In 2026, 'AI Upstarts' Collectively Bet on World Models
 06/23 2026
06/23 2026
 426
426

The next generation of AI companies may not necessarily emerge solely in places with the largest parameters, the most papers, and the strongest computing power. They could also arise in locations with the densest real-world scenarios, the most frequent industry feedback, and the fastest engineering iteration. This is because the way AI truly changes the world is not by merely answering questions on a screen but by entering industrial settings, understanding the world, simulating it, taking action within it, and ultimately enhancing its operational efficiency.
Author | Dou Dou
Editor | Pi Ye
Produced by | Industrial+
AI seems to be collectively 'escaping' from pure text, making a comprehensive push into the real physical world defined by gravity, momentum, and geometric space.
On January 8, the Beijing Academy of Artificial Intelligence (BAAI) released the 'Top 10 AI Technology Trends for 2026,' listing world models as a crucial consensus direction toward AGI and proposing a paradigm shift from Next Token Prediction to Next State Prediction.
In the following months, industry actions came thick and fast, almost too numerous to keep up with.
First, large sums of capital originally flowing into embodied AI began targeting companies labeled with 'world models.'
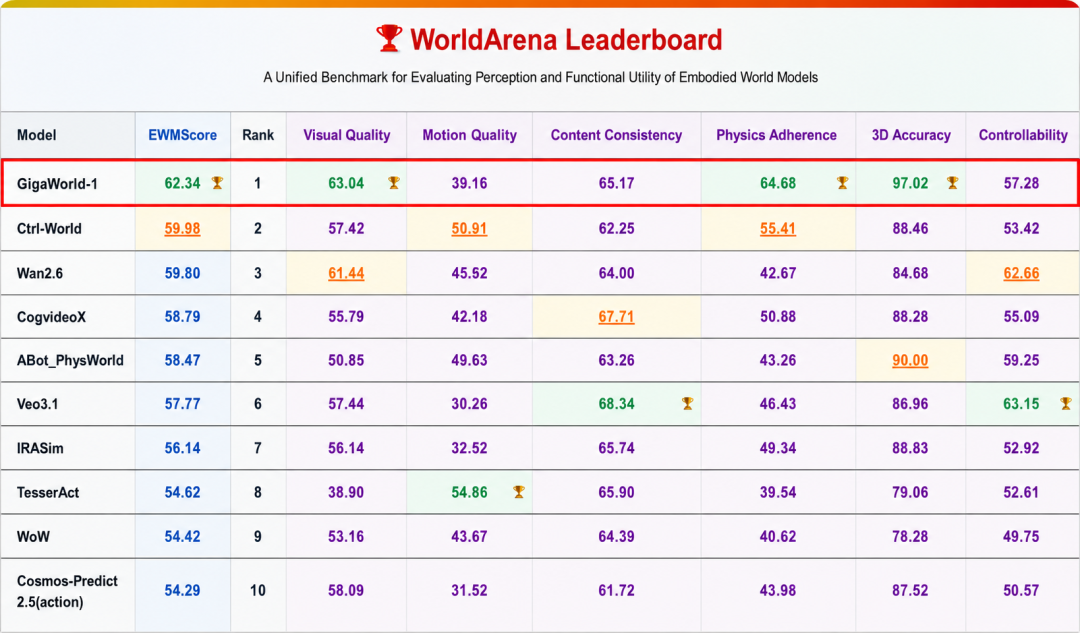
In March, Jijia Vision secured approximately 1.5 billion yuan in funding. That same month, its GigaWorld-1 topped the WorldArena evaluation, becoming the world's only embodied world model with a comprehensive score exceeding 60 points, outperforming Google, NVIDIA, and Alibaba. From March of this year to now, it has attracted 3.5 billion yuan in funding, earning the market title of 'China's first world model unicorn.'
Additionally, AI² Robotics raised over 1 billion yuan in its Series B funding round, valuing the company at over 10 billion yuan. Qianxun Intelligence, an embodied AI foundation company, completed four funding rounds within the first three months of 2026, attracting 4.5 billion yuan. Starry Sky Atlas, developing the world model Fast-WAM, secured nearly 2 billion yuan in its Series B+ round in April, following a nearly 1 billion yuan Series B round in February.
The secondary market showed similar 'preferences.'
On April 17, 'Physical AI' newcomer Koolar Tech, the world's first listed company with spatial intelligence as its core technological foundation, saw its stock surge 144% on its debut. Meanwhile, Shengshu Tech accumulated 2.6 billion yuan in financing over two months, reaching a post-investment valuation exceeding 12 billion yuan, with rumors of a planned Hong Kong IPO as early as 2026.
Notably, both companies' technological approaches represent one of the paths toward world models.
Players from various fields are also stirring. On April 16, Tencent and Alibaba each released a world model product on the same day. Tencent introduced the open-source Hunyuan 3D World Model 2.0 (HY-World 2.0), while Alibaba unveiled HappyOyster, focusing on real-time interaction.
Automakers are taking even more aggressive actions. Geely released the WAM (World Action Model), attempting to unify intelligent driving, smart cockpits, and chassis control. Huawei's ADS rejected VLA (Vision-Language-Action) and adhered to its WA (World Action) route, with the head of its automotive BU stating, 'VLA looks smart but isn't the true solution for autonomous driving.' Momenta, meanwhile, is betting heavily on world models.
In the robotics sector, NVIDIA launched Cosmos, DreamGen, and DreamZero, while Zhiyuan released GE-2, and Starry Sky Atlas began laying the groundwork for world model infrastructure.
Overseas, the scene is equally vibrant.
Turing Award winner Yann LeCun, after leading Meta AI for years, recently struck out on his own, founding AMI Labs focused on world models. In March 2026, AMI Labs secured a record-breaking $1.03 billion seed funding round. LeCun declared, 'The current LLM route is fundamentally flawed. Relying solely on text prediction, AI will never reach human-level intelligence. We need models that understand physical reality.'
Fei-Fei Li's World Labs completed $1 billion in financing in February, bringing its total funding to $1.23 billion and its valuation to approximately $5 billion, with its first commercial product, Marble, officially launched. Recently, OpenAI also announced its formal entry into the robotics sector.
Capital from primary and secondary markets, top scientists, and cross-industry giants are converging densely around one term: world models.
But why have world models suddenly become a must-have for everyone?
1. The Scaling Law Slows Down: The Industry Seeks Answers Beyond Language
A new consensus among AI giants: AGI cannot be achieved through text alone.
In recent years, large language models have followed a simple yet effective logic: predicting the next word. This mechanism has driven remarkable leaps in cognitive capabilities, leading the industry to believe that AGI could be achieved by simply scaling up parameters, increasing data, and stacking computing power.
But by 2026, an increasingly unavoidable issue has emerged: the Scaling Law is starting to falter.
Take OpenAI as an example. In its GPT-4.5 system card, OpenAI claimed GPT-4.5 was the 'largest and most knowledgeable model yet' and that it 'scales pre-training further.' However, on SWE-bench Verified, GPT-4.5 post-mitigation scored only 38%, just 2%–7% higher than GPT-4o and 30% lower than Deep Research.
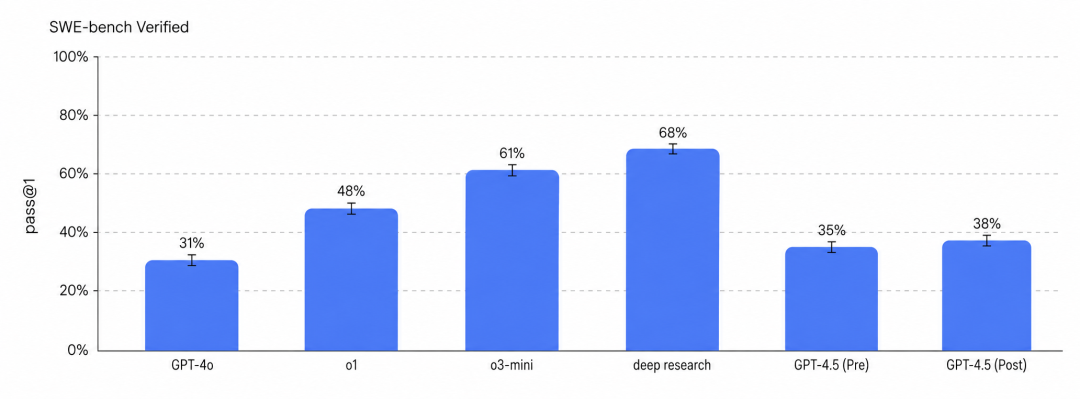
This suggests that while 'larger pre-training' still offers improvements in model iteration, it is no longer the most effective source of capability.
Meanwhile, the 'data wall' is emerging. High-quality text data from the internet has been nearly exhausted. Epoch AI estimates that approximately 300 trillion tokens of high-quality, deduplicated human public text are available for AI training. If current trends continue, language models will exhaust this stockpile between 2026 and 2032.
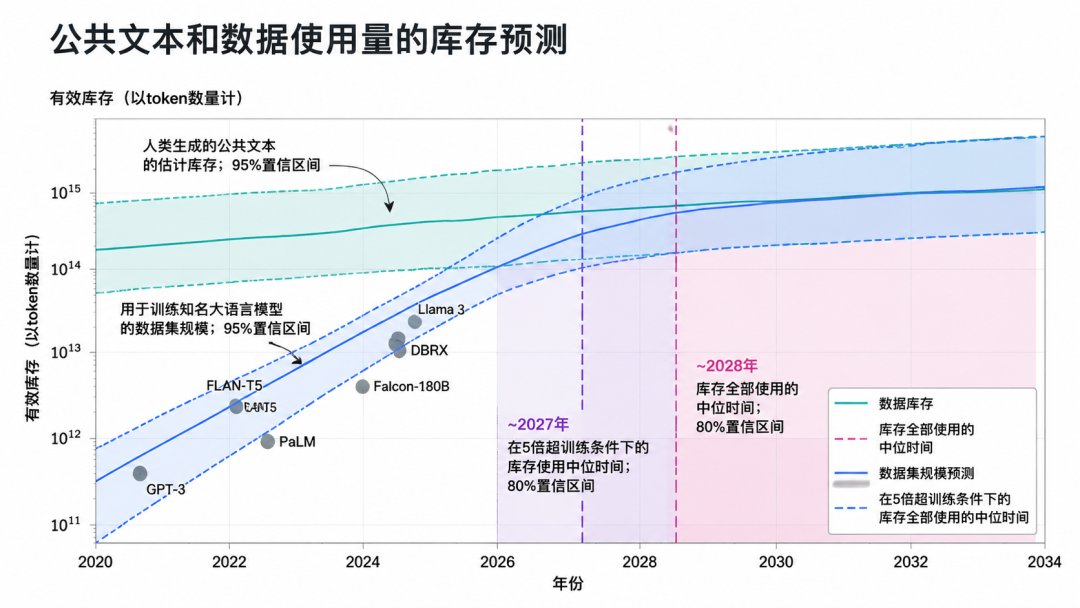
Moreover, even with the world's largest corpus, AI cannot truly understand concepts like gravity, friction, inertia, and spatial relationships.
The reason is straightforward: corpora record how humans describe the world, not how objects move within it. Physical common sense is inherently scarce in text because people rarely write down obvious facts like 'cups fall,' 'wheels roll,' or 'wet surfaces are slippery.' As a result, large pre-trained models perform poorly on such physical common-sense tasks.
Multimodal models have not fully resolved this issue.
The BLINK benchmark shows that tasks involving depth, spatial correspondence, and multi-view reasoning, which humans can nearly instantly complete, yield an average accuracy of only 51.26% for GPT-4V and 45.72% for Gemini—not far from random guessing.
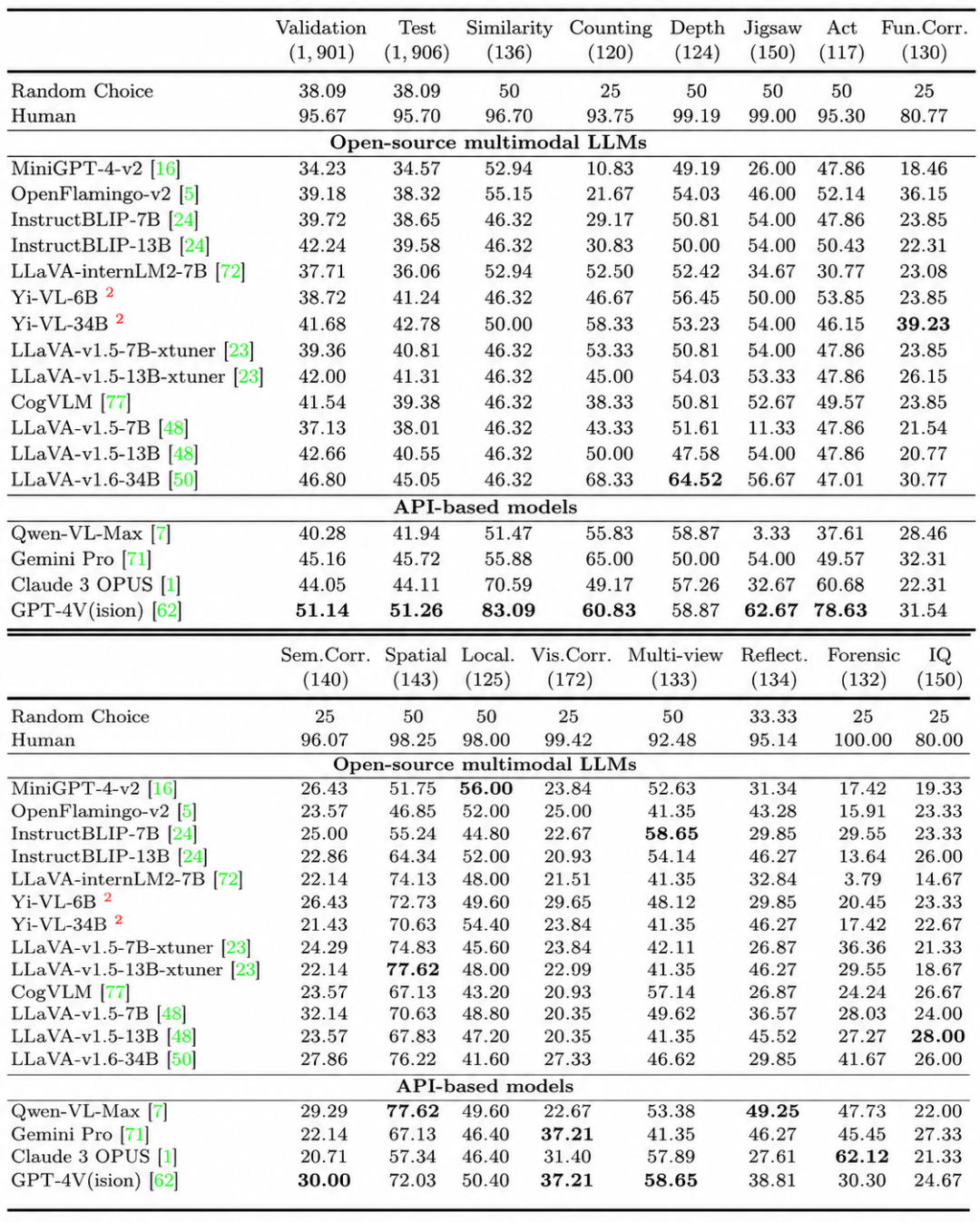
PhysBench further expands testing to real-world physical dimensions like friction, density, tension, elasticity, motion, collision, throwing, and fluids. Across 75 visual-language models and 10,002 test samples, researchers found that physical understanding does not consistently improve with model size, training data volume, or video frame count. In other words, even if AI reads every word about 'gravity' on the internet, it may still not understand why a ball cannot vanish into thin air, why objects cannot pass through walls, or why motion must be continuous.
This limitation ultimately manifests as the most vexing problem for enterprises deploying AI: hallucinations.
The reality is that in high-stakes, low-tolerance scenarios like finance, healthcare, and industry, LLMs still cannot establish stable and reliable physical causal reasoning capabilities. This is why many enterprise applications remain stuck at the assistance level and cannot become core decision-making systems.
Clearly, a gap remains between 'semantic understanding' and 'physical reasoning,' and this gap has become the primary obstacle to AI's industrial adoption.
This is the underlying reason for the attention on world models. A more direct reason is that embodied AI has reached a bottleneck.
As the vehicle for AI's entry into the real world and its path to AGI, this field has been a hotbed in recent years, attracting massive capital inflows and players from various sectors. Under such circumstances, the market and capital offer no room for respite, demanding breakthroughs and new technological avenues.
World models provide a fresh solution—or rather, a new technological narrative—allowing companies to continue telling this story.
At its core, a world model is a 'learnable physics simulator and rendering engine.' Instead of relying on text, AI uses a 'visual chain of thought' involving sight, 3D motion, and even touch to predict how a physical environment will change (B) if action (A) is taken.
While LLMs have given AI access to thousands of years of human language, logic, and civilization, world models equip AI with the ability to perceive spacetime, feel gravity, and understand reality. They represent the necessary path for transforming AI into true productivity.
2. Physical AI Positioning Battles Across Factions: Competing for the Next Gateway to Productivity
If the previous stage of large model competition focused on text understanding and generation, the current round of world model competition centers on bringing AI into a computable, interactive, and trainable physical world. The industry's collective bet on world models reflects a desperate search for AI's next productivity gateway across sectors.
However, it must be acknowledged that world models are far from mature. They lack a unified technical roadmap, are not a short-term panacea to replace large language models, and even lack a consensus definition.
For instance, at the recent BAAI Conference, BAAI President Wang Zhongyuan proposed four categories of world models: language-centric (LLM/VLM/VLA), pixel-centric (video generation, like the misapplied Sora), 3D structure-centric (3D reconstruction), and visual representation-centric.
Fei-Fei Li and her World Labs team offered a different classification, proposing three functional frameworks for world models in their published article: renderers, simulators, and planners.
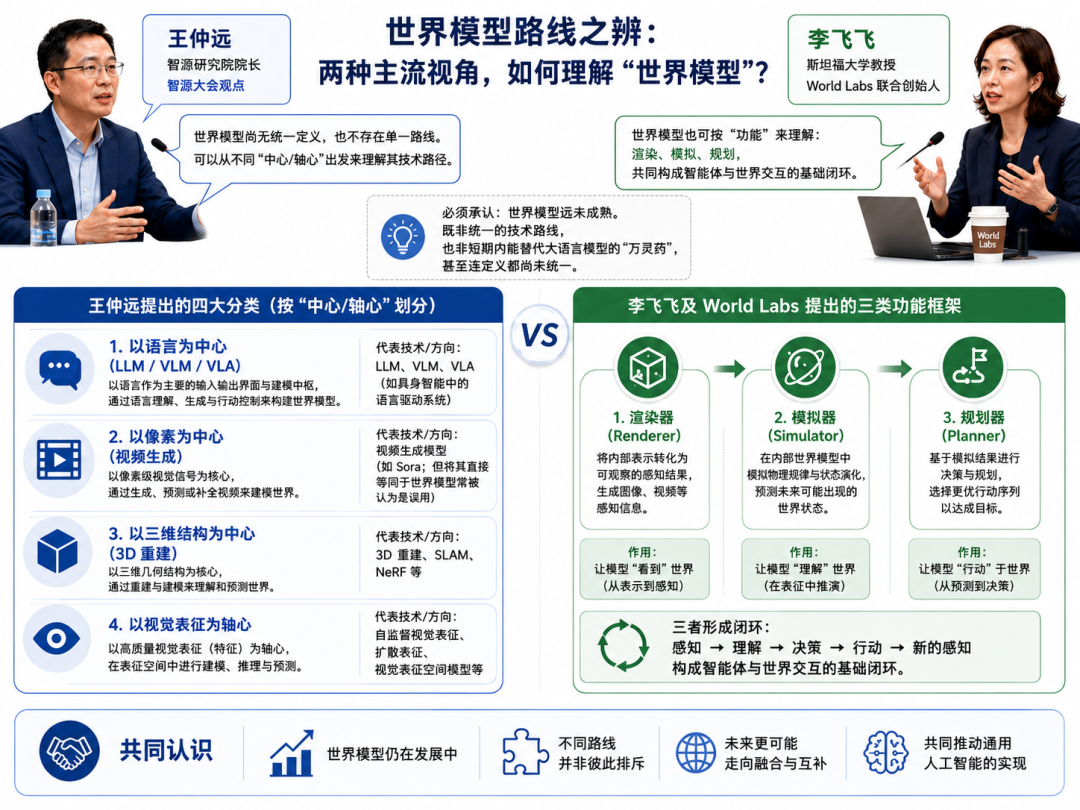
Even so, the industry remains in an early trial phase where different sectors approach 'understanding the physical world' from their respective strengths. In this gradual migration, players from diverse backgrounds are leveraging their industrial logic to try to unlock world models.
The video generation faction was the first to move.
This group's confidence stems from possessing the industry's strongest video generation engines. Shengshu Tech, Alibaba's HappyOyster, Kuaishou Kling, ByteDance's Seedance, and overseas players like Sora and Runway form the first wave. This trend is driven by breakthroughs in real-time interaction technologies like AR-DiT. Previously, such models could only generate non-interactive 'films,' but with AR-DiT advancements, video models now shift toward action-driven frame-by-frame generation, elevating 'text-to-video' to 'drivable video worlds.'
However, the hidden danger (hidden risk) of this approach is that it learns visual coherence rather than physical reality, lacking true 3D structure and prone to inconsistencies over time.
Spatial intelligence players offer a contrasting approach, advocating 'reconstruct first, then understand.'
Key representatives include Fei-Fei Li's World Labs and domestic player Koolar Tech. Tencent Hunyuan also entered this path using its vast gaming data, reducing open-world map modeling from months to just over ten minutes, disrupting the gaming industry. Koolar Tech, acting as a foundational 'water seller,' has accumulated hundreds of millions of physically accurate design data from over a decade of home improvement software, supplying virtual training grounds for embodied AI companies.
The sector with the most acute need for world models is embodied AI.
Robots' biggest pain point is the scarcity of real-world data, and world models allow them to rehearse skills repeatedly in 'imagination' before fine-tuning with minimal real data. This explains why massive capital is now crazy (frenziedly) targeting companies labeled with 'world models.'
However, this is also the faction with the deepest route disagreements. For example, Jijia Vision advocates learning skills through imagination in virtual spaces; Zhiyuan and Starry Sky Atlas focus on building infrastructure like simulation platforms; AMI Labs attempts to bypass pixels and predict the future in abstract latent spaces; while Qianxun Intelligence explicitly takes the opposite approach, abandoning energy-intensive frame-by-frame prediction for lighter pre-training with fewer parameters. Currently, various routes are converging technologically, with world models replicating the large language model playbook by serving as the 'pre-training' phase for embodied AI.
Compared to robots' long cycles, automakers and intelligent driving companies are taking world models directly onto the road, becoming the closest faction to monetization.
Intelligent driving is the earliest field to possess massive real-world road testing data and clear payment scenarios. Additionally, autonomous driving simulation is already the most mature and deployed application of world models, enabling batch synthesis of rare dangerous scenarios for testing—an efficiency order of magnitude higher than pure road testing alone.
From this perspective, the video faction enters through pixels, the spatial faction through geometry, the embodied faction through actions, and automakers through scenarios. These represent inevitable steps toward physical AI convergence across different industries based on their unique scenarios. In the short term, creative design will monetize fastest; in the medium term, intelligent driving will widen the gap; in the long term, world models will not culminate in a single product but will serve as the future physical AI infrastructure connecting data, simulation, and action. They represent the critical intermediate layer AI must develop to transition from the digital to the physical world.
Once these industry entry points are established one by one, market competition is bound to sink deeper into the industrial chain.
III. The Next Generation of AI Companies: Understanding, Simulating, and Acting in the World
The importance of world models lies not only in representing a new model route but also in pushing AI's battleground from screens, text, and software interfaces to automobiles, robots, factories, warehouses, architecture, cities, and homes.
Large language models can first be trained in the cloud and then disseminated through APIs, office software, search engines, customer service, coding tools, and other entry points. Their primary battleground is the digital world. However, the goal of world models is not to answer questions but to predict, generate, intervene, and transform the physical world. They naturally need to integrate into automobiles, robots, factories, warehouses, architecture, game engines, spatial design software, and XR devices.
This means that competition for world models will not hinge solely on whose model parameters are larger, whose videos are more realistic, or whose benchmark scores are higher. The real competition will occur deep within the industrial chain, such as who possesses high-quality physical data, who controls simulation and evaluation platforms, who can connect to real devices, and who can form feedback loops in real-world scenarios.
In other words, world models represent a set of infrastructure that AI must rebuild to enter the physical world.
The industrial stack for large models in the past was relatively clear, with chips and cloud computing at the base, foundational models in the middle, and applications and agents at the top. However, world models have elongated this chain. The future technology stack for physical AI may evolve into physical data acquisition, data cleaning and synthesis, world representation layer, foundational world model layer, simulation and evaluation layer, action model layer, and deployment feedback layer.
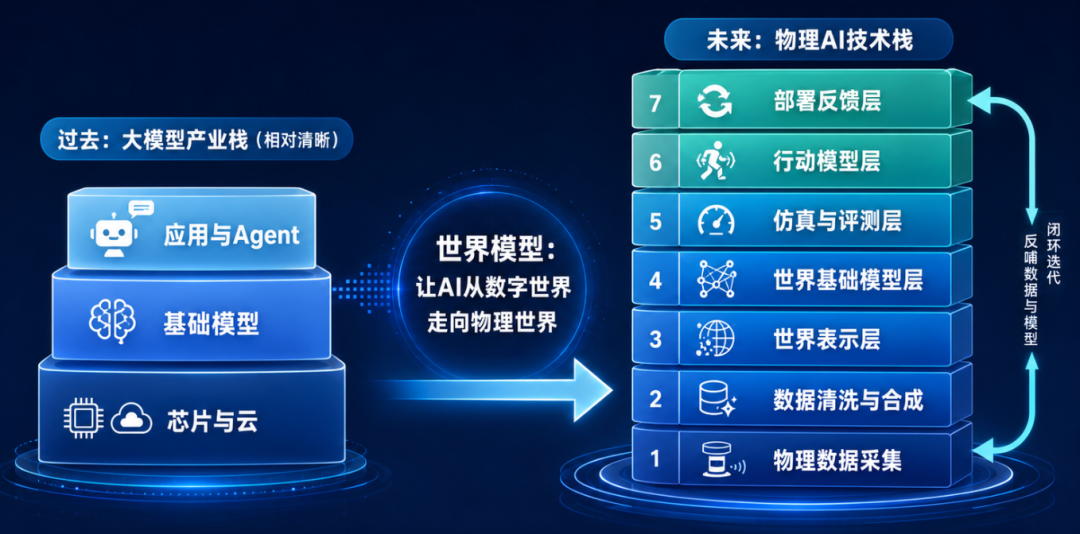
Once this chain is formed, world models will no longer be just 'AI for content generation' but will become the operating system of the physical AI era. They will connect downward to chips, sensors, and robot bodies and upward to agents, industry software, and enterprise business systems. They will receive real-world data while generating virtual worlds that are trainable, verifiable, and deployable. Their position is akin to that of foundational models in the large language model era, but their level of industrial integration will be deeper, as they must be bound to physical devices, engineering processes, industry standards, and safety verifications.
Therefore, the true significance of world models lies in enabling AI to systematically enter physical industries for the first time.
This also makes Chinese companies more noteworthy in this round of competition.
In the era of physical AI, competitive variables will change. Model capabilities will remain important, but scenario density, engineering capabilities, supply chain collaboration, Body manufacturing (bodily manufacturing), industry delivery, and customer feedback will be equally crucial.
This happens to be where Chinese companies excel. China boasts the world's most complete manufacturing system, the most complex urban traffic scenarios, the fastest-growing robotics industry chain, a vast new energy vehicle market, and abundant real-world spatial and industrial scenarios. These are the physical data sources and implementation grounds that world models need most.
In other words, competition for world models will not only take place in laboratories and the cloud but also in workshops, on roads, in warehouses, stores, homes, construction sites, and urban infrastructure. Whoever can integrate models into these scenarios faster and obtain real feedback sooner is likely to establish a stronger engineering closed loop (closed loop) and data flywheel.
This means that the next generation of AI companies may not necessarily emerge solely in places with the largest parameters, the most papers, and the strongest computing power but could also arise in locations with the densest real-world scenarios, the most frequent industry feedback, and the fastest engineering iterations. Because the way AI truly changes the world is not by remaining on screens to answer questions about the world but by entering industrial sites to understand, simulate, and act in the world—ultimately improving its operational efficiency.
-
![]()
Over 50% of Revenue Hinges on Yutong Optics! This Optical Equipment Manufacturer is Charging Towards an IPO
-
![]()
YOCO Optics Finalizes Industrial and Commercial Registration Update Post 160 Million Yuan Investment in Jiangfeng Biology, Securing 20% Stake to Emerge as Second-Largest Shareholder!
-
![]()
Google Market Value Plummets by $1.5 Trillion Overnight Following the Loss of Two Key Figures
-
![]()
Put an End to the EV 'Weight Gain Race'! Can Your Car Still Be Driven Under the New National Standards?
-
![]()
In 2026, 'AI Upstarts' Collectively Bet on World Models
-
![]()
【OFweek Weike Cup】Phoenix Optics Officially Participates in the 2026 Optical Industry Annual Innovation Product Award
-
![]()
Ford Ditches Mach-E: Will Its Billion-Dollar Electrification Drive Have to Start All Over Again?
-
![]()
【OFweek Weike Cup】Shuangli Hepu Officially Participates in the 2026 High-Growth Enterprise Award in the Optical Industry