Generate in Real-Time at 20 FPS with Just 2 GPUs! SoulX-LiveAct Ushers in a New Era of 'Hour-Scale' Interactive Digital Humans
 03/24 2026
03/24 2026
 433
433
Analysis: The Future of AI-Generated Content 
Key Highlights
As digital human technology transitions from 'lab demonstrations' to 'live streaming applications,' the industry has long been plagued by two major challenges: First, long-duration generation failures where faces 'melt' during extended video rendering; Second, computational resource black holes requiring expensive hardware clusters to maintain smooth performance.
Recently, the Soul AI team unveiled its latest open-source model, SoulX-LiveAct. Leveraging innovative Neighbor Forcing strategies and ConvKV Memory mechanisms, the model achieves 20 FPS real-time streaming inference using just two H100/H200 GPUs while enabling true 'infinite-duration' generation—completely resolving VRAM explosion and motion drift issues in long-video production.
Summary Overview
Problems Addressed
Inconsistent Learning Signals: Most existing forcing strategies propagate sample-level representations with mismatched diffusion states, leading to inconsistent learning signals and unstable convergence.
Inference Efficiency Limitations: Unrestricted growth of historical representations without structural organization hinders effective reuse of cached states, severely limiting inference efficiency and preventing true infinite video generation.
Proposed Solutions
Neighbor Forcing:
Introduces a diffusion-step-consistent autoregressive (AR) formulation that propagates temporally adjacent frames as latent neighbors under identical noise conditions.
This design provides distribution-aligned and stable learning signals while preserving drift throughout the AR chain.
Leverages latent local smoothness of temporally adjacent frames evaluated at the same diffusion step, making AR modeling easier and more stable.
ConvKV Memory:
Introduces a structured ConvKV memory mechanism that compresses keys and values in causal attention into fixed-length representations.
Enables constant-memory inference and true infinite video generation without relying on short-term motion frame memory.
Effectively summarizes long-term contextual information using lightweight 1D convolutions without introducing additional architectural complexity.
Applied Technologies
Autoregressive (AR) Diffusion Models: Combines diffusion modeling with causal AR generation to support streaming inference and avoid fixed-length constraints.
DiT (Diffusion Transformer): SoulX-LiveAct employs the DiT model architecture combined with Flow Matching techniques.
Audio Cross-Attention: Injects audio conditions for lip synchronization and emotional expression.
Block-Level AR Diffusion Strategy: Divides sequences into contiguous blocks for generation.
FP8 Precision, Sequence Parallelism, and Operator Fusion: Optimizes real-time systems for improved hardware efficiency.
Emotion and Action Editing Module: Auxiliary module for controlling facial expressions and poses.
Achieved Results
Significant Improvements: Demonstrates markedly improved training convergence, hour-scale generation quality, and inference efficiency compared to existing AR diffusion methods.
Real-Time Performance: Enables hour-scale real-time character animation with 20 FPS streaming inference on two NVIDIA H100 or H200 GPUs.
SOTA Performance: Achieves state-of-the-art results in lip synchronization accuracy, character animation quality, and emotional expression while maintaining the lowest inference costs.
Computational Efficiency: Delivers 512x512 resolution per-frame computation at 27.2 TFLOPs, significantly lower than previous AR diffusion methods (e.g., Live-Avatar's 39.1 TFLOPs/frame).
Long-Video Consistency: Maintains stable identity representations and fine-grained details in long-video generation, resolving common issues of identity drift and detail inconsistency.
Challenge: The 'Marathon' Problem of Real-Time Digital Humans
While current autoregressive (AR) diffusion models show great potential for video generation, they face two major bottlenecks when scaling to 'hour-scale' or even 'infinite-duration' real-time interaction:
Training Inconsistency: Traditional forcing strategies suffer from mismatched diffusion states during propagation, leading to unstable signals and digital human 'breakdowns' during extended generation.
VRAM Black Hole: KV Cache grows linearly with generation length, making it difficult for single GPUs to support continuous hour-long conversations.
Core Innovations: Neighbor Forcing and ConvKV Memory
To overcome these challenges, SoulX-LiveAct introduces two key technical innovations:
Neighbor Forcing: Ensuring Every Frame Has 'Good Neighbors'
The research team proposes a diffusion-step-consistent autoregressive formulation. By treating temporally adjacent frames as 'latent neighbors' propagated under identical noise conditions, it ensures distribution alignment of learning signals. This not only enhances generation stability but also enables smoother motion transitions between frames.
ConvKV Memory: Eliminating VRAM Anxiety
Constrained by the computational overhead of long-range attention mechanisms, SoulX-LiveAct introduces a structured ConvKV storage mechanism. It compresses keys and values in causal attention into fixed-length representations, maintaining constant VRAM usage during inference. Whether generating 1-minute or 1-hour videos, memory consumption remains controlled.
Performance: Not Just Fast, but Exceptionally Stable
In multiple benchmark tests, SoulX-LiveAct demonstrates dominant performance:
Real-Time Streaming Inference: Achieves 20 FPS on dual GPUs (H100/H200), meeting high-frequency interaction requirements.
Ultimate Consistency: Supports continuous hour-scale generation with stable identity features and consistent details, avoiding common issues like facial distortion or sudden costume changes.
Multimodal Control: Supports image, audio, and text-based instruction driving, enabling the generation of digital humans with vivid expressions, controllable emotions, and rich full-body motions.
Experimental Results: Setting New SOTA Benchmarks
Quantitative metrics show that SoulX-LiveAct achieves SOTA performance in lip-sync accuracy, human animation quality, and emotional expressiveness while maintaining significantly lower inference costs than comparable models.
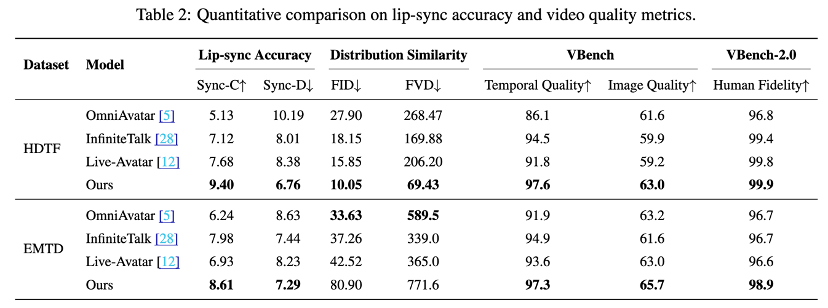
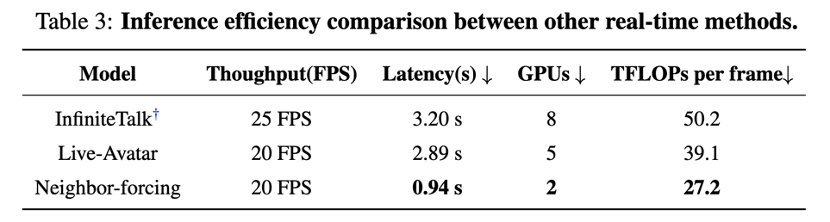

Technical Deep Dive -- Understanding SoulX-LiveAct's Foundational Logic: How Does It Redefine Generation Paradigms?
While previous technologies merely 'patched' old frameworks, SoulX-LiveAct fundamentally transforms diffusion models at their core.
Neighbor Forcing: From 'Independent' to 'Synchronized'
In autoregressive video generation, each frame depends on its predecessor. Traditional Teacher Forcing contains a hidden flaw: diffusion step misalignment.
Technical Pain Point: Models typically train with frame t and t-1 at different noise levels. During inference, small prediction errors in previous frames rapidly amplify.
SoulX-LiveAct's Solution: We introduce the Neighbor Forcing strategy. During training, adjacent frames are forced to occupy the same diffusion timestep s.
Mathematical Intuition: This design teaches the model not just single-frame denoising but conditional joint distributions between adjacent frames. It establishes a 'local trust domain' ensuring that during infinite sequence inference, each frame remains within the 'robust prediction range' of its predecessor, completely eliminating facial breakdowns.
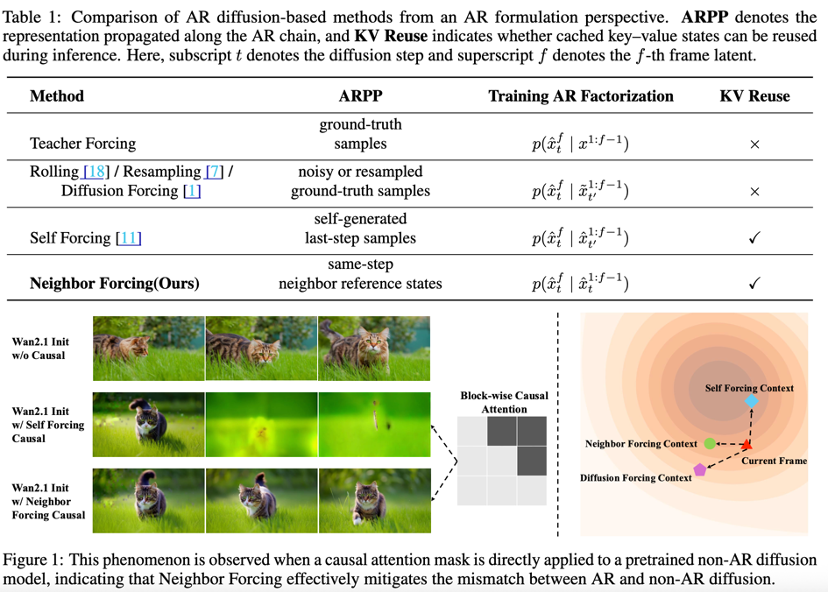
ConvKV Memory: From 'Infinite Growth' to 'Spatial Folding'
The Transformer architecture's attention mechanism suffers from computational complexity that scales with sequence length—a death sentence for real-time digital humans.
Traditional Approach: Caching all historical frames' keys and values leads to exploding VRAM usage over time.
SoulX-LiveAct's Solution: We introduce a convolution-based key-value memory network (ConvKV). Rather than brutally discarding history, it reorganizes space and dimensions.
Temporal Compression: Uses depthwise convolutions to downsample old KV caches, compressing redundant background and static pixel information.
Causal Alignment: Employs causal masking to ensure compressed memories contain only past semantic information without leaking future data.
Engineering Significance: This design reduces attention complexity from O() to constant O(1) VRAM overhead. Whether conversing for 10 seconds or 10 hours, the model always processes fixed-size 'memory blocks.'
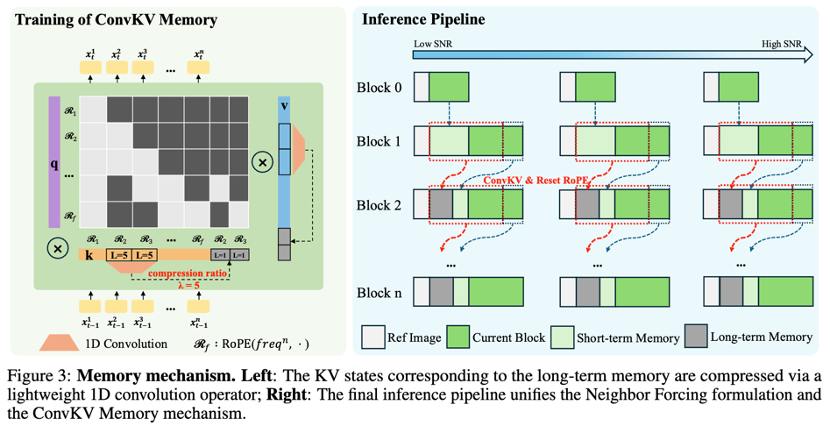
Open Source and Future Directions
The Soul AI team is committed to democratizing digital human technology. SoulX-LiveAct is now fully open-source, including technical reports, code, and pre-trained models.
References
[1] SoulX-LiveAct: Towards Hour-Scale Real-Time Human Animation with Neighbor Forcing and ConvKV Memory
-
How Meituan is Becoming the 'Interface' for AI Integration into the Physical World
-
![]()
RoboScience Machine Science Makes ICRA Best Paper List for Two Years Running with Its 'Embodied Brain' Innovation
-
![]()
Focusing on UTG Ultra-Thin Flexible Glass! CSG Optical New Material Production Base Establishes in Xianning, Hubei
-
![]()
AI Meets Optics: Tsinghua Smart Vision Secures A+ Round Funding Led by Hillhouse Capital
-
![]()
Why are 3C Brands Flocking to Douyin Mall During 618?
-
![]()
Token Economy Falters as Economic Tokenization Faces Challenges
-
![]()
Lenovo's Monthly Surge of 109%, Foxconn Industrial Internet's Market Cap Surpasses Kweichow Moutai: A Collective Resurgence of the 'IT Old Guard'?
-
![]()
After Zhang Xue's Victory, Where is Motorcycle Intelligence Headed?






