Is "100 Seconds of Thinking Time" Becoming a Relic? AI Reasoning Too Slow, Berkeley Pioneers Parallel Model Reasoning
 05/11 2026
05/11 2026
 608
608
Let AI harness its unique thinking capabilities.
Does the message "Already thinking (took XXX seconds)..." leave you feeling restless? While AI has indeed grown smarter and more versatile in recent years, when confronted with certain intricate reasoning tasks or complex multi-app operations, these smarter and more cautious AI large models often respond even more sluggishly.
(Image source: deepseek)
In response to the "waiting in circles" phenomenon, the Berkeley Artificial Intelligence Research Lab (BAIR) recently published a blog post proposing a novel solution—Adaptive Parallel Reasoning (APR).
Why Does AI Reasoning "Go in Circles"?
Before delving into APR, it's crucial to understand why current AI models frequently encounter bottlenecks.
Currently, mainstream models predominantly adopt a "sequential reasoning" approach: when a large model receives a complex task, it first dissects the task into smaller, logically interconnected subtasks, processes them sequentially from start to finish, and finally verifies the results.
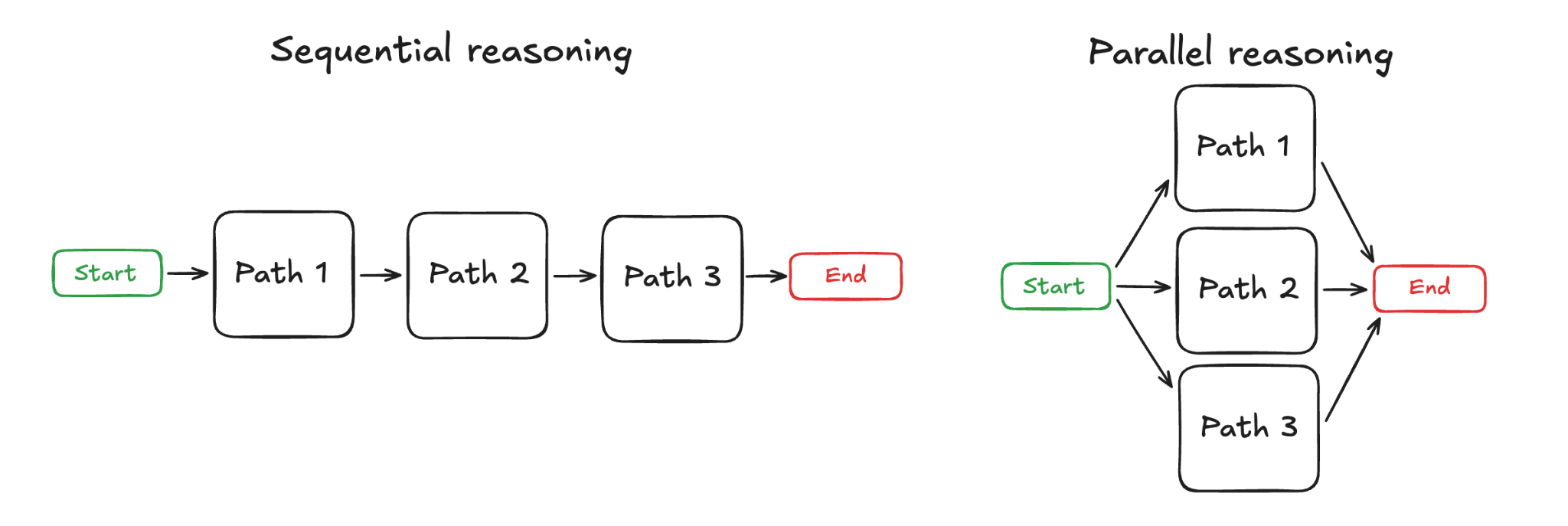
Left: Sequential Reasoning (SR), Right: Parallel Reasoning (APR) Image source: BAIR
On the plus side, this reasoning method ensures relatively reliable accuracy and a transparent reasoning process. For instance, last month, when Leikeji utilized ChatGPT to create an original comic, by expanding the reasoning window, we could observe the AI's step-by-step process of designing the story, dialogues, and visual planning.
Image source: Leikeji
However, to ensure reasoning accuracy, mainstream models also employ "inference-time scaling." In simpler terms, after the model derives a result through reasoning, it initiates another round of reasoning to validate that result. Only when multiple reasoning outcomes align is the final result output.
Evidently, the more "verification" rounds there are, the longer the reasoning process takes, and consequently, the longer users must wait.
Of course, sequential reasoning has its merits. For particularly complex reasoning tasks, it ensures traceability of reasoning results. By reviewing the reasoning process, we can manually inspect each step's results and relatively easily pinpoint where the AI erred in its calculations.
So, what's the trade-off?
Clearly, the "sequential reasoning + inference-time scaling" approach necessitates longer reasoning times, leading to extended user wait times. The method of progressively breaking down tasks and then re-reasoning also significantly increases token usage for model reasoning. Not to mention that this computational model can easily surpass the actual text window size of the task, and running the task multiple times may result in context loss.
What was intended to enhance reasoning results has inadvertently become the primary cause of overwhelming AI large models.
To address the "reasoning queue" issue, the AI industry has proposed a "parallel reasoning" approach. Essentially, this still involves dissecting reasoning steps into multiple smaller tasks. Over the past two years, many AI researchers have proposed methods for verifying results in parallel reasoning models.
However, the challenge lies in the fact that AI large models employing "parallel reasoning" typically rely on additional external models to break down tasks. The large model itself cannot determine the optimal granularity for task breakdown: overly fine breakdowns of simple tasks waste tokens, while insufficient breakdowns of complex tasks may lead to computational errors.
Empowering Large Models to Learn Task Breakdown Independently
What if we allow AI large models to decide the extent of task breakdown themselves? This is precisely what Adaptive Parallel Reasoning aims to achieve.
As the name suggests, the key distinction between Adaptive Parallel Reasoning (APR) and traditional parallel reasoning is that the model can dynamically and freely switch between sequential and parallel reasoning modes.
For straightforward computational or logical requests, such as "Can 105 be divided by 7?" or "What's the weather tomorrow?", a model using APR will adopt the standard sequential reasoning mode and may not even require inference-time scaling to ensure result accuracy, thus eliminating the need to break down the request into multiple independent items.
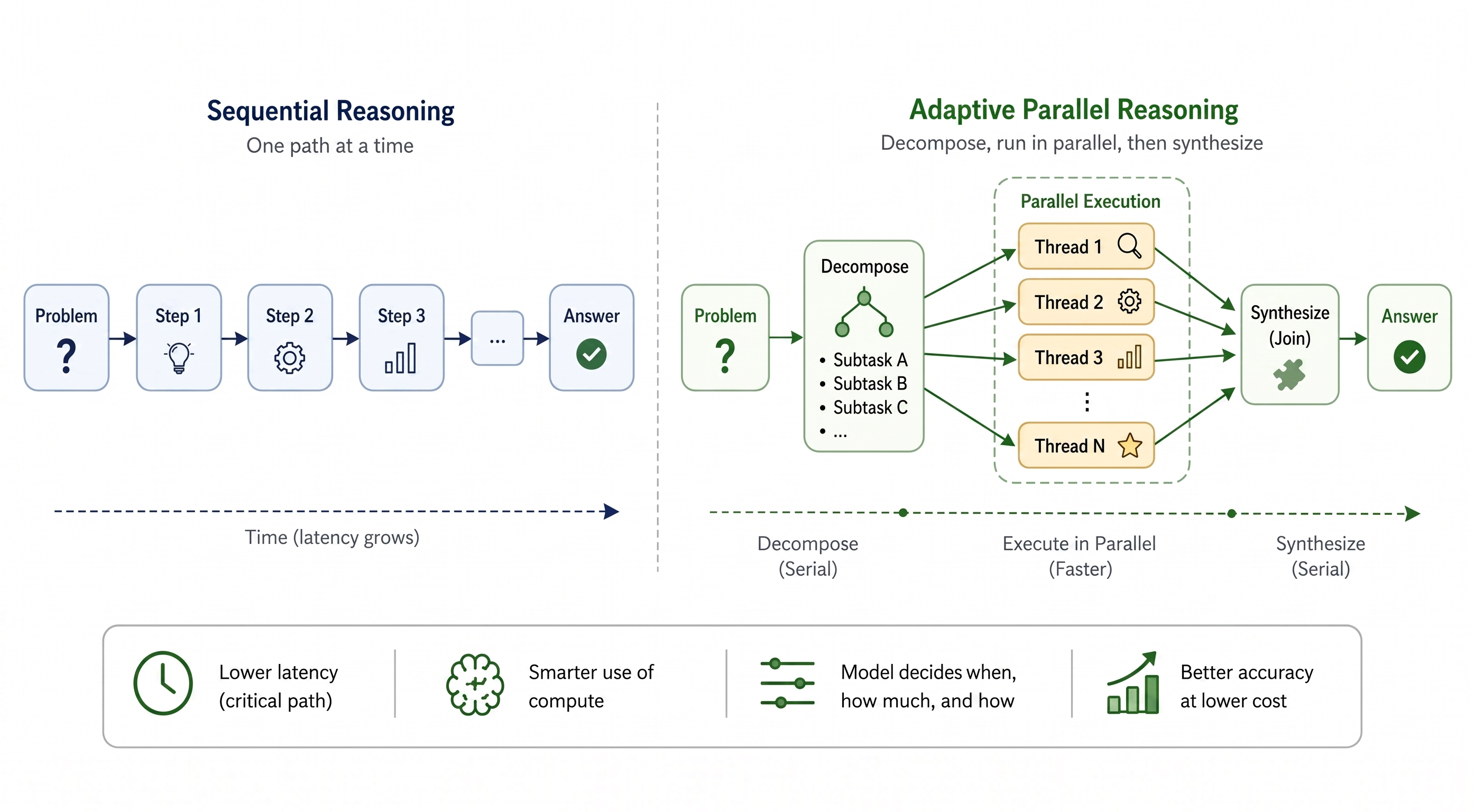
Left: Sequential Reasoning (SR), Right: Adaptive Parallel Reasoning (APR) Image source: BAIR
However, when faced with complex mathematical reasoning or logical requests with clear step-by-step or contextual relationships, such as the task "Import and analyze Hamilton's terminal speed at T14 during the 2026 F1 Chinese Grand Prix qualifying session, and compare it with 2025 data, outputting the results in a visualized format":
A model using APR will, without exceeding a single contextual window, break down the entire task into multiple independent smaller tasks and "process them in parallel" (i.e., handle tasks without contextual relationships simultaneously), thereby saving time for the overall large task.
Secondly, traditional parallel reasoning often involves having several AI models repeatedly process the same small task, which essentially wastes tokens. In contrast, APR allows the AI to assign tasks before breakdown, further reducing token waste.
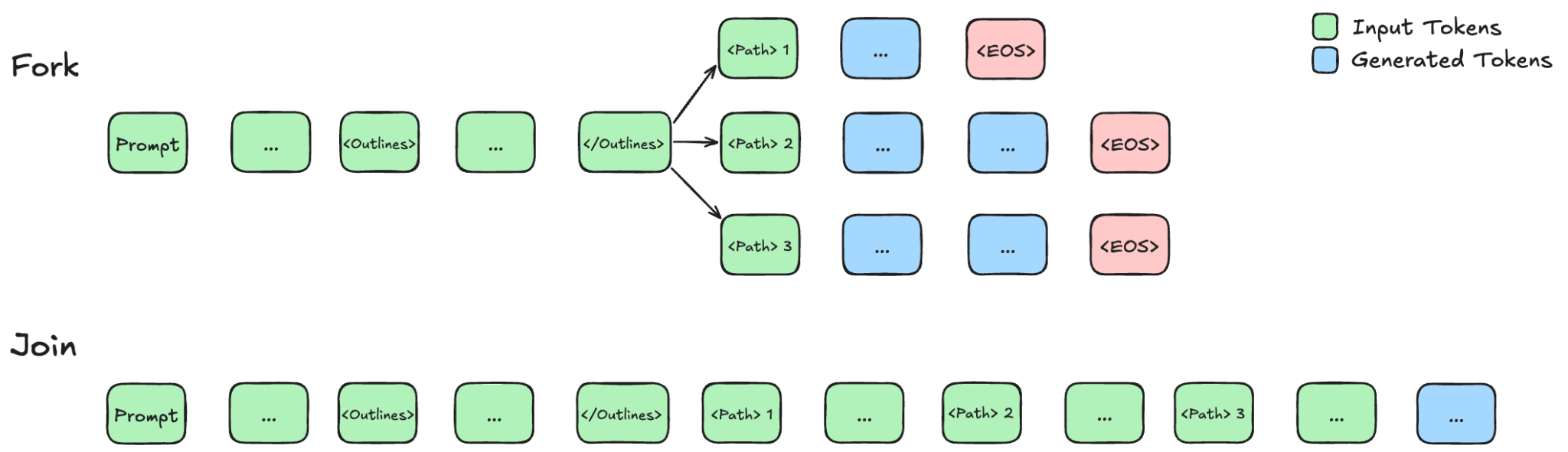
Schematic of Two Different Reasoning Modes Image source: BAIR
Moreover, because APR breaks down the task chain into independent smaller tasks, this mode also cleverly avoids the common AI hallucination issues associated with excessively long text windows. This is understandable—after all, having six people each spend four hours on a math problem will likely yield a higher accuracy rate than having one person work for 24 hours straight.
Enabling AI to "Think in Parallel" Like Machines
That said, while the concept of APR offers a new working mode for AI large models, it also comes with its own set of risks.
The author of the parallel reasoning training framework Parallel-R1 has pointed out that training in APR mode can lead to "model rollback": just like real "workers," if the "rewards" for APR mode are removed, the AI model will revert to the traditional sequential reasoning mode and return to its "comfort zone."
Additionally, allowing the model to assess task complexity and break down tasks independently may lead to the model misjudging the priority of subtasks, overlooking genuine reasoning challenges, and getting bogged down in minor details. Furthermore, for a technology like AI models that involves "probability" and "randomness," introducing more elements of AI "subjective judgment" during reasoning will inevitably affect the stability of the final results.
It is certain that as a new approach to AI reasoning, APR still requires time to be refined.
Image source: Claude
However, from a user perspective, in the era of AI Agents, the days of AI dialogue scenarios that are purely for "chitchat" are becoming increasingly rare. Yesterday, Claude introduced interoperability with Microsoft 365; in March, OpenAI released ChatGPT 5.4, which can natively operate computers... Undoubtedly, the ability to handle cross-application long task chains will be a competitive edge for future AI.
Coupled with the fact that the "interconnected" nature of long task chains will also amplify the efficiency shortcomings of AI large model reasoning, the situation where, as teachers used to say, "one person delays for a minute, and the whole class delays for half an hour" will now occur in AI Agents. In this context, although the APR approach is still unstable, considering its ability to "reduce costs and increase efficiency," Leikeji believes that more and more AI services will adopt APR.
Furthermore, from the perspective of AI development, Leikeji views this shift from sequential to adaptive parallel thinking as a milestone in the transition of AI large models from "simulating human thinking" to "leveraging machine strengths."
Linear, sequential reasoning essentially involves machines simulating human thought processes. On the positive side, this reasoning method endows AI large models with the rigorous, step-by-step characteristics of human thinking. However, the multi-threaded nature of silicon chips makes them inherently suited for parallel computing. This fundamental architectural difference means that "parallel thinking" is the truly suitable thinking mode for AI.
Having AI think in a human-like manner is akin to having a humanoid robot pull a rickshaw; only when AI thinks in an AI-like manner can it truly enter the "mechanical era."
It is certain that once this "non-linear" thinking mode becomes mainstream, the interaction patterns of AI Agents will also change accordingly. Currently, to prove that it is thinking, AI displays the reasoning process, remaining confined to the "text window" limitation. However, in the era of "parallel" computing, AI will inevitably become more "black-box"—reasoning "at full throttle" in the background while directly outputting results in the foreground.
By then, AI will no longer need to prove to users that it is "thinking"; meaningless prompts like "already thinking for XXX seconds" will completely disappear in the AI era.
Parallel Thinking Theory for Large Model AI Reasoning
Source: Leikeji
All images in this article are from the 123RF licensed image library.
-
![]()
Tesla Restructures Its Balance Sheet
-
![]()
Accelerating the High-Speed Interconnection Upgrade of AI Computing Clusters! JONHON Releases ELSFP External Light Source Optical Connectors
-
![]()
Breaking the overseas blockade of volumetric holographic materials, this optical enterprise secures nearly 100 million yuan in financing!
-
![]()
Why Does Jensen Huang So Openly Praise China’s AI?
-
![]()
"Wudang" Unveiled: Arm China's Next-Gen AI VPU Redefines Video Encoding
-
![]()
From Energy Conservation and Carbon Reduction to AI Decision-Making: GECON East Intelligence and Chery Group Explore a New Green and Smart Paradigm for Automobile Manufacturing
-
![]()
WAIC 2026 Observation | AI Accelerates Towards the Core of Industries, Industrial AI Enters a Critical Phase
-
![]()
Volkswagen China Fires the First Shot in Foreign-Funded 'White Box Delivery'!







