OpenAI Gives NVIDIA a ‘Jalapeño’ Surprise: Micron Technology and Others Stand to Gain?
 06/26 2026
06/26 2026
 398
398
As memory prices surge, token prices plummet.
OpenAI's chip has finally made its debut, albeit in a somewhat unexpected manner: Sam Altman, alongside Broadcom President and CEO Hock Tan, jointly unveiled a standard 12-inch wafer, with the chip's name, Jalapeño, inscribed on its base.

Image Source: OpenAI
Jalapeño originally denotes a type of Mexican chili. Initially, the name didn't strike us as significant until we watched an analysis video and it suddenly clicked: the word sounded familiar.
After some thought, I recalled hearing it for the first time as a member of Leitech's MWC reporting team, when I purchased a taco at a snack stall at the MWC venue in Barcelona. Curious about the chili's sour and spicy flavor, I inquired about its type, and the vendor replied—Jalapeño.
Jalapeño is renowned for its spiciness and accessibility (hence its global popularity alongside Spanish culture), and perhaps it also embodies the characteristics of OpenAI's chip: sufficiently powerful performance and excellent cost-effectiveness.
Alright, let's set aside the pleasantries for now and delve deeper into this chip.
To be frank, OpenAI is still keeping the actual parameters, process node, and other details of the Jalapeño under wraps, only vaguely stating that it is currently the strongest in its class and has successfully run GPT-5.3-Codex-Spark in the laboratory.
This model may not be familiar to everyone. In fact, it is a small-scale Codex model specifically trained by OpenAI for real-time programming needs, requiring 'low latency, high concurrency' from the chip rather than absolute performance. Given the ASIC architecture adopted by the Jalapeño, it can be inferred that its performance should be comparable to that of Google's eighth-generation TPU chip.
If we estimate based on the highest-performance TPU 8t (12.6PFLOPS) in the eighth-generation TPU, the theoretical computing power of the Jalapeño might be around 13PFLOPS (just a speculative guess). However, considering the Jalapeño's inference purpose, Leitech speculates that its computing power is more likely to be around 10PFLOPS, as it needs to balance efficiency and power consumption.

Image Source: Google
Considering that it took only 9 months from the announcement of the Jalapeño's development to its successful tape-out, the speed and results are indeed remarkable. However, when we see Hock Tan standing beside Altman, this 'miracle' becomes more understandable. After all, Broadcom is a giant in the ASIC field, allowing OpenAI to 'stand on the shoulders of giants.'
Nevertheless, compared to the development speed, Leitech is more intrigued by whether OpenAI is truly prepared for mass production. From the information disclosed so far, it is highly likely that TSMC will be responsible for producing the Jalapeño.
As we all know, TSMC currently has limited spare capacity. Deploying a data center sufficient to support OpenAI's computing power needs is not feasible in the short term, at least. Therefore, one should view with skepticism the claims by some media that the Jalapeño will soon surpass NVIDIA.
Even according to OpenAI's plan, the deployment cycle of the Jalapeño will extend until 2029, with the ultimate goal of building a 10GW-level computing power center.
From Microsoft's Azure Maia 200 to Google's eighth-generation TPU, from Amazon's Trainium3 to Alibaba Cloud's Zhenwu M890, behind these products are cloud service leaders who once competed with NVIDIA for graphics cards. Now, they are all developing their own chips, and now even OpenAI, NVIDIA's 'closest ally,' has unveiled the Jalapeño.

Image Source: Alibaba Cloud
Betrayed by all? Not quite, but there must be a sense of confusion and isolation.
This brings us back to the question: Why does everyone want to break free from NVIDIA's hardware ecosystem and build their own computing power ecosystem? The answer, of course, is cost.
Specifically, Xiaolei has already elaborated on this in detail in the article 'Google Starts Selling TPUs: Big Players Aim to Produce 'Low-Cost Tokens' with AI Chips' published a few days ago. Interested readers can take a look.
For those who don't want to delve into it, just remember this: NVIDIA holds the cards (GPU + CUDA) and commands the AI giants, who have 'suffered under NVIDIA for too long.'
In fact, the conflict between OpenAI and NVIDIA didn't just arise now. If you recall, in September last year, there were widespread rumors in the market that NVIDIA would make a massive strategic investment in OpenAI, possibly amounting to $100 billion.
Let's do the math: wasn't that exactly nine months ago? In other words, the Jalapeño might have already entered the substantive launch phase at that time. From this perspective, the evaluations of Altman by OpenAI's former executives were not entirely off the mark: he is politically astute, prioritizes commercial interests, and is obsessed with absolute control.

Image Source: Wikipedia
While negotiating the largest investment plan in history, they were planning to undercut the other party. Although it's hard to measure such commercial behavior by 'morality,' NVIDIA must feel betrayed, which is why the $100 billion investment plan has made little progress after months of negotiations.
It wasn't until the market became uneasy about the future of the AI industry due to the crisis in their cooperation that both parties, considering the future market, chose to finalize a $30 billion investment, with NVIDIA only participating as one of the three major investors and not even the largest contributor (Amazon invested $50 billion).
After this investment was finalized, Jensen Huang publicly stated, 'This might be the last time.' Clearly, NVIDIA might have already received news from the supply chain that OpenAI was developing the Jalapeño and that it was close to or already in the tape-out phase.
The money they invest might become a weapon used against them in the future. This taste must be unpleasant. However, NVIDIA and OpenAI are too deeply intertwined. Both parties need each other to continue the 'AI' show, so they are in a state where 'neither can do without the other.'
Even with the Jalapeño, this remains true for OpenAI. In fact, one could say: as long as AI models like Claude, DeepSeek, and Gemini exist, OpenAI cannot do without NVIDIA because it still needs the most powerful computing cards to build the most powerful computing matrix for training the 'strongest' models.
However, beyond that, all cloud service providers will consciously reduce their reliance on NVIDIA's computing cards, both for the sake of profit and to ensure that the future of AI is not controlled by a single vendor.
From OpenAI to Alibaba Cloud, everyone is experimenting with ASIC chips. Some readers might ask: What exactly is ASIC? Is the AI industry abandoning GPUs?
Simply put, ASIC stands for 'Application-Specific Integrated Circuit.' It is not a fixed structure but is designed to be fully customized according to a company's needs, and this chip is only suitable for specific scenarios. Therefore, ASIC chips are far less flexible than general-purpose chips like GPUs and CPUs. When the model architecture undergoes significant changes, companies often need to design new ASIC chips to ensure efficiency.
This is also why everyone cannot do without NVIDIA, as only general-purpose chips like GPUs can simultaneously support multiple models with different architectures while maintaining high efficiency. ASICs, on the other hand, are more like 'specialized tools' tailored to the model's needs once you have a deep understanding of them.
In fact, the development cost and time for each generation of ASIC chips are not low. OpenAI's nine months is already considered a miracle in the semiconductor industry. Nevertheless, it is cost-effective for cloud service providers because they can absorb large shipments themselves, spread the cost per chip through economies of scale, and factor in later maintenance costs, ultimately making a profit.
Interestingly, while writing this article, semiconductor stocks were experiencing a rebound after a continuous plunge, giving many investors a 'psychological rollercoaster' ride. The plunge a few days ago is not hard to understand. The continuous surge had already pushed the stock prices of companies like Micron to unprecedented levels. At the same time, Micron announced a temporary halt to its HBM memory capacity upgrade plan, redirecting some capacity back to consumer-grade product lines like GDDR.
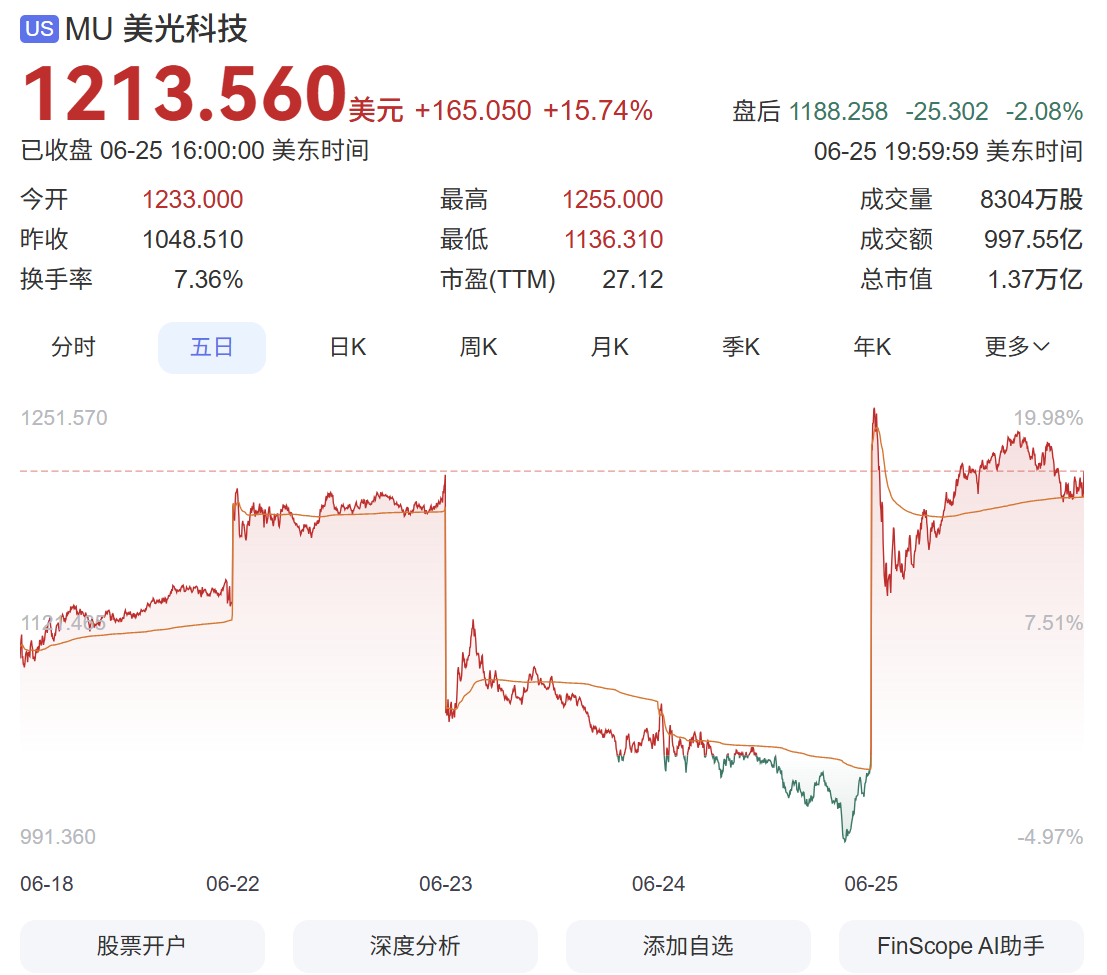
Image Source: Baidu Stocks
This led some investors to believe that the growth myth surrounding HBM was about to collapse, causing expectations for the future of AI industry computing hardware to fall, and combined with other factors, ultimately leading to a collective plunge in semiconductor companies' stock prices.
Then, Micron's earnings report caused the plunging stock prices to 'soar again.'
In fact, if you understand the current state of AI chips, you probably wouldn't doubt the future revenue of memory manufacturers (this is just an analysis and does not constitute investment advice). Because whether it's NVIDIA's computing cards or the ASIC chips developed by various companies, as long as they are used in inference scenarios requiring high concurrency, high throughput, and low latency, HBM memory is almost the only choice at present.
This situation will continue until breakthrough technologies emerge, such as the complete maturation of the Wafer-Scale architecture or the full realization of on-chip large SRAM designs (integrating large-capacity high-speed memory into the chip). Currently, although these technologies have made some progress, they are still some time away from full maturity.
If anything, the most likely 'black swan event' at present is if an AI company suddenly announces the development of a new algorithm that significantly reduces the storage requirements of AI models. For example, Google's recently disclosed TurboQuant is said to reduce inference memory requirements by more than six times. Although the conclusions of its paper are still controversial, if this technology matures, it will directly impact the demand for HBM.
In addition, DeepSeek's MoE routing optimization, MLA route, and new model structures developed for specific memory technologies (such as hybrid scheduling of large and small models) are all foreseeable directions. This is why memory companies don't particularly like DeepSeek—because they are truly 'disruptive.'
However, at least for the next two to three years, the shortage of memory is unlikely to be alleviated.
On the contrary, as chip manufacturers are all developing their own ASIC chips (which often require more than 128GB of HBM memory per chip), the supply and demand for HBM will become even tighter.
In the coming years, the AI industry is likely to become even more 'heated,' as the current investment levels have made failure unaffordable for everyone.
Therefore, NVIDIA's GPU myth is likely to continue, the HBM shortage cycle is far from over, and the ASIC war has only just begun. What consumers will ultimately see is likely to be increasingly cheaper AI services on one hand, but increasingly expensive graphics cards, memory, SSDs, and electronic products on the other.
In this light, the name Jalapeño is truly apt: it's not as overwhelming as the Ghost Pepper, but it's enough to make the entire AI chip market feel the heat.
AI companies aim to make tokens cheaper. But before that happens, it might be the entire semiconductor supply chain that catches fire first.
OpenAI, NVIDIA, Google, Alibaba Cloud, ASIC
Source: Leitech
The images in this article come from the 123RF licensed image library. Source: Leitech
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






