The Battle for the Final Form of Intelligent Driving: Understanding the Underlying Logic and Architectural Evolution of 'End-to-End' Autonomous Driving
 03/23 2026
03/23 2026
 564
564
At the recent GTC 2026, both OEMs like Li Auto, Xiaomi, and Geely Qianli Technology, as well as ADAS suppliers such as Yuanrong, DJI Zhuoyu, and WeRide, shared their research and applications of autonomous driving algorithms.
When it comes to advanced autonomous driving algorithms, there are essentially three key terms: 'End-to-End,' 'World Model,' and 'VLA.' These three terms largely indicate a unified direction for autonomous driving algorithm development.
Therefore, Vehicle will organize the logic and architecture of these algorithms based on the content from GTC 2026, helping everyone understand current marketing jargon, avoid being misled, or get started with autonomous driving algorithms.
First, let's talk about 'End-to-End.' Ever since Tesla launched FSD V12 in early 2024, Chinese ADAS companies have been claiming, 'We're end-to-end too.'
But by 2026, many will notice that past ADAS systems often felt like 'novice drivers,' prone to swerving, abrupt braking, or getting confused by road construction. Now, systems are increasingly driving like seasoned veterans. The core secret behind this transformation is the widespread adoption of end-to-end algorithms.
Today, we'll skip the boring math formulas and explain this hottest 'black technology' in the intelligent driving circle in the most straightforward way possible.
1. What is an End-to-End (E2E) Algorithm for Autonomous Driving?
An end-to-end large model for autonomous driving refers to a neural network system trained on large-scale data that directly takes multi-modal sensor inputs (such as cameras, LiDAR, etc.), performs representation learning and decision-making reasoning through a unified model, and outputs vehicle control commands (such as steering, acceleration, braking).
Essentially, it is a model paradigm that treats the autonomous driving task as a holistic mapping problem from input to output. You could also say they share a certain 'language' for information transmission. That's why when discussing end-to-end systems, you often see diagrams like this: one large model where 'photons go in, actions come out.' 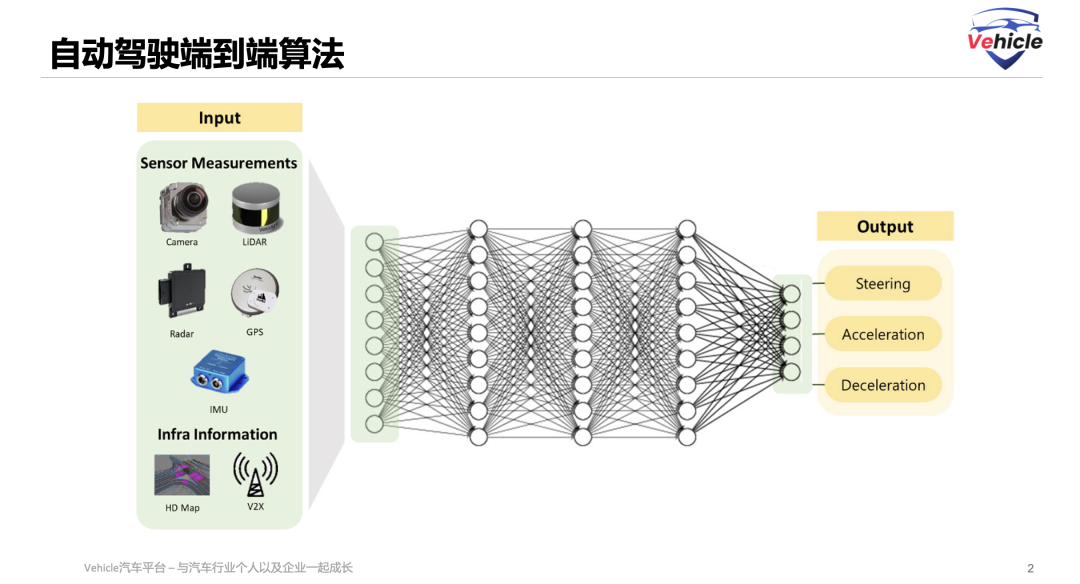
Architecturally, a common end-to-end system consists of a vision encoder plus an action decoder. End-to-end systems are characterized by fast, intuitive responses, typically learned through imitation learning, enabling a more human-like driving experience.
This sets the stage for the future development of end-to-end systems. The traditional drawback of end-to-end approaches is that they can only handle situations they've seen before—unfamiliar scenarios leave them confused. Thus, they constantly need to be fed long-tail data. When does this process end?
This led to the development of concepts like VLA and World Models based on end-to-end foundations. Now we have claims that so-called L2++ algorithms can scale to L4 because they can reason about unseen situations and learn autonomously.
Regardless, the industry consensus behind this evolution in autonomous driving algorithms can be summarized as:
The autonomous driving industry has completely abandoned rule-based planning logic and manually designed feature representations because the human world is simply too complex. Even seemingly singular tasks like traffic driving involve countless scenarios that rules cannot fully cover.
Based on this end-to-end logic, we can innovate algorithm applications and develop more human-like algorithmic thinking to create better product forms. Now that we've talked about 'end-to-end' for so long, what exactly are its types? What iterations has it undergone?
2. The Development and Types of End-to-End Algorithms
Although we often hear about end-to-end systems in marketing, the end-to-end architecture for autonomous driving in China has actually evolved through three core forms. 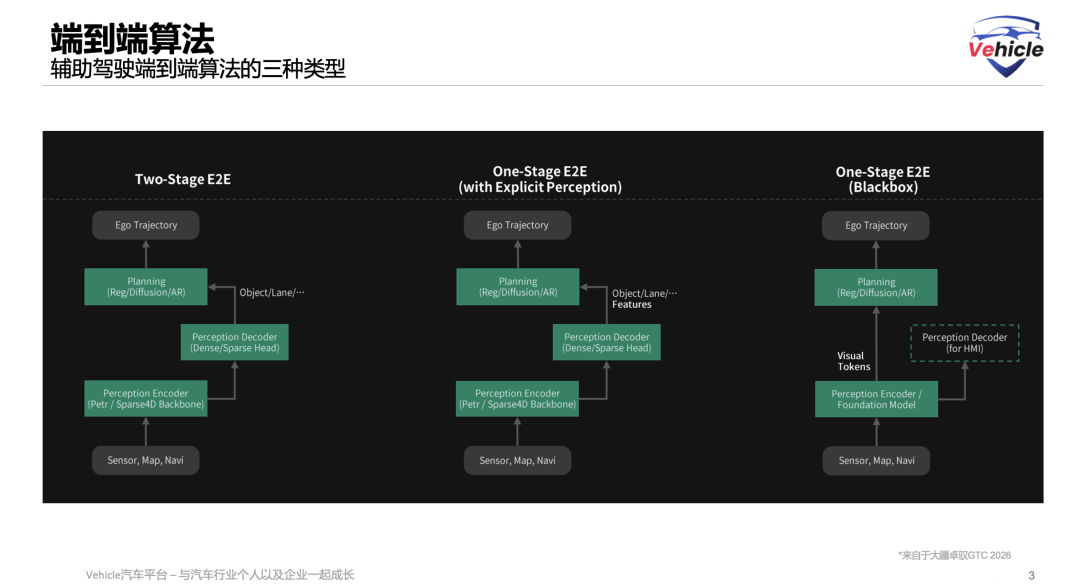
The first form was the two-stage end-to-end approach. Although called end-to-end (typically meaning the entire network can be jointly backpropagated and trained), it structurally retained the traditional two-stage 'perception-planning' serial logic. Of course, no one explicitly calls their algorithm a two-stage end-to-end system, but before Horizon Robotics announced their one-stage end-to-end approach in 2025, essentially all well-known mass-produced end-to-end systems from companies like XPENG and Momenta were likely two-stage approaches.
Its algorithmic architecture: Sensor data → Perception encoder → Perception decoder → Outputs explicit human-readable results (e.g., obstacles, lane lines) → Planning module → Vehicle trajectory.
Architectural characteristics: The planning module relies entirely on explicit physical-level results (human-readable target-level information) from the perception network for decision-making.
Advantages and disadvantages: The advantage is strong interpretability—if an accident or swerving occurs, it's easy to trace whether it was a perception miss or a planning error. The disadvantage is severe information loss, as the 3D world is compressed into a few specific labels (e.g., only outputting bounding boxes and classes), preventing many driving-relevant implicit signals (e.g., subtle pedestrian body movements, visual cues about road slipperiness) from reaching the planning module.
Some argue that strictly speaking, two-stage end-to-end systems aren't truly end-to-end—they're just labeled as such for marketing purposes in China.
The next form is the one-stage end-to-end approach with explicit perception, a transitional form or hybrid architecture currently used by many safety- and performance-balanced intelligent driving teams.
Its algorithmic architecture is consistent with the two-stage approach, but its planning module receives two inputs: one from the perception encoder's low-level high-dimensional features and another from the perception decoder's explicit results (objects/lanes...).
Architectural characteristics: The planning module can 'see' both traditional obstacles and lane lines while also directly accessing uncompressed low-level neural network features.
Advantages and disadvantages: It retains the structural constraints of explicit perception (as a safety redundancy or auxiliary supervision) while introducing rich implicit features, breaking the traditional two-stage information bottleneck.
This is currently the mainstream form of end-to-end systems in China—one-stage end-to-end trajectory output combined with post-processing of explicit perception elements. The only difference between companies is how much post-processing they apply. If the one-stage approach performs poorly, excessive post-processing makes driving unnatural, while insufficient post-processing leads to accidents. 
The ultimate end-to-end form is the 'purest' version and currently the industry's ultimate exploration target (similar to Tesla FSD V12's philosophy).
Its algorithmic architecture: Sensor data → Perception encoder (or foundation model) → Visual tokens → Planning module → Vehicle trajectory.
Architectural characteristics: It completely abandons explicit perception inputs. The planning module directly processes high-dimensional 'visual tokens,' skipping human-defined object/lane concepts. The perception decoder (for HMI) is stripped away and only used to render information on the vehicle's screen (HMI), not participating in actual driving decisions.
Advantages and disadvantages: The advantage is truly 'lossless' information transmission with extremely high theoretical potential, as the model learns purely from data how to map pixels directly to actions. The disadvantage is its typical 'black box' nature with extremely poor interpretability—if the vehicle makes a strange maneuver, engineers cannot locate and fix the issue through code debugging as before but must rely on feeding more targeted data to correct it.
The core differences among these three end-to-end forms lie in the information dimensionality of the planning module's inputs and the weight of explicit perception in the overall system.
Development is essentially a process evolving from 'modular residues' toward a 'purely data-driven black box,' with the principle of progressively reducing information loss from top to bottom.
3. Deconstructing End-to-End Algorithms: Perception Backbone Networks and Decoders
As mentioned earlier, end-to-end algorithms consist of many different modules working together to preserve and transmit information captured by sensors—what we can collectively call visual information 'tokens'—ultimately enabling precise execution by the actuator.
So what modules are involved? What algorithms do they use?
The autonomous driving perception system typically processes information through a modular relay race, with each module handling different tasks and passing information via tokens.
First leg: The Backbone Network—'Laying the Foundation' After multiple cameras capture raw 2D images, the Backbone processes them first, transforming raw pixels into 2D feature maps containing high-level semantic information like object edges, textures, and colors. This is often called the 'visual tokenizer.' Common backbone networks fall into two categories:
CNN-based Backbones: Examples include ResNet series (e.g., ResNet-50, ResNet-101), the industry's most classic and widely used foundational networks with relatively controllable computational costs. VovNet is also popular for its efficient feature fusion, favored by leading intelligent driving teams when chasing benchmarks or ultimate performance.
Transformer-based Backbones: Examples include ViT (Vision Transformer) or Swin Transformer, which feature global attention mechanisms capable of extracting superior global contextual features, making them mainstream in the large model era. Engineers optimizing Backbones often switch to versions with larger receptive fields to provide high-quality material for subsequent 3D object detection—the current mainstream algorithm.
Second leg: The Perception Framework (Neck/Head)—'Building the Skyscraper' Algorithms like PETR or Sparse4D convert basic image features into deep features with 3D or even 4D (including time) spatial and semantic understanding for input into the overall network architecture.
PETR (Position Embedding Transformation): Since cameras capture 2D images but autonomous driving needs 3D object positions, PETR uses 3D position embedding technology to directly 'fuse' 3D spatial information into the 2D Backbone's output image features.
Sparse 4D: This query-based sparse perception method doesn't explicitly convert the entire image to 3D. Instead, it iteratively updates a small number of 'query points' in the feature space to gradually focus on and understand key targets in the environment, efficiently completing 3D detection, tracking, and mapping.
Third leg: The Perception Decoder Immediately following the perception encoder, its task is to 'decode' the final perception results from the features (vehicle locations, obstacle presence, etc.). Two major schools exist:
Sparse Head (Query-based approach): The core logic is 'following the map.' It pre-defines a fixed number of 'query vectors' (e.g., 900 virtual detection points) projected into the feature map to actively search for targets. Successful matches directly output the target's 3D bounding box. Representative algorithms include DETR3D, PETR, and Sparse4D series. Advantages: extremely computationally efficient (skipping empty regions) and excellent at tracking dynamic targets (cars, pedestrians). Disadvantages: struggles to describe irregular objects (e.g., broken bricks, abnormal roadblocks, continuous flower beds).
Dense Head (Dense BEV approach): The core logic is 'carpet bombing.' It forcibly divides the 3D space around the vehicle into dense grids (e.g., 20x20x20 cm cubes), scanning and performing full convolution calculations on each grid. Representative algorithms include BEVDepth and Occupancy Networks. Advantages: provides a deadzone-free safety baseline (detecting any occupied space) and excels at static environment perception (lane lines, drivable areas). Disadvantages: extremely computationally intensive, wasting resources on countless invalid 'air grids.' 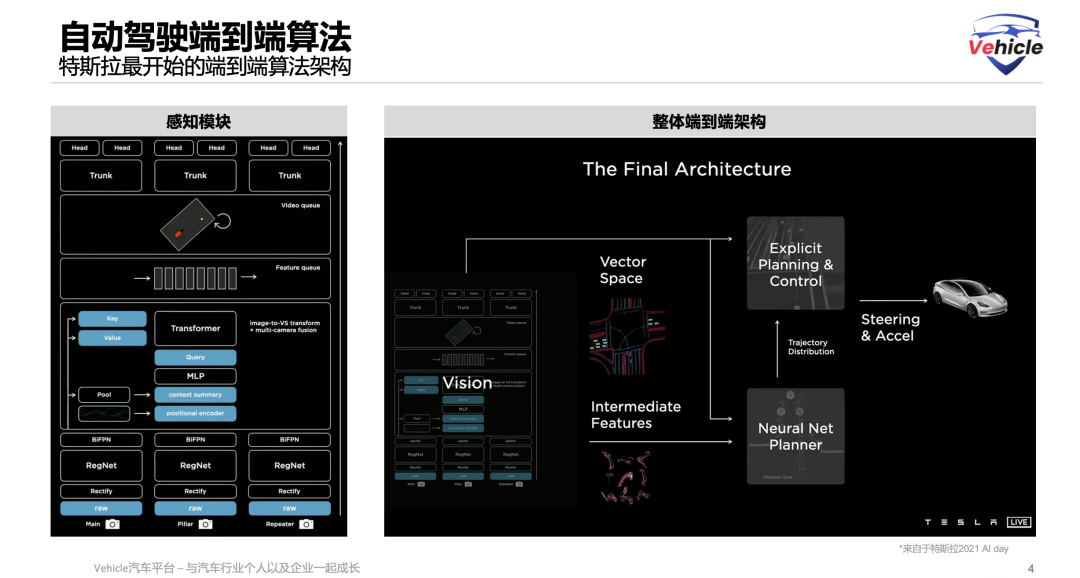
These essentially represent the core backbone modules of current end-to-end perception algorithms. Whether they continue using tokens or extract human-recognizable objects for information transfer to the planning module determines whether the algorithm is one-stage or two-stage end-to-end.
4. Deconstructing End-to-End Algorithms: The Planning Module for Generating Actions
The planning module's (Planning Decoder) core task is to generate the vehicle's trajectory for the next few seconds (coordinate points, speed, and heading angle) based on perception features for execution by the actuators.
Currently, three major algorithmic schools dominate: 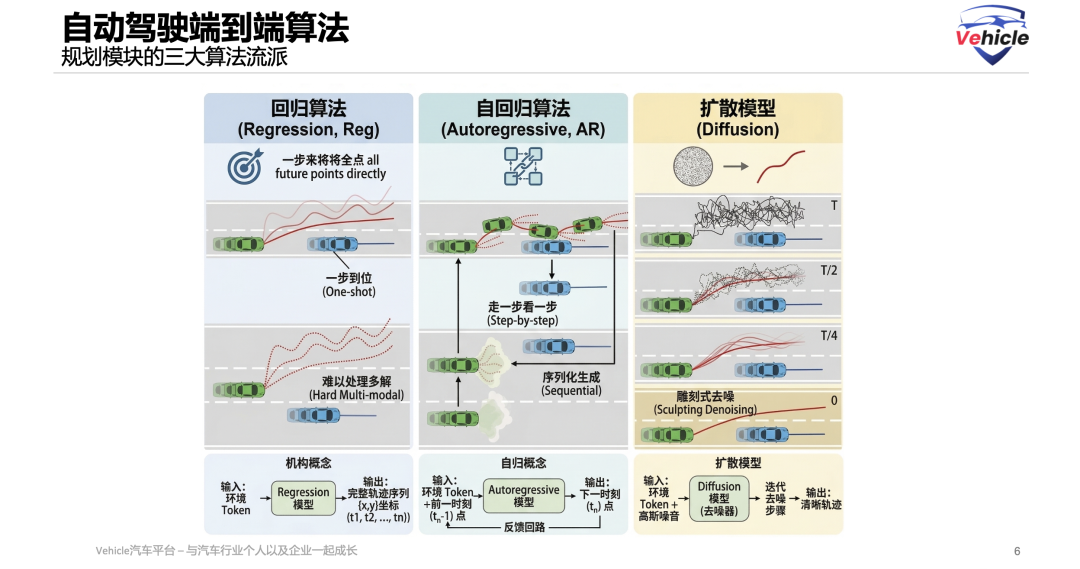
Reg (Regression): The core idea is 'one-shot' global prediction. The model glances at the current environment and simultaneously outputs all future trajectory point coordinates (e.g., x,y coordinates at moments t1, t2, t3) in one go, like an arrow instantly deciding its trajectory.
Strengths and Weaknesses: The strength lies in its extremely fast calculation speed and extremely low latency, making it highly suitable for deployment in vehicles. The weakness is its difficulty in handling 'multiple solutions' scenarios (multimodal problems). For example, when encountering an obstacle that can be bypassed either to the left or right, a simple regression algorithm will attempt to 'find the average,' resulting in a fatal trajectory that goes straight into the obstacle.
AR (Autoregressive Algorithm): The core idea is serial prediction, akin to 'taking one step at a time,' similar to how large language models generate text. After the model predicts the point at $t_1$, it feeds this back as a known condition to predict $t_2$, much like 'crossing a river by feeling the stones' or 'word chain games.'
Strengths and Weaknesses: The strength is its adherence to the causal logic of time series, ensuring coherent actions and excellent handling of 'multiple solutions' problems (outputting a probability distribution for sampling at each step). The weakness is error accumulation (Error Accumulation), where 'one wrong step leads to all wrong steps,' and due to the necessity of serial computation, the generation speed is relatively slow.
Diffusion (Diffusion Model): The core idea is iterative denoising through 'holistic refinement,' currently the most cutting-edge approach favored by companies like Li Auto and Xiaomi. It generates random, illogical 'noisy trajectories' on the road surface and then incrementally refines them over multiple steps, combining environmental features, much like sculpting—chipping away excess from a rough stone to reveal a perfect trajectory.
Strengths and Weaknesses: The strength lies in its perfect resolution of 'multiple solutions' dilemmas (simultaneously sculpting distinct yet reasonable trajectories and selecting the best one), producing smooth, human-like trajectories that well satisfy physical constraints such as vehicle dynamics. The weakness is its high computational demand, requiring repeated iterations and often necessitating techniques like Parallel Decoding for acceleration to enable onboard implementation.
Summary
With this combination of end-to-end algorithm modules, information from sensor inputs is encoded into Tokens and passed among the modules, minimizing manual information filtering and maximizing efficient transmission before being encoded into actions for execution.
Moreover, the training process becomes simpler. Data is directly fed into the model for training, which forms the so-called model parameters based on the data. These parameters can be simply understood as the amount of 'knowledge.' More detailed knowledge theoretically corresponds to a better model, but accommodating larger parameters requires more powerful computing chips.
Therefore, the completion of end-to-end algorithm construction will inevitably lead to competition in model parameter scale, chip computing power, and model application innovation, such as world models and VLA.
Finally, while algorithms are crucial tools for autonomous driving, the autonomous driving product is where the interaction with application scenarios is most profound. Friends interested in autonomous driving products can click to read 'Autonomous Driving Product Manager,' a book co-published by Vehicle and Mechanical Industry Press, which provides a detailed introduction to autonomous driving products.
References and Images
VLA World Model for Autonomous Driving pdf - DJI Zhuoyu Xiaozhi Chen
Unleashing the Omni-Paradigm for Next-Gen Autonomous Driving with Unified VLA Models pdf - Li Auto Zhan Kun
Redefining the Boundaries of Autonomous Driving with Foundation Model pdf - Yuanrong Cao Tongyi
*Reproduction and excerpting are strictly prohibited without permission-
-
How Meituan is Becoming the 'Interface' for AI Integration into the Physical World
-
![]()
RoboScience Machine Science Makes ICRA Best Paper List for Two Years Running with Its 'Embodied Brain' Innovation
-
![]()
Focusing on UTG Ultra-Thin Flexible Glass! CSG Optical New Material Production Base Establishes in Xianning, Hubei
-
![]()
AI Meets Optics: Tsinghua Smart Vision Secures A+ Round Funding Led by Hillhouse Capital
-
![]()
Why are 3C Brands Flocking to Douyin Mall During 618?
-
![]()
Token Economy Falters as Economic Tokenization Faces Challenges
-
![]()
Lenovo's Monthly Surge of 109%, Foxconn Industrial Internet's Market Cap Surpasses Kweichow Moutai: A Collective Resurgence of the 'IT Old Guard'?
-
![]()
After Zhang Xue's Victory, Where is Motorcycle Intelligence Headed?






