World Models: 'World Building' is Feasible, but Not the Future Embodied AI Wants
 06/23 2026
06/23 2026
 504
504

Editor: Lv Xinyi
From VLA to WAM: An Overrated Revolution and an Underrated Evolution.
Over the past six months, the field of embodied AI has witnessed two of the most lively public spectacles. One took place on screens: from Sora to various video generation models showcasing their capabilities one after another, the details of a cup of water spilling and spreading, and the movement of characters in continuous spaces, propelled the narrative of 'AI recreating reality' to its peak, with exclamations of 'the world model is here' echoing repeatedly. The other spectacle involved tombstones: Jim Fan, Chief Research Scientist at NVIDIA, used a meme image of a WAM (World Action Model) standing before the tombstone of VLA (Vision-Language-Action Model) to declare 'VLA is dead, long live the world model,' directly bringing the debate over approaches to the forefront. (This article only discusses world models in embodied AI.)
Both spectacles share a common core term: world model.
However, paradoxically, the more people talk about it in the field of embodied AI, the more ambiguous its identity becomes. Some refer to generating realistic videos as a world model, others call robotic action previews world models, and some label autonomous driving simulation environments as world models as well. Under the same concept lie vastly different technological goals and commercial aspirations.
The greatest danger facing world models today is not 'unclear definitions,' but rather that everyone is defining its entire value based on its most easily showcased and viral aspects. When the flair of 'world building' overshadows the essence of 'using the world,' world models are being led away from their true destination—the real physical scenarios of Physical AI—by the most skilled storytellers.
World models certainly require the ability to 'build worlds.' Without those stunning generative demonstrations, they would not have entered the public and capital spotlight so quickly. However, for the Physical AI industry, generating a world is merely the beginning of the problem. Ultimately, the world must be controlled, verified, and corrected, becoming a preview space and decision-making basis for machine actions before they occur. Video generation can open the door to world models, but it cannot complete the journey toward the real physical world.
We are never short of new concepts and narratives; embodied AI will undoubtedly find its own universal path. By then, whether this path is called VLA, WAM, or something else may no longer matter.
After all, it will already be embedded in our lives.

Remember Sora?
When OpenAI released Sora, the report's title was 'Video generation models as world simulators,' announcing that video generation models could become a viable path toward a 'universal simulator for the physical world.' The long videos showcased by Sora at the time, with their camera movements, local 3D consistency, and object state preservation, allowed the public to intuitively feel for the first time that AI seemed to be learning to 'build a world.' Compared to text and images, videos naturally align with human intuition about the 'world'—they have time, space, motion, and continuous change, easily creating the illusion that 'the model has already grasped physical laws.'
Such capabilities are naturally suited for conference demonstrations and readily attract the attention of capital and media. Over time, 'video generation = world model' has become the default cognitive entry point for many.
This is certainly not wrong. In digital-native scenarios, video generation routes are efficient solutions, and numerous unicorn companies have emerged. Their products can be used in the gaming industry to generate dynamic scenes in real-time, reducing art costs while enhancing player freedom; in aerospace, high-end manufacturing, and other high-cost trial-and-error fields, they expand testing boundaries and enrich simulation scenarios, also holding clear commercial value. In these cases, the generated 'world' is not just a visual for viewers but an interactive, trial-and-error simulation environment.
The real misinterpretation occurs during cross-domain applications. When world models encounter embodied AI, many assume that a model's ability to generate a continuous and realistic digital world equates to its mastery of understanding, predicting, and acting in the physical world.
Wang Zhongyuan, Dean of the Beijing Academy of Artificial Intelligence, offers a piercing judgment: The video generation technology widely regarded as representative of world models is essentially pixel-level world simulation. 'Video generation models can generate a scene where a group of pigs fly in the sky alongside an airplane because their training data includes a large amount of science fiction film content. Their goal has never been to reproduce the laws of the real physical world.'
A classic embodied scenario suffices to illustrate the gap: grasping a cup. A model can generate cups with consistent appearances from different perspectives—this is visual consistency, which it can learn from video data. However, what is the friction when the hand touches it? Can the material withstand the corresponding grip strength? Does the cup land on the table because the model remembers that 'cups are usually on tables,' or does it truly understand gravity, support forces, and contact constraints? Complex mechanical responses, state changes after contact, and causal constraints from real physical laws cannot be covered by a generated video. When a car generated to move sideways is introduced into autonomous driving training without validation, the real physical world will eventually exact a painful toll.
In other words, video generation is a form of expression for world models and has already found applications in many scenarios, but it is by no means the world model desired by embodied AI, nor is it the core form within the context of Physical AI. Defining world models in embodied AI through the visual effects of 'world building' is essentially using the yardstick of the digital world to measure problems in the physical world.

The narrative that 'VLA is dead, WAM is the successor' is the most popular within the industry.
Over the past two years, VLA has been the mainstream path for embodied AI. It follows the pre-training approach of large language models, establishing a mapping between 'perception-instruction-action' through massive teleoperation data, enabling robots to transition from rigid repetitive actions to understanding natural language and breaking down complex tasks. All mainstream players in the industry have once taken VLA as their core technological foundation.
However, VLA's shortcomings are also clear: Essentially a form of imitation learning that relies on memory and mapping, it lacks a fundamental understanding of physical laws. Once encountering unfamiliar scenarios or objects not present in the training data, its generalization ability rapidly fails. Jim Fan's proposed WAM route precisely targets this pain point. Its core logic shifts from 'semantic understanding' to 'physical prediction': Instead of directly outputting actions, it first predicts future world states and then derives action sequences, effectively allowing the robot to 'rehearse' the consequences in its mind before acting, thereby enhancing its adaptability to unfamiliar scenarios.
Thus, the 'disruption theory' quickly gained traction, with VLA being labeled an outdated paradigm and world models hailed as the next-generation answer for embodied AI. However, in real-world industrial practice, things are far from a simple 'either-or' scenario.
The industry is differentiation (dividing) into two clear routes, driven by different technological philosophies and commercial aspirations:
One is the 'Replacement Camp' led by Silicon Valley. Represented by NVIDIA and Google DeepMind, they rely on abundant computing power and data reserves to pursue a complete paradigm reconstruction. NVIDIA's Cosmos 3 integrates language, images, videos, and action sequences into a unified Physical AI world model framework, attempting to make generation, simulation, and action prediction no longer isolated modules; Waymo, in collaboration with Google DeepMind, launched the Waymo World Model, leveraging the capabilities of the Genie 3 model. This model is not just used to generate rare weather conditions, animal intrusions, and other long-tail scenarios but focuses on making these scenarios controllable by driving actions, road layouts, and linguistic conditions to test the reactions of autonomous driving systems in counterfactual situations.
This route is the most ambitious and aligns perfectly with 'revolutionary narratives,' but its barriers to entry are extremely high—a game for top-tier giants.
The other route is more prevalent domestically: the 'Integration Camp.' Most players have chosen not to start from scratch but to embed world models as a complementary capability within existing VLA architectures. In May 2026, Zhiping Fang released the VLA embodied large model AlphaBrain. Drawing inspiration from the division of labor in the human brain—'brain-cerebellum-body'—it coordinates through a 'fast-slow system,' embedding the 'rehearsal' capability of world models within the VLA architecture. The slow system handles environmental situation awareness and high-level behavioral planning, while the fast system manages fine-grained sensing and rapid feedback. Guo Yandong, founder of Zhiping Fang, is straightforward in his judgment: 'World models and VLA are not conflicting at all; they are originally branches of the same technological route. If you want to perform longer-range reasoning tasks, you need world models + VLA, or merge world models with VLA.'
Yinhe General Technology has also made significant strides. Their LDA-1B model, released in April this year, simultaneously conducts policy learning, physical prediction, and visual perception within a unified framework, achieving the integration of world models and action models at an industrial-scale billion-parameter level for the first time. Relevant achievements have been selected for the robotics conference RSS, with model weights and training code open-sourced. They do not dwell on 'choosing between VLA and world models' but instead pragmatically allow prediction and execution to share the same model, leveraging each other's strengths and compensating for weaknesses.
In our view, there is no absolute right or wrong between 'replacement' and 'integration'; they are merely different choices for different stages. VLA will not truly 'die,' nor is the world model a revolutionary force that disrupts everything. What it complements is VLA's most lacking capability: physical prediction. The ultimate relationship between the two is more likely to be hierarchical collaboration rather than a zero-sum game. What truly determines the success of a route is never how trendy the concept is but who can first establish a functional chain of data, simulation, and real-machine deployment, enabling robots to truly enter real-world scenarios.

When conceptual hype outpaces technological implementation, bubbles are almost inevitable. The current world model track already exhibits at least three layers of bubbles worthy of caution.
The first is the definition bubble. Today, 'world model' has become a catch-all term. Yann LeCun views it as world state prediction at an abstract level, Li Feifei defines it as an interactive 3D spatial representation, NVIDIA positions it as a generative simulator for Physical AI, while startups vary from using video generation as a substitute to rebranding traditional simulation engines as world models. Dozens of companies in China claim to be developing world models, but they may not even be talking about the same thing. When a technological concept can be interpreted infinitely, it often loses its meaning as a technical benchmark. Behind this definition inflation lie financing needs and marketing narratives—after all, calling it a 'world model' sounds more valuable than a 'video generation tool' or 'simulation optimization solution.'
The second is the computing power bubble. The mainstream training route for world models relies on massive video data and enormous computing power, which happens to be NVIDIA's home turf. Jensen Huang stated at the GTC conference that by 2027, Blackwell and Rubin chips, along with their supporting systems designed for embodied AI models, would generate at least $1 trillion in revenue for NVIDIA. To some extent, the push by Silicon Valley's top players for a 'full-modality universal world model' route aligns perfectly with NVIDIA's commercial logic of 'selling computing infrastructure.' However, the investment threshold for this route is a bottomless pit for most companies. Small and medium-sized teams that previously bet on VLA already struggled to bear such large sunk costs, let alone starting from scratch in the world model track. When everyone discusses the same high-computing-power route but few calculate the return on investment, it is a clear signal of a bubble.
The third, and most fatal, is the implementation bubble. All conceptual narratives must ultimately answer the same question: Can they enhance real-machine performance? The reality is that the simulation-to-reality transfer gap does not automatically disappear just because the model's name changes from VLA to WAM. A minor visual glitch, anti-gravity effect, or blurry boundary in a video can solidify into incorrect physical cognition during robot training; a prediction that seems reasonable but violates physical laws can mislead real machines even more severely than not using a model at all.
Shen Yujun, Chief Scientist at Ant Intelligent Wave, pointed out the core difference: Generative models in the digital world can prioritize high-definition realism—speed is not critical. However, models in the physical world must first and foremost be fast, stable, and accurate, capable of providing real-time feedback to support actions. Many teams focus on rendering scenes increasingly realistically in the digital world while neglecting that real physical interaction data is the scarcest resource. World models may achieve impressive metrics in simulations, but until they validate real value on factory production lines, logistics warehouses, or open roads, they remain technological explorations in laboratories rather than industrial-grade infrastructure.
So, what should the world model for Physical AI or embodied AI look like? The answer lies not in demonstration videos from conferences but in the demands of real-world scenarios. Its core evaluation standard is never 'how realistic the generated world is' but 'whether it helps machines act better in the physical world'—whether it reduces trial-and-error costs, enhances generalization ability, and embeds into real business loops.
From current industrial practices, players truly heading in the right direction are all doing the same thing: shifting world models from 'demonstration-oriented' to 'task-oriented.' In other words, the ultimate form of world models is not an independent 'product' but a foundational capability embedded within various physical systems. It resides in the simulation backend of autonomous driving, the action planning modules of robots, and the predictive systems of factory production lines, quietly performing prediction, trial-and-error, and correction. Most of the time, users may not even perceive its existence.
That will be the era of world models—though they may no longer be called world models by then.
-
![]()
Over 50% of Revenue Hinges on Yutong Optics! This Optical Equipment Manufacturer is Charging Towards an IPO
-
![]()
YOCO Optics Finalizes Industrial and Commercial Registration Update Post 160 Million Yuan Investment in Jiangfeng Biology, Securing 20% Stake to Emerge as Second-Largest Shareholder!
-
![]()
Google Market Value Plummets by $1.5 Trillion Overnight Following the Loss of Two Key Figures
-
![]()
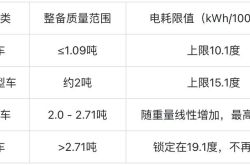
Put an End to the EV 'Weight Gain Race'! Can Your Car Still Be Driven Under the New National Standards?
-
![]()
In 2026, 'AI Upstarts' Collectively Bet on World Models
-
![]()
【OFweek Weike Cup】Phoenix Optics Officially Participates in the 2026 Optical Industry Annual Innovation Product Award
-
![]()
Ford Ditches Mach-E: Will Its Billion-Dollar Electrification Drive Have to Start All Over Again?
-
![]()
【OFweek Weike Cup】Shuangli Hepu Officially Participates in the 2026 High-Growth Enterprise Award in the Optical Industry