The 'Ceiling' of Text-to-Image Generation Has Been Shattered! Gen-Searcher Enables AI to 'Find Answers by Flipping Through Books': It's Not Memorization, It's an Open-Book Exam!
 04/02 2026
04/02 2026
 467
467
Interpretation: The Future of AI-Generated Content 

Key Highlights
Gen-Searcher: Pioneered the exploration and training of a multimodal deep search AI agent for image generation. The project has been fully open-sourced, aiming to provide an open infrastructure for future research in this domain.
Data Pipeline and Benchmark Construction: Developed a specialized data pipeline to construct 'search-intensive' image generation data for model training, resulting in two training datasets: Gen-Searcher-SFT-10k and Gen-Searcher-RL-6k. Additionally, introduced KnowGen, a challenging new benchmark designed to evaluate search-augmented image generation capabilities in knowledge-intensive real-world scenarios.
Experimental Validation: Extensive experiments demonstrate Gen-Searcher's superior performance. The approach improved Qwen-Image's performance by approximately 16 points on the KnowGen benchmark and about 15 points on the WISE benchmark.
Summary at a Glance
Problem Addressed
While existing image generation models can produce high-fidelity images, they are fundamentally constrained by the fixed internal knowledge acquired during pre-training, often failing in real-world scenarios requiring rich world knowledge or up-to-date information.
Proposed Solution
Gen-Searcher—the first trained search-augmented image generation AI agent capable of performing multi-hop reasoning and searches to gather textual knowledge and reference images to support evidence-based generation. The work also constructed a specialized data pipeline, curated two high-quality datasets (Gen-Searcher-SFT-10k and Gen-Searcher-RL-6k), and introduced the KnowGen benchmark for evaluation.
Technologies Applied
Adopted a two-stage training scheme: supervised fine-tuning (SFT) followed by agentic reinforcement learning (RL). The RL phase employed a dual-reward feedback mechanism, combining text-based rewards (evaluating the sufficiency, correctness, and generative relevance of output text) and image-based rewards (i.e., K-Score, assessing the quality of the final generated image). The final reward calculation formula is . Optimization utilized the GRPO algorithm, with the advantage function computed as .
Achieved Results
Gen-Searcher brought significant improvements across different image generation backbones. For instance, Qwen-Image's K-Score on KnowGen improved from 14.98 to 31.52 (approximately a 16.5-point increase). Notably, Gen-Searcher trained on Qwen-Image could be directly applied to Seedream 4.5 and Nano Banana Pro without additional training, yielding improvements of about 16 and 3 points, respectively, demonstrating strong transferability. On the WISE benchmark, Gen-Searcher elevated Qwen-Image's performance from 0.62 to 0.77.
Method Architecture
Dataset Construction
High-quality training data is crucial for developing search agents capable of performing multi-hop deep searches and reasoning for image generation. However, such data does not naturally exist, as it requires aligned triplets of search-intensive prompts, agent search trajectories, and evidence-based images.
To address this challenge, a specialized data pipeline was designed to automatically construct training data for search-supported image generation. The overall pipeline consists of four stages: text prompt construction, agent trajectory generation, evidence-based image synthesis, and data filtering and curation. Figure 3 below illustrates the data curation pipeline.
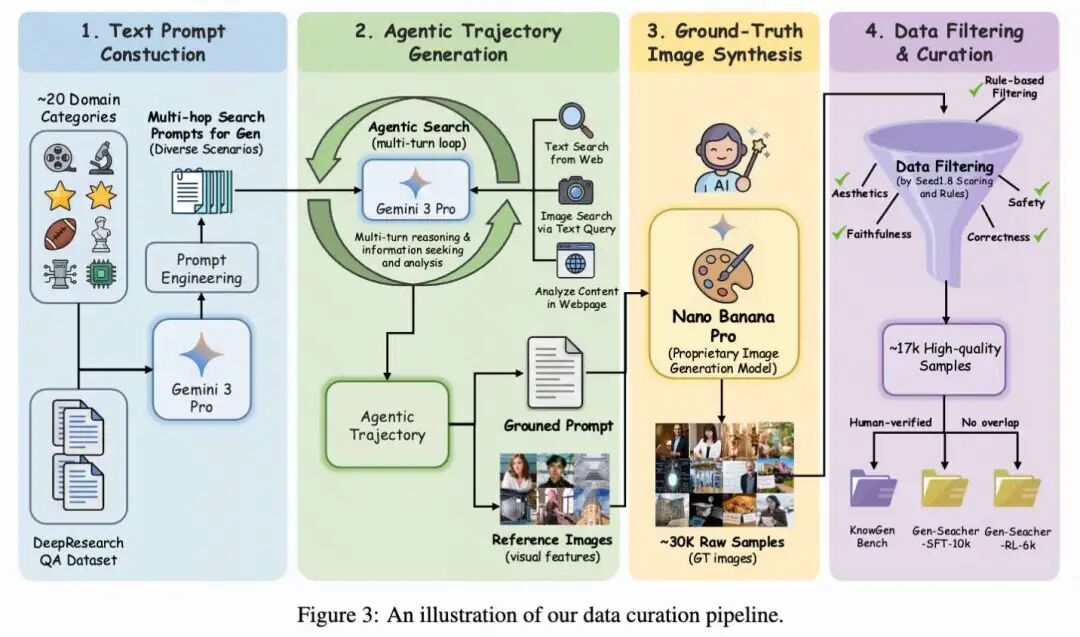
Text Prompt Construction. First, text prompts requiring deep web searches prior to image generation were constructed. To ensure diversity and authentic search difficulty, two complementary strategies were employed. The primary method used carefully designed prompt engineering to guide Gemini 3 Pro in generating multi-hop search-intensive prompts across a broad range of categories, including anime, architecture, art, astronomy, biology, celebrities, chemistry, culture, engineering, films, games, geography, history, industry, medicine, physics, politics, posters, religion, and sports. These prompts were explicitly designed such that the required information could not be obtained through a single search round but necessitated multi-step evidence aggregation and analysis across the web.
As a supplementary strategy, samples from existing deep research Q&A datasets were converted into image generation-oriented prompts. Specifically, Gemini 3 Pro was used to transform information-seeking questions into prompts requiring the generation of evidence-based visual descriptions of the queried entities or events. This strategy primarily contributed prompts related to general news, further expanding coverage of diverse knowledge scenarios.
Agent Trajectory Generation. Given the constructed text prompts, agent search trajectories were generated to perform deep searches and collect sufficient evidence for generating final search-supported prompts and providing accurate visual features along with selected reference images. These trajectories also served as valuable supervised data for subsequent supervised fine-tuning.
Specifically, Gemini 3 Pro was employed in a multi-round manner alongside a set of search tools. The toolkit included search for retrieving textual information from the web, image_search for finding relevant images via textual queries, and browse for reading and analyzing the detailed content of retrieved web pages. Throughout this process, the agent continuously analyzed textual and visual feedback from the environment, identified useful evidence and reference images, and planned subsequent actions accordingly. Through this multi-round reasoning and search process, the agent progressively aggregated information from multiple sources before ultimately generating evidence-based prompts for image synthesis and a set of relevant reference images.
Real Image Synthesis. After obtaining the final evidence-based prompts and visual references, the proprietary image generation model Nano Banana Pro was used to synthesize corresponding images. The generated images served as synthetic ground truth for training the search agent. This process yielded approximately 30K raw samples, including prompts, search trajectories, evidence-based prompts, reference images, and ground truth images.
Data Filtering and Benchmark Construction. To ensure data quality, another powerful proprietary model, Seed1.8, was employed to score the generated samples from multiple perspectives, including whether the prompts genuinely required searching, the correctness of the generated content, faithfulness to the prompt, visual aesthetics, text rendering clarity, and safety considerations. These model-based scores were combined with rule-based filtering, such as removing prompts with excessively long token lengths or inconsistent search results. After filtering, approximately 17K high-quality samples were obtained.
From this curated dataset, 630 manually verified samples were selected to construct a held-out benchmark named KnowGen, which will be introduced later. The remaining 16K samples were used for training and split into two datasets: Gen-Searcher-SFT-10k for supervised fine-tuning and Gen-Searcher-RL-6k for agentic reinforcement learning. Strict measures were taken to ensure no overlap between the training data and evaluation benchmark.
KnowGen Benchmark
For evaluation, KnowGen was introduced—a comprehensive benchmark designed to assess search-supported image generation in knowledge-intensive real-world scenarios. Unlike traditional text-to-image benchmarks that primarily emphasize prompt adherence or visual quality, KnowGen explicitly focuses on knowledge-intensive and search-dependent generation scenarios, where solving prompts typically requires retrieving and aggregating evidence from the web.
Each sample in KnowGen is constructed to require non-trivial external knowledge, with many samples necessitating multi-hop searches across multiple sources. To ensure reliability, all evaluation samples underwent human verification.
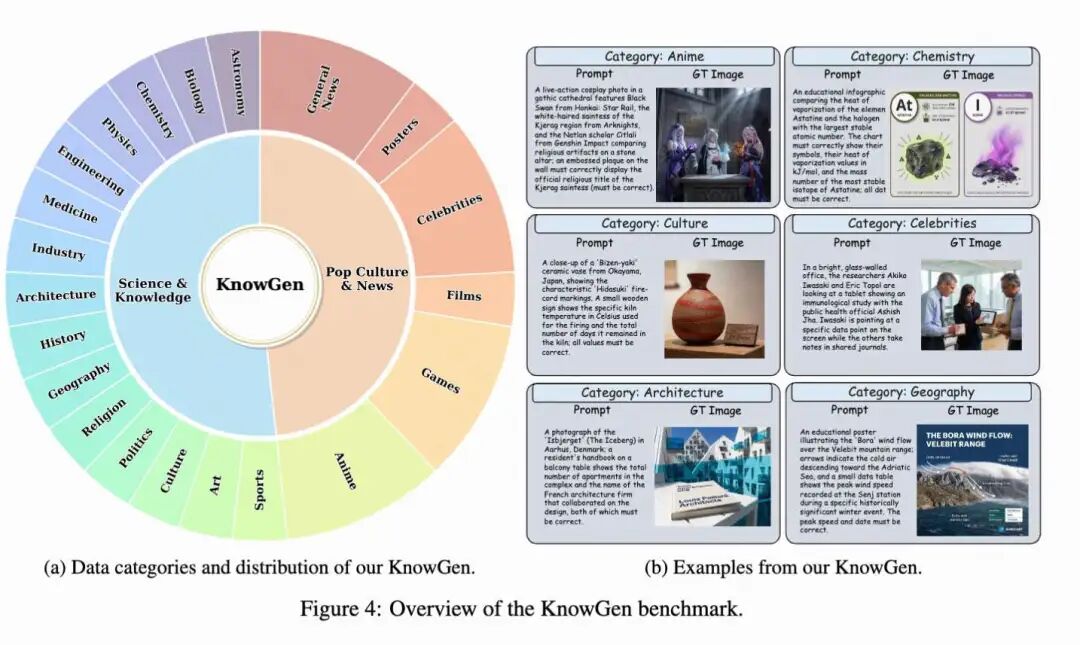
Category Composition. To provide broad coverage of different types of search-supported generation tasks, the 630 samples in KnowGen were divided into two high-level subsets: Science & Knowledge and Pop Culture & News. The Science & Knowledge subset includes the following categories: astronomy, biology, chemistry, physics, engineering, medicine, industry, architecture, history, geography, religion, politics, culture, art, and sports. These tasks typically require factual world knowledge, entity disambiguation, or domain-specific information and often involve fine-grained evidence-based details that must be correctly rendered visually or textually.
The Pop Culture & News subset covers prompts related to anime, games, films, celebrities, posters, and general news. Compared to the first subset, these tasks more frequently involve rapidly changing real-world information, pop culture entities, and textual or appearance details required by the prompts that must be accurately rendered. This two-part design enables KnowGen to evaluate both relatively stable knowledge-intensive scenarios and dynamic, highly updated real-world scenarios within a unified benchmark. Figure 4 below provides an overview of the benchmark's categories and examples.
Evaluation Metrics. To assess generation quality on KnowGen, the K-Score was introduced—a metric designed to evaluate search-supported image generation from multiple perspectives. GPT-4.1 was adopted as the judge for evaluating model outputs, following the practices of the WISE benchmark. For each sample, the evaluator received the original text prompt, ground truth reference images, and the model-generated image as input and scored the generation results across four dimensions: faithfulness, visual_correctness, text_accuracy, and aesthetics.
Faithfulness measures whether the generated image follows the prompt at the scene structure level, including required subjects, relationships, settings, and requested formats. Visual correctness assesses whether critical evidence-based visual attributes are consistent and correct relative to the target concept compared to reference images, such as subject appearance, object features, or other externally verifiable visual cues. Text accuracy measures whether any readable text required by the prompt is present, clear, and correct in the image; when the prompt does not require readable text, this dimension is considered inapplicable and excluded from the average score. Aesthetics evaluates the overall visual quality and artistic appeal of the generated image, including composition, color harmony, lighting, etc., assessing whether the image presents visual refinement and aesthetic pleasure.
According to the evaluation design, each dimension was scored using a three-level discrete scale . Specifically, a score of 1 indicates that the generated image fully meets the requirements of that dimension, 0.5 indicates that the dimension is generally correct or met but contains minor issues or partial mismatches, and 0 indicates that the generation fails to meet the critical requirements of that dimension. The final K-Score is calculated as a weighted combination of these four dimensions:
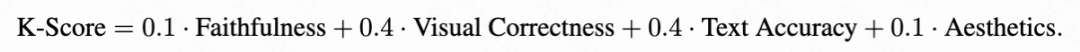
This weighting emphasizes the two most critical aspects of search-supported image generation, namely correctly rendering evidence-based visual attributes and accurately reproducing required textual content, while still considering overall prompt adherence and image aesthetics. The work reports K-Scores separately for the two high-level subsets as well as the overall average on KnowGen.
Training Scheme
This section trains Gen-Searcher as a multimodal deep search AI agent capable of iteratively collecting external knowledge and visual evidence from the web for image generation. The training scheme follows a two-stage pipeline, including SFT and agentic RL.
Search Tools. Gen-Searcher is equipped with three search tools. The first is search, which performs web text searches and returns the top-k relevant webpage URLs and their short snippets for each query. This tool is primarily used to verify factual information, such as entity names, event details, dates, locations, and concise descriptions. The second is image_search, which retrieves the top-k relevant images for a given textual query, along with image URLs and brief descriptions, enabling the agent to determine identities, objects, landmarks, clothing, and other fine-grained appearance details. The third is browse, which takes a webpage URL as input and returns a summary of the page content; in implementation, this summary is generated by Qwen3-VL-30B-A3B-Instruct. This tool is used when shallow search results are insufficient, and the agent needs to extract specific evidence from web pages. At each step, the agent observes the current prompt and accumulated search feedback before deciding whether to continue searching, retrieve visual references, browse pages for more details, or terminate with a final evidence-based prompt and selected reference images. Figure 5 below shows a representative reasoning trajectory example for Gen-Searcher.

Two-Stage Training. The work initialized Gen-Searcher from Qwen3-VL-8B-Instruct. In the first stage, supervised fine-tuning was performed on Gen-Searcher-SFT-10k to teach the model to perform multi-round tool usage, including issuing search queries, interpreting textual and visual feedback, selecting useful reference images, and composing final search-supported prompts. In the second stage, the model was further optimized through reinforcement learning on Gen-Searcher-RL-6k, enabling it to learn more effective search strategies and produce improved tool invocation trajectories. Notably, the image generator remained fixed during training; the work only optimized Qwen3-VL-8B-Instruct to generate search-supported prompts and corresponding reference images.
Dual-Reward Feedback Design. A natural choice for RL in this setting is to directly use image-based rewards (e.g., K-Score) to evaluate the final generated image. However, relying solely on image rewards leads to significant noise and instability. This is because the final image quality depends not only on the correctness of retrieved evidence but also on the capability and randomness of the downstream image generator. Particularly for open-source generators like Qwen-Image, even when the agent has collected correct information, complex prompts may still fail to produce high-quality images, and even similar grounded prompts can lead to substantially different generated results. Thus, pure image-based rewards introduce large variance and make policy optimization unstable.
To address this issue, the work introduces an additional text-based reward, denoted as rtext, which evaluates whether the final output text contains sufficient, correct, and generation-relevant information for synthesizing the target image. GPT-4.1 is similarly used as a judge to score this reward on a five-point scale, with values in [0, 4]. Compared to image rewards, text rewards provide more direct supervision over the quality of information gathering and evidence aggregation. However, relying solely on text rewards is also insufficient, as text that superficially contains sufficient information may not necessarily support high-quality image generation. Optimizing only for text rewards would thus ignore the actual final task generation results and may encourage outputs that are textually informative but practically ineffective for generation. Corresponding prompts can be found in Appendix B.
Therefore, the work combines both signals and adopts a dual-feedback reward design, where the text-based reward supervises the quality of collected information, and the image-based reward reflects the final generation performance. The final reward is computed as:

where λ is a balancing hyperparameter. Here, the work simply sets λ = 0.5 and uses K-Score as rimage.
Optimization. After computing the final reward, the work uses GRPO to optimize the policy. For each output τ sampled under query q, the advantage is calculated by normalizing its reward with the mean and standard deviation of rewards within the sampling group:

The final policy update follows the standard GRPO objective:
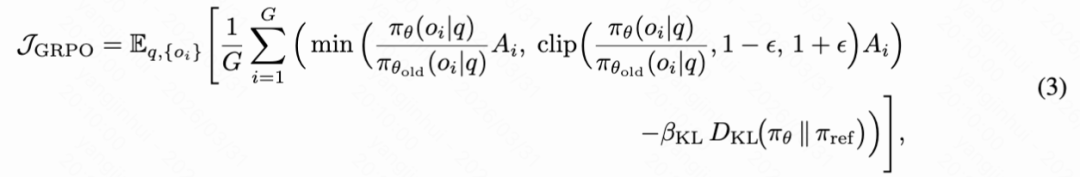
where variables and hyperparameters are defined as per the original GRPO algorithm.
Experimental Analysis
Experimental Setup. The work trains Gen-Searcher-8B using 8 NVIDIA H800 GPUs, with Qwen3-VL-8B-Instruct as the base model. Supervised fine-tuning is first performed on Gen-Searcher-SFT-10k, followed by agent RL training on Gen-Searcher-RL-6k. Both SFT and RL use AdamW as the optimizer, with the SFT learning rate set to 1e-5 and the RL learning rate set to 1e-6, both with a batch size of 8.
During RL training, Qwen-Image-Edit-2509 is additionally deployed on 16 H800 GPUs to support rollout image generation, as the 2509 version is found to provide superior text rendering quality compared to the 2511 version. Meanwhile, Qwen3-VL-30B-Instruct-A3B is deployed on 8 H800 GPUs as a summarization model for the browse tool. To improve efficiency, the group size is set to 6, the maximum number of interaction rounds is limited to 10, a maximum of 5 images are returned per round, the maximum context length is set to 36K, and the model response length per round is limited to 4K. Following prior practices, rollouts with excessive length or duplicate responses are masked during training. The training process consumes approximately one day.
KnowGen Benchmark Results. Table 1 below shows the performance of different models on the KnowGen benchmark. Overall, KnowGen presents a highly challenging benchmark for current image generation models, especially open-source ones. Even strong open-source baselines like Qwen-Image, HunyuanImage-3.0, FLUX, and Z-Image achieve K-Scores of only around 9 to 15, indicating that knowledge-intensive and search-supported image generation remains far beyond the capabilities of standard text-to-image systems. In contrast, proprietary models perform significantly better, with Nano Banana Pro achieving the strongest baseline result of 50.38 and GPT-Image-1.5 reaching 44.97. This large gap suggests that KnowGen poses significant challenges in both background knowledge retrieval and faithful visual realization, highlighting the clear differences between open-source and proprietary systems in handling such tasks.
The method brings significant improvements across different image generation backbones. When combined with Qwen-Image, Gen-Searcher-8B boosts the overall K-Score from 14.98 to 31.52, a gain of 16.54 points. This substantial improvement demonstrates that Gen-Searcher can largely compensate for the insufficient built-in search capabilities of open-source image generators by actively collecting grounded textual evidence and visual references from the web. More importantly, Gen-Searcher does not merely learn prompt heuristics specific to a particular generator but learns transferable search-grounding strategies that generalize to different downstream image generators.
Notably, although Gen-Searcher uses Qwen-Image as the rollout generator during RL training, it migrates well to other generators at test time. In particular, it boosts Seedream 4.5 from 31.01 to 47.29, a gain of 16.28 points, and further elevates Nano Banana Pro from 50.38 to 53.30, achieving the best overall result in the table. These results not only demonstrate the effectiveness of the search agent but also showcase its strong transferability and robustness across image generators with very different native capabilities.
Analysis of the four evaluation dimensions reveals that the gains brought by Gen-Searcher primarily stem from improvements in visual correctness and text accuracy, the two most important components in KnowGen. This suggests that the search framework enables image generators to better produce accurate visual attributes and textual content requiring real-world knowledge. In some cases, a slight decline in aesthetic scores is observed, likely because the generator needs to integrate information from multiple retrieved reference images and thus cannot always produce the most ideal or visually pleasing compositions.
The work also identifies an interesting pattern on Nano Banana Pro: its improvements mainly come from visual correctness, while text accuracy remains almost unchanged. A possible explanation is that Nano Banana Pro already supports text-based search internally, which helps maintain text-related performance, but it does not retrieve visual reference images, leaving substantial room for improvement in determining fine-grained visual attributes.
WISE Benchmark Results. Table 2 below reports the performance of different models on the WISE benchmark. Compared to KnowGen, WISE is a relatively simpler benchmark but still requires a certain amount of world knowledge for correct image generation.
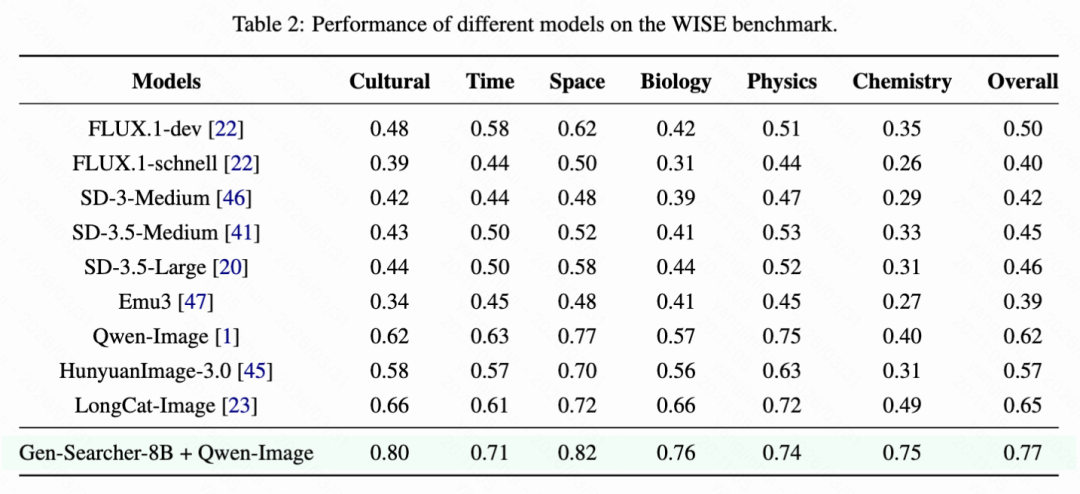
Gen-Searcher-8B, combined with Qwen-Image, achieves the best overall performance of 0.77 on WISE, significantly outperforming the original Qwen-Image baseline of 0.62 by 0.15. It also surpasses all other open-source models, including LongCat-Image, HunyuanImage-3.0, and FLUX.1-dev. Observing individual categories, the method brings noticeable improvements in Cultural, Time, Space, Biology, and particularly Chemistry, where the Chemistry score improves from 0.40 to 0.75. These results further demonstrate that Gen-Searcher can generalize beyond KnowGen and effectively enhance image generation capabilities on knowledge-based image generation benchmarks.
Ablation Experiments. To verify the effectiveness of different components in Gen-Searcher and better understand the role of each design choice in the overall framework, the work compares the following variants:
(1) The original Qwen-Image baseline without any search enhancement;
(2) Qwen-Image + workflow, using Qwen3-VL-8B-Instruct as the search agent with a manually designed prompt-based search workflow without any additional training;
(3) Qwen-Image + Gen-Searcher-SFT, applying only supervised fine-tuning to train Gen-Searcher without reinforcement learning;
(4) Qwen-Image + Gen-Searcher w.o. text reward, removing the text-based reward and using only the image-based reward during RL training;
(5) Qwen-Image + Gen-Searcher w.o. image reward, removing the image-based reward and using only the text-based reward during RL training;
(6) The complete Gen-Searcher model, including SFT initialization and the proposed dual-reward feedback design during agent RL training.
As shown in Table 3 below, all components contribute positively to the final performance. Compared to the original Qwen-Image baseline, the prompt-based workflow boosts the KnowGen score from 14.98 to 22.91, indicating that merely introducing external search brings benefits for knowledge-intensive image generation. Replacing the prompt-based workflow with Gen-Searcher-SFT further increases the score to 28.15, demonstrating the advantage of directly learning tool usage behavior from trajectory data over relying on manually designed prompt rules. This suggests that supervised learning on curated search trajectories enables the model to better organize search actions, integrate retrieved evidence, and produce more effective grounded prompts for generation.

Agent reinforcement learning provides additional gains on top of SFT, with the complete Gen-Searcher achieving the best performance of 31.52. This indicates that while SFT provides a strong initialization for basic tool usage, RL remains crucial for further optimizing long-horizon search behavior and improving the overall quality of collected evidence and final outputs. Moreover, removing either the text reward or the image reward leads to noticeable declines, with scores dropping to 29.59 and 29.36, respectively. This confirms that the two reward signals play complementary roles. The text reward provides more direct supervision over whether the agent has collected sufficient and correct information at the textual level, while the image reward aligns the policy with the final generation results and encourages the collected evidence to be practically useful for image synthesis. Overall, the ablation results validate the effectiveness of the overall framework, including the learned search behavior, agent RL optimization, and the proposed dual-reward design.
Qualitative Visual Analysis. Figure 6 below shows representative qualitative examples on the KnowGen benchmark. Overall, Gen-Searcher consistently improves the quality and correctness of generated images across different downstream generators in knowledge-intensive, real-world scenarios. First, it is observed that Nano Banana Pro still falls short in generating accurate fine-grained visual attributes for realistic, knowledge-intensive scenes, as it cannot perform image searches to obtain precise visual references. Thus, even when some textual information is correct, the generated identities, object appearances, or architectural details may deviate from the target. In contrast, Gen-Searcher improves Nano Banana Pro by searching for relevant reference images and grounding the generation process with more accurate grounded visual evidence.

An interesting finding is that for Qwen-Image, even when the search agent has collected correct information, the final generation may still be inaccurate due to limitations of the image generator itself (e.g., multi-subject consistency issues, poor text rendering). The fourth row of Figure 6 above provides such an example, where the search content is correct but the generated image still fails to faithfully realize the desired multi-character details. In summary, these examples demonstrate that Gen-Searcher can substantially improve the generation quality of both the powerful proprietary model Nano Banana Pro and the open-source model Qwen-Image by providing support for grounded textual and visual evidence, while some failure cases also indicate that the capabilities of downstream image generators remain a challenge.
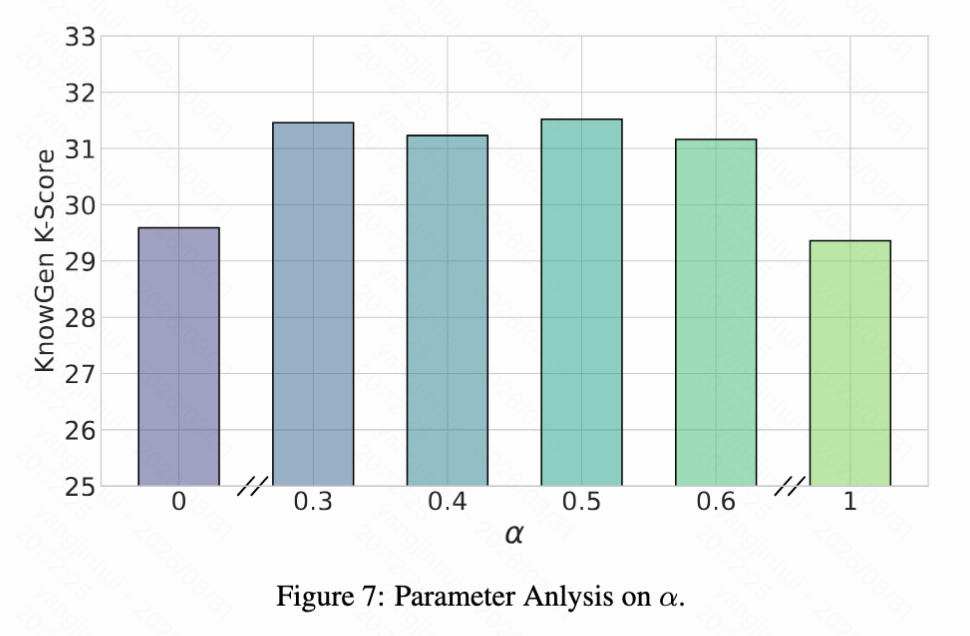
Parameter Analysis. The work further analyzes the balancing coefficient λ between the text-based reward and the image-based reward in the dual-feedback design. Figure 7 below shows the performance of Gen-Searcher trained with RL using different λ values. It is observed that setting λ = 0 or λ = 1 both lead to noticeable performance declines, indicating that both reward signals are necessary for effective training. This aligns with the motivation: relying solely on image rewards introduces high variance due to the randomness and limited capabilities of downstream generators, while relying solely on text rewards ignores whether the collected information actually supports high-quality image synthesis. In contrast, strong performance is consistently observed when λ is set within the range of 0.3 to 0.6, suggesting that the method is relatively insensitive to this hyperparameter over a reasonably wide range.
Conclusion
This work introduces Gen-Searcher, the first study attempting to train a multimodal deep search agent using agentic reinforcement learning for knowledge-intensive image generation. To achieve this setup, the work constructs a specialized data pipeline, creates two training datasets, Gen-Searcher-SFT-10k and Gen-Searcher-RL-6k, and introduces the KnowGen benchmark along with K-Score for evaluating real-world knowledge-intensive image generation. Based on these resources, the work trains Gen-Searcher through a two-stage approach involving supervised fine-tuning and agentic reinforcement learning with dual reward feedback.
Extensive experiments demonstrate that Gen-Searcher significantly enhances various image generation backbones on both KnowGen and WISE, while also exhibiting strong transferability across image generators. The work anticipates that this research will serve as an open foundation for future studies on real-world image generation search agents.
References
[1] Gen-Searcher: Reinforcing Agentic Search for Image Generation
-
How Meituan is Becoming the 'Interface' for AI Integration into the Physical World
-
![]()
RoboScience Machine Science Makes ICRA Best Paper List for Two Years Running with Its 'Embodied Brain' Innovation
-
![]()
Focusing on UTG Ultra-Thin Flexible Glass! CSG Optical New Material Production Base Establishes in Xianning, Hubei
-
![]()
AI Meets Optics: Tsinghua Smart Vision Secures A+ Round Funding Led by Hillhouse Capital
-
![]()
Why are 3C Brands Flocking to Douyin Mall During 618?
-
![]()
Token Economy Falters as Economic Tokenization Faces Challenges
-
![]()
Lenovo's Monthly Surge of 109%, Foxconn Industrial Internet's Market Cap Surpasses Kweichow Moutai: A Collective Resurgence of the 'IT Old Guard'?
-
![]()
After Zhang Xue's Victory, Where is Motorcycle Intelligence Headed?






