of Experts (MoE) architecture, a concept now familiar in the AI landscape. It distributes model parameters across specialized sub-networks, or "experts," invoking only the most relevant ones during inference.
GLM-5 adopts a "256 experts + 8 activated" configuration, maintaining a large total parameter count while invoking only about 3% per inference, effectively controlling computational costs and response latency.
Retaining dense structures in the first three layers ensures stable foundational language understanding capabilities, avoiding representational fragmentation caused by sparsity.
Next, Zhipu chose to adopt DeepSeek's proven Sparse Attention mechanism (DSA) rather than developing a similar mechanism in-house.
As mentioned, GLM-5's integration of DSA represents architectural reuse. The code clearly shows that the "GlmMoeDsaForCausalLM" class in GLM-5 directly inherits from "DeepseekV2ForCausalLM."

Paper link:
The DSA mechanism, open-sourced by DeepSeek five months ago, introduces a novel approach to processing long texts.
Traditional large models rely on self-attention mechanisms, where each word computes attention relationships with all preceding words, leading to computational costs that grow quadratically with text length. This makes long-text inference prohibitively expensive.
DSA, however, selects only the most relevant subset of words for in-depth computation, using a lightweight indexer to evaluate relevance quickly and output a relevance score.
By using ReLU instead of Softmax as the activation function, this process consumes only about 5% of the computational resources required by self-attention.
After obtaining relevance scores, the model selects only the top k most relevant historical words for self-attention computation. In a 128K context scenario with k=2048, computational load can be reduced by as much as 98%.
To ensure the quality of selected words, DeepSeek employed a two-stage training strategy: first, the indexer learned "which words deserve more attention" in dense attention mode, then switched to sparse attention mode once its output distribution aligned with self-attention.
In practical testing, using DSA on an H800 GPU for long-text processing reduced inference costs by about 40% to 50%, with less than 1% performance loss on core tasks.
Thus, the DSA mechanism achieves precise "on-demand allocation" of computational resources through low-cost routing, enabling the model to balance capability and efficiency in long-context scenarios.
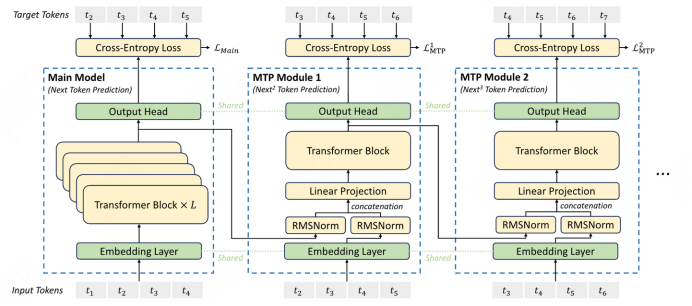
Finally, there is the Multi-Token Prediction (MTP) technology, another innovation from DeepSeek.
This inference acceleration mechanism fundamentally changes how large models generate tokens. The standard Transformer architecture uses a strict autoregressive approach, predicting only the next word in each forward computation, leading to predictable computational demands in long-text scenarios.
MTP allows the model to predict multiple consecutive words in a single forward computation, reducing iteration counts and boosting computational efficiency.
To prevent increased error rates from predicting multiple words at once, MTP relies on special training-stage design: the model simultaneously predicts the joint distribution of the current word and several subsequent words, with the loss function adjusted to cover prediction targets across multiple future positions, enabling the model to learn local word sequence generation patterns.
To illustrate, consider a Python programming scenario: when the model detects the function definition keyword "def," the traditional approach would require predicting each subsequent character one by one.
With MTP, the model might directly output the complete code statement "calculate_sum(a, b)."
The reason is simple: code follows strong syntactic rules, where function names are inevitably followed by parentheses and parameters. The model has already learned this syntactic structure during training, allowing it to safely predict multiple tokens at once.
Practical testing shows that in structured text generation tasks like code, JSON, and SQL, MTP can increase token generation speed by 2-3 times.
03 Industry Insights: The Rise of Technological Reuse
Based on community testing and technical architecture deductions, we can broadly confirm:
GLM-5 holds advantages and competitiveness in code generation and logical reasoning scenarios.
Pony-alpha's demonstrated code capabilities in the complex Minecraft project, combined with its reuse of classic DeepSeek technologies like DSA for efficient long-sequence processing, suggest GLM-5 could create differentiated value in vertical domains such as software development assistance and algorithm design.
However, its shortcomings cannot be overlooked. Community testing has clearly pointed out that GLM-5 currently lacks multimodal capabilities and cannot process non-text inputs like images and audio.
Against the backdrop of domestic mainstream large models generally evolving toward joint visual-language understanding, this deficiency will inevitably limit GLM-5's applicability in AIGC creation scenarios and become more pronounced during the Spring Festival period.
More intriguingly, while the news focuses on the new breakthroughs brought by GLM-5, every sentence implicitly revolves around DeepSeek's classic technologies.
One can only hope that Zhipu will surprise us with something new in the coming days.
Zhipu AI's choice to directly integrate open-source technologies reflects its emphasis on R&D efficiency while also indicating a shift in the domestic large model development path: "open-source + optimization" is more pragmatic than "closed-source + self-development."
The AI industry is poised to move beyond the arms race in parameter scale and focus on refining inference efficiency. Under the premise of controlling computational costs, enhancing vertical performance will become the key dimension of competition in the next phase.
-
![]()
The Complete Blueprint of Tsinghua-Affiliated Embodied AI 'Startup Dream Team': 7 Companies, 25 Billion in Funding, and the Dawn of an Era
-
![]()
The Ministry of Industry and Information Technology Forces Auto Companies to 'Self-Examine and Rectify,' Banning Unsafe Old Electric Vehicles from the Roads
-
![]()
Trump Hits the Brakes: America's Pure Electric Vehicle Race Crashes into a Wall
-
![]()
New 'Traffic Rules' for Unmanned Logistics Vehicles: No Nighttime Driving, Black Boxes Now Mandatory
-
![]()
Musk's Strategic Pivot: A Boon or Bane for Chinese Automakers?
-
![]()
Musk's Strategic Shift: A Boon or Bane for Chinese Automakers?
-
![]()
The US Hands the AI Market to Its Chinese Competitors on a Silver Platter
-
![]()
Eight Departments and One Pair of Glasses: China Writes the 'Next Gateway' into National Policy Documents