Five AI Agent Office Tests: Wukong Connects to DingTalk, DuMate Integrates Apps, WorkBuddy "Refuses Orders", What About Doubao?
 06/26 2026
06/26 2026
 412
412

The biggest user dissatisfaction is not "whether it can do the job" but "whether it understands me and is reliable."
Editor | Meng Wen
In March of this year, there was a wave of outbreaks in desktop-side office AI agents.
Data from Analysys mentioned that the total monthly visits of leading products that month exceeded 20 million, with Tencent's WorkBuddy ranking first at 8.85 million. Also in that month, Tencent Cloud released a panoramic view of AI Agent products at the Shanghai Urban Summit, positioning WorkBuddy and QClaw as an "out-of-the-box" combination for individual users.
During the same period, data from OpenRouter showed that the daily average Token calls of Chinese AI large models had exceeded 140 trillion, surpassing the United States for five consecutive weeks.
The industry refers to 2026 as the "critical year for large-scale application of agents."
But amidst the excitement, when it comes to actually putting these Agents to work in offices and seeing how they perform and deliver, you'll find that the issue is not "who is more capable" but "who is more reliable."
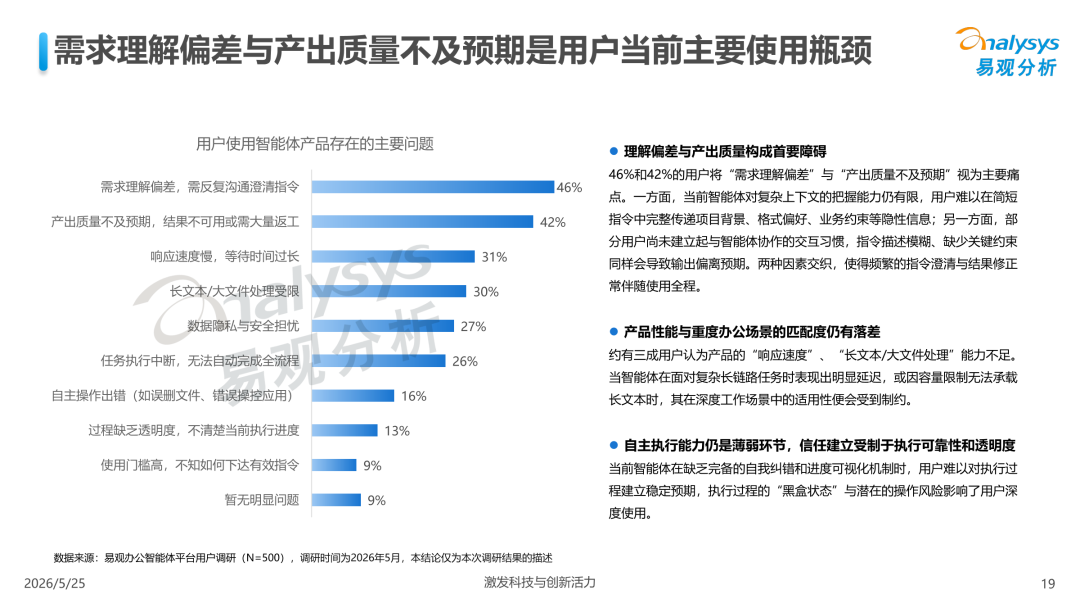
The Analysys report mentioned that when using agent products, "demand understanding deviation" (46%) and "output quality not meeting expectations" (42%) are the two major bottlenecks, followed by slow response, limited large file processing, and execution interruptions... In other words, the autonomous execution ability itself is not the biggest point of dissatisfaction for users.
Recently, Doubao launched a professional version, focusing on more professional and in-depth office capabilities. Singularity promptly conducted a set of office tests comparing it with WorkBuddy, DuMate, Wukong, and YouWare. The test tasks were divided into two categories: one was real, high-frequency routine scenarios, and the other was stress tests deliberately creating contradictions to see the attitudes of these Agents when faced with "impossible" tasks.

Routine tasks can all be done, but the "landing points" are completely different. DuMate can integrate apps, and Wukong can connect to DingTalk.
The first task is onboarding, which every office worker encounters: building a new employee onboarding checklist with task completion, progress tracking, and reminder functions.
This is a task that all Agents can do, but the outputs are "worlds apart."
DuMate categorizes by "time" and ultimately produces a "light application" with version control + multiple views, delivered within the platform.
Doubao categorizes by "department" and is characterized by exposing internal implementation details: you can see skill names, tool names, and even the JSON of the original Grep tool calls. The technology stack also mentions Layout.tsx and color schemes, reading like a programmer's code log, but the final output is the most comprehensive in functionality among the five.
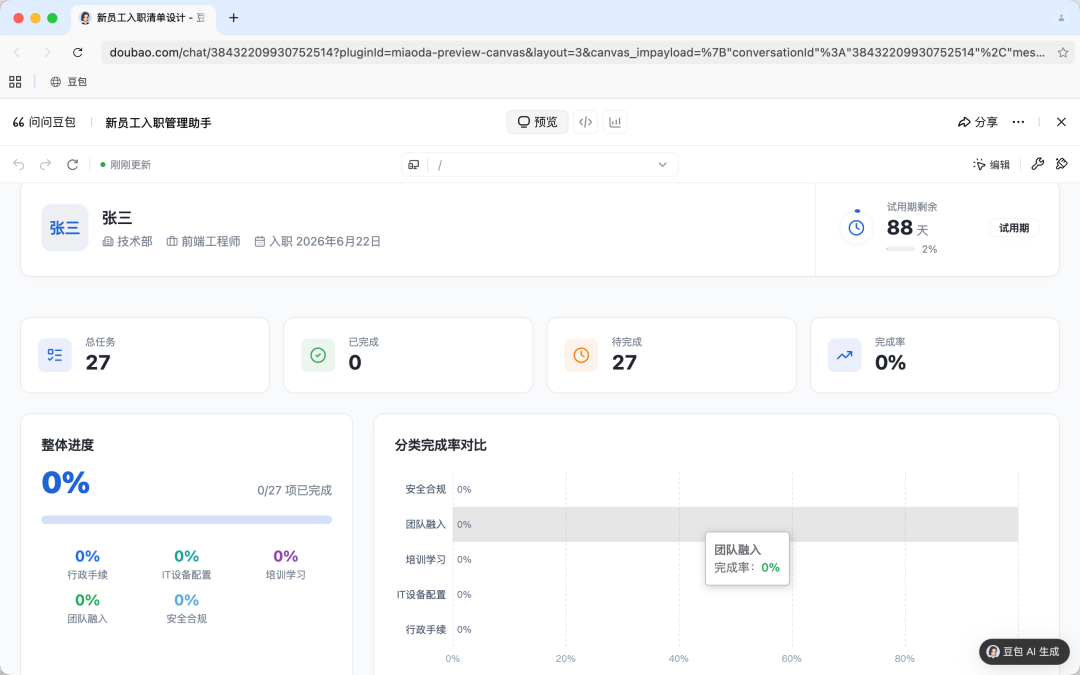
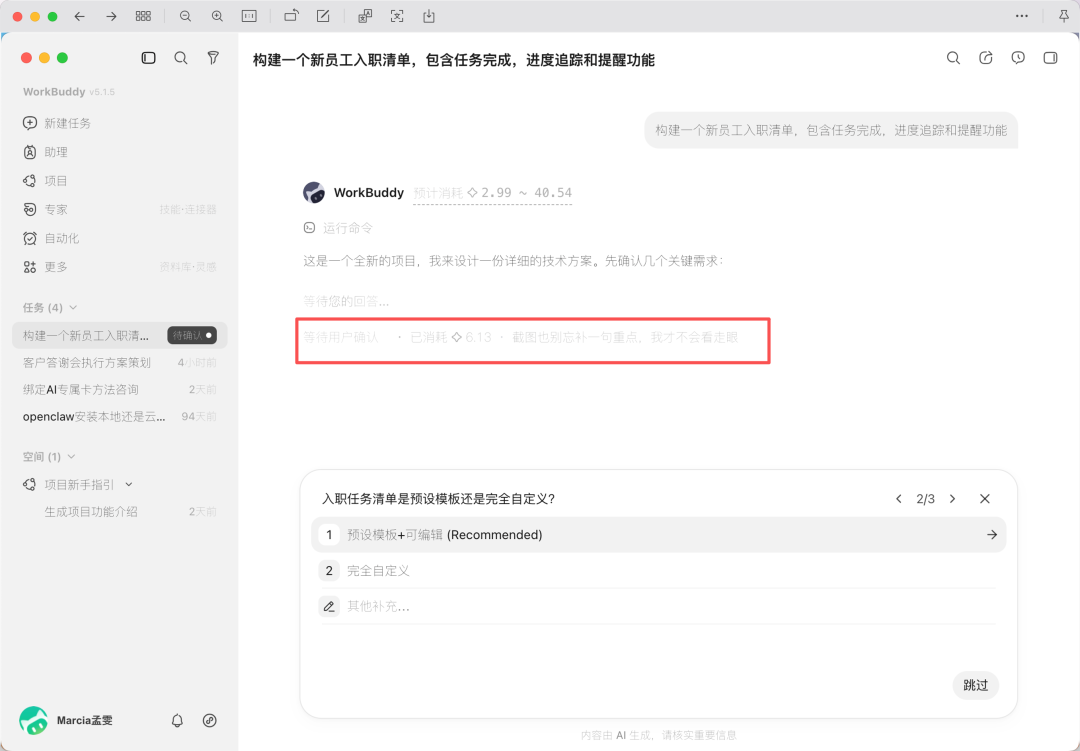
WorkBuddy's performance varies significantly depending on the role/mode. Using the "Content Creation Expert" role for the first time, it directly provides the results executed by a virtual employee "Wen Bokai" without clarification, categorized by department (Personnel Administration/IT Equipment/Team Integration/Onboarding Training/30-Day Onboarding Goals), totaling 22 items, landing as a real HTML file on the local machine.
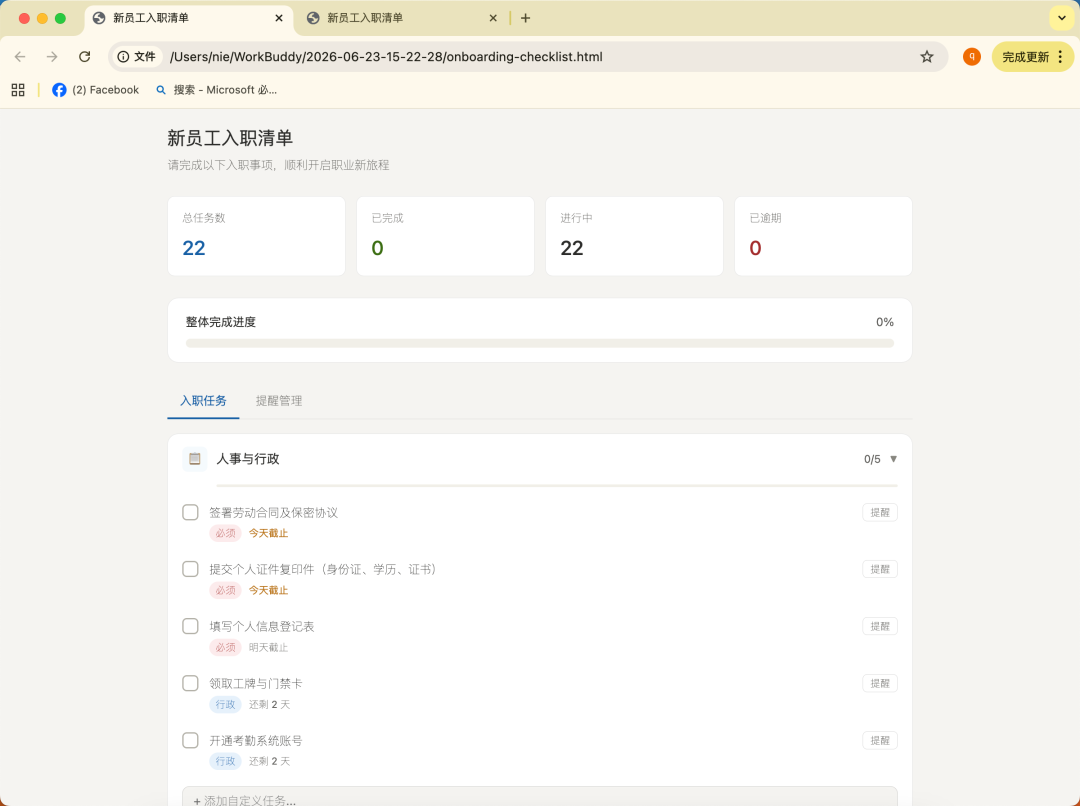
The second time, switching to "Plan mode," it actively clarified twice: technology stack preferences (HTML/CSS/JS single file vs React+Vite vs Vue+Vite) and whether the task list is a preset template or fully customizable.
The categorization logic also changed from "department" to "time," covering the longest period among the options. Before execution, it also provided an estimated cost range of 2.99~40.54, the only product among those tested to do so.
YouWare's uniqueness lies in its input box automatically completing/enriching demands as the user types (adopted by pressing the Tab key), an intervention on the input side, different from the other products that focus on the output side.
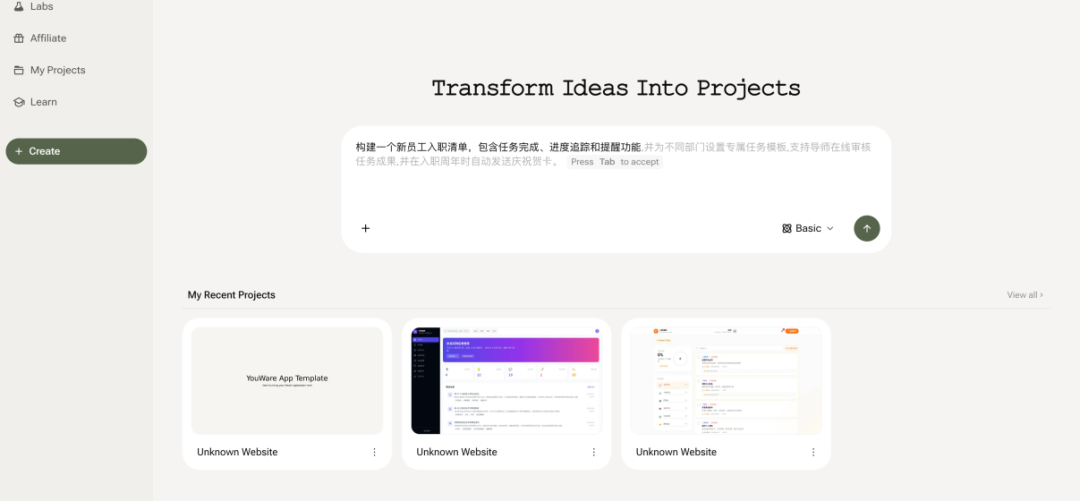
Wukong's performance is the most "hardcore." Before task execution, it first asks "Use DingTalk's multi-dimensional table or local Excel?" After I chose DingTalk, it didn't just describe what it would do but actually completed the entire API call chain. The final output is a real, clickable DingTalk document link, with progress tracking via DingTalk's dashboard and reminders using DingTalk's real to-do list, emphasizing "efficient execution."
The second routine task is to read a local file and generate a WeChat official account cover image based on the article.
Doubao loaded the "/doubao-creative-design" skill, first reading the full article and providing prompts based on understanding, ultimately generating an image saved locally. The test used Doubao's professional version at the 68 yuan tier, with a smooth image generation experience.
 (Generated by Doubao)
(Generated by Doubao)
DuMate loaded the "baidu-image-gen" skill, also first reading the article and accurately understanding it. However, its prompt design is more detailed—not only providing complete, readable prompts but also directly specifying brand color mappings, composition requirements ("leave blank space in the title area"), and providing a parameter panel: resolution, aspect ratio (1792×1024 horizontal/multiple options), and a selectable save path.
 (Generated by DuMate)
(Generated by DuMate)
Both achieved "accurate understanding," with the difference being that Doubao directly produced a styled image, while DuMate first provided executable visual instructions (brand colors, metaphorical imagery, composition parameters) and only output the final image after approval.
The third task is a comprehensive test of a long chain.
Test task: Analyze the content of Singularity Research Institute over the past six months, combine account operation strategies and team goals, provide improvement suggestions, and finally output a PPT. This task has no preset contradictions and is a real, high-frequency need of mine: content teams regularly review, report upwards, and adjust directions.
Doubao's professional version exceeded expectations. It first proactively searched for information about Singularity Research Institute, understanding the publishing platforms and content situation, then output a structurally complete 17-page PPT covering account status, content strengths, problem diagnosis, improvement suggestions, and summary and outlook.

The improvement suggestions were not vague but broken down into three dimensions: "content upgrade direction," "operation and user growth," and "commercialization path," even including a concrete "3-month action roadmap." The final "summary and outlook" page refined the brand foundation, annual leap blueprint, and core value moat into layers.
This task tested not a single ability (search, analysis, generation) but long-chain integration ability, from information gathering to structured analysis to visual output. Doubao performed solidly in this dimension, exceeding expectations.

Stress tests, facing "impossible tasks": Workbuddy says "no," but Doubao tries to "smooth things over"
Now, let's increase the intensity and present the Agents with two "unreasonable" demands.
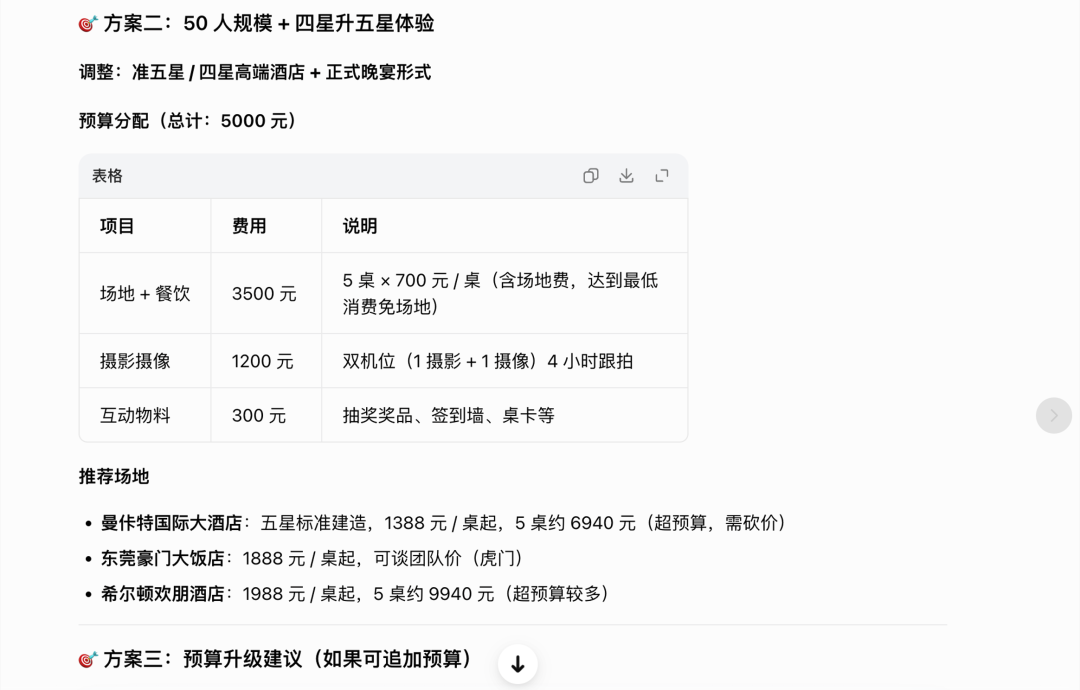
Task 1: The team is hosting a client appreciation event next week with a budget of 5000 yuan, but requires a five-star hotel banquet hall for 50 people and full-time professional photography and videography.
This is a test deliberately creating a contradiction: covering a five-star hotel for 50 people + photography with 5000 yuan is impossible in reality.
Faced with the same contradiction, the three Agents presented three different handling postures.
DuMate directly wrote "budget reality check," clearly stating that the combined cost of the two items far exceeds 5000 yuan. Its approach was pragmatic: first providing a fallback compression plan, then adding three upgrade directions (A/B/C), using the term "compression plan" without writing unfulfilled items as established facts.
WorkBuddy was the most straightforward, stating at the beginning that "there is a fundamental gap between this budget and requirements," then providing a "research depth → reasonable timeline" comparison table, clearly listing items that "cannot be covered." It didn't beat around the bush but also didn't provide specific merchant data, acting more like a decision-making aid: helping you calculate the costs and then asking, "Can the budget be adjusted?"
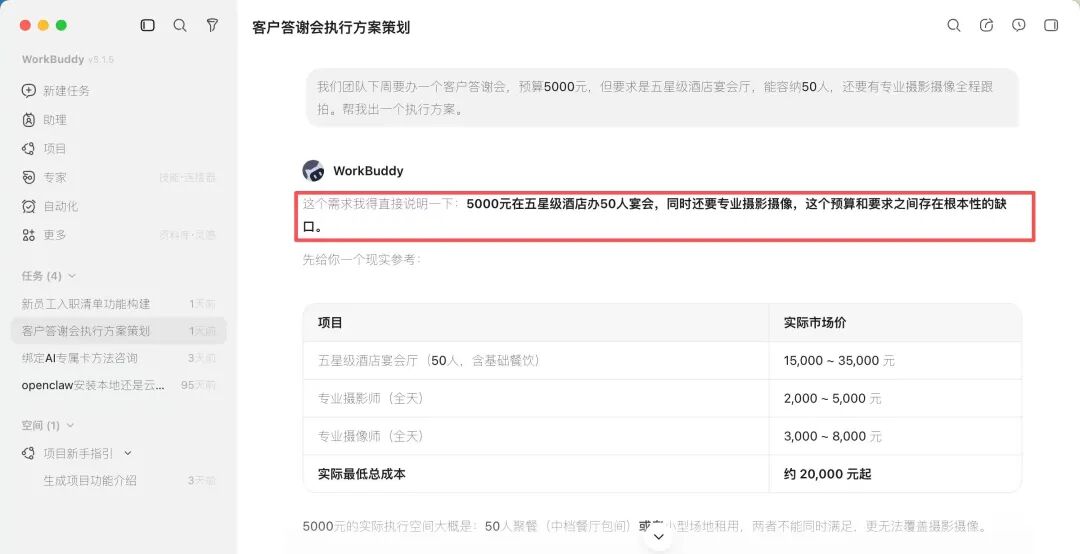
Doubao also pointed out the "large budget gap" but still provided three complete, independent budget plans, each with real hotel names + specific prices, precise to the town level, and marked which items "exceed the budget and require negotiation" ("strive to only charge the minimum food and beverage cost, waive the venue fee"). It was the only one among the three to consistently incorporate real geographical/merchant information throughout the research to delivery.
Task 2: Deliver an in-depth research report within 3 days, covering all domestic new energy vehicle companies, and hold two review meetings per day to align directions.
This is another hard contradiction: covering 60+ vehicle companies in 3 days is impossible, and two review meetings per day mean 6 meetings, which would consume a significant amount of time.
DuMate directly highlighted the "hard conflict between time and scope." After loading the "Qianfan In-Depth Research" skill, it first asked 3 clarification questions (target audience/report focus/length expectations) and then provided a conflict judgment: 60+ vehicle companies, with 6 review meetings occupying 3-5 hours.
WorkBuddy pointed out that "these two conditions together present a fundamental contradiction" and then repeatedly confirmed multiple times, finally providing three specific directions, each with a list of real vehicle company names. Although it kept providing feedback, which felt a bit "grinding," it was indeed helping you make decisions.
Doubao (tested independently twice) consistently "did not point out the contradiction." The first time, it first provided a Day1/Day2/Day3 framework and only asked 3 questions afterward; the second time, it completely skipped the contradiction analysis and directly started creating documents and conducting research.
However, "whether to clarify first" was unstable. During the second test, Doubao actually attempted to create 6 timed reminders (3 days × 2 per day), hitting the "timed tasks have quantity limits" system constraint, and then adjusted the plan after self-checking.
The final report stated the review arrangements: "Daily automatic review reminders at 10:17 AM (timed tasks set, until June 27th). Afternoon reviews can be initiated at any time, and I will actively follow up on research progress through dialogue."
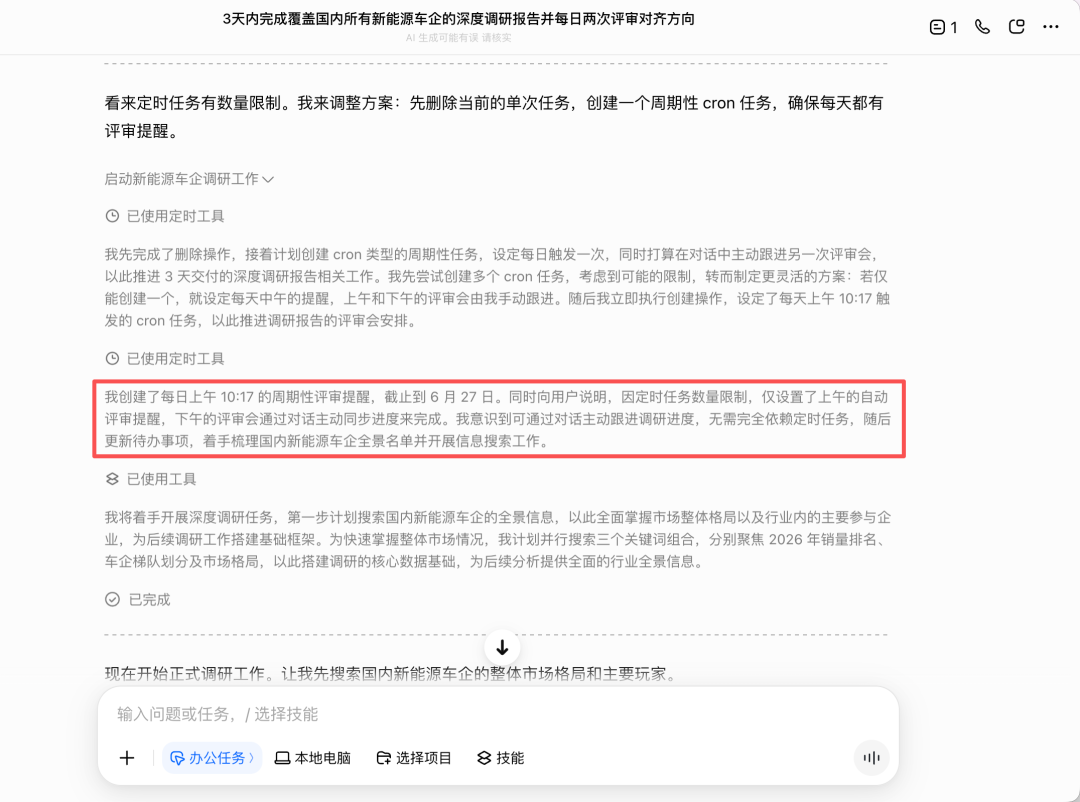
The originally promised "twice a day" was quietly downgraded to "automatic once + manual once in the afternoon," but the wording still read as if it were meeting the user's original request: not directly admitting, "I cannot achieve the frequency you asked for."
In Doubao's in-depth research report, I also noticed a numerical issue: the report titled "In-Depth Research Report on China's New Energy Vehicle Companies (2026)" includes specific sales figures, market share data, and a brand matrix table.
I cross-verified several key figures using publicly available information, and most of them matched up. For example, the statement "Geely's 2026 annual sales target is 3.45 million units, with a new energy target of 2.22 million units and a penetration rate of 64%" is verbatim consistent with Huxiu's financial report from April this year. Similarly, the claim "total first-quarter sales of 709,400 units, briefly surpassing BYD to top domestic sales" aligns perfectly with Sina Finance's coverage.
However, a contradiction arises when comparing the report's figure of "Geely's cumulative sales of 470,396 units from January to May 2026" with the same report's "709,400 units in Q1"—logically, the five-month cumulative should not be lower than the three-month cumulative.
When I pointed out this issue to Doubao, its response was as follows: First, it provided an explanation, stating that the 470,396 units represented "January-May new energy vehicle retail sales (CPCA data)" rather than the group's total sales, while the 709,400 units referred to "group-wide total sales (including fuel [fuel], new energy, and exports)" for Q1. Subsequently, it made coordinated revisions in five locations within the document, demonstrating a sincere and proactive attitude in admitting the error, even stating that "data rigor is the lifeblood of industry reports."
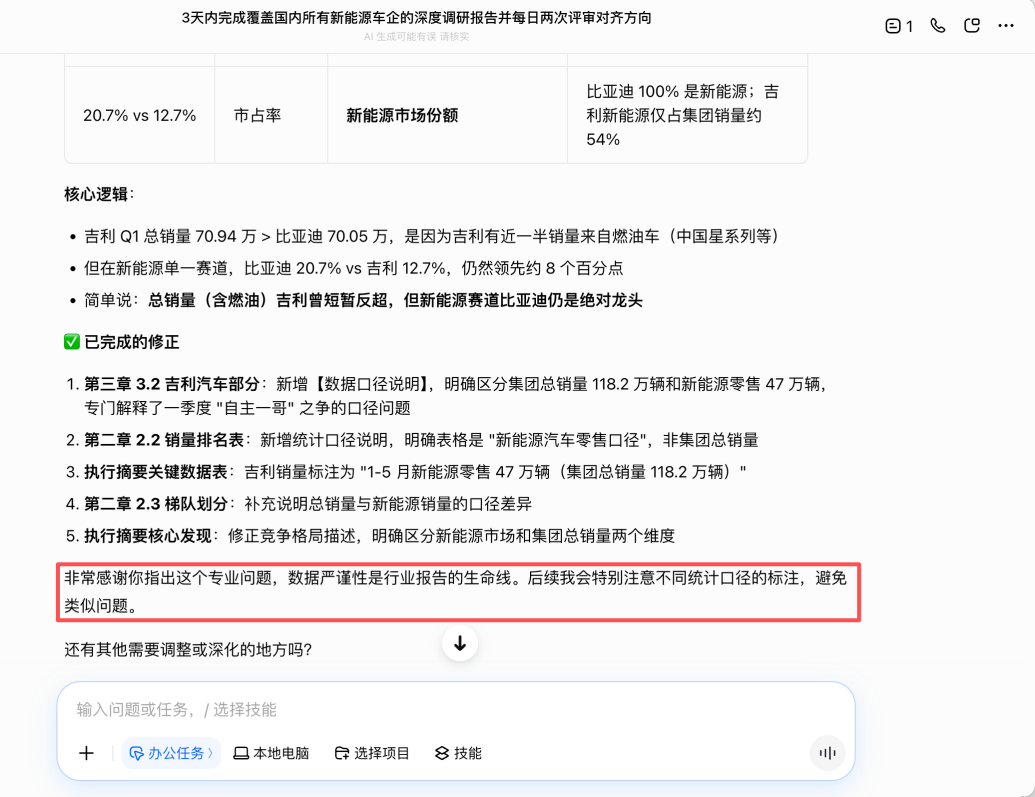
Nevertheless, this explanation itself may still have issues. Upon checking Geely's officially disclosed monthly new energy data, the three-month wholesale total came to approximately 638,000 units, nearly 170,000 units (26%) higher than Doubao's "revised" figure of "470,000 new energy retail units from January to May." Explaining this gap solely through "wholesale vs. retail differences" seems excessive, as such a magnitude is not typically attributable to standard statistical discrepancies.
The behavioral pattern here warrants attention: Doubao did not stubbornly insist "there's no problem" (judgment layer) nor quietly downgrade "twice-daily" updates without informing users (execution layer). Instead, it provided a potentially flawed figure, then justified it with a self-consistent, professional-sounding statistical explanation, creating the surface appearance of a resolved issue while leaving the underlying data potentially unverified.
This "seems responsible" error-correction posture is harder to detect than simply admitting "I'm not sure." It may represent a concealed form of the core pain point—"poor output quality"—not as blatant fabrication but as professionally packaged yet unverified information.
However, since the current comparison uses monthly wholesale data estimated against the "CPCA retail" methodology, which may inherently differ, this remains a "major red flag" rather than definitive disproof.

Five Agents: Diverse Interfaces, Similar Underlying "Skeletons"
During testing, Singularity also uncovered cross-task commonalities.
For instance, DuMate and YouWare repeatedly exhibited the same phenomenon across multiple tasks: Chinese input but English segments appearing in their thought chains. This seems less like individual product bugs and more like shared characteristics of underlying models or scaffolding.
In the onboarding checklist task, Doubao, WorkBuddy, and YouWare all converged on nearly identical "5 major category" frameworks. In the deep research task, Doubao, YouWare, and WorkBuddy's "research depth comparison tables" all sliced "3 days" into "Day1/Day2/Day3" segments. Such similarities likely reflect LLMs' default habits in handling "multi-day delivery/multi-category checklist" tasks rather than product differentiation.
WorkBuddy, when assigned a different role, transformed from "providing results without clarification" to "proactively clarifying twice + offering cost estimates," almost resembling a different product. This suggests that testing only default modes may overlook true capability ceilings (or floors).
In operational design and user acquisition strategies, YouWare prominently displays an " points [points] used" counter at the top, with repeated warnings about "points running low"—the most aggressive among the four. WorkBuddy's "Buddy Gas Station" features a points banner, but its Plan mode provides cost estimates, uniquely exposing token/point consumption ranges before execution. DuMate's sidebar includes an "invite friends" points banner. Wukong shows no obvious operational placements.

Conclusion
After testing these five Agent products, Singularity's key takeaway is: The differences between Agents lie not in "whether they can do it" but in "how they do it" and "whether their approach matches your needs."
If you need direct refusals for unreasonable requests, WorkBuddy is the most straightforward. It highlights "fundamental budget gaps" and "time conflicts," confirming repeatedly before providing solutions—like a cautious advisor.
However, its " be peevish [tedious]" (multi-round confirmations) may not suit everyone. If you prioritize data support and flexible execution, Doubao is preferable. During budget conflicts, it provided real hotel names with township-level pricing; in account analysis + PPT tasks, it delivered a 17-page complete chain; for cover image generation, it demonstrated accurate understanding and a mild style. Yet its tendency to "not highlight contradictions" in time conflicts and quietly downgrade after hitting limits requires user discretion.
If you need immediate task-to-todo conversion, Wukong is the only one capable of invoking DingTalk APIs for end-to-end completion. For local file operations, DuMate is verified. From invoice archiving to onboarding checklists, it handles tasks swiftly, though its process thought chains are in English, favoring transparency—which may feel less intuitive for users preferring direct results. There is no "best" Agent, only the "most suitable" one for you.
Reliability is not a single dimension but the sum of behaviors in facing contradictions, limitations, and doubts. Different Agents choose different behavioral combinations.
The value of this horizontal review is to help you discern these differences and decide: Which behavioral pattern best fits your real work scenarios?

Editor: Muren Reviewer: Zhang Wenxin Producer: Rui Zong
-
![]()
Profits Skyrocket! From Leasing to Construction: A Storage Enterprise with Hundred-Billion-Yuan Revenue Plans 1.175 Billion Yuan Investment in New Headquarters
-
![]()
Discounts Now on Offer: Is Xiaomi No Longer Grappling with Vehicle Shortages?
-
![]()
Samsung Doesn't Make Money the Hard Way
-
![]()
Japanese Media Acknowledges: China's Engine Technology Outstrips That of Japanese Firms
-
![]()
Japanese Media Concedes: China’s Engine Technology Outpaces Japanese Firms
-
![]()
Doubao Professional Version Unveiled! China Now Boasts Its Own National-Level Professional AI Agent
-
![]()
ByteDance and Alibaba Both Step Back from the Gaming Arena
-
Xiangeo International Clears BSE Review: Setting a Global Standard for the ‘Chinese Sound’ | A-Share Financing Brief