It’s High Time MaaS Providers Rolled Out a “Crazy Thursday” Token Deal
 04/03 2026
04/03 2026
 439
439
Thursdays are my token-guzzling days—keeping tabs on work progress, conducting reviews, and churning out weekly reports.
I fire up Claude Code, type “Help me summarize this week’s work,” and boom—my token quota takes a nosedive. After drafting the report, I’ve already burned through 33% of my allowance. Other tasks haven’t even started, and I’m already capped.
A $200 token package? Gone in 3.5 hours. One task can gobble up 30% of my quota without breaking a sweat.
The real kicker? I’ve got zero clue where my tokens are vanishing.
After Claude Code’s code was accidentally leaked and reverse-engineered by Reddit users, Anthropic finally fessed up: Claude Code was overcharging. Following a barrage of complaints and reverse-engineering evidence on Reddit, the official account chimed in: “We’re on it—this is our top priority.”
This boils down to an engineering blunder. On one hand, the Harness architecture lets AI tackle complex tasks, but at a steep cost compared to single-model chats. On the other, Claude’s traffic algorithm is riddled with flaws.
I get it—the agents are token-hungry beasts. To get decent results, I’ve got to feed them more tokens.
So, do domestic MaaS providers face the same ordeal? Can they at least promise a fix during peak AI usage?
That’s why I’m pitching this: MaaS providers should roll out a weekly “Crazy Thursday” token special—unlimited tokens, just V me $50 to fuel my AI ambitions.

What’s Lurking in the Application-Layer Black Box?
Why is Claude Code so effective? It’s not a single model—it’s a multi-agent pipeline. Coders, reviewers, and debuggers operate independently. The token consumption of these sub-agents is lumped into “one conversation.”
The Harness architecture lets AI handle complex tasks, but token costs skyrocket. Community tests reveal token usage can be 5–10 times higher than direct model calls for intricate tasks. This overhead is buried in “one conversation” bills, leaving users in the dark.
Even sneakier is the model switching within the Coding Plan. Roles like Plan Mode, Reviewer, and Debugger trigger invisible calls with every switch. You think you’re chatting with “one AI,” but behind the scenes, it’s hopping between five or six sub-agents.
Then there’s the truth dug up by Reddit users: two independent cache bugs render prompt caching useless. These bugs are particularly damaging.
Bug 1: Sentinel Replacement Breaks Caching
Claude Code uses separate binaries for Windows/macOS/Linux. When conversations involve billing logic, sensitive fields are replaced with sentinel values. But this replacement messes up the hash consistency of prompt caching, causing cache misses even when they should hit, forcing redundant token calculations.
Bug 2: Resume Parameter Forces Cache Invalidation
Starting from v2.1.69, the resume parameter (for resuming interrupted conversations) invalidates the cache. If you exit mid-conversation or switch devices, all prior context caching is wiped, and the system recalculates tokens for the entire history. For heavy users with long contexts, this is a nightmare—every “continue conversation” burns money.
The combined effect of these bugs is catastrophic. Normally, caching should save 90% of redundant computation costs when reading a GitHub PR. But due to the bugs, you pay full price every time, inflating costs by 10–20 times.
So, the Harness structure not only has explosive consumption but also accelerates billing due to algorithmic flaws.
What’s even more ironic is that Anthropic only acted after users reverse-engineered the bugs. As one user roasted: “You’ve got the world’s best models and developers, yet you ignored thousands of complaints until someone disassembled your code.”
This “users discover first, vendors admit later” pattern is now the norm in AI. ChatGPT Plus never refunds historical quotas, and Gemini Advanced “slows down” without warning. Anthropic’s issue isn’t the bugs themselves—it’s the lack of basic billing transparency. When users question bills, they can’t provide data to prove their innocence.
Compare this to OpenClaw, which updates 1–2 times a week and fixes issues overnight. Anthropic’s sluggish response exposes a harsh reality: when model capability becomes the moat, user experience and billing transparency become expendable.
Technical debt is passed on to users. How much of your money goes to “actual AI usage” versus “system waste”? No one knows.
How Do Domestic MaaS Providers Stack Up?
If Claude Code’s application layer is a black box, what about domestic MaaS providers?
Honestly, domestic providers are generally more transparent. At least at the API layer, they break costs down further. But at the application layer, Harness/Agent scheduling costs remain hidden:
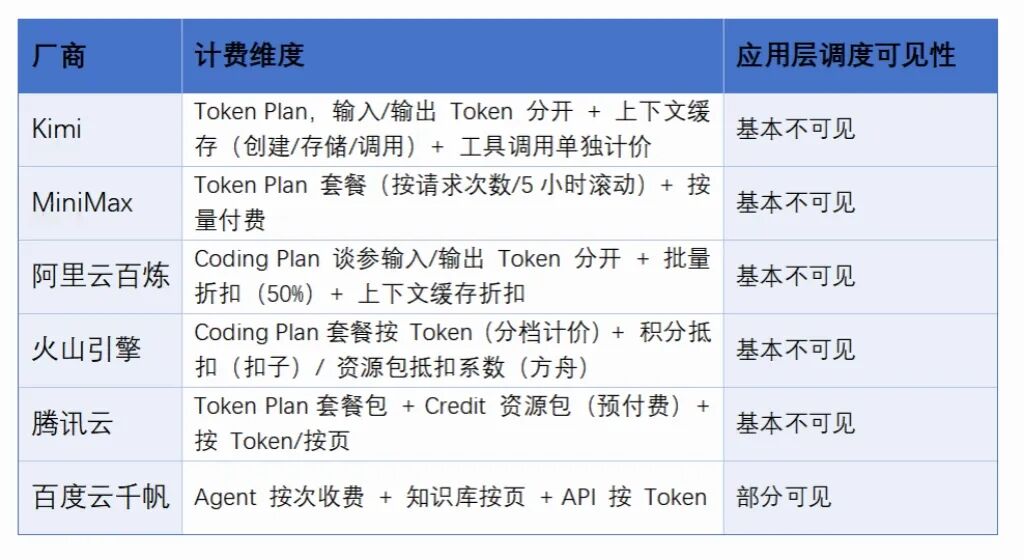
Token-based pricing is transparent and traceable at the API level, but at the application layer—where problems are actually solved—transparency falls short. Maybe because everyone’s still stuck in OpenClaw’s framework without innovation.
Since OpenClaw’s rise, providers have rolled out custom token packages. But quota limits, “flexible” deployment of outdated models, and throttling during peak hours are common. Users sometimes revert to pay-as-you-go API pricing, defeating the purpose: fixed packages fail, so they fall back to the old metered model.
Billing transparency stops at the API layer. When using AI applications that invoke tokens via agents, scheduling costs are a black box. While providers like Kimi and Volcano now limit agent usage via quotas, users must wait for refreshes after depletion.
API transparency suits developers; application transparency suits enterprise buyers. When explaining to your boss, “I invoked the Deep Research Agent 500 times” is more convincing than “I consumed 1 million tokens.” Interestingly, among six providers, only Baidu displays agent costs explicitly. The other five bundle Harness scheduling costs into tokens.
This isn’t about money—it’s about users’ right to know how their compute resources are used.
In the cloud era, no one accepts “$200/month for a server, but no breakdown of CPU vs. bandwidth.”
AWS bills down to millisecond compute time, byte-level traffic, and even regional price differences. Observability is the foundation of mature cloud computing.
AI applications are still in the Wild West. Providers market Harness scheduling and multi-agent collaboration as “magic,” hiding technical debt as “usage.” This strips users of transparency.
Users need detailed bills, a “debug mode” toggle to view Harness call chains, automatic refunds for bug-induced overcharges (not “under investigation”), and a clear distinction between “what you spent” and “what you should’ve spent.”
Given how fast MaaS providers are evolving, by next Crazy Thursday, I hope to at least know how my tokens were devoured. V me $50, and I’ll treat myself to two extra Original Recipe chicken pieces.
-
How Meituan is Becoming the 'Interface' for AI Integration into the Physical World
-
![]()
RoboScience Machine Science Makes ICRA Best Paper List for Two Years Running with Its 'Embodied Brain' Innovation
-
![]()
Focusing on UTG Ultra-Thin Flexible Glass! CSG Optical New Material Production Base Establishes in Xianning, Hubei
-
![]()
AI Meets Optics: Tsinghua Smart Vision Secures A+ Round Funding Led by Hillhouse Capital
-
![]()
Why are 3C Brands Flocking to Douyin Mall During 618?
-
![]()
Token Economy Falters as Economic Tokenization Faces Challenges
-
![]()
Lenovo's Monthly Surge of 109%, Foxconn Industrial Internet's Market Cap Surpasses Kweichow Moutai: A Collective Resurgence of the 'IT Old Guard'?
-
![]()
After Zhang Xue's Victory, Where is Motorcycle Intelligence Headed?






