How do Convolutional Neural Networks Enable Autonomous Driving to Identify Obstacles?
 04/13 2026
04/13 2026
 495
495
Throughout the development of autonomous driving, the perception system has consistently served as the vehicle's "eyes," with the core mission of enabling computers to comprehend the complex and ever-changing physical world. Convolutional Neural Networks (CNNs), a deep learning model specifically designed for processing grid-like data structures such as images and videos, have become the cornerstone of autonomous driving perception.
By simulating the processing methods of the human visual system, CNNs transform raw pixel data into object descriptions with semantic information, thereby enabling vehicles to identify obstacles, understand road markings, and assess traffic intentions. Unlike early computer vision techniques, this network architecture no longer relies on manually set rules by humans. Instead, it automatically extracts the most critical visual features for driving decisions by learning from millions of driving scenarios.
Simulating the Deep Mechanisms and Perceptual Logic of Human Vision
The ability of CNNs to efficiently parse images stems from their unique three-layer core structure: convolutional layers, activation layers, and pooling layers.
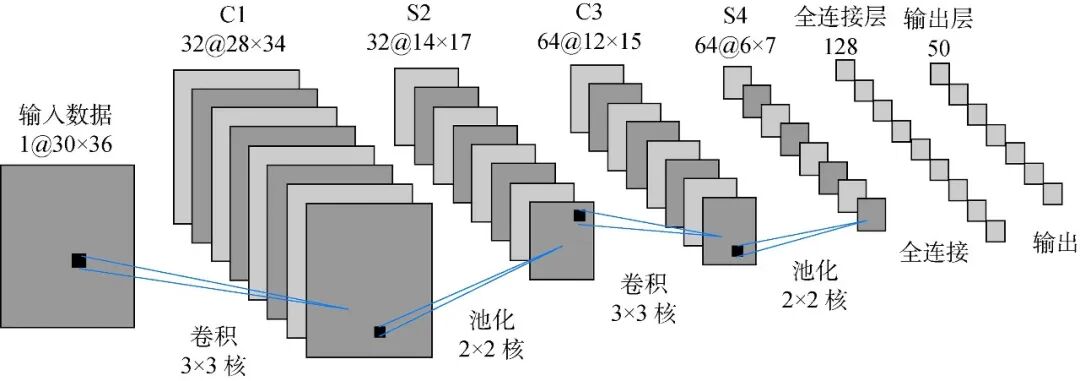
Image Source: Internet
The convolutional layer is the most fundamental computational unit of the entire network. It utilizes small matrices called "convolutional kernels" or "filters" that slide across the image. Each convolutional kernel acts like a specialized detective, focusing on identifying specific patterns within the image.
In the initial stages of the network, these detectors search for the simplest visual cues, such as horizontal or vertical lines, color edges, and changes in brightness and darkness. This local perception mechanism significantly reduces computational load and enables the model to recognize spatial relationships.
As information progresses deeper into the network, these simple lines are combined into circular outlines, rectangular objects, or more complex textures, ultimately evolving into an understanding of complete objects. This allows the system to recognize clear traffic signs or a car changing lanes, among other objects.
To empower the network with the ability to handle real-world nonlinear problems, an activation layer is added after the convolutional layer, with the Rectified Linear Unit (ReLU) being the most commonly used. The mathematical expression of this function is very simple, namely f(x)=max(0,x). Its role is to filter out weak signals and amplify strong ones, ensuring that only the most important features proceed to the next processing stage.
The pooling layer further compresses the spatial dimensions of the data through downsampling. This approach not only significantly reduces the number of parameters required for subsequent computations but also introduces an extremely important characteristic: translation invariance.
This means that regardless of whether a pedestrian is in the center or the corner of the image, the system can identify them through similar feature responses. This process of synthesizing high-level semantics from low-level features through a hierarchical structure not only improves recognition accuracy but also makes the autonomous driving system more resilient when facing objects from different perspectives and distances.
This end-to-end learning approach has completely transformed the traditional machine vision process, which required experts to manually adjust parameters. The power of CNNs also lies in their versatility. This architecture is not only applicable to visual images but can also be adapted to process LiDAR point cloud data or acoustic sensor spectrograms, providing comprehensive environmental perception support for vehicles.
From Road Object Recognition to Environmental Semantic Understanding
In the daily operation of autonomous driving, CNNs undertake multiple tasks ranging from "recognizing objects" to "understanding the environment." Object detection is the most direct application, requiring the system not only to determine whether targets exist in the image but also to accurately locate them.
The widely used YOLO (You Only Look Once) series models achieve extremely high real-time processing speeds by dividing the entire image into grids and simultaneously predicting the bounding boxes of all targets in a single computation. This is crucial for high-speed autonomous vehicles, as the system must react the moment a pedestrian steps into the lane.
However, merely locking onto objects with rectangular boxes is far from sufficient for complex path planning. Vehicles also need to precisely understand the drivable area of the road, which involves semantic segmentation technology. By classifying images pixel by pixel, CNNs can categorize every pixel in the field of view as "road," "sidewalk," "obstacle," or "lane marking."
Mask-based CNN models, such as Mask R-CNN, excel in this domain. They can not only outline vehicles but also delineate their precise contours. This pixel-level perception accuracy allows autonomous vehicles to accurately calculate the distance to neighboring vehicles in congested urban streets or execute safe U-turns in narrow alleys.
In the task of traffic sign recognition (TSR), the system faces challenges such as significant variations in sign scale and complex backgrounds.
By integrating Feature Pyramid Networks (FPNs), CNNs can extract information from feature maps at different resolutions, ensuring that both large stop signs nearby and blurry speed limit signs in the distance are effectively captured.
To further enhance system reliability, the perception framework also incorporates temporal sequence information from consecutive frames. This spatiotemporal fusion strategy effectively eliminates judgment errors caused by momentary light flickers or camera obstructions.
Additionally, perception results are cross-verified with high-definition maps. If the visual system identifies a temporary construction sign at a location marked as a normal road segment on the map, the system elevates its alert level to ensure the safest decisions are made under the protection of redundant information.
Exploring Directions for Perceptual Blind Spots and Handling Rare Scenarios
Although CNNs have performed exceptionally well in standardized scenarios, autonomous driving perception still faces the "long-tail problem." These situations include suddenly appearing irregular obstacles on the road, pedestrians in unusual clothing, or extremely rare construction guidance signs.
Traditional perception models may produce false positives or false negatives when confronted with such unseen data. To overcome this challenge, the industry is dedicated to developing more reasoning-capable "occlusion-aware" frameworks. For instance, the OAIAD architecture introduces an explicit occlusion modeling module that utilizes vectorized query mechanisms to infer potential risks in areas obscured by preceding vehicles.
If the system realizes that a large truck is blocking the view ahead on the left, it will adopt defensive driving strategies, such as proactively adjusting the lateral position to expand the field of view or moderately reducing speed to allow reaction time.
When handling these highly challenging scenarios, the combination of multi-sensor fusion and CNNs demonstrates immense potential. While visual systems have a natural advantage in semantic recognition, they still have limitations under drastic light changes or severe weather conditions (e.g., dense fog, heavy rain).
By deeply coupling visual features processed by CNNs with depth information from LiDAR and velocity information detected by millimeter-wave radar, the system can obtain a more reliable environmental representation. This fusion strategy has been statistically proven to significantly reduce collision risks.
Final Remarks
Through its sophisticated hierarchical feature extraction mechanism, CNNs have constructed a detailed and robust digital world for autonomous vehicles. From the basic convolutional kernel scanning to pixel-level semantic segmentation, and then to complex occlusion reasoning and multi-sensor fusion, CNNs demonstrate capabilities far surpassing traditional technologies at every stage.
Although addressing extremely complex long-tail scenarios still requires ongoing exploration, CNNs, as the core of the perception system, have fundamentally defined the technological landscape of modern autonomous driving. With the widespread availability of computing power and algorithmic iterations, autonomous driving will become safer, more efficient, and intelligent.
-- END --
-
![]()
Is Design the Root of the Problem? The Lexus ES Dilemma: Despite New and Old Models Coexisting Post-Redesign, Sales Plummet by 40%
-
![]()
Are Japanese Automakers Now Taking Cues from China? A Perspective on Japan's Reversal in Learning
-
![]()
In the First Half of the Year, Car Companies’ Profit Margin Plummets to 3.8%! CPCA: Automakers Must Speed Up Battery Production Amid Upstream Pressures | MINGJING Pro
-
![]()
Tesla’s Q2 Revenue Rises, Yet Profitability Slips; Energy Storage Margins Take a Dive
-
Chinese Automakers Strike Gold Overseas: Prices Double?
-
![]()
Joint Ventures, Once Dismissed, Are Now Making a Comeback
-
![]()
Automotive Market News: Retail Penetration Rate of New Energy Vehicles Reaches 62.8%
-
![]()
Once a Sales Leader Among New Car Manufacturers, Now Selling Equipment at Bargain Prices