AI-Generated Image Detail Collapse Terminator! RefineAnything: Multimodal Region-Level Refinement, One-Click Restoration for Text/Logo/Faces with Pixel-Level Background Preservation
 04/14 2026
04/14 2026
 629
629
Analysis: The Future of AI-Generated Content 
Results Demonstration
Input:

Reference Image:

Prompt: "Refine the LOGO"
Output:

Input: 
Prompt: "Refine the text 'Dinghao Mall'"
Output: 
【Introduction】While AI-generated image technology advances rapidly, "local detail collapse" remains a critical pain point for real-world applications—distorted text, deformed logos, finger abnormalities, and broken fine structures are especially detrimental in high-precision scenarios like e-commerce posters, advertising design, and UI assets. Most existing editing models focus on coarse semantic edits, struggling to refine local details without disrupting the background. To address this, the research team proposes RefineAnything—the first multimodal diffusion framework dedicated to region-level image refinement. By simply specifying a region (via scribbles or bounding boxes), users can restore fine details within the region while strictly preserving every pixel outside it, supporting both referenced and reference-free modes. This work has been accepted by ECCV 2026. The code is open-source, with checkpoint release planned.
I. Challenge: The "Last Mile" Problem in AI-Generated Images
Modern image generation models excel in overall composition and semantics but frequently fail in local fine details:
Local Detail Collapse: High-frequency structures like text, logos, and fine lines in generated images often appear twisted, broken, or blurred—yet these details are the most critical information carriers in commercial scenarios.
Weak Region Controllability: Existing instruction-driven editing models struggle to precisely control "where to edit," leaving users unable to effectively specify repair regions.
Background Drift: Editing models often inadvertently alter background content when refining local areas, especially when the target region occupies a small proportion of the full image.
RefineAnything is designed to simultaneously solve these three challenges—precise regions, effective details, and unchanged backgrounds.
II. Core Methodology of RefineAnything
1. Overall Architecture: Multimodal Conditional-Driven Regional Refinement 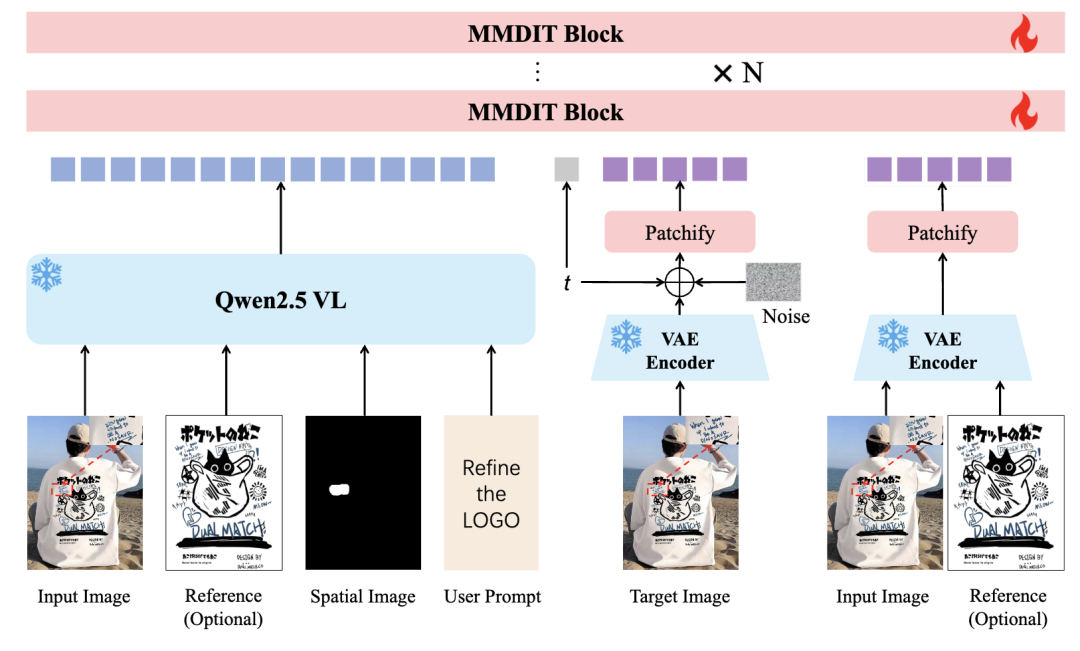
Built upon the Qwen-Image architecture, RefineAnything consists of three core components:
**Frozen Multimodal Encoder (Qwen2.5-VL)**: Unifies input images, optional reference images, region annotations (scribbles/bounding boxes), and text instructions into multimodal conditional tokens, providing high-level semantic guidance for the denoising process.
VAE Visual Encoder: Encodes input and reference images into VAE latent variables, supplying low-level fine visual information that synergizes with multimodal tokens.
MMDiT Denoising Backbone: Under dual conditioning from multimodal tokens and VAE latent variables, it progressively denoises to generate refined results. Training requires only LoRA fine-tuning of attention projection layers (to_q, to_k, to_v, to_out).
This architecture uniformly supports both referenced (e.g., Repair deformation Logo based on an original logo reference) and reference-free (e.g., "refine the face" via text instruction alone) usage scenarios.
2. Focus-and-Refine: Focused Cropping, Refinement, and Seamless Pasting 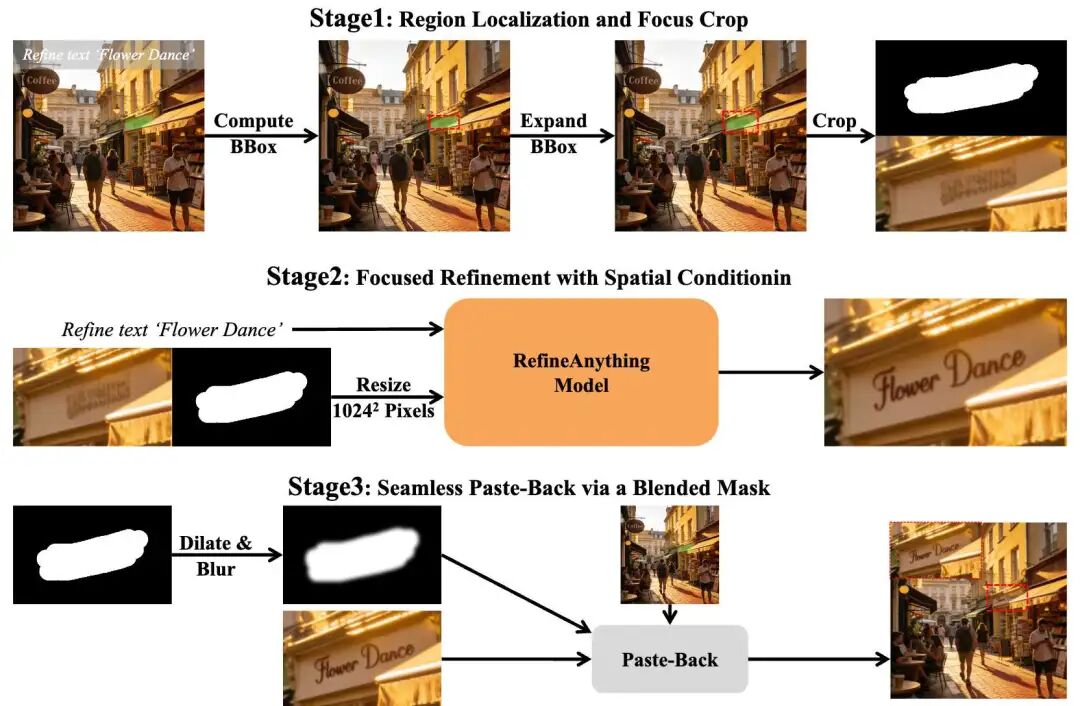
This is one of RefineAnything's core innovations, stemming from a counterintuitive key finding:
At fixed input resolution, cropping the target region, upsampling it to full-image resolution, and then feeding it into the VAE—without introducing any new information—significantly improves reconstruction quality within the region compared to direct full-image encoding.
This suggests that the bottleneck restricting local refinement quality is not insufficient information but whether the model's fixed-resolution resources are allocated to the correct location. Based on this, the team proposes a three-step Focus-and-Refine strategy:
Step 1—Region Localization and Focused Cropping: Calculate a bounding box from user scribbles/bounding boxes, expand margins, crop the target region, and upsample it to the model's input resolution, concentrating resolution resources on the area to be repaired.
Step 2—Focused Refinement: On the cropped view, using the cropped scribble mask as spatial conditioning, perform conditional generation—optionally with a reference image—to produce the refined result.
Step 3—Seamless Pasting: Dilate + Gaussian-blur the crop mask to generate a soft fusion mask, then weight-blend the refined result with the original image within the cropped region before pasting it back into the full image, architecturally ensuring strict background preservation.
3. Boundary Consistency Loss
To further eliminate seam artifacts at paste boundaries, the team designed a boundary-aware training loss: it increases supervision weight in a narrow band near the edited region's boundary during training, encouraging the model to generate results that naturally fuse with surrounding context—significantly improving pasting naturalness.
III. Data Contributions: Refine-30K Dataset and RefineEval Benchmark
Refine-30K Training Dataset
The team constructed a dedicated training set containing 30K samples:
20K Referenced Samples: Generated high-quality paired data through a complete pipeline of VLM cross-image localization → SAM3 segmentation → scribble-based local degradation → controlled restoration.
10K Reference-Free Samples: Located salient targets on single images, generated local degradation, and introduced a VLM defect validation mechanism to filter unreasonable degraded samples, ensuring data quality.
RefineEval Benchmark
The team simultaneously constructed a dedicated evaluation benchmark, RefineEval, covering 67 cases and 402 degraded inputs. It assesses both referenced and reference-free settings for edited region fidelity and background consistency.
IV. Experimental Results: Comprehensive Superiority Over Strong Baselines
1. Referenced Refinement
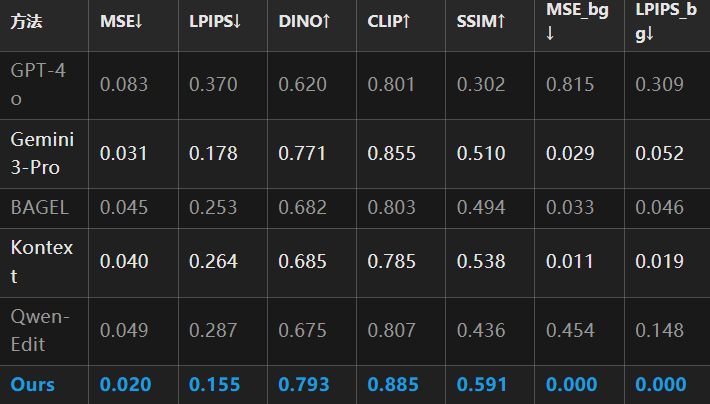
RefineAnything leads across all metrics: compared to the strongest open-source baseline Kontext, MSE reduces by **50%**, LPIPS by **41%**, and DINO/CLIP similarity increases by +0.108/+0.100. Notably, background preservation metrics approach perfection (MSE_bg=0.000, SSIM_bg=0.9997), fundamentally eliminating background drift.
2. Reference-Free Refinement
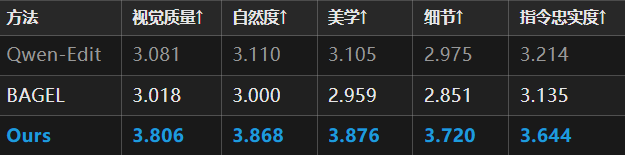
Under reference-free settings, RefineAnything ranks first across all five dimensions, improving by +0.4~0.8 points over the strongest baseline Qwen-Edit.
3. Ablation Study: All Components Are Indispensable
Removing Focus-and-Refine: Refinement quality declines markedly, subtle errors become difficult to repair, and new artifacts may be introduced.
Removing Boundary Consistency Loss: Visible seams, color inconsistencies, and structurally unreasonable splices appear at paste boundaries.
Only when the two core components work together can high-quality local refinement and seamless fusion be achieved.
V. Conclusion and Outlook
RefineAnything is the first to study region-level image refinement as a dedicated problem setting, proposing a complete solution:
The Focus-and-Refine strategy concentrates the model's resolution resources on the target region, significantly boosting refinement effectiveness;
Boundary Consistency Loss eliminates paste boundary artifacts, ensuring repaired results naturally fuse with surrounding content;
Refine-30K + RefineEval provide standardized data support for training and evaluation in this direction.
Under pixel-level background preservation, the framework achieves high-quality restoration of fine details like text, logos, faces, and hands, clearing the "last mile" obstacle for AI-generated images in commercial high-precision scenarios.
【Conclusion】
With its elegant "focus-crop-refine-seamless-paste" design, RefineAnything provides the first systematic solution to local detail repair in AI image generation. From e-commerce product images to advertising design, from UI assets to social media content, this work delivers practical technical support for real-world applications requiring "pixel-level precision."
References
[1] RefineAnything: Multimodal Region-Specific Refinement for Perfect Local Details
-
How Meituan is Becoming the 'Interface' for AI Integration into the Physical World
-
![]()
RoboScience Machine Science Makes ICRA Best Paper List for Two Years Running with Its 'Embodied Brain' Innovation
-
![]()
Focusing on UTG Ultra-Thin Flexible Glass! CSG Optical New Material Production Base Establishes in Xianning, Hubei
-
![]()
AI Meets Optics: Tsinghua Smart Vision Secures A+ Round Funding Led by Hillhouse Capital
-
![]()
Why are 3C Brands Flocking to Douyin Mall During 618?
-
![]()
Token Economy Falters as Economic Tokenization Faces Challenges
-
![]()
Lenovo's Monthly Surge of 109%, Foxconn Industrial Internet's Market Cap Surpasses Kweichow Moutai: A Collective Resurgence of the 'IT Old Guard'?
-
![]()
After Zhang Xue's Victory, Where is Motorcycle Intelligence Headed?






