ByteDance Attempts to Break the 'Impossible Triangle' of Seedance 2.0
 03/27 2026
03/27 2026
 433
433
After Seedance 2.0 dethroned Sora, the AI video generation race entered a phase of frenzy and anxiety.
Even with the powerful capabilities of Seedance 2.0, it still cannot break the 'impossible triangle' in this field:
Model scale, generation duration, and inference speed are always difficult to achieve simultaneously.
To achieve cinematic-quality visuals like Seedance 2.0, one must have a multi-modal model with hundreds of billions of parameters designed by a major company like ByteDance. The cost is a maximum video duration of 15 seconds, expensive per-generation fees, and wait times of over ten minutes.
To generate videos quickly, one must compromise on parameter count, using a small model with around 1 billion parameters. The cost is blurry visuals, loss of detail, and collapse beyond 10 seconds.
Without achieving high-quality, real-time long videos, AI video generation will never reach the level of cinema.
However, ByteDance, the creator of the groundbreaking Seedance 2.0, has ambitions far beyond this.
The Helios large model, jointly developed by Peking University and ByteDance, is attempting to slice through this 'impossible triangle' with a sharp edge.
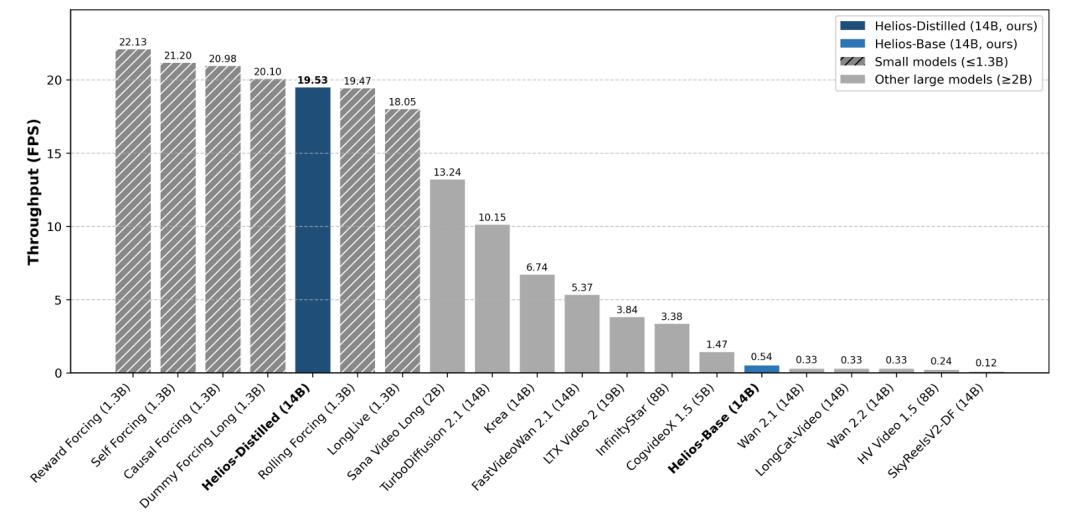
Helios is the first 14B-parameter large model capable of running on a single NVIDIA H100 GPU at 19.53 frames per second (FPS).
While not lightweight in terms of parameter count, it is a 'mini' model compared to the flagship large language models of major AI companies.
Despite its 'slender' build, its image quality rivals the strongest models available and can generate coherent (coherent) videos lasting several minutes at near 'real-time' speeds.
01
The Nightmarish 'Long-Range Drift'
Users of JIMENG, KLING, and Sora have likely wondered: Why are video generations limited to 10 or 15 seconds at most? No amount of money can break this limit.
In reality, this is not just a computational issue. Even if the generation time limit is forcibly increased, the results may not be satisfactory:
AI-generated videos often start with stunning visuals in the first few seconds, but as time passes, image quality rapidly declines. For example, the protagonist may fail to maintain facial features, limb structures may mutate, backgrounds may distort, and actions may defy physical logic.

This is the 'drift' phenomenon.
The process of AI video generation is similar to that of large language models answering questions. Large language models need to make the next response based on memory and context, while multi-modal models need to 'draw the future based on the past.'
With a fixed FPS, longer videos mean more frames, which implies an exponential increase in the information the AI must remember from each frame.
In this process, even a tiny flaw in the previously generated frames will accumulate and amplify in subsequent generations, ultimately leading to a complete collapse.
To address this issue, the earliest intuitive solution proposed by academia was to train the AI to generate long clips in one go to prevent flaws from expanding. However, this reinforcement learning method not only risks underfitting and overfitting but also has prohibitive computational costs. Large models with hundreds of billions of parameters cannot afford it, and 1 billion parameters are the limit.
Therefore, the Helios research team realized they had to look for issues in the video generation process itself.
They first noticed that long-video collapses often involve overall loss of control over brightness and color, but this issue rarely occurs in the first few seconds of the video.
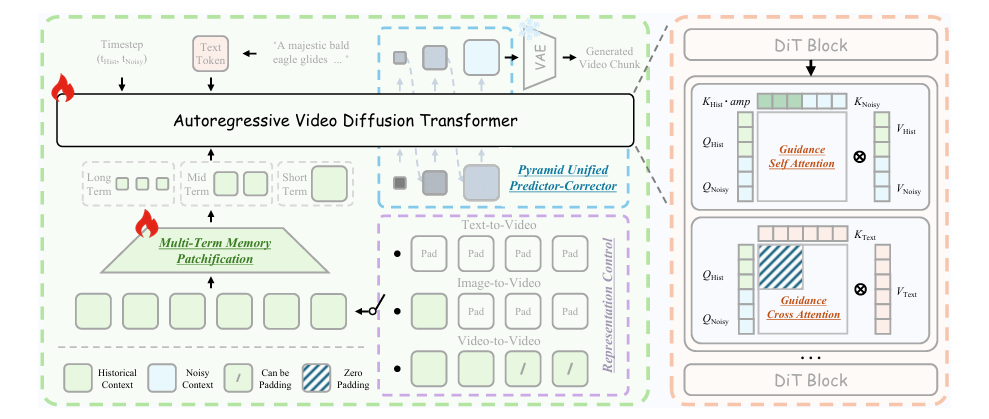
Thus, the 'First Frame Anchor' mechanism was born.
The research team anchored the first frame of the video as the 'linchpin' of the entire generation process. The AI must 'keep its eyes' on the first frame throughout the lengthy generation process, locking in the global appearance distribution.
No matter how the prompt dictates the development of subsequent frames, the overall tone and character identity established in the first frame can always pull the AI back on track, preventing 'sudden style changes.'
Even so, flaws are still inevitable, so the AI must learn to handle 'imperfections.'
Helios employs a special technique during training: Frame Aware Corrupt.
Simply put, various flaws are randomly introduced into the historical frames the AI relies on, forcing the AI to reduce its absolute dependence on historical frames through reinforcement learning and learn to repair problems based on common sense.
After training in this manner, Helios has an extremely high tolerance for errors and is less likely to collapse even in long videos.
The last issue to address is positional drift and repetitive motion.
The positional encoding in AI video generation is absolute. When the generated video length exceeds the maximum length the AI has seen during training, the attention mechanism becomes disordered, causing the scene (frame) to flash back to its initial position.
Helios changes positional encoding to relative referencing, focusing not on 'this is frame X' but on 'this is a continuation of the past X frames,' fundamentally cutting off periodic repetition of actions.
02
The 'Magic' of Computational Power
The issue of image quality collapse has been resolved at the software level, but a harder challenge arises at the hardware level:
With 14 billion parameters, how can it achieve real-time operation at 19.5 FPS on a single GPU?
The essence of AI video generation is no different from that of large language models. The commonly used Diffusion Transformer (DiT) architecture also uses self-attention mechanisms to capture spatial details (single-frame content) and temporal coherence (inter-frame motion) in videos.
However, since the dimensionality of images in vector space is higher than that of text, the computational load for each frame in a video far exceeds that of a single large language model query. Extending the video by just a few seconds exponentially increases the computational load and memory usage, necessitating GPU clusters to distribute the pressure.
Trading computational power for image quality and video duration, as demonstrated by Sora's shutdown and the 'dumbing down' of Seedance 2.0 after its release, clearly shows that this approach is commercially unviable.
Helios decisively chose a different path. This underlying reconstruction scheme, called 'Deep Compression Flow,' squeezes every last drop of potential from the GPU, from token reduction to step distillation and memory management, performing 'magic tricks' to 'witness miracles.'
1. Token Perspective: Extreme Compression of Spatiotemporal Dimensions
The first issue to address is memory explosion caused by excessively long video contexts. Helios solves this by asymmetrically compressing spatiotemporal dimensions.
As mentioned earlier, AI video generation involves 'drawing the future based on the past.' Thus, determining how much 'historical data' to prepare is crucial.
For humans, memory resembles a 'stack' data structure—last in, first out: we remember recent events vividly but are vague about things that happened ten minutes ago.
Helios borrows this multi-phase memory chunking mechanism from bionics, dividing the historical frames the AI needs to review into three types: short-term, medium-term, and long-term.
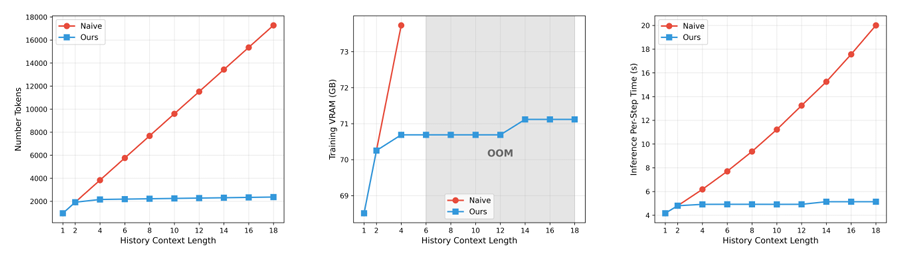
For frames that just passed a few moments ago, Helios retains the highest-resolution details; for frames from longer ago, it applies high-intensity compression, retaining only the roughest global layout.
This simple approach keeps the token consumption for reviewing distant historical frames at an extremely low and constant level, compressing memory usage for historical information to one-eighth of the original, completely eliminating the insolvable problem of 'memory explosion' on a single GPU.
When generating frames, Helios does not start directly at the highest resolution but adopts a bottom-up development strategy.
This resembles a painter's process: first, quickly sketch the overall color and layout contours at low resolution, then gradually zoom in to refine details like edges and textures.
Early denoising determines the macrostructure, while later denoising optimizes details. Using this task decomposition mechanism reduces computational load by more than half.
2. Step Perspective: Adversarial Hierarchical Distillation
AI video generation is slow because traditional diffusion models require around 50 iterative denoising steps.
Past video generation models, when learning to generate in one step, had to prevent 'memory loss' by using 'simulated unfolding inference' for training.
After generating a video segment, the model not only relied on a reward model to evaluate its quality but also continuation (continued writing) several simulated future long videos.
Unsurprisingly, this approach resulted in extremely long processing times and memory explosion.
However, Helios uses a 'Pure Teacher Forcing' mode, allowing the model to forgo simulating future videos and instead feed it massive amounts of real continuous video clips as the sole reference standard.
During each training session, the model focuses solely on 'perfectly drawing the next short segment' given the real historical frames, eliminating the complex simulation process and exponentially increasing training efficiency.
During denoising, a distillation mechanism similar to that in large language models is also present.
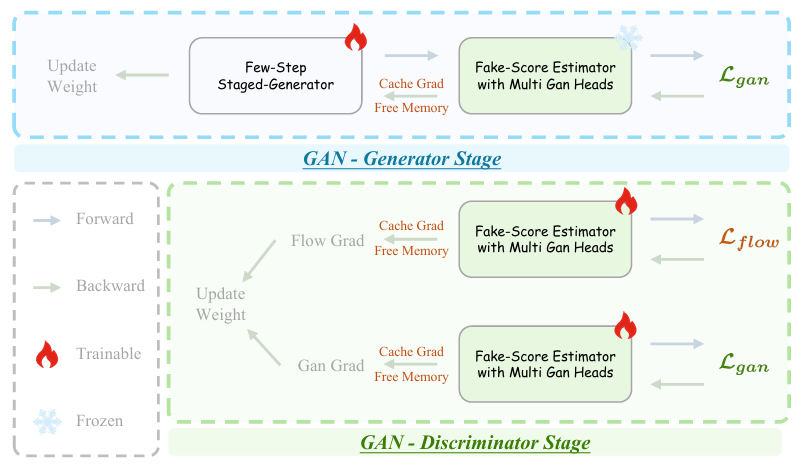
However, knowledge distillation always has a fatal flaw: the student's ceiling cannot exceed the teacher's, but their floor might be lower. Once flaws are amplified, the quality of generated videos naturally declines.
To address this, Helios introduces adversarial post-training based on real videos. If the student's output after denoising is merely an imitation of the teacher and lacks authentic physical details, it is sent back for revision.
This strict training method miraculously compresses the Image fidelity (frame fidelity) that originally required 50 steps into just 3 steps.
3. Memory Perspective: Reconstructed Scheduling Mechanism
GPU memory is fixed, but multiple sub-models within the larger model require serial computation.
To address this, the research team designed an advanced scheduling mechanism that uses dedicated data channels to keep only the currently computing sub-model in GPU memory. Once computation is complete and the sub-model is idle, its parameters are instantly transferred to the CPU to wait.
For modern AI training frameworks like PyTorch, intermediate variables during forward computation are saved to memory for use for backward propagation.
The research team noticed this and directly broke the framework's underlying computational logic. As soon as gradient calculation is complete, they manually trigger the program to release activation states within milliseconds, saving more than double the idle memory.
Additionally, official deep learning frameworks have hidden data transmission overhead.
To further accelerate video generation, the research team bypassed PyTorch and used the low-level compiler language Triton to write core code. They even eliminated a multiplicative dimension in memory usage complexity during traditional attention mechanism calculations.
It is this series of extreme optimizations, from the algorithmic bottom layer (underlying layer) to memory scheduling, that enables a 14B-parameter large model to run miraculously on an H100.
03
Helios: Reshaping the AI Video Business Landscape
A breakthrough in underlying technology often triggers industry chain upheavals, and Helios happens to be born from ByteDance, the creator of Seedance 2.0.
This model, neither particularly large nor small, possesses an unprecedented combination of traits: 'high quality + real-time + single-card + long duration,' precisely puncturing the barriers to AI video commercialization.
The shutdown of Sora and the 'dumbing down' of Seedance 2.0 shortly after its release demonstrate that the biggest obstacle to large-scale AI video adoption in the ToC market is high pricing.
Over the past year, video generation models on the market that produce decent results have required extremely high computational costs to generate a single 10-second video.
Under a subscription model, the current usage volume would only result in losses for AI companies. Even if APIs are opened to B-end enterprises, not only do technical gaps exist, but the costs required to produce commercial-grade outputs using these models would deter developers.
However, Helios lowers the operational threshold for a 14B model to a single H100 GPU while maintaining high throughput.
Although consumer-grade GPUs are still insufficient, this means cloud providers and SaaS platforms will see dramatic reductions in single-instance concurrency costs, and API business models may undergo qualitative changes.
The current point-based system, where users pay per generation, may shift to token-based pricing like that of large language models.
Only when generation costs are low enough can multi-modal models transition from 'luxury goods' to infrastructure like large language models.
Helios also brings another disruptive commercial possibility: AI video generation is about to shed its 'offline rendering' label and move toward real-time interactive engines.
Both Seedance 2.0 and Sora are essentially advanced offline renderers: users input prompts, the model generates content, they wait, and then receive a 'blind box' video.
This non-real-time interaction destined (dooms) these tools to serve only as material (material) production tools for content creation. No matter how poor the results, payment is still required.
But Helios already shows the makings of a real-time interactive engine. Its 19.5 FPS speed and coherent contextual memory are tailor-made for interactive generation.
If, in the future, users can dynamically modify instructions during the playback of generated videos, it will directly unlock commercial opportunities in world modeling, immersive experiences, and even embodied intelligence.
The emergence of Helios has pointed a new direction for all players in the AI video generation field:
Instead of sacrificing parameters for generation speed, it's better to focus on memory management, distillation mechanisms, and video memory scheduling.
The technological moat is built upon the extreme reconstruction of the underlying architecture.
-
How Meituan is Becoming the 'Interface' for AI Integration into the Physical World
-
![]()
RoboScience Machine Science Makes ICRA Best Paper List for Two Years Running with Its 'Embodied Brain' Innovation
-
![]()
Focusing on UTG Ultra-Thin Flexible Glass! CSG Optical New Material Production Base Establishes in Xianning, Hubei
-
![]()
AI Meets Optics: Tsinghua Smart Vision Secures A+ Round Funding Led by Hillhouse Capital
-
![]()
Why are 3C Brands Flocking to Douyin Mall During 618?
-
![]()
Token Economy Falters as Economic Tokenization Faces Challenges
-
![]()
Lenovo's Monthly Surge of 109%, Foxconn Industrial Internet's Market Cap Surpasses Kweichow Moutai: A Collective Resurgence of the 'IT Old Guard'?
-
![]()
After Zhang Xue's Victory, Where is Motorcycle Intelligence Headed?






