Short Drama Revolution! CUHK & Kuaishou Release ShotStream: Real-Time Generation of Cinematic Multi-Shot Videos at 16 FPS with On-the-Fly Editing
 04/01 2026
04/01 2026
 422
422
Analysis: The Future of AI-Generated Content 

Key Highlights
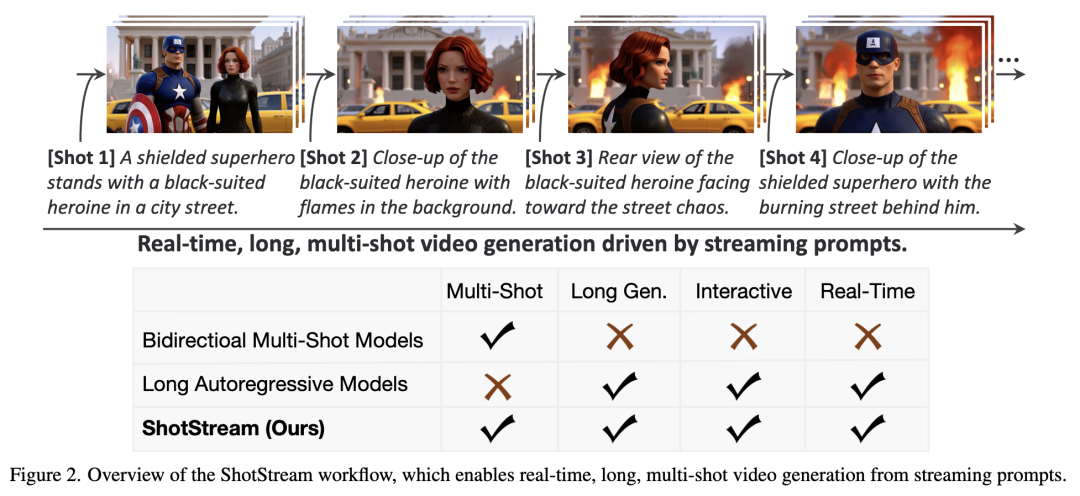
ShotStream, a novel causal multi-shot long video generation architecture, enables interactive storytelling and real-time synthesis.
Redefines multi-shot synthesis as a 'next-shot generation' task to support interactivity, allowing users to dynamically adjust ongoing narratives via streaming prompts.
Introduces a novel dual-buffer memory mechanism combined with RoPE discontinuity indicators to ensure causal model consistency across and within shots.
Proposes a two-stage distillation strategy to effectively mitigate error accumulation by bridging the training-inference gap, enabling robust long-sequence multi-shot generation.
Summary Overview
Problems Addressed
Existing bidirectional architectures for multi-shot video generation suffer from two key limitations: (1) Lack of interactivity, requiring all prompts to be provided upfront without dynamic narrative adjustment during generation; (2) High inference latency, making real-time generation difficult.
Proposed Solution
This paper introduces ShotStream, a novel causal multi-shot generation architecture. It reconstructs multi-shot generation as an autoregressive 'next-shot' generation task with streaming prompt mechanisms. Challenges in causal architectures are addressed through bidirectional-to-causal model distillation combined with a dual-buffer mechanism and two-stage distillation strategy.
Technologies Applied
Fine-tunes a text-to-video model into a bidirectional 'next-shot' prediction teacher model;
Distills the teacher model into an efficient 4-step causal student model via Distribution Matching Distillation (DMD);
Implements a dual-buffer memory mechanism (global buffer for inter-shot consistency, local buffer for intra-shot consistency) with RoPE discontinuity indicators;
Employs a two-stage distillation strategy (intra-shot and inter-shot self-forcing) to alleviate error accumulation.
Achieved Results
ShotStream achieves real-time generation at 16 FPS on a single GPU, matching or surpassing slower bidirectional models in quantitative metrics including visual consistency, prompt adherence, and shot transition control. User studies also show ShotStream receives the highest preference rates in visual consistency, prompt adherence, and visual quality.
Architectural Approach
This section details ShotStream's architecture and training methodology. A text-to-video model is first fine-tuned into a bidirectional next-shot model. It is then distilled via Distribution Matching Distillation into an efficient 4-step causal model. A novel dual-buffer memory mechanism and two-stage distillation strategy are proposed to enable efficient, robust, and long-sequence multi-shot generation.
Bidirectional Next-Shot Teacher Model
The next-shot model's objective is to generate subsequent shots conditioned on historical shots. Since historical shots contain hundreds of frames with high visual redundancy, retaining complete historical information is unnecessary and infeasible under limited condition budgets. This paper employs a dynamic sampling strategy to extract sparse context frames as conditions. Given H historical shots and a maximum conditional context budget of C frames, F = ⌊C/H⌋ frames are sampled from each historical shot, where ⌊·⌋ denotes the floor function. Any remaining budget is allocated to the most recent shot to maximize utilization (set to 6 frames in experiments).
To condition on the sampled sparse context frames X_cond, a temporal token concatenation mechanism is employed—an injection technique proven effective in multi-control generation, editing, and camera motion cloning. While effective, these methods do not distinguish between conditional and target frame prompts; instead, they uniformly apply target frame prompts to conditional frames. Direct application to next-shot generation is problematic because previous shot prompts contain crucial information binding past visual content with textual descriptions. This binding helps extract necessary context for generating subsequent shots. Therefore, this paper also injects shot-specific prompts corresponding to each conditional context frame into the model, where each shot's frames attend to both global prompts and corresponding local shot prompts via cross-attention. As shown in Figure 3, the next-shot model reuses the base model's 3D VAE E to convert X_cond into conditional latent vectors Z_cond,
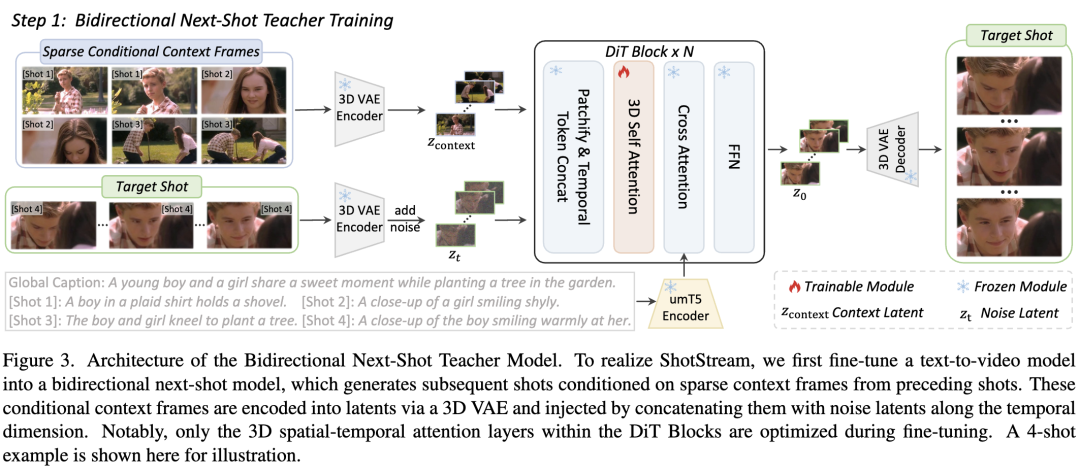
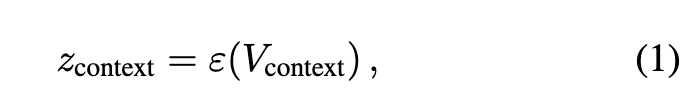
where X_cond contains F frames, C denotes channels, and spatial resolution is H×W. Based on this shared latent space, conditional latent vectors Z_cond and noisy target latent vectors Z_target (containing T frames) are first chunked:
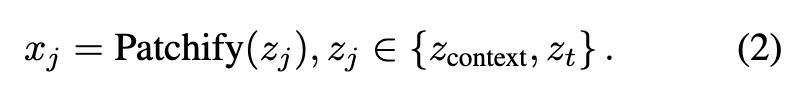
The resulting conditional tokens T_cond and noisy video tokens T_target are then concatenated along the frame dimension to form inputs for DiT blocks:
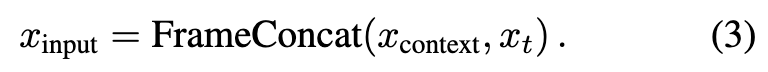
The FrameConcat operation denotes concatenation of conditional and noise tokens along the frame dimension. Since token sequences T_cond and T_target share identical batch size b, spatial tokens per frame s, and feature dimension d, this temporal concatenation produces a combined tensor. During training, noise is added only to target video tokens while keeping context tokens clean. This design enables DiT's native 3D self-attention layers to directly model interactions between conditional and noise tokens without introducing new layers or parameters to the base model.
Causal Architecture and Distillation
The bidirectional next-shot teacher model detailed earlier requires approximately 50 denoising steps, resulting in high inference latency. To achieve low-latency generation, this paper distills this multi-step teacher model into an efficient 4-step causal generator. However, transitioning to this causal architecture introduces two primary challenges: (1) maintaining inter-shot consistency, and (2) preventing error accumulation to preserve visual quality during autoregressive generation. To address these, two key innovations are proposed: a dual-buffer memory mechanism and a two-stage distillation strategy.
Dual-Buffer Memory Mechanism. To maintain visual coherence, a novel dual-buffer memory mechanism is introduced (as shown in Figure 4): a global buffer stores sparse conditional frames to preserve inter-shot consistency, while a local buffer retains recently generated frames to ensure intra-shot consistency. However, querying both buffers simultaneously in the proposed chunked causal architecture introduces temporal ambiguity, as the model struggles to distinguish between historical and current shot contexts. To resolve this, a discontinuous RoPE strategy is proposed, explicitly decoupling global and local contexts by introducing a discrete temporal jump at each shot boundary. Specifically, for the t-th latent vector in the k-th shot, its temporal rotation angle is computed as φ_t = ω_0 · (t + k · Δ), where ω_0 denotes the base temporal frequency and Δ serves as a phase offset representing shot boundary discontinuity.
Two-Stage Distillation Strategy. A major challenge in autoregressive multi-shot video generation is error accumulation caused by the training-inference gap. To mitigate this, a two-stage distillation training strategy is proposed.
In Stage 1 (Intra-Shot Self-Forcing, shown in Figure 4, Step 2.1), the model samples global context frames from real historical shots while the chunked causal generator unfolds temporally to generate the target shot. Specifically, the local buffer utilizes data from previously self-generated chunks within the current target shot rather than real data. While this stage establishes foundational next-shot generation capabilities, the training-inference gap persists: during inference, the model must rely on its own potentially imperfect historical shots as conditions rather than real data.
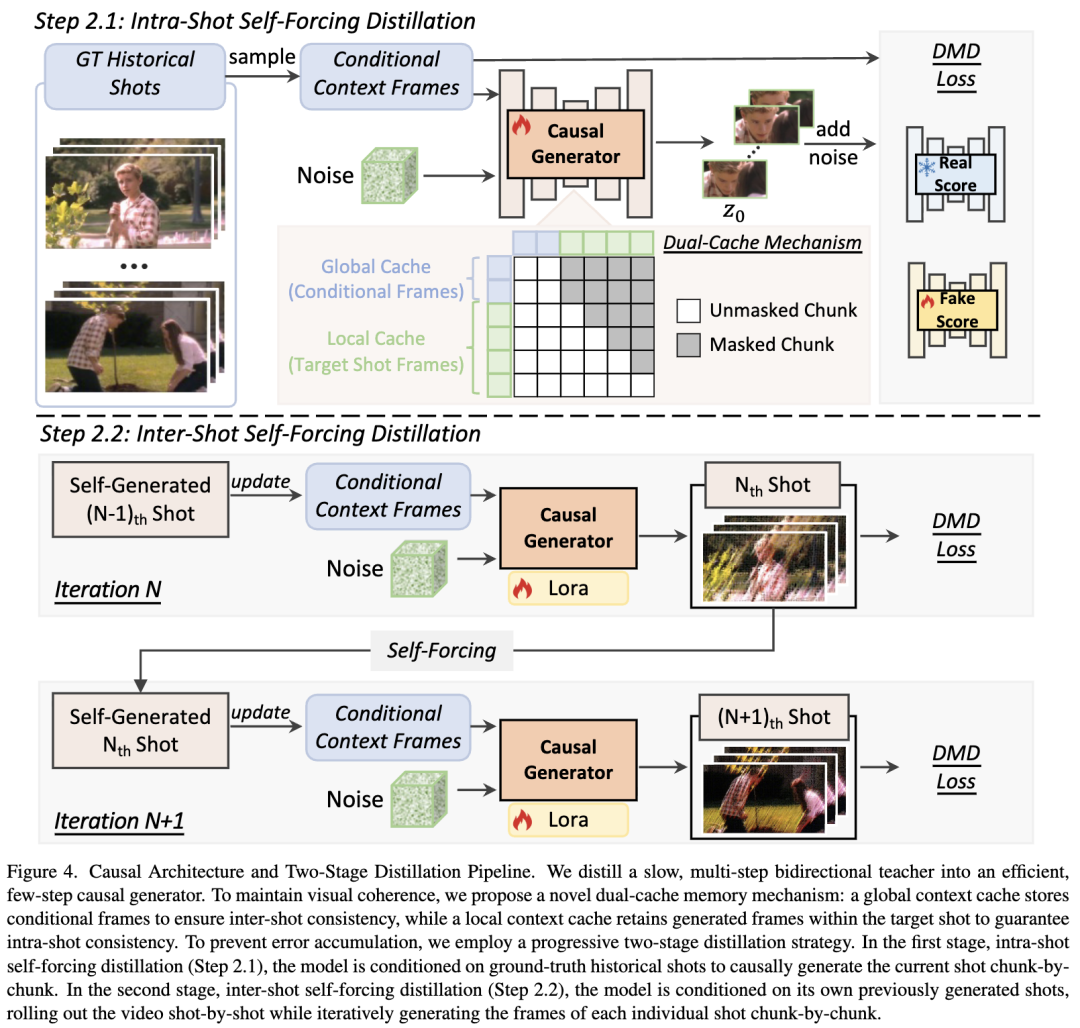
To bridge this gap, Stage 2 (Inter-Shot Self-Forcing, shown in Figure 4, Step 2.2) is introduced. The causal model generates the first shot from scratch and applies DMD. For all subsequent iterations, the generator synthesizes the next shot entirely based on previously self-generated shots. During each iteration, the model continues using intra-shot self-forcing to generate each new shot chunk-by-chunk, applying DMD only to newly generated shots. This autoregressive unfolding continues until the complete multi-shot video is generated. By closely mimicking the inference-time unfolding process, this stage aligns training with inference, effectively reducing error accumulation and improving overall visual quality.
Inference. ShotStream's inference process identical to its training procedure. It generates multi-shot videos shot-by-shot. When generating each new shot, global context frames are updated by sampling from previously synthesized historical shots. Within the current shot, video frames are generated chunk-by-chunk in sequence using the causal few-step generator and KV cache, ensuring computational efficiency.
Experiments
Experimental Setup
Implementation Details: ShotStream is built upon Wan2.1-T2V-1.3B, generating 128-frame video clips. The bidirectional next-shot teacher is trained on an internal dataset containing 320K multi-shot videos. For causal adaptation, the student model is initialized by regressing against 5K teacher-sampled ODE solutions. Distillation proceeds in two stages: Stage 1 uses real historical shots from the dataset for intra-shot self-forcing; Stage 2 employs prompts from a 5-shot video subset for inter-shot self-forcing. The model operates with a chunk size of 3 latent vector frames, using a 2-chunk global buffer and 7-chunk local buffer.
Evaluation Benchmark: To comprehensively assess multi-shot video generation capabilities, this paper follows prior work by generating 100 diverse multi-shot video prompts using Gemini 2.5 Pro. These test prompts cover a wide range of themes.
Evaluation Metrics: Before computing metrics, pre-trained TransNet V2 detects shot boundaries in each video. The model's multi-shot performance is evaluated across five key dimensions:
1) Intra-shot consistency (subject and background consistency);
2) Inter-shot consistency (subject, background, and semantic consistency);
3) Transition control (Shot Cut Accuracy, SCA);
4) Prompt adherence (text alignment);
5) Overall quality (aesthetic quality and dynamism).
Baseline Models: Two types of open-source video generation models are compared:
1) Bidirectional multi-shot video generation models: Mask2DiT, EchoShot, CineTrans;
2) Autoregressive and interactive long video generation models: Self Forcing, LongLive, Rolling Forcing, Infinity-RoPE.
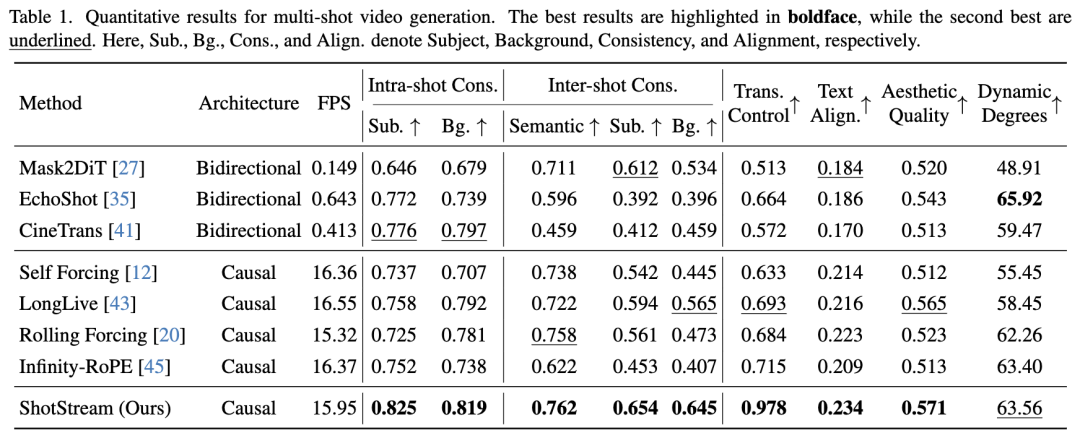
Quantitative Results
As shown in Table 1, the proposed model outperforms comparison methods across major metrics. It achieves the highest visual consistency while maintaining precise control over shot transitions. Additionally, the method excels in per-shot prompt alignment and overall aesthetic quality. Regarding inference efficiency, the method achieves over 25× throughput (FPS) improvement compared to bidirectional models. It also enables autoregressive long multi-shot video generation with minimal speed loss relative to other causal long video models.
Qualitative Results
As shown in Figure 5, a qualitative comparison is provided for a complex, narrative-driven multi-shot prompt. Baseline methods (including Mask2DiT, CineTrans, Self Forcing, and Rolling Forcing) fail to generate shots aligned with their respective prompts. While EchoShot and Infinity-RoPE successfully adapt to single-shot instructions, they perform poorly in inter-shot consistency. LongLive confuses the identities of two women appearing in the sequence. In contrast, the proposed method achieves high visual consistency and smooth transitions while faithfully adhering to the multi-shot prompt.

User Study
Due to the subjectivity of evaluating multi-shot video generation, this paper conducts a user study to compare different methods and validate the perceptual advantages of the proposed ShotStream. The user study involved 54 participants, with results shown in Table 2 below, indicating that our method consistently received preference among most users.

Ablation Study
This paper conducts an ablation study to validate the key design choices and training strategies for the bidirectional next-shot teacher model and the causal student model.
Bidirectional Next-Shot Teacher Model Design: As shown in Table 3 below, this paper validates the design choices in four key aspects: context frame sampling strategy, conditional frame prompting strategy, conditional injection mechanism, and training strategy. The results indicate that dynamic sampling strategy, multi-prompt injection, frame concatenation injection mechanism, and fine-tuning only the 3D self-attention layers are all effective.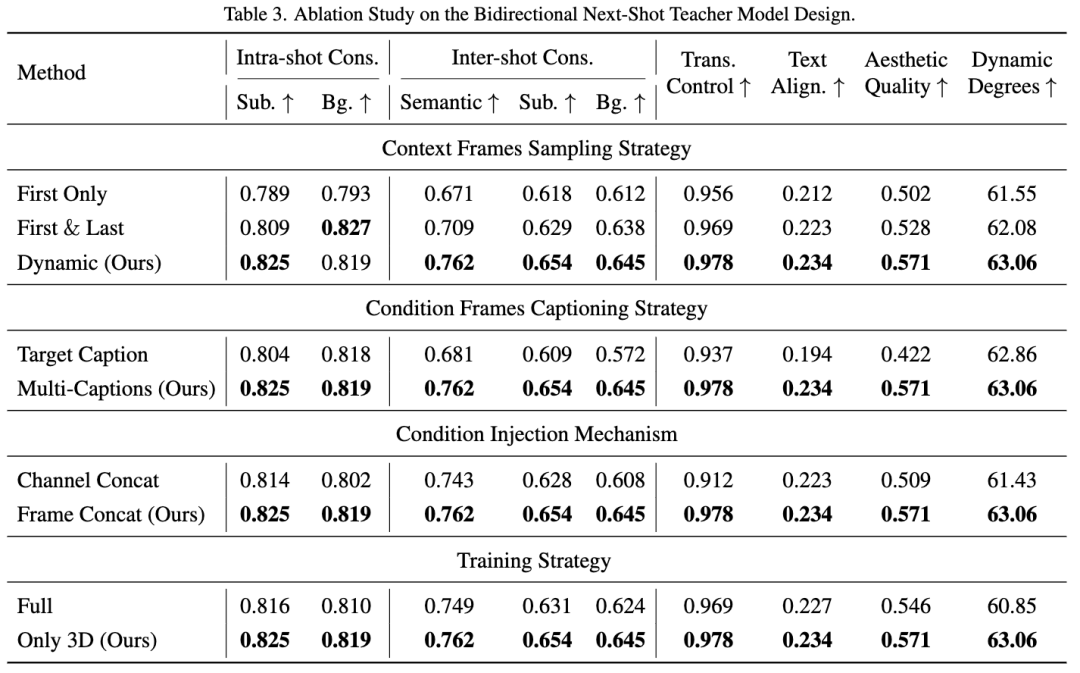
Causal Student Model Design: As shown in Table 4 below, this paper conducts ablation on the design and distillation strategies of the causal model.
1) Dual-Buffer Differentiation Strategy: The results indicate that explicitly differentiating global and local buffers is crucial (Row 1 vs. Row 3), and our proposed training-free RoPE offset method outperforms the learnable embedding method (Row 2 vs. Row 3).
2) Causal Distillation Training Strategy: This paper evaluates the effectiveness of a two-stage distillation strategy compared to a single-stage baseline. Both stages are indispensable: Stage 1 establishes the foundational next-shot generation capability, while Stage 2 bridges the training-inference gap by faithfully simulating inference.
Furthermore, the qualitative results in Figure 6 below reinforce the necessity of RoPE offset and two-stage distillation. Notably, inter-shot self-enforced distillation significantly improves long-term consistency in visual style and color ('Stage 1 Only' vs. 'Our Method').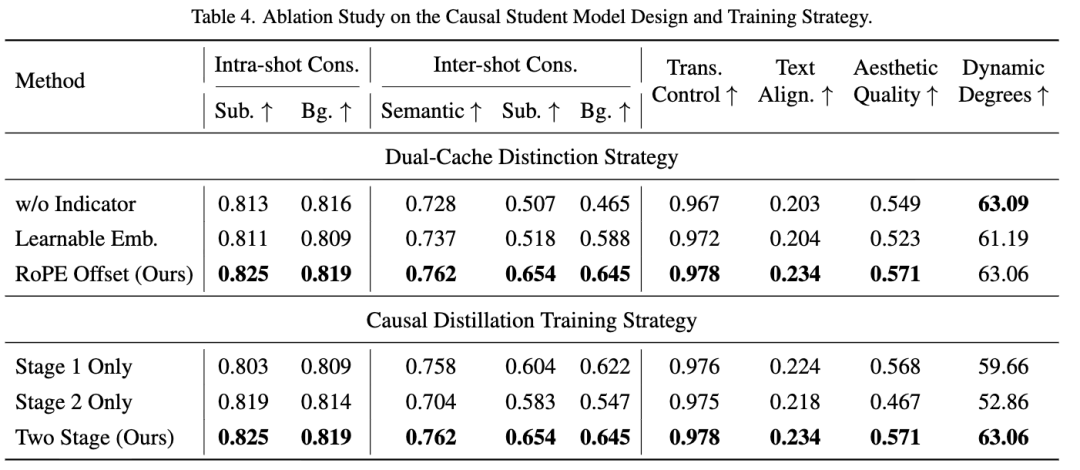

Conclusion
ShotStream, a novel causal multi-shot video generation architecture, enables real-time generation at 16 FPS on a single GPU and supports interactive long narratives. Core contributions include redefining the next-shot generation task as a streaming task, training a bidirectional next-shot teacher model, and distilling it into a causal architecture through our proposed two-stage distillation strategy. Additionally, this paper introduces a novel dual-buffer memory mechanism to ensure visual consistency. Compared to existing bidirectional multi-shot models, ShotStream significantly reduces generation latency and supports runtime streaming prompt inputs. This enables users to interactively guide the narrative, adjusting upcoming shots based on previously generated content. Furthermore, by extending the capabilities of autoregressive long video generation models to generate coherent multi-shot sequences, ShotStream paves the way for real-time, interactive long-form storytelling.
Limitations and Future Work. Although ShotStream is effective in autoregressive multi-shot video generation, this paper identifies two main limitations. First, visual artifacts and inconsistencies are observed when scenes and text prompts are highly complex. This primarily stems from the limited capacity of the backbone network; as the current model is relatively small, scaling up the base model is expected to improve performance and stability in challenging scenarios. Second, while our method is efficient, there is still room for acceleration to provide a better interactive experience. Techniques such as sparse attention and attention sink can be integrated into our model to achieve faster generation. These extensions will be left for future research.
References
[1] ShotStream: Streaming Multi-Shot Video Generation for Interactive Storytelling
-
How Meituan is Becoming the 'Interface' for AI Integration into the Physical World
-
![]()
RoboScience Machine Science Makes ICRA Best Paper List for Two Years Running with Its 'Embodied Brain' Innovation
-
![]()
Focusing on UTG Ultra-Thin Flexible Glass! CSG Optical New Material Production Base Establishes in Xianning, Hubei
-
![]()
AI Meets Optics: Tsinghua Smart Vision Secures A+ Round Funding Led by Hillhouse Capital
-
![]()
Why are 3C Brands Flocking to Douyin Mall During 618?
-
![]()
Token Economy Falters as Economic Tokenization Faces Challenges
-
![]()
Lenovo's Monthly Surge of 109%, Foxconn Industrial Internet's Market Cap Surpasses Kweichow Moutai: A Collective Resurgence of the 'IT Old Guard'?
-
![]()
After Zhang Xue's Victory, Where is Motorcycle Intelligence Headed?






