When Occupancy Networks Are Available, Do We Still Need Convolutional Neural Networks (CNNs) in Autonomous Driving?
 04/20 2026
04/20 2026
 613
613
In the realm of visual perception for autonomous driving, Occupancy Networks are rapidly gaining traction, showcasing immense potential to supersede traditional object detection techniques. A pertinent question was posed in a recent article discussing Occupancy Networks: With the advent of Occupancy Networks, is there still a need for Convolutional Neural Networks (CNNs) in autonomous driving?
To address this query, it's essential to elucidate the distinct roles they play within the overall system. Occupancy Networks primarily function as a means to represent the world in autonomous driving, whereas CNNs are a cornerstone tool for processing image data. The relationship between the two is not one of mutual exclusivity but rather one of complementarity, with each fulfilling its unique function.
How Does Traditional Visual Recognition Operate?
Prior to the widespread adoption of Occupancy Networks, the predominant perception solution for autonomous driving was CNN-based object detection. Imagine this as drawing frames around every image captured by the camera.
When the camera captures the road ahead, the CNN extracts features such as edges, textures, and shapes from the pixels through successive convolutional operations. If it detects that the features in a specific area match those of a car or a person it has been trained to recognize, it will label that location and provide a rectangular frame.
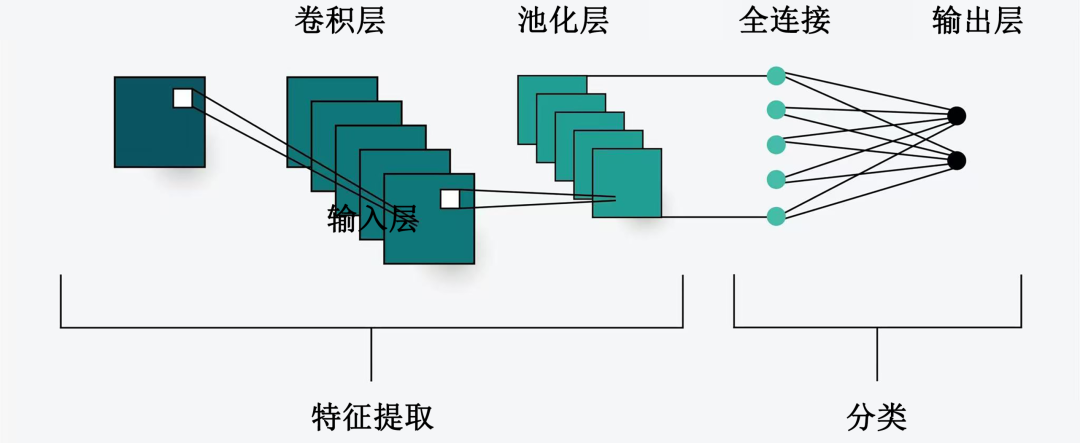
Convolutional Neural Network Architecture
This method proves highly efficient when dealing with standard objects, as it directly informs the system of the distance to a car ahead.
However, relying solely on framing presents a significant drawback: it struggles to cope with unseen objects.
If a strangely shaped plastic bucket falls onto the road, or if there is an overturned truck carrying irregularly shaped building materials, traditional CNN-based object detection models may fail to detect them due to the inability to find matching features.
This is because such models are essentially tackling classification problems. If the problem extends beyond their knowledge base, they may opt to ignore it. Such undetected objects are clearly unacceptable for autonomous driving, which strives for ultimate safety.
Why Are Occupancy Networks Necessary?
To address this "long-tail problem," Occupancy Networks emerged. Instead of attempting to differentiate whether the object ahead is a car or a tree, Occupancy Networks directly partition 3D space into countless tiny cubes, commonly referred to as voxels.
The objective of Occupancy Networks is straightforward: to ascertain whether each cube is occupied or vacant.
In this manner, the perception system can construct a real-time 3D physical world model. In this model, even if there is a pile of disorganized debris ahead, as long as it occupies space, the Occupancy Network will mark it as impassable.
This shift from solving classification problems to making spatial judgments significantly enhances the adaptability of autonomous driving to unknown environments. It no longer depends on complex object labels but returns to the essence of the physical world.
Through Occupancy Networks, vehicles can more precisely perceive the edges, height, and depth of objects and even forecast their movement trends in space.
This not only resolves the issue of undetected irregularly shaped objects but also furnishes a cleaner and more three-dimensional environmental map for the vehicle's planning and control system.
Are Occupancy Networks and CNNs Interchangeable?
Given the potency of Occupancy Networks, can CNNs be dispensed with? The answer is negative. In fact, in current Occupancy Network architectures, CNNs still play an indispensable foundational role.
It's crucial to understand that Occupancy Networks handle the occupancy of 3D space, but the input from sensors, particularly the raw images captured by cameras, remains two-dimensional pixels.
To transform these chaotic pixels into meaningful features, the most mature and efficient method remains CNNs.
In the current perception process, CNNs serve as the backbone network. After the camera captures an image, the CNN initially performs preliminary feature extraction, converting the image into high-dimensional feature vectors. These feature vectors encompass key information such as the color, texture, and brightness variations of objects.
Subsequently, this information is fed into subsequent modules (such as Transformers or cross-spatial mapping modules) to be transformed into occupancy probabilities in 3D space.
In essence, CNNs are responsible for "seeing," providing the raw materials for perception; while Occupancy Networks are responsible for "thinking," constructing the world into a 3D model based on these materials.
How Will Future Perception Architectures Evolve?
Although CNNs currently remain the dominant backbone network, the perception architecture of autonomous driving is indeed undergoing transformation. With the advancement of computing hardware, some tasks previously managed by CNNs are shifting toward Transformers, particularly in processing multi-camera fusion and long-term temporal information, where Transformers exhibit stronger global modeling capabilities.
However, this does not imply that CNNs will vanish entirely. In edge processing tasks with extremely stringent real-time requirements and relatively limited computing resources, CNNs remain highly competitive due to their exceptionally efficient local feature extraction capabilities.
Future autonomous driving perception systems will likely entail a deep integration of multiple technologies. CNNs may persist in processing image pixels at the bottom layer, swiftly extracting basic features through lightweight designs; while Occupancy Networks will oversee the broader perspective at a higher level, integrating data from various sensors into a unified spatial model.
In this evolutionary trajectory, Occupancy Networks have not rendered CNNs obsolete but have liberated them from the onerous task of framing, enabling them to revert to their most proficient role of image feature extraction.
The synergy of the two empowers autonomous vehicles to not only perceive objects on the road but also genuinely comprehend the three-dimensional physical world.
-- END --
-
How Meituan is Becoming the 'Interface' for AI Integration into the Physical World
-
![]()
RoboScience Machine Science Makes ICRA Best Paper List for Two Years Running with Its 'Embodied Brain' Innovation
-
![]()
Focusing on UTG Ultra-Thin Flexible Glass! CSG Optical New Material Production Base Establishes in Xianning, Hubei
-
![]()
AI Meets Optics: Tsinghua Smart Vision Secures A+ Round Funding Led by Hillhouse Capital
-
![]()
Why are 3C Brands Flocking to Douyin Mall During 618?
-
![]()
Token Economy Falters as Economic Tokenization Faces Challenges
-
![]()
Lenovo's Monthly Surge of 109%, Foxconn Industrial Internet's Market Cap Surpasses Kweichow Moutai: A Collective Resurgence of the 'IT Old Guard'?
-
![]()
After Zhang Xue's Victory, Where is Motorcycle Intelligence Headed?






