Will BEV and Transformer Persist in the End-to-End Era of Autonomous Driving?
 04/23 2026
04/23 2026
 371
371
When delving into autonomous driving technology, a common misconception arises: many believe that end-to-end represents an isolated innovation set to entirely supplant BEV (Bird's Eye View) or Transformer. Some have even inquired via comments whether end-to-end models will continue to incorporate BEV+Transformer.
In reality, end-to-end technology does not seek to overthrow existing perception architectures. Instead, it aims to integrate previously disparate modules into a comprehensive neural network in a more efficient and logical manner. BEV and Transformer remain the cornerstone components of this system, albeit with transformed operational methodologies.
Why Spatial Perception Remains Central
The fundamental prerequisite for autonomous driving is for the vehicle to possess precise knowledge of its location and surroundings. While end-to-end models can directly output driving trajectories, without an internally established accurate spatial model, the system's actions would become erratic and illogical.
The core value of BEV technology lies in providing a unified spatial framework. It projects real-time image data collected by multiple cameras positioned around the vehicle into a top-down perspective. From this vantage point, the distances between objects, lane directions, and intersection layouts become as intuitive as when humans view a map.
In current end-to-end solutions, BEV transcends its role as a mere visually appealing perception display for engineers. Its true function is as a feature container. When data from multiple cameras floods into the model, the system overlays features within this unified spatial plane.
This methodology resolves issues of overlapping or obstructed camera views, enabling the model to maintain a coherent spatial memory when navigating scenarios like high-curvature bends or complex urban intersections. Without this spatial perspective, end-to-end models would struggle to decipher chaotic pixels and exhibit stable driving decision-making capabilities.
How Transformer Connects Spatial and Temporal Information
If BEV serves as the stage, then Transformer acts as the chief director, responsible for determining which information to retain and prioritize. Within end-to-end models, Transformer's attention mechanism addresses a critical perception challenge: correlating information from disparate locations and times.
Through this mechanism, the model can autonomously discern which visual features are most pertinent to the current driving task. For instance, when approaching a traffic light intersection, it automatically assigns weights to the traffic signals ahead and pedestrians to the side, rather than irrelevant trees along the roadside.
More crucially, current end-to-end models heavily rely on Transformer to process time-series data. Driving is a continuous process, not a static moment. Transformer can concatenate feature information from the past few seconds, akin to human short-term memory. This endows the model with predictive capabilities, enabling it to infer the approximate position and speed of a cyclist obscured by a parked bus based on previous observations. This profound integration of spatial-temporal information empowers end-to-end models to react more sensitively and naturally than pure rule-based algorithms in extreme scenarios like "ghost probes."
How Components Within the Neural Network Communicate
Traditional autonomous driving architectures resemble an assembly line, where perception feeds into prediction, which in turn feeds into planning and control. Each stage translates data into human-readable formats, such as coordinates and speed values of target objects. However, in end-to-end models, this communication becomes more streamlined. Features generated by BEV and Transformer are directly passed downstream in the form of high-dimensional vectors. The greatest advantage of this approach lies in minimizing information loss.
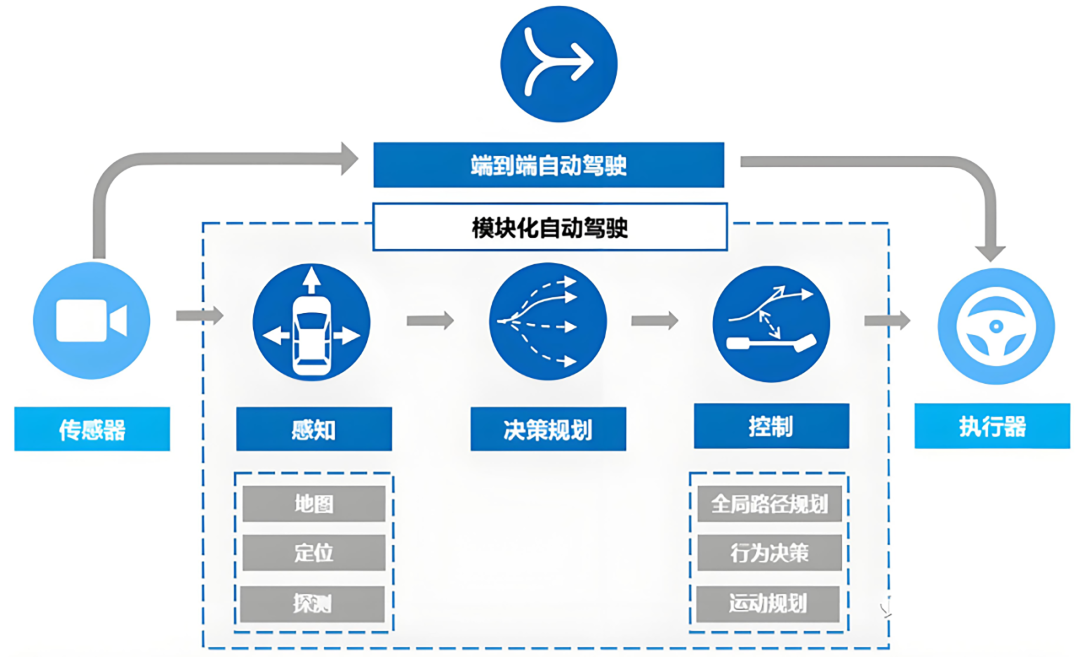
Image source: Internet
In the past, misidentifying an irregular object as a utility pole might lead subsequent planning modules to execute erroneous avoidance maneuvers based on this incorrect label. However, in end-to-end systems, even if the model cannot name the object, it can perceive through Transformer that the features at that location are impassable and directly calculate a detour curve.
This direct mapping from raw features to driving behavior eliminates the need for cumbersome manually defined rules, enabling the vehicle to handle various peculiar road conditions more akin to an experienced driver than a robot adhering strictly to instructions.
How Will Future Models Evolve?
Although current end-to-end models heavily rely on BEV and Transformer, this combination is in a constant state of evolution. The prevailing trend is to imbue models with a stronger sense of the world. Many technical solutions are experimenting with incorporating ideas from Occupancy Networks, shifting the focus from specific objects to whether each volumetric unit in space is occupied. This approach enhances the robustness of end-to-end models when dealing with irregular obstacles like construction zones and debris.
Furthermore, with the proliferation of multimodal large models, end-to-end architectures are beginning to assimilate experiences from language and visual large models. Future systems may not only "see" the road but also comprehend implicit traffic logic through architectures akin to Transformer, such as recognizing gestures from traffic police officers by the roadside or interpreting the intentions behind sudden decelerations of vehicles ahead.
Therefore, BEV and Transformer will not vanish; instead, they are evolving from standalone plugins into indispensable neurons within the system's neural network under the end-to-end trend, collectively propelling autonomous driving towards greater intelligence.
-- END --
-
How Meituan is Becoming the 'Interface' for AI Integration into the Physical World
-
![]()
RoboScience Machine Science Makes ICRA Best Paper List for Two Years Running with Its 'Embodied Brain' Innovation
-
![]()
Focusing on UTG Ultra-Thin Flexible Glass! CSG Optical New Material Production Base Establishes in Xianning, Hubei
-
![]()
AI Meets Optics: Tsinghua Smart Vision Secures A+ Round Funding Led by Hillhouse Capital
-
![]()
Why are 3C Brands Flocking to Douyin Mall During 618?
-
![]()
Token Economy Falters as Economic Tokenization Faces Challenges
-
![]()
Lenovo's Monthly Surge of 109%, Foxconn Industrial Internet's Market Cap Surpasses Kweichow Moutai: A Collective Resurgence of the 'IT Old Guard'?
-
![]()
After Zhang Xue's Victory, Where is Motorcycle Intelligence Headed?






