The only criterion for testing an Agent's capability is long tasks.
 04/02 2026
04/02 2026
 472
472

The only criterion for testing an Agent's capability is long tasks.
This judgment is based on a simple fact: short tasks can be completed through memorization, while long tasks require understanding. In short tasks, the model only needs to process current input; in long tasks, the model must maintain contextual coherence, remember the initial intent after hundreds of steps, and autonomously adjust strategies when encountering anomalies.
The harsh data from academic benchmarks tell us that the pass rate of current top Agents in long tasks is less than 20%, and code quality continues to deteriorate with task iteration. This is not a problem that can be solved by increasing parameters but requires rethinking Agent architecture—a systematic engineering effort spanning context management, workflow orchestration, multi-agent collaboration, and defense-in-depth.
The competition between Claude and Codex reveals two distinct evolutionary paths. Claude enhances contextual capacity and collaboration, while Codex strengthens superhuman debugging and self-evolution. These paths are not mutually exclusive. An Agent capable of conquering long tasks may require the strengths of both.
The rise of Token economics provides an anchor for the commercial value of long tasks. When an Agent can complete complex tasks that take humans hours or even days, the cost of consuming millions of tokens becomes negligible. The challenge lies in raising the Agent's completion rate from 20% to 80%, preventing code quality degradation during iteration, and maintaining stability amid uncertainty.
These questions have no simple answers. But one thing is certain: in this spring of the Agent the first year , long-task capability is no longer just a technical metric but the sole criterion distinguishing "toys" from "tools." Only Agents capable of completing long tasks have valuable tokens, meaningful business models, and the potential to reshape human workflows and lifestyles.
01
From Short Tasks to Long Tasks: The Agent's Rite of Passage
2026 has been widely recognized as the "Agent Year." The true implication behind this judgment is that AI is transforming from "answerers" to "doers." The core of the third AI wave is autonomous execution, not just Copilot-style assistance.
This shift sounds simple, but its engineering implications are revolutionary.
Over the past two years, the central narrative of large model competition has been the models' capabilities themselves: parameter scale, reasoning depth, and single-step completion rates for complex tasks. These metrics were effective in the Chatbot era, when AI's role was to "answer"—you asked a question, it provided a response, and the task ended in a single interaction.
But when AI begins to act as an "executor," the rules change completely. A slightly complex task, such as developing a web application from scratch or completing a cross-system data analysis report, requires dozens or even hundreds of steps: understanding requirements, decomposing tasks, invoking tools, handling exceptions, verifying results, and self-correcting. Errors can occur at every step, and each error accumulates.
This means that short-task capability is achievable by most models and is essentially just programming automation disguised as an Agent. Long-task capability, however, is the true entry threshold for Agents, testing not just reasoning ability but also the precision of context management, the resilience of workflow orchestration, and the ability to handle uncertainty.
LongCLI-Bench, released in February 2026, specifically tests Agents' long-task capability in real-world development scenarios. The benchmark covers four engineering categories: development from scratch, feature addition, error repair, and code refactoring, each requiring dozens of sequential operations.
The results are sobering: even the most advanced Agents have a pass rate below 20%. More telling is the failure mode: most tasks stall before reaching 30% completion, with critical failures often occurring in the early stages.
This means that even the top Agents today struggle to "get off to a good start" in genuine long tasks.
They can demonstrate astonishing capabilities in single-step tasks, but when the task chain lengthens, dependencies become complex, and sustained contextual memory and strategic adjustments are required, they lose their way.
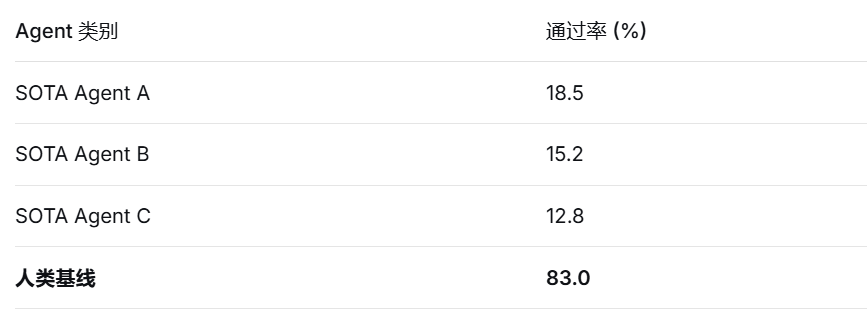
Chart: Long-task pass rate comparison; Data source: LongCLI-Bench, February 2026. Even the most advanced Agents have a pass rate below 20% in long-task benchmarks.
Another study, SlopCodeBench, revealed deeper issues. It tracked Agents' performance in iterative tasks and uncovered a systematic degradation pattern: as task iterations increased, code quality generated by Agents consistently declined. Structural erosion appeared in 80% of trajectories, and redundant code proportions rose in nearly 90%.
The research team compared Agent-generated code with code from 48 open-source Python repositories, finding that Agent code was 2.2 times more redundant than human-written code and exhibited significantly worse structural erosion. When tracking the evolution of 20 code repositories over time, human code quality remained stable, while Agent code worsened with each iteration.
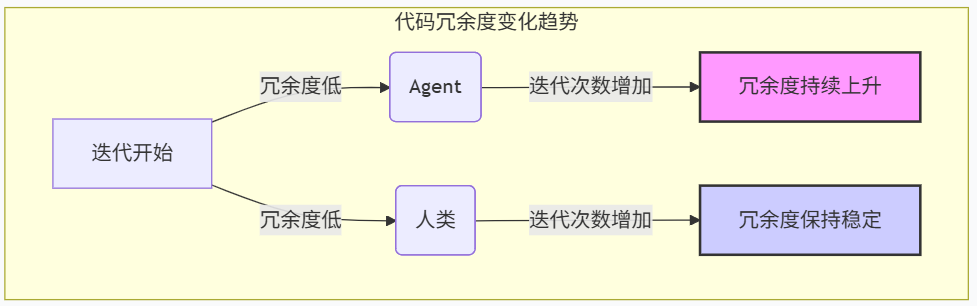
Chart: Agent code redundancy rises continuously with iterations, while human code remains stable. Data source: SlopCodeBench, March 2026.
This finding reveals a fundamental issue: current Agents lack the ability to maintain structural consistency in complex tasks without being sidetracked by short-term demands. Yet, this ability is precisely the core of long-task success.
02
Claude and Codex: Two Paths to Long-Task Mastery
In the arena of AI programming tools, the competition between Claude and Codex offers the best window into the evolution of Agent capabilities.
On February 5, 2026, Anthropic and OpenAI released their flagship models on the same day: Claude Opus 4.6 and GPT-5.3-Codex. This head-to-head clash, superficially a performance contest, fundamentally represents two different understandings of Agent core capabilities.
Claude's Approach: Long Context and Team Collaboration
The most critical upgrade in Claude Opus 4.6 is the expansion of its context window from 200,000 tokens to 1 million tokens. This means you can feed it an entire project codebase at once, allowing it to see all files simultaneously and understand the overall architecture.
But the real game-changer is not just the extended context window but Anthropic's sophisticated design for "context splitting." Calvin French-Owen, a former core researcher on OpenAI's Codex team, Speak frankly (stated bluntly) in a podcast that Claude Code's greatest strength lies in its context-splitting capability.
When faced with complex tasks, Claude Code automatically generates multiple exploratory sub-agents. These sub-agents scan the entire filesystem, retrieve relevant content using tools, and each maintains an independent context window. After completing their tasks, they summarize and feed key information back to the main agent.
This design significantly reduces "contextual noise."
In code repositories—environments with extremely high information density—not all information is equally important. Claude's strategy is to let specialized sub-agents explore, filter, and summarize, then pass only the most critical information to the main agent. This collaborative division of labor allows the main agent to focus on high-level decision-making without being overwhelmed by low-level details.

Chart: Context capacity increased by 5x, key information retrieval capability improved by 4x. (Claude Opus 4.6 vs. previous generation); Data source: Anthropic official technical report.
Codex's Approach: Superhuman Debugging and Self-Evolution
In contrast, OpenAI's GPT-5.3-Codex chose a different path. French-Owen's evaluate (assessment) is that Codex has "personality"—like AlphaGo, it performs superhumanly in debugging complex problems, solving many issues that Opus models cannot.
Codex's core strength lies in its "self-construction" capability. It is OpenAI's first model to help build itself. The Codex team uses Codex to debug its own training processes, manage its deployments, diagnose test results, and conduct evaluations. This "AI building AI" feedback loop means its evolution will accelerate over time.
In product philosophy, OpenAI focuses on creating the most powerful large model (i.e., AGI). This is reflected in Codex's design: it does not pursue the most elegant interaction or the most transparent decision-making process; instead, it aims to find solutions humans cannot in the most difficult debugging scenarios.
The Essence of the Two Approaches
The competition between Claude and Codex reveals two dimensions of Agent core capabilities.
The first dimension is context capacity. Claude Opus 4.6 scored 76% on the MRCR v2 test (which measures AI's ability to find information in massive texts), while Sonnet 4.5 scored only 18.5%. This 76% vs. 18.5% gap is not incremental but qualitative. It determines whether an Agent can remember critical information from early stages in long tasks and maintain its original goal after hundreds of steps.
The second dimension is context quality. French-Owen shared a practical insight: when contextual token usage exceeds 50%, he actively cleans it up. He uses a "canary detection" method—burying irrelevant but verifiable small pieces of information in the context. Once the model starts forgetting, it indicates contextual contamination.
The combination of these two dimensions forms the core formula for Agent long-task capability:
Long-task capability = Context capacity × Context quality
With only capacity but no quality, Agents will drown in a sea of information; with only quality but no capacity, Agents cannot handle truly complex tasks.
03
Only Agents Capable of Long Tasks Have Valuable Tokens
As Agents begin executing long tasks, tokens transition from a technical byproduct to a strategic asset.
Tokens are becoming the "new commodity" of the AI era—standardized, measurable, and tradable. Xia Lixue, co-founder of Wuxin Qiong, experienced this firsthand: since January 2026, the company's token consumption has doubled every two weeks, increasing tenfold to date.
This growth rate was last seen during the 3G mobile data era. But the implications are entirely different: 3G data growth represented a shift in user behavior, while token consumption growth reflects the AI-ization of economic activities themselves.
Jinduan Research Institute Accurately captured (keenly captured) this trend as early as 2025, proposing the concept of "Token economics" in its article "Tokens Will Become the Most Important Resource in the Future World," arguing that tokens will serve as the fundamental unit for measuring value in the intelligence era and reshape resource allocation logic.
At the 2026 GTC Conference, Jensen Huang formally introduced the concept of "Token economics," bringing it to wider recognition. Agents have now become the core workload for large models, with tokens serving as the key production factor driving the digital economy. In March 2026, the National Data Bureau officially translated "token" as " token " (ci yuan) and identified it as the "value anchor of the intelligence era."
Token consumption and task length are positively correlated. More importantly, the value density of tokens increases with task length.
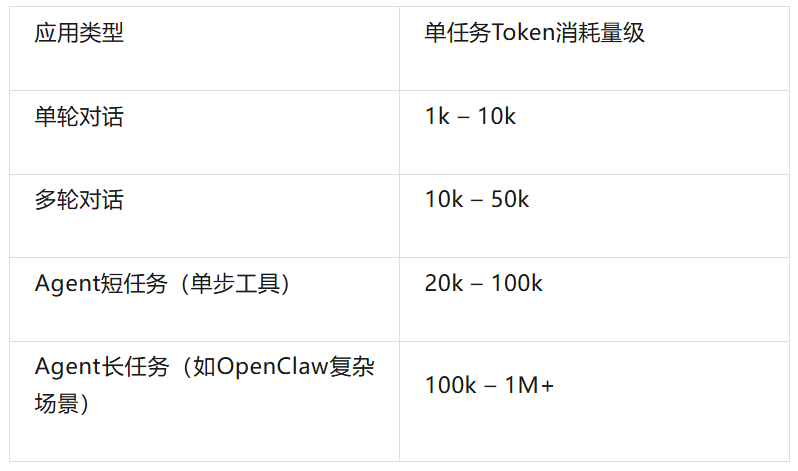
Chart 4: Token consumption magnitude in long tasks. Long-task token consumption can reach millions, tens or even hundreds of times that of short tasks.
In short-task scenarios, token value is linear: 1,000 tokens complete a Q&A, with limited value. But in long-task scenarios, token value is exponential: millions of tokens completing a full software development task can generate commercial value worth tens of thousands of dollars.
This explains why business models are shifting from subscription-based to token-based.
However, this also introduces new challenges. Once Agents operate automatically at high frequencies, uncontrollable massive computational consumption places cost pressures on enterprise clients that are difficult to bear.
This means the commercial value of long tasks lies not just in what they can accomplish but also in how many tokens they consume—and who controls the pricing of those tokens.
AI's most profound impact on the SaaS sector is the structural dismantling of its underlying per-seat pricing model. As digital labor, AI inherently reduces human workload, directly threatening the annual recurring revenue growth logic on which traditional SaaS relies.
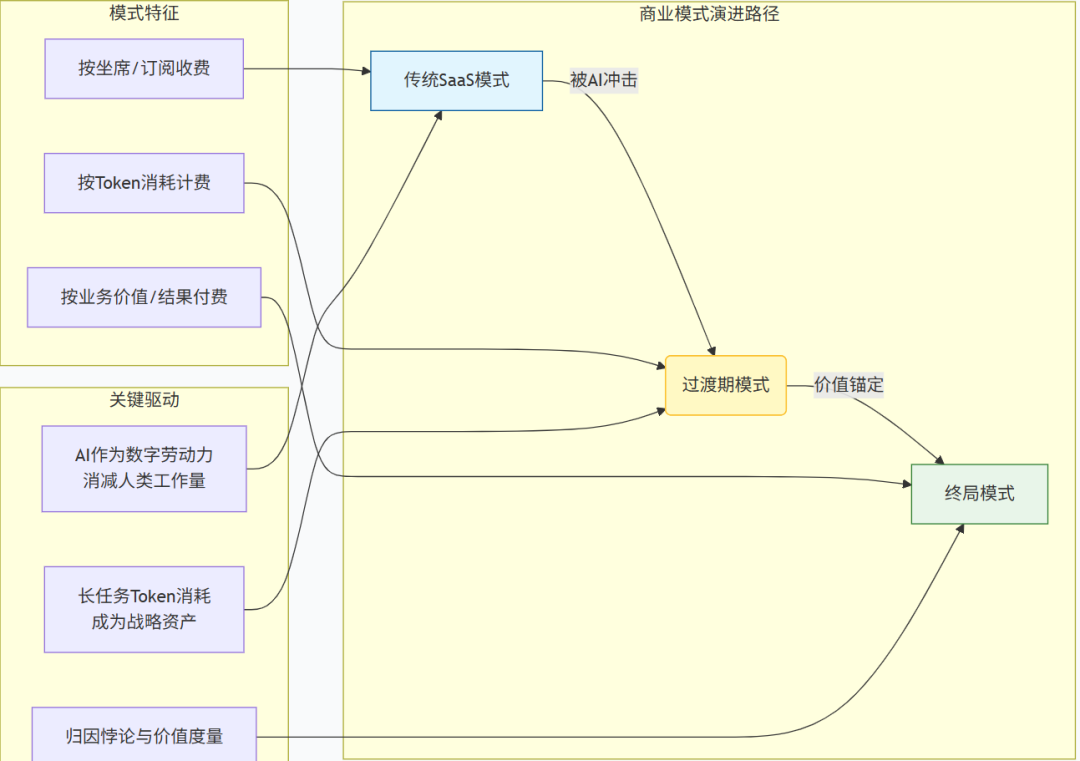
Chart: Agent Business Model Transition: License → Token → Pay for Results. The value anchoring for long tasks is key to this transition. Source: Jinduan Research Institute
The ultimate vision for the industry is to move towards a payment model based on business value or final results. However, this model faces a fundamental measurement challenge: when tasks are sufficiently long and complex, the contributions of AI and humans become deeply intertwined and difficult to separate. This dilemma in value attribution is not a technical issue specific to a certain scenario, but a core proposition that the agent business model must confront.
There are no ready-made answers to these questions.
But what is certain is that in the spring of the first year of agents, the exploration of long-task capabilities is no longer just a competition of technical metrics, but a critical leap that determines whether AI can transform from a 'toy' into a 'tool'.
Continuous innovation around context capacity and quality, multi-agent collaboration, orchestration systems for defense-in-depth, and token economics is collectively painting this grand picture of transitioning from 'answering questions' to 'completing tasks'. The outcome of this transformation will profoundly reshape the way we interact with the digital world and the underlying logic of business value creation.
-
How Meituan is Becoming the 'Interface' for AI Integration into the Physical World
-
![]()
RoboScience Machine Science Makes ICRA Best Paper List for Two Years Running with Its 'Embodied Brain' Innovation
-
![]()
Focusing on UTG Ultra-Thin Flexible Glass! CSG Optical New Material Production Base Establishes in Xianning, Hubei
-
![]()
AI Meets Optics: Tsinghua Smart Vision Secures A+ Round Funding Led by Hillhouse Capital
-
![]()
Why are 3C Brands Flocking to Douyin Mall During 618?
-
![]()
Token Economy Falters as Economic Tokenization Faces Challenges
-
![]()
Lenovo's Monthly Surge of 109%, Foxconn Industrial Internet's Market Cap Surpasses Kweichow Moutai: A Collective Resurgence of the 'IT Old Guard'?
-
![]()
After Zhang Xue's Victory, Where is Motorcycle Intelligence Headed?






