The Computational Power Dilemma in the Sino-US AI Rivalry | WAVE
 06/23 2026
06/23 2026
 328
328
Editor|Yang Xuran
As the world of AI large models evolves along the Scaling Law, Chinese large models are constrained by a shortage of high-end chips.
A group of 'OpenAI defectors,' led by Ray Dalio, have built Anthropic into a global leader in large models with a valuation reaching $1 trillion. The company's Opus 4.6 has become a performance benchmark for large models.
Its latest model, Mythos, was not directly released to the public due to its 'overwhelmingly powerful performance.' With a scale of 10 trillion parameters and a training dataset of 300 trillion tokens, its estimated training cost reached $10 billion.
The U.S. government even suspended access to this model for all foreign citizens on 'national security' grounds.
Currently, China's strongest model, DeepSeek V4 Pro, has a total of 1.6 trillion parameters, about six times less than its U.S. counterparts with ten-trillion-scale products. Research suggests that DeepSeek V4 Pro lags about eight months behind the U.S. frontier.
'A day in AI is like a year in the real world.' The root of this generational gap lies in the lack of high-end computational power.
Despite international figures like Jensen Huang and Elon Musk heaping praise on Chinese AI, the scarcity of high-end computational power, especially AI training chips, remains a deep chasm that has long persisted in the Sino-US AI competition.
U.S. tech giants, relying on massive capital expenditures, vast clusters of top-tier GPUs, and abundant per-capita token allocations, are fighting a wealthy battle. Meta alone possesses more GPU computational power than all Chinese AI companies combined, and U.S. tech giants' AI expenditures are astronomical.
Against the backdrop of exponential growth in computational power demand and soaring hardware procurement costs for storage chips, domestic large models like DeepSeek can only reduce costs through model distillation, triggering a new round of Sino-US rivalry.
With high-end AI chip imports blocked and market demand surging, finding a more feasible development path before domestic substitution can meet demand is an urgent question for the entire Chinese AI industry.
This is a deep-dive value article from the WAVE content team. Follow us on multiple platforms.

Computational Power Constraints
Since late last year, domestic GPU companies like Moore Threads, MetaX, Biren Technology, and Iluvatar CoreX have sparked a capital frenzy. However, beneath the secondary market wealth feast, an undeniable and increasingly urgent dark line is emerging.
Over the past few years, domestic AI chips have mainly focused on the relatively safe and peripheral 'inference side.' For example, Doubao recently planned to purchase 50,000 chips from Iluvatar CoreX for inference tasks to meet the high-frequency demands of China's largest AI app terminal.
In contrast, at the pinnacle of the AI training computational power pyramid, domestic chips can only handle peripheral 'support' tasks.
AI training chips are primarily used for training AI models, involving massive matrix operations and parameter adjustments, requiring strong computational capabilities and high energy efficiency. They are more powerful and expensive, such as NVIDIA's A100, H100, H200, and AMD's MI300 series.
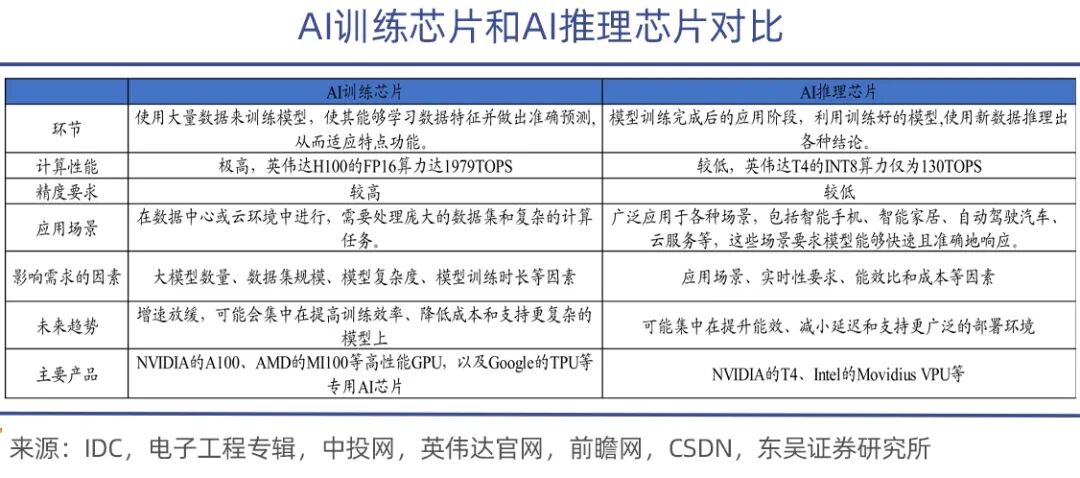
In comparison, inference chips have a much lighter task load. Used in the deployment stage after model training, they primarily execute inference tasks, requiring high real-time performance, rapid response, and low power consumption while ensuring accuracy.
A fitting metaphor is that training teaches AI models to 'acquire knowledge,' while inference lets large models 'apply knowledge.' During the learning phase, training chips process vast amounts of data to 'feed' dynamic updates of billion-, trillion-, or even ten-trillion-scale parameters, requiring not only formidable computational power but also efficient bandwidth and communication capabilities, as well as stability in clusters of tens of thousands of cards.
The root of the Sino-US model gap lies in these 'invisible areas,' especially the absence of high-end training chips.
Under the Scaling Law for large models, larger model parameters lead to a corresponding linear increase in computational power demand, while exponentially inflating computational and hardware costs make training large models a 'private game' for a few tech giants.
Among U.S. tech giants, Meta alone plans to deploy over 1.2 million high-end GPUs by the end of 2026, with annual investments exceeding $145 billion. By some estimates, Google's total AI computational power is equivalent to 5 million NVIDIA H100s, accounting for a quarter of the global total.
Amazon, Microsoft, Alphabet, and Meta's combined capital expenditures this year reached $725 billion, a 77% year-on-year surge, equivalent to 13% of U.S. annual private domestic total investment. Morgan Stanley predicts that U.S. tech companies' capital expenditures could reach a record $1.1 trillion by 2027.
Currently, the U.S. controls over 70% of the global high-end GPU market, leaving China with only 1/8th of the available high-end chips after the chip ban. The Stanford AI Index Report 2026 notes that the U.S. has over 5,427 data centers, more than ten times China's total.
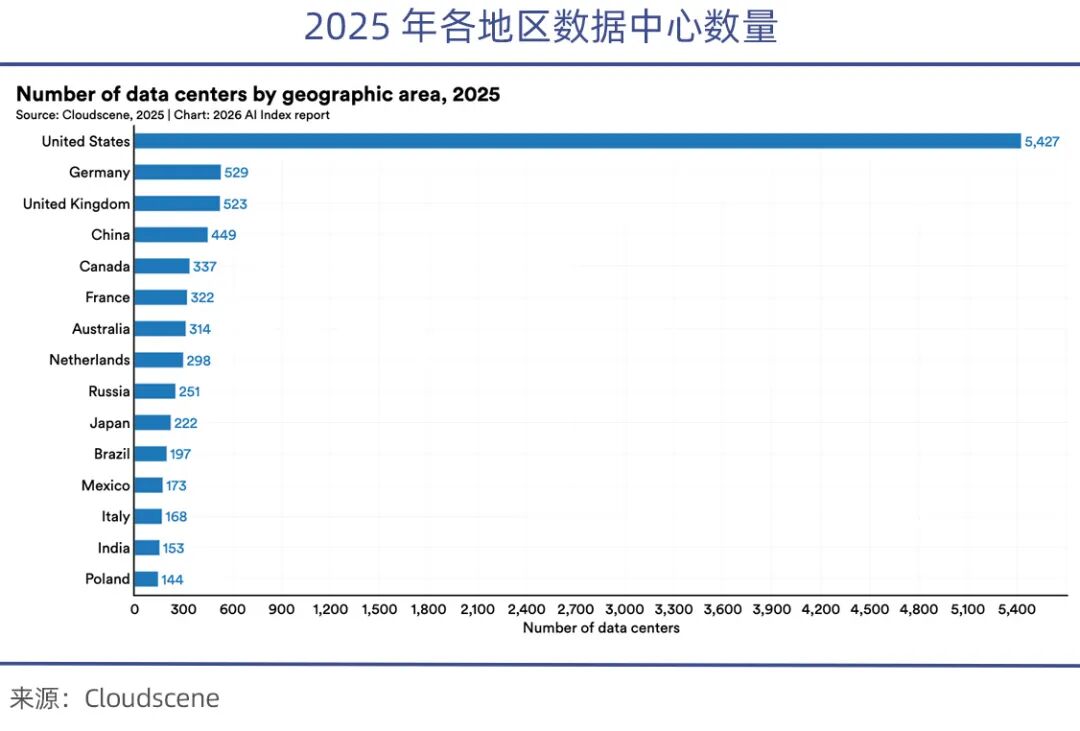
According to the China Academy of Information and Communications Technology (CAICT), as of early 2025, the U.S. computational power scale reached 2,400 EFLOPS, more than double China's 1,053 EFLOPS.
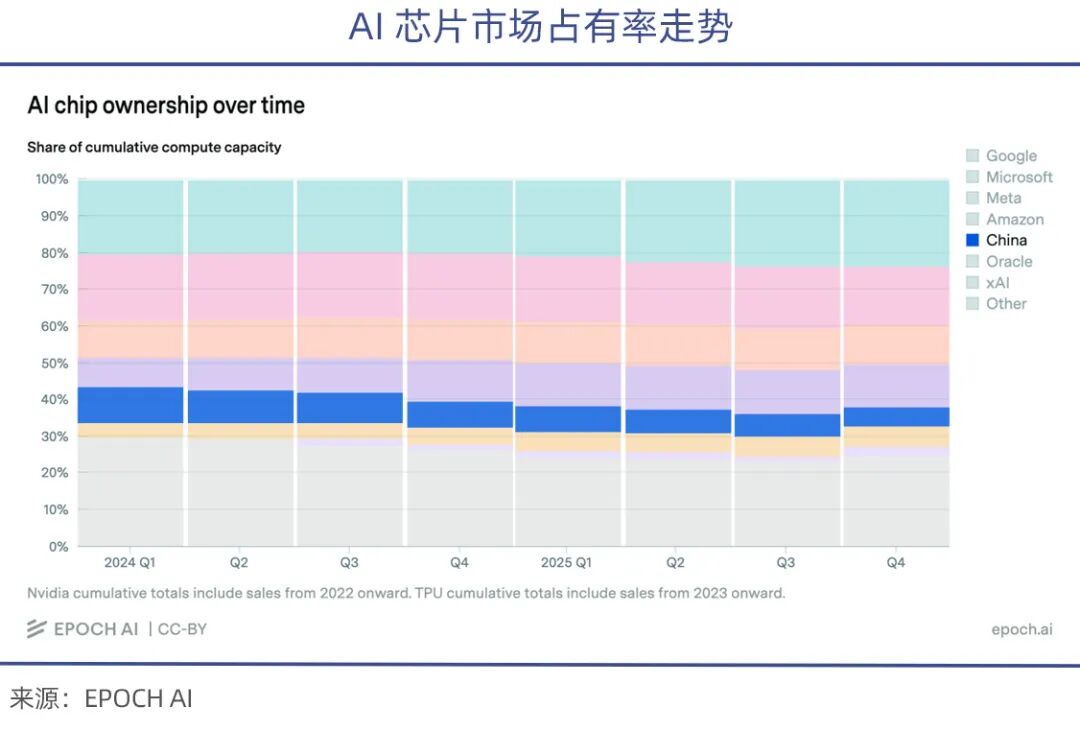
The computational power scale of each of these four U.S. tech giants alone already exceeds the combined total of all Chinese AI companies.
This overwhelming computational power advantage allows U.S. companies to complete dozens of large model iteration experiments in a year.
Musk is even more extravagant, with his xAI boasting Colossus 2, dubbed the world's 'first GW-scale AI cluster.' He claims to be training seven models simultaneously—two with 1 trillion parameters, two with 1.5 trillion, one with 6 trillion, and one with 10 trillion. This 'brute-force aesthetics' is only possible with extreme computational abundance.

Meanwhile, due to U.S. chip export restrictions, China's share of high-end AI chips shipped in recent years has continued to decline (according to epoch.AI statistics).
It is no exaggeration to say that the vast gap in computational power infrastructure will keep Chinese AI in a catch-up phase for the long term, making it even harder for domestic large models to match their U.S. counterparts.

Generational Gap
'China's pace of innovation is unstoppable.' 'Anyone who thinks China can't make chips is mistaken. The Sino-US gap is only at the nanosecond level.'
NVIDIA founder Jensen Huang has repeatedly praised China's semiconductor progress in public.

Musk often expresses similar views on X, stating that 'China will solve the chip bottleneck and dominate global AI computational power' and that 'China will win the AI race on Earth.'
Lavish praise from tech titans can easily be taken at face value, but these remarks seem to border on flattery. Some U.S. media outlets continually promote the narrative that the Sino-US model gap is minimal, attempting to obscure objective truths.
In response, China's AI community should remain clear-headed and calm.
While China's advanced large models now perform comparably to U.S. rivals in solving standardized problems, the gap becomes more pronounced in complex industrial and enterprise environments.
Compared to frontier models from U.S. companies like Anthropic, China remains a follower. The U.S. CAISI assessment suggests that China's strongest model, DeepSeek V4 Pro, lags about eight months behind the U.S. frontier.
Li Kaifu recently noted in a Wall Street Journal interview that, using U.S. top models like Anthropic's Claude Fable 5 as benchmarks, the U.S. currently leads China by about 15 months.

Large models follow the Scaling Law: larger model parameters, more training data, and greater computational power input lead to better model performance. Today, the most advanced U.S. large models have entered the ten-trillion-parameter era, with iteration speeds accelerating.
Anthropic's most powerful model, Mythos, has 10 trillion parameters and cost $10 billion to train. xAI's Colossus 2 is simultaneously training seven models, including 6-trillion and 10-trillion-parameter models. OpenAI can iterate a 4-trillion-parameter model in just one month.
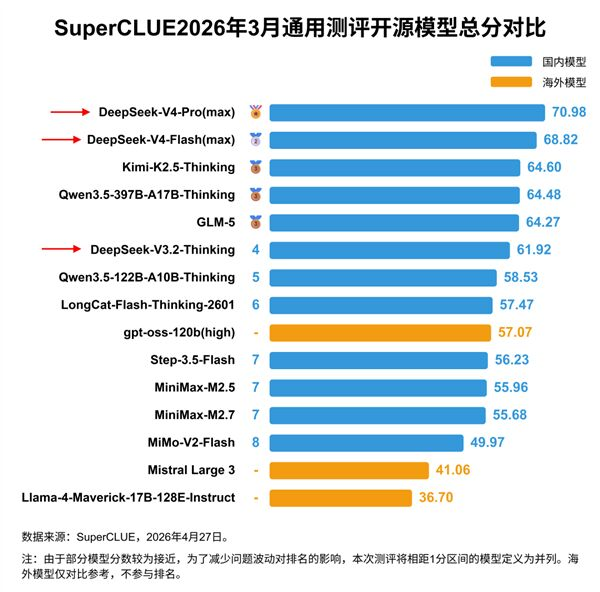
China's strongest model, DeepSeek V4 Pro, has 1.6 trillion parameters, about six times less than its U.S. ten-trillion-scale counterparts.
Anthropic's Claude series is widely regarded as the strongest AI programming large model in recent years, and Mythos has once again shattered public expectations, outperforming its previous flagship, Opus 4.6.
OpenBSD is renowned in the industry for having the most secure system, yet Mythos discovered a vulnerability unnoticed for 27 years. It also found flaws in FFmpeg and the Linux kernel that had gone undetected for years or even decades, all autonomously without human reliance.
It is important to note that 'pre-training' in large models determines the upper limit of model capabilities and cannot be elevated to the level of a 10-trillion-parameter model through 'post-training' adjustments of a trillion-parameter model. The decisive factor in pre-training is high-end computational power chips, which determine parameter scale and training iteration speed.
iFLYTEK Chairman Liu Qingfeng admitted that leading large model vendors, especially U.S. giants, are building ultra-large-scale computational power platforms. Domestic computational power is currently facing growing pains, limiting training in ultra-long text contexts.
Thus, the computational power gap is the root cause of the Sino-US model disparity.

Domestic Rise
One company monopolizes 90% of the global high-end AI training chip market—this has helped NVIDIA maintain its crown as the world's most valuable company. Its market capitalization once exceeded Germany's 2025 GDP, the world's third-largest economy.
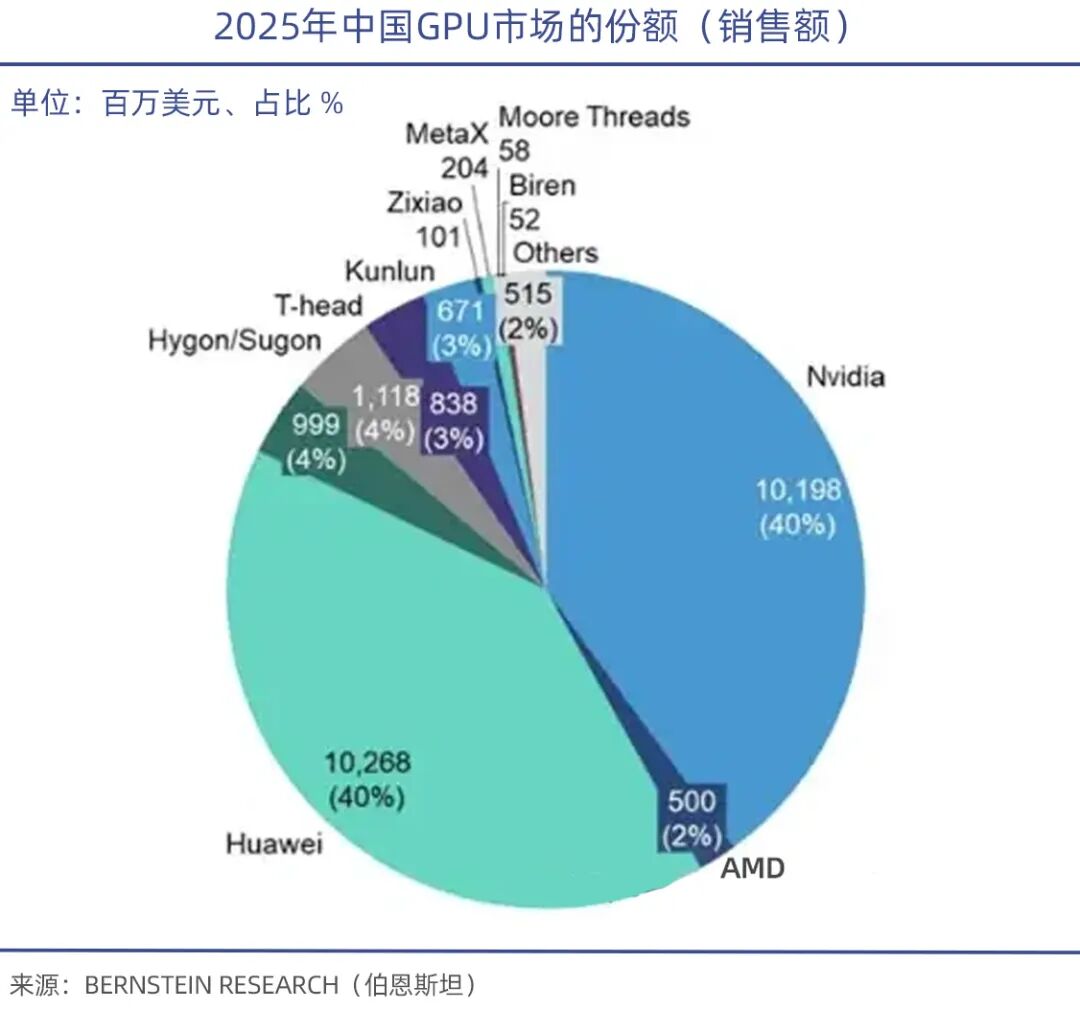
TrendForce data shows that in Q1 2026, NVIDIA captured 68% of the global GPU server market, AMD held 5-6%, while domestic GPU vendors accounted for less than 4% collectively.
With first-mover advantages, formidable technical barriers, high-speed interconnectivity, software ecosystems, and bind to TSMC's advanced manufacturing processes, NVIDIA dominates the market. In high-end training scenarios, NVIDIA's GB300 outperforms AMD's MI325, Cambricon's MLU690, and Moore Threads' MTT40, especially in training trillion-parameter large models, where it outperforms competitors by over 30%.
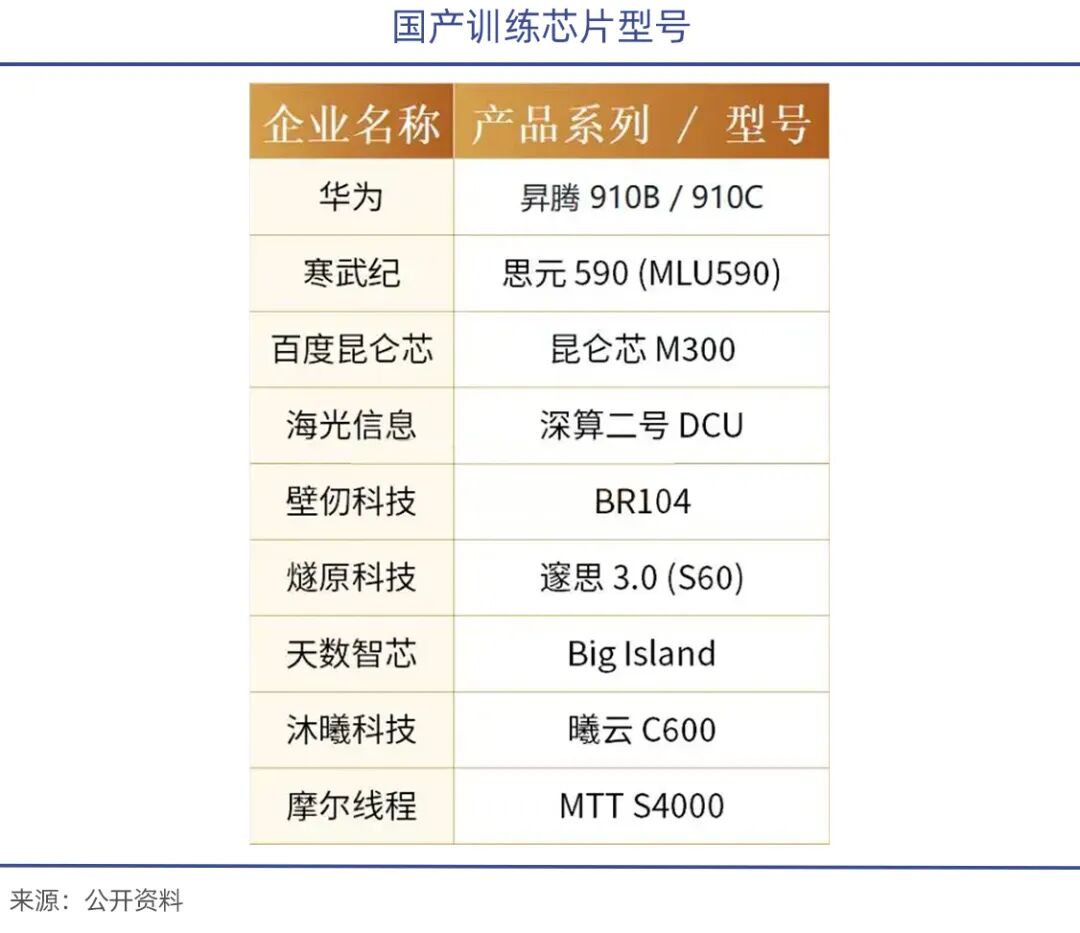
Under export bans, Jensen Huang previously stated that NVIDIA's market share (new additions) in China has effectively dropped to zero, leaving only the existing market. Supported by domestic substitution policies, companies like Huawei's Ascend 910, Hygon DCU ShenSuan 2, Cambricon's MLU370/590, and Moore Threads and MetaX have emerged.
Among them, Ascend 910 is Huawei's most powerful computational power chip, with 640 TOPS (INT8) of performance, comparable to NVIDIA's A100.
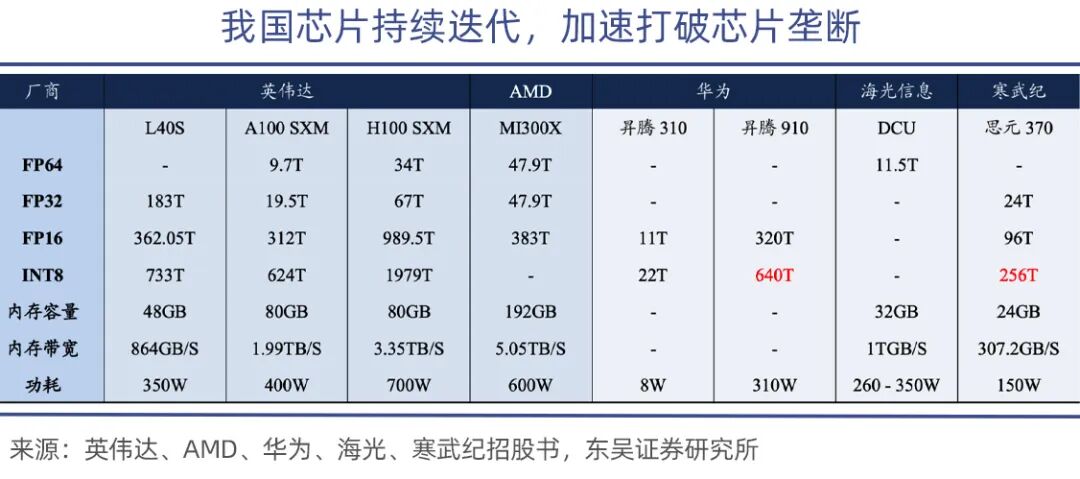
While domestic GPUs still lag in absolute performance, they can start with inference and edge scenarios. Currently, they generally meet domestic government and enterprise inference demands, narrowing the gap with NVIDIA's mid-range products to 15-20%, making substitution feasible.
It is particularly noteworthy that while computing power performance is important, the technological software ecosystem behind it is the Achilles' heel of domestic GPUs. Just as CUDA is the foundation of NVIDIA's GPU empire, Zheng Weimin, an academician of the Chinese Academy of Engineering, pointed out that the core issue with domestic AI chips is the inadequate ecosystem. If the ecosystem were robust, chips with 60% performance would still find users.
It can be said that the software ecosystem represents the most formidable barrier in the GPU race, and NVIDIA's capabilities in this area are equally irreplaceable.
The CUDA ecosystem, after more than a decade of cultivation, boasts over 4 million developers, hundreds of thousands of open-source models, and a full range of third-party toolchains covering AI training, inference, graphics rendering, and scientific computing, creating an unparalleled ecological barrier.
IDC data shows that currently, over 95% of AI models worldwide are developed based on the CUDA ecosystem. With policy support, domestic GPUs require long-term collaboration with the industrial chain and sufficient patience from media, public opinion, and capital markets.
In January of this year, Zhipu collaborated with Huawei to open-source the new-generation image generation model GLM-Image. Based on Huawei's Ascend Atlas 800T A2 devices and the MindSpore AI framework, the model completed the entire process from data processing to model training, becoming the first SOTA multimodal model trained entirely on domestic chips.
Moore Threads also partnered with the Beijing Academy of Artificial Intelligence (BAAI) to complete the full training process of BAAI's self-developed embodied brain model, RoboBrain 2.5, using the MTT S5000 AI computing cluster and the FlagOS-Robo framework. This achievement marked the first validation of the usability of domestic computing clusters in training large embodied intelligence models.
It is evident that domestic GPUs have made breakthroughs in adaptability and ecosystem construction, transitioning from "point breakthroughs" on the inference side to "gradual adaptation" on the training side—a significant step forward.

Summary
Overall, against the backdrop of restricted imports of advanced overseas chips, it is advisable to adopt a "combination of Chinese and Western approaches" by leveraging both domestic and international resources while focusing on supporting domestic computing chips to meet urgent market demands.
The authenticity of the demand is beyond doubt. While the "bubble theory" persists, its voice is not growing louder. Global enthusiasm for AI development has surpassed that of any previous industry in its early stages.
Since the beginning of this year, the global capital market has once again entered a super AI cycle, with shares of Samsung, SK Hynix, Broadcom, and TSMC repeatedly reaching new highs. In the domestic market, hard-tech companies like Cambricon have also experienced sharp rises, with optical module giant InnoLight's market value even surpassing that of Kweichow Moutai at one point.
Looking back at the history of South Korea's semiconductor industry, the country supported its memory chip sector with national efforts, endured the darkest moments, and ultimately defeated Japan to become the undisputed leader in the global memory industry.
Whether in memory chips, mobile chips, or current AI chips, China is still in the catching-up phase, which cannot be achieved overnight. However, with its vast market, a continuous influx of AI talent, and substantial capital strength, domestic GPUs have begun to demonstrate a certain degree of adaptability, capable of addressing the genuine needs of many AI enterprises.
In this AI competition concerning national destiny, China and the United States are both adversaries and possess technologies, markets, and resources that each other requires.
-
![]()
Over 50% of Revenue Hinges on Yutong Optics! This Optical Equipment Manufacturer is Charging Towards an IPO
-
![]()
YOCO Optics Finalizes Industrial and Commercial Registration Update Post 160 Million Yuan Investment in Jiangfeng Biology, Securing 20% Stake to Emerge as Second-Largest Shareholder!
-
![]()
Google Market Value Plummets by $1.5 Trillion Overnight Following the Loss of Two Key Figures
-
![]()
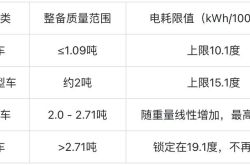
Put an End to the EV 'Weight Gain Race'! Can Your Car Still Be Driven Under the New National Standards?
-
![]()
In 2026, 'AI Upstarts' Collectively Bet on World Models
-
![]()
【OFweek Weike Cup】Phoenix Optics Officially Participates in the 2026 Optical Industry Annual Innovation Product Award
-
![]()
Ford Ditches Mach-E: Will Its Billion-Dollar Electrification Drive Have to Start All Over Again?
-
![]()
【OFweek Weike Cup】Shuangli Hepu Officially Participates in the 2026 High-Growth Enterprise Award in the Optical Industry