World model V-JEPA steps into assisted driving applications, ready to revolutionize Physical AI.
 04/20 2026
04/20 2026
 510
510
Recently, AI luminary Yann LeCun reposted a new product called BADAS-2.0, built on his world model V-JEPA 2 theory, on his personal LinkedIn and X accounts. He stated that the JEPA world model will save lives and is now being applied in Physical AI. 
So, this article decodes and analyzes:
What is the product BADAS-2.0?
What physical hardware does it rely on?
What performance can it achieve?
How does it utilize V-JEPA2 technology for implementation?
What are its current development status, challenges, and constraints?
How will future world models assist in the development of autonomous driving and Physical AI?
We hope to provide some information and inspiration to everyone.
1. What is BADAS-2.0?
BADAS (Based on V-JEPA2 Advanced Driver Assistance System) is the second-generation "collision anticipation" model family launched by Nexar AI. It identifies collision risks through a world model and then provides interpretable and interactive alerts via a Visual Language Model (VLM).
Its positioning fundamentally differs from traditional ADAS: Traditional ADAS is "reactive" (objects appear in the danger zone → alert/brake), while BADAS is "predictive"—it outputs the probability of "this vehicle being involved in an accident" 0.5–3 seconds before an incident occurs.
So, this logic is somewhat similar to the world model discussed in our previous article, "The Second Half of Autonomous Driving: Equipping Machines with 'Common Sense' and 'Deductive Capabilities' through World Models." It predicts future events, though this model does not generate trajectory actions for execution, similar to active safety's Forward Collision Warning (FCW).
The V-JEPA2 world model theory can work effectively in this product logic. Essentially, AEB-type collisions and even assisted driving can be achieved, which is why Yann LeCun reposted and promoted it on his personal LinkedIn and X accounts.
In the BADAS-2.0 paper, the authors refer to this paradigm as ego-centric incident anticipation. Compared to academic benchmarks like DAD/DADA-2000/DoTA, it only focuses on events involving the host vehicle, filtering out 40–92% of "false alerts about other vehicles' accidents" in real-world deployments.
BADAS-2.0 enhances the capabilities of its 1.0 version along three axes:
(i) Long-tail accuracy—introducing 10 new rare safety-critical scenario benchmarks;
(ii) Edge distillation—distilling the large 300M ViT-L model (ViT: a method that divides images into small patches (regions) and inputs them into a Transformer for natural language processing) into two versions: 86M and 22M;
(iii) Interpretability—attention heatmaps + Visual Language Model (VLM) generate natural language action recommendations (BADAS-Reason).
Its overall algorithmic model architecture is as follows: 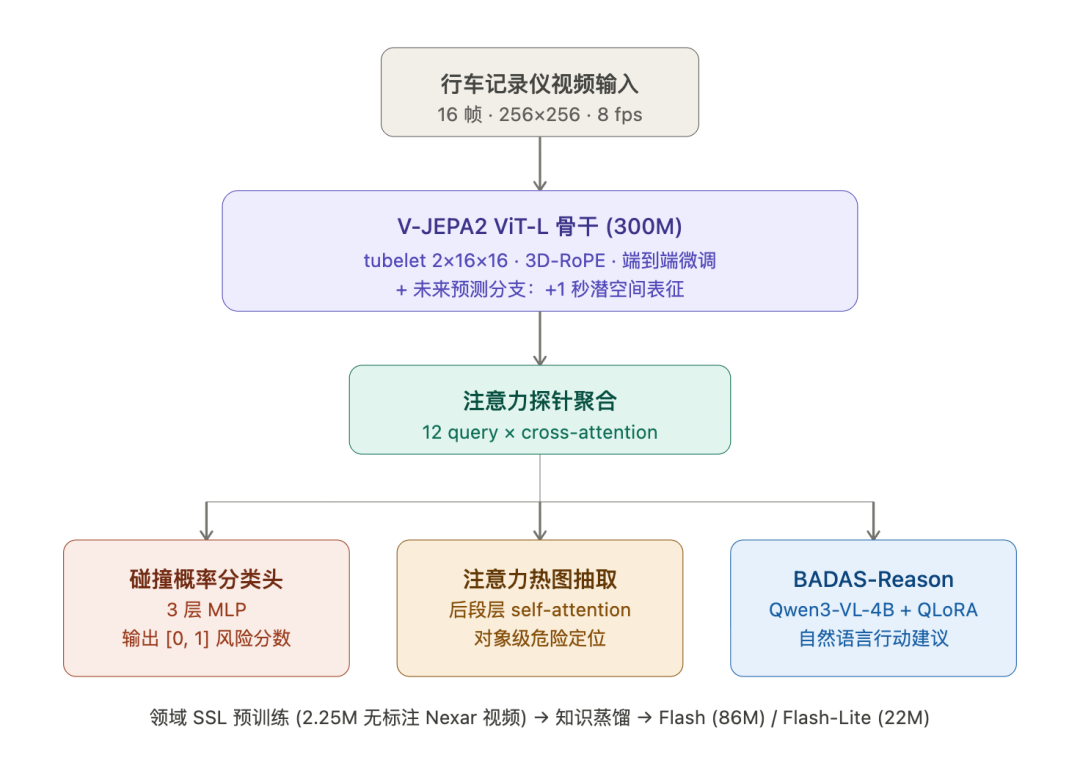
2. Physical Hardware Foundation
BADAS-2.0 is not a model that can exist independently of Nexar's infrastructure—its data sources and deployment targets are designed as an integrated system.
Sensing end: Nexar operates approximately 350,000 connected dashcams, covering 94% of U.S. roads. Each month, about 100 million miles of raw video are added, accumulating over 10 billion miles/45PB of video/60 million "edge case" videos.
This is the physical foundation for expanding BADAS-2.0's training set—the paper deployed BADAS-1.0 as an "active oracle" on this cluster to continuously score and filter high-risk clips for manual annotation, expanding from 40k to 178,500 clips (about a 2M window).
Combined with location-directed data collection from Nexar Atlas's geospatial platform (e.g., targeting accident-prone intersections), this forms a data flywheel. 
Deployment/inference end: The paper explicitly tested three types of platforms—
Cloud GPU: NVIDIA A100 (for training and benchmark evaluation)
In-vehicle/robot-grade edge: NVIDIA Jetson Thor / DRIVE AGX Thor (66 ms real-time budget @ 16 Hz)
Edge CPU: Flash-Lite can even meet real-time requirements on pure CPU
Official data shows that Flash-Lite is 12x faster than the flagship model on A100 and 5x faster on NVIDIA Thor. All three model variants fall within the hard real-time budget of 66 ms/frame—a figure corresponding to the median 1.70-second human driver reaction time, minus OS and communication link overhead.
In summary, it consists of an ordinary connected and map-based dashcam (DVR or Dash Camera) + an ordinary CPU or AI inference chip for assisted driving, plus a compute cluster for training.
3. Three-Tier Models and Performance
A key design of BADAS-2.0 is "same architecture, three-tier deployment": 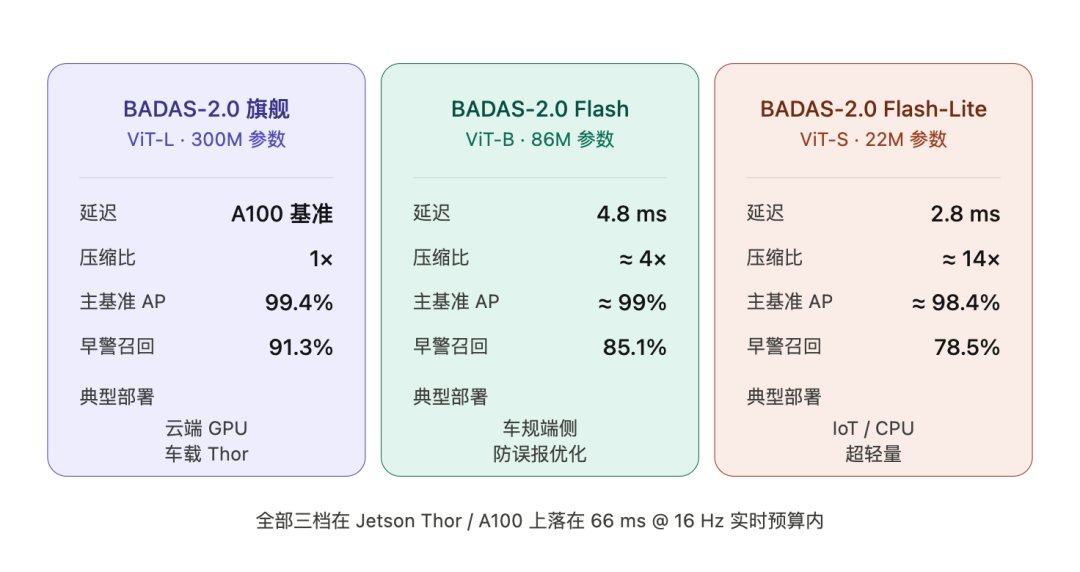
Key performance metrics (Sec. 4):
99.4% Average Precision,
Ranked first on all four mainstream benchmarks (DAD, DADA-2000, DoTA, Nexar)
Kaggle mAP improved from 0.925 in 1.0 to 0.940 in 2.0, with a 74% reduction in false positive rate (FPR)
Even when fine-tuned on the same data, BADAS-2.0 significantly outperforms NVIDIA COSMOS-Reason2 (a 2B-parameter foundational model), with the largest gaps in long-tail categories like foggy conditions and infrastructure
A key fact: The 22M Flash-Lite (91x smaller than COSMOS) still outperforms fine-tuned COSMOS-BADAS on long-tail benchmarks, providing hard evidence of the JEPA architecture's advantage over autoregressive VLMs in safety-critical prediction tasks
Below is a horizontal comparison (horizontal comparison) of AP across several benchmarks: 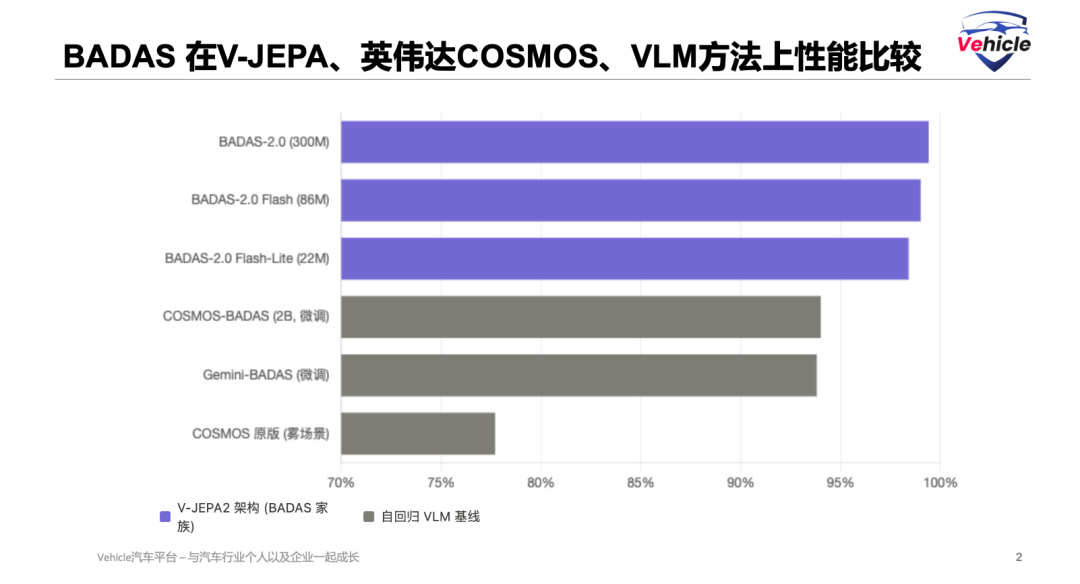
4. How V-JEPA2 Technology is Utilized for Implementation
This is the core question for understanding why BADAS-2.0 is effective. The key innovation of V-JEPA2 (Meta FAIR 2025) is a scaled-up version of Yann LeCun's Joint-Embedding Predictive Architecture (JEPA) for video—predicting occluded video representations in latent space rather than reconstructing pixels.
Specific architectural elements:
Encoder E_θ: ViT-L/H/g (300M–1B parameters), dividing videos into 2×16×16 tubelets
Predictor P_φ: A lightweight ViT-S (about 22M) predicts latent space representations of masked parts
Uses 3D-RoPE positional encoding (time + H + W)
Approximately 90% high mask ratio, L1 loss, EMA teacher to prevent representation collapse
Training data VideoMix22M = 22 million videos ≈ 1 million hours of internet video
Achieves 77.3% top-1 on Something-Something v2 (motion understanding), 39.7 R@5 on Epic-Kitchens-100 action prediction (SOTA) 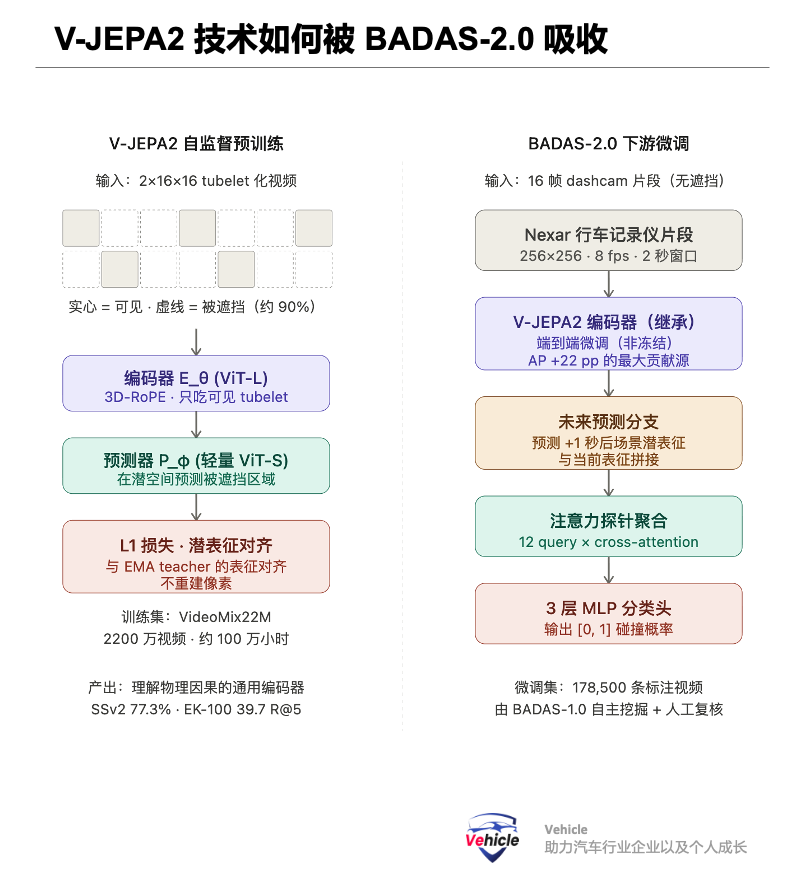
Why is pixel reconstruction unsuitable for collision prediction, while latent space prediction is suitable? Pixel reconstruction optimizes for "what the next frame looks like" (visual fidelity), while latent space prediction optimizes for "the abstract semantics/physical state of the next frame" (physical causality). Collision anticipation requires the latter—not "the reflective details of the vehicle ahead," but "whether its motion trend will intersect with the host vehicle's trajectory." This is the structural advantage of the JEPA architecture over video diffusion models (COSMOS) and autoregressive VLMs (Gemini) in safety-critical scenarios.
Specific integration in BADAS-2.0:
Backbone transfer: The ViT-L encoder (300M) from V-JEPA2 is end-to-end fine-tuned to Nexar dashcam data. Not frozen with a probe attached, but fully parameter-updated—the paper's 1.0 ablation shows that end-to-end fine-tuning boosts AP from 0.707 to 0.928, the largest single contribution
Future prediction branch: A branch is added after the encoder to predict latent space representations 1 second later, concatenated with the current representation and fed into a classification head. This is a simplified version of the V-JEPA2-AC (action-conditioned) idea—making the model explicitly "look into the future" rather than infer implicitly
Attention probe aggregation: 12 learnable query tokens perform cross-attention on a 2048-patch × 1024-dimensional representation matrix, aggregating into fixed-length scene-level features
3-layer MLP head: Outputs collision probability in [0,1]
Key points for Flash/Flash-Lite: Domain self-supervised learning (SSL) pretraining is a prerequisite for distillation. The paper's most important ablation reveals:
Randomly initialized ViT-S trained directly on BADAS supervision signals → AP near random
V-JEPA-style masked feature prediction on 2.25M unlabeled Nexar videos → +28.1 pp AP (reaching near-production quality)
Adding knowledge distillation from the ViT-L teacher → another +1.0 pp AP, while FPR drops from 20.6% to 9.1%
In other words, domain self-supervision contributes 28x, while distillation contributes 1x. Without V-JEPA-style domain SSL, small models simply cannot learn this task.
An interesting counterintuitive finding: The distilled ViT-S/B small models are even more precise in attention localization than the ViT-L flagship. The authors explain that small models align their representations to "driving-relevant regions" from the start during domain SSL, while ViT-L inherits from general video pretraining and must simultaneously adapt to representation distribution and learn collision cues, resulting in more diffuse attention. This has implications for future architectural choices.
5. Current Challenges and Constraints
From an industry researcher's perspective, BADAS-2.0's constraints are distributed across several layers:
Data layer: While long-tail categories have improved significantly, animals, extreme weather, and rare infrastructure remain the most challenging categories; the data flywheel relies on existing deployment scale—the paper itself admits that "the biggest transferable lesson is: the deployed model itself is the cheapest annotator," but this equals admitting that without the production scale of 1.0, data expansion for 2.0 would be impossible, creating a barrier for teams trying to replicate this paradigm.
Architectural layer: V-JEPA2 is an external dependency from Meta, with risks of license or roadmap shifts propagating downstream; ViT-L (300M) is still too large, forcing pure IoT cameras to choose Flash-Lite and rely on CPU/GPU hybrids, unable to run entirely on low-power NPUs.
Methodological layer: The paper explicitly contrasts with autoregressive VLM baselines (Gemini-BADAS, COSMOS-BADAS)—even when fine-tuned on the same data, they still lag BADAS-2.0 by 5+ percentage points. While this is BADAS's differential advantage, it also exposes an industry problem: there is currently no cheap and easily reusable VLM alternative paradigm. To enter this track ( track , "track" or "field"), teams must complete the entire pipeline of "large-scale real data + JEPA self-supervision + end-to-end fine-tuning + domain SSL + distillation."
Interpretability layer: BADAS-Reason relies on Qwen3-VL-4B + QLoRA fine-tuned on 8,680 human-generated descriptions. The edge-side latency and OEM compliance risks are not fully presented in the main paper's experiments; additionally, FlashAttention must be disabled (eager attention mode) to export weights for heatmaps, incurring a cost for inference optimization.
Deployment Layer: Currently, all tests are conducted on Jetson Thor and A100. The true automotive-grade functional safety certification (ISO 26262 ASIL-D), OEM vehicle integration, and arbitration logic with existing FCW/AEB pathways are still in the productization stage. The 66 ms budget is sufficient for L2+, but may be tight for L4 planning closed loops. 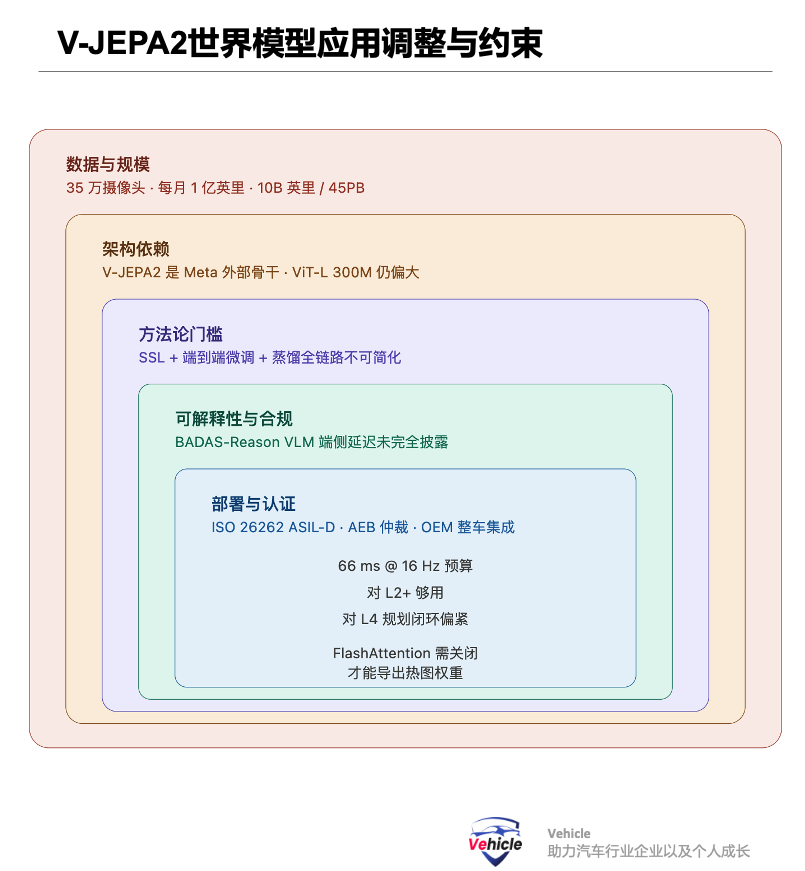
VI. Future Development Directions
Drawing from the two papers and Nexar's official roadmap, I see four evolutionary paths:
1. BADAS World – From Prediction to Simulation. The original V-JEPA2 paper includes V-JEPA2-AC (action-conditioned predictor) and an MPC-based zero-shot robotic planning branch. Nexar has already previewed the "BADAS World" approach, which follows a physics-aware driving simulation route by embedding ego action conditions into the prediction branch to form a closed loop in the JEPA world model—this is the main narrative of the LeCun-style world model.
2. BADAS-Reason v2 – Frontloading Reasoning. The current BADAS-Reason relies on post-hoc VLM explanations (generating natural language after collision probability is determined). In the future, reasoning and prediction could be merged—the original V-JEPA2 paper already demonstrated the ability to achieve 84.0 points on PerceptionTest after alignment with Llama 3.1-8B. Applying this alignment method to BADAS could produce a joint output where "reasoning is prediction."
3. Generalization of Physical AI. Nexar's official press release explicitly mentions that BADAS-2.0 can still make stable predictions in out-of-distribution (OOD) non-driving physical collision scenarios. This implies that the paradigm of "JEPA architecture + large-scale real-world edge data + distillation" can be transferred to safety-critical fields such as industrial safety, warehousing and logistics, and medical robots, rather than being limited to autonomous driving.
4. OEM Pre-installation. The latency performance of 2.0 Flash and Flash-Lite makes it possible for the first time for a "perception model trained on real collision corpora" to be integrated into mass-produced vehicle ECUs (the previous 1.0's 2.5 s/window was unacceptable). Nexar has already formed a partnership network with Waymo, Lyft, IBM, NVIDIA, and others. The next question is whether it can enter the Tier-1 supply chain. 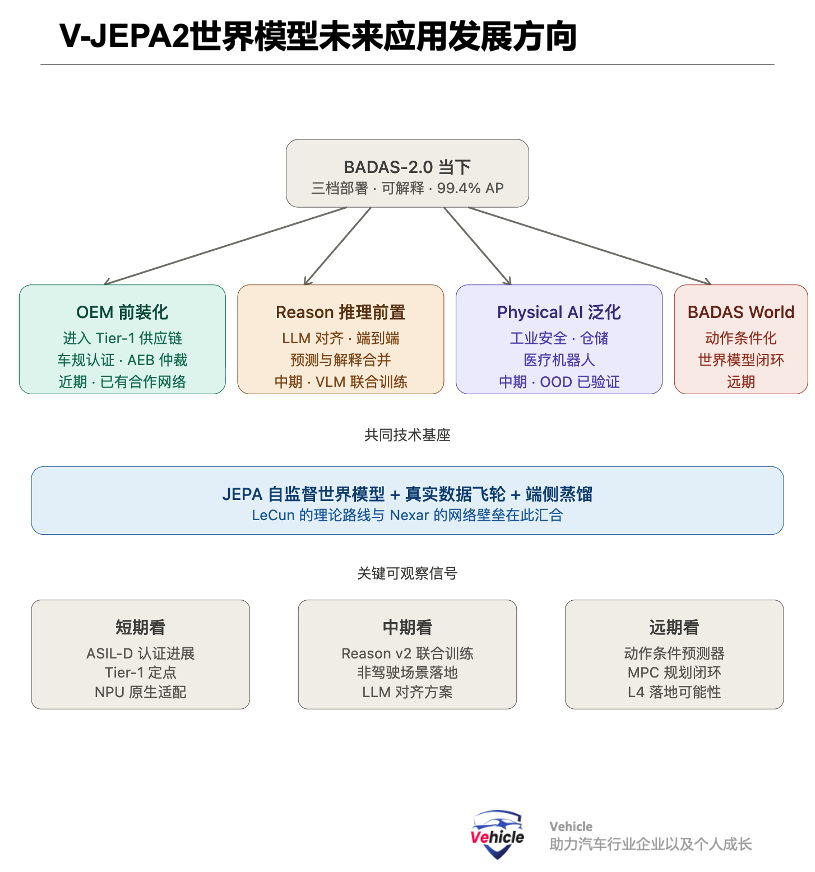
Summary
From the perspective of an industry researcher, here is a summary:
The true technological significance of BADAS-2.0 lies not in "a more accurate forward collision warning," but in its first empirical demonstration at production scale of a complete paradigm:
"JEPA self-supervised world model backbone + large-scale real-world edge data flywheel + domain-specific SSL + end-to-end fine-tuning + distillation to the edge."
It can outperform both "larger-parameter VLM foundation models" and "more mature industrial ADAS" in safety-critical prediction tasks.
This path combines LeCun's JEPA theoretical approach with data network barriers and is highly likely to become a universal technical template for future Physical AI in safety-critical systems (driving, robotics, healthcare, industrial).
References and Images
Beyond the Beep: Scalable Collision Anticipation and Real-Time Explainability with BADAS-2.0.
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
*Reproduction or excerpting without permission is strictly prohibited.-
-
Ofilm Teams Up with ADSensE to Propel Large-Scale Deployment of All-Solid-State LiDAR Powered by ADS6311 Chip!
-
![]()
Loss of 2.5 Billion Yet Facing Strong Demand for Shares? Another Battle for Control of Lianchuang Electronics
-
![]()
Huawei’s Enjoy Series Flies Off the Shelves, Prompting Xiaomi to Double Down on Budget Smartphones
-
![]()
Beijing Hyundai's Top Executive Criticizes Industry Disorder: Certain Brands Treat Customers as Beta Testers
-
![]()
The domestic mobile phone market has declined for five consecutive quarters! Huawei defies the trend with significant growth: maintains its top market share
-
Annual Revenue Surpasses 3 Billion: An Automotive Trim 'Little Giant' Makes Its Debut on the Beijing Stock Exchange
-
![]()
The Space Force Wants to Spend $30 Billion on Rocket Launches: Is Trump Doubling Down, and Is SpaceX the Big Winner?
-
![]()
Going Crazy! One out of Every Three Plug-in Hybrids Sold in Europe is a Chinese Vehicle





