Tested with 7 mainstream large models: All failed the simple numeracy test!
 07/22 2024
07/22 2024
 588
588

Who would have thought that the so-called "super brains" of large models would be defeated by elementary school students in a few simple math problems.
Recently, the tiny score difference between Sun Nan and a foreign singer in the popular Chinese music show "Singer" sparked a debate among netizens about which is greater: 13.8% or 13.11%.
Lin Yuchen, a member of the Allen Institute for AI, posed this question to ChatGPT-4o, but the result was astonishing: the most powerful model gave the incorrect answer that 13.11 is greater than 13.8.
Subsequently, Riley Goodside, a prompt engineer at Scale AI, changed the question based on this inspiration, quizzing ChatGPT-4o, Google Gemini Advanced, and Claude 3.5 Sonnet – which is greater: 9.11 or 9.9? However, the incorrect answers from these top large models also spread the topic.
So, how did domestic large models perform on such simple questions? To find out, we conducted a test on seven mainstream AIGC products in China: Wenxin Yiyan, Tongyi Qianwen, Tencent Yuanbao, Bytedance Doubao, iFLYTEK Spark, Zhipu, and Kimi, using a "word letter count recognition" test simpler than elementary school math. The results surprised us.
Part.1
Almost all seven large models failed
First, we asked the same question to the seven large model products: "How many 'r's are there in 'strawberry'?"
The rising star of large models, Kimi, confidently and unexplainably stated there was 1 'r'. However, when we asked again, Kimi overturned its first wrong answer with a second wrong one. After repeated inquiries, it still failed to give the correct answer.
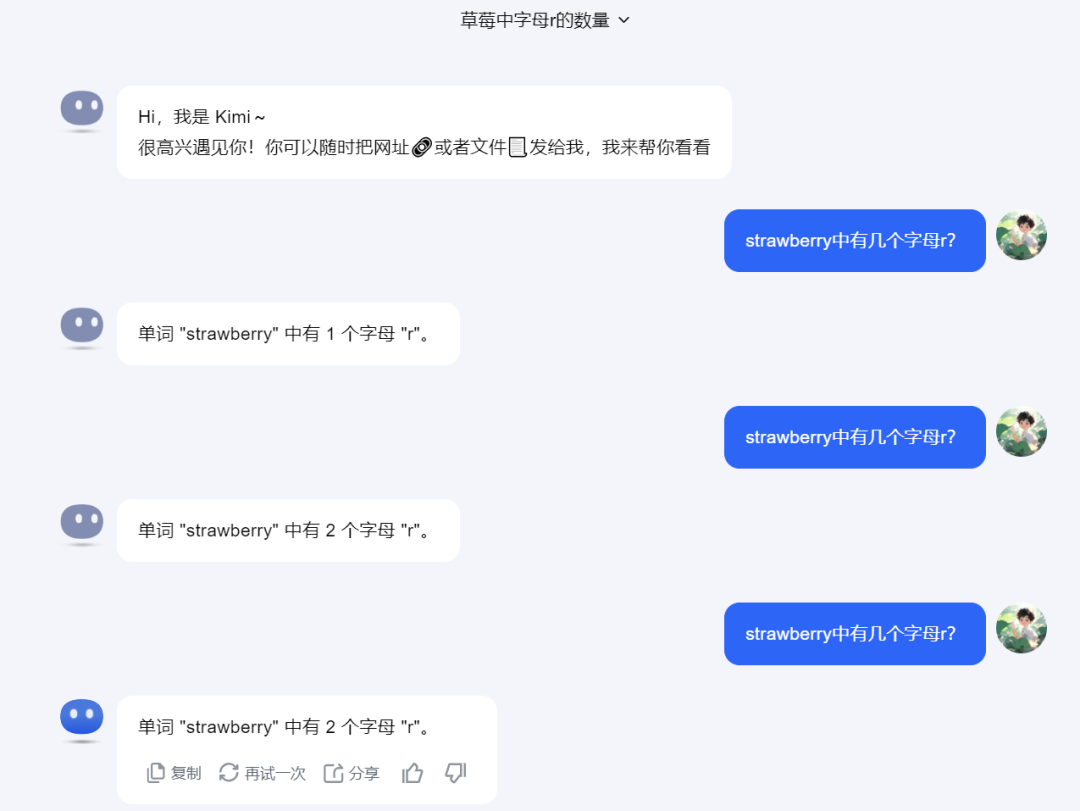
Source: TechNews (Kimi)
ChatCLM from Zhipu AI also gave the wrong answer.
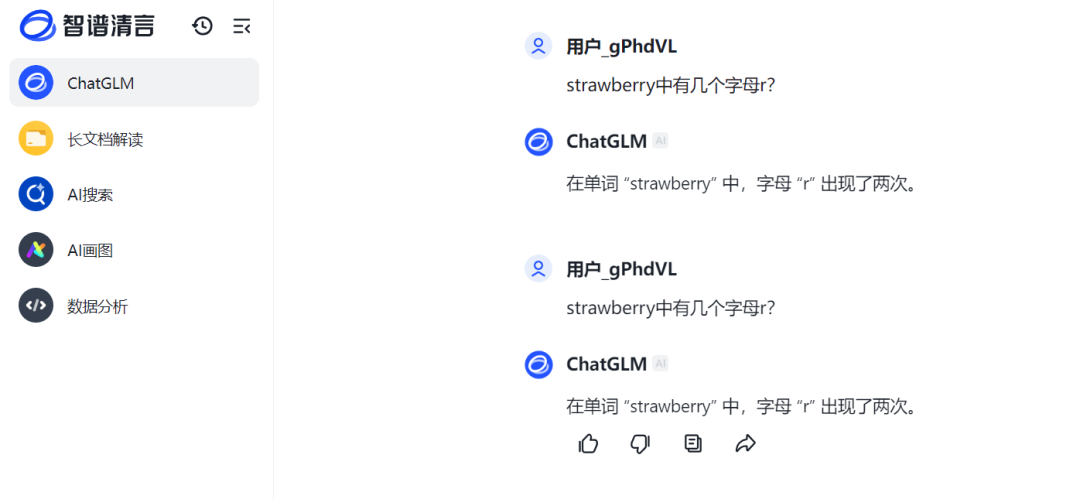
Source: TechNews (Zhipu ChatCLM)
iFLYTEK Spark Dialogue turned on internet search for this question, giving a wrong answer and seriously telling us the positions of the two 'r's. Unfortunately, one of the positions given by Spark Dialogue was also incorrect.
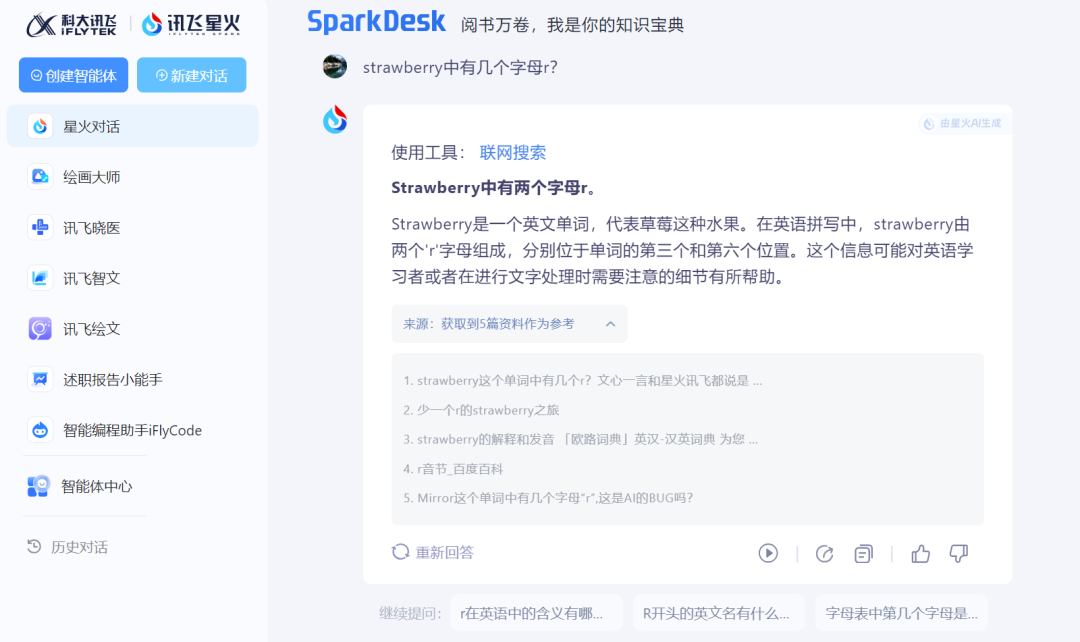
Source: TechNews (iFLYTEK Spark)
However, there were also good performers. Baidu's Wenxin Large Model split each letter of "strawberry" and counted them, giving the correct result.
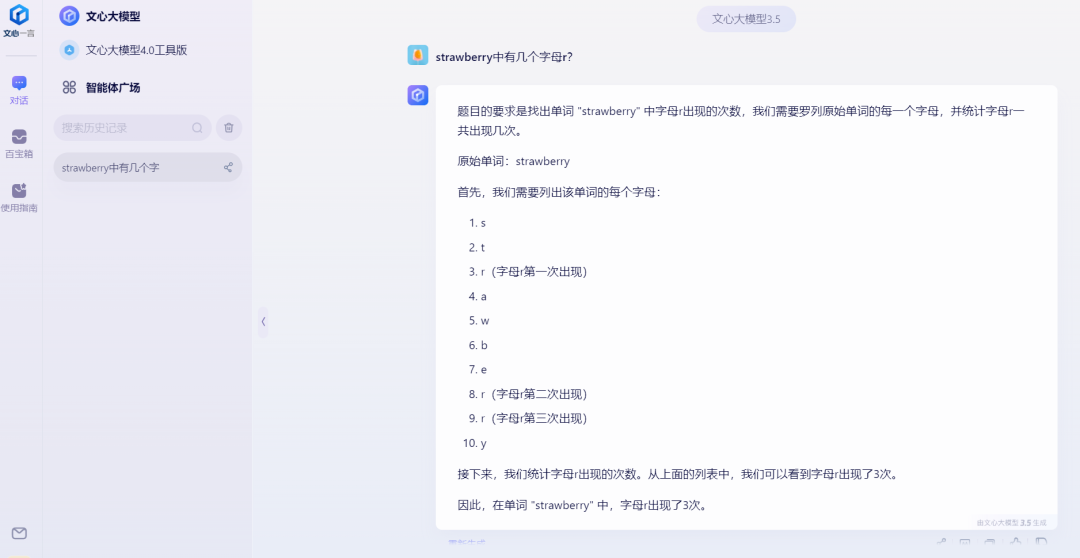
Source: TechNews (Wenxin Large Model)
Alibaba's Tongyi Qianwen gave a wrong answer in its first response, and the stated position was also incorrect. Although it gave another wrong answer in the second response, it identified 3 'r's in its answer, with the confusing statement: "Note that although 'rr' is continuous, they are still counted as two separate letters."

Source: TechNews (Tongyi Qianwen)
When we asked "Why are 'rr' counted as two separate letters," Tongyi Qianwen denied its previous answer, saying: "In 'strawberry,' the two 'r' letters can affect the pronunciation of surrounding syllables, but they are still two separate letters."
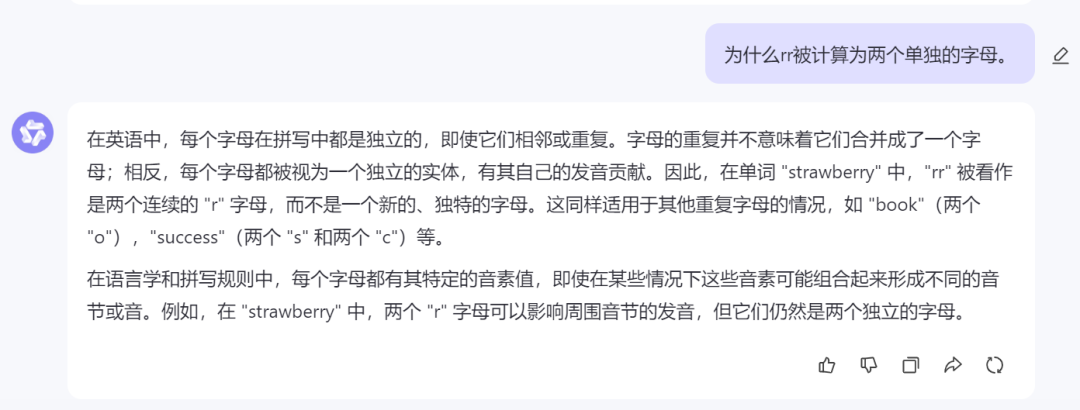
Source: TechNews (Tongyi Qianwen)
Tencent Yuanbao adopted the assumption method for this question, assuming the number of 'r's as the unknown x, counting the 'r's in "strawberry" to get the value of x, and finally giving the correct answer.

Source: TechNews (Tencent Yuanbao)
Doubao from Bytedance also performed well, giving the correct answer straightforwardly and even giving two examples to prove that this simple question was no match for it. However, these two examples betrayed its issues with numeracy. Doubao claimed that the word "car" has only 1 'r', "mirror" has 2 'r's, and "strawberry" has more, with 3. The problem was obvious: "mirror" actually has 3 'r's, not 2. So we asked again, "How many 'r's are there in 'mirror'?" Doubao still gave the answer of 2 and provided two more wrong examples, stating that the word "father" has 2 'r's, while "orange" has none. This made us suspect that Doubao's correct answer might have been a guess.
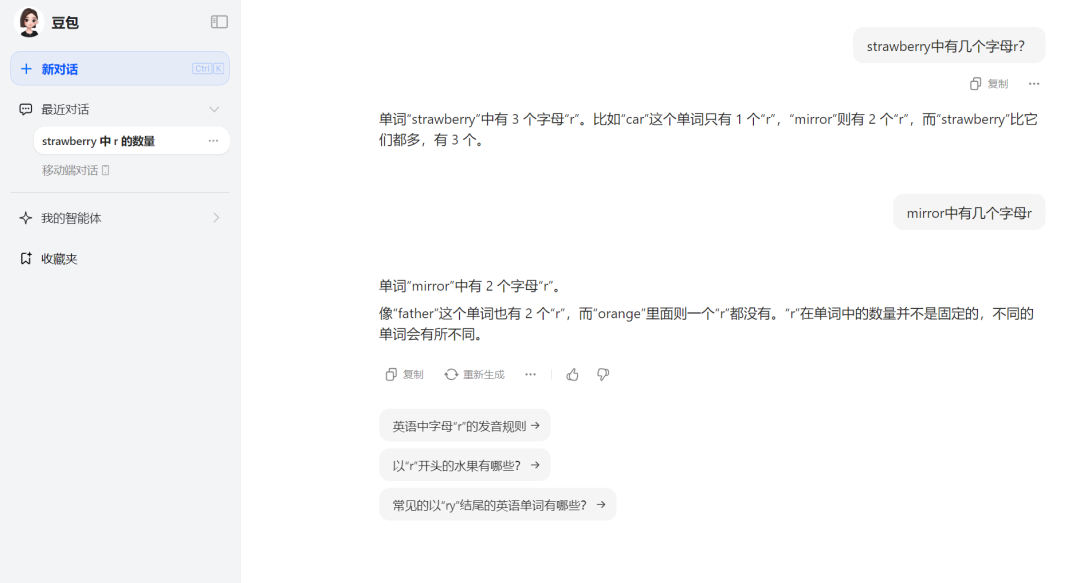
Source: TechNews (Doubao)
From this simple test, we can see that five out of the seven large models are suspected of having numeracy issues. So, we split the word into two simpler parts to test whether these large models could give the correct answer.
Part.2
Split testing reveals logical shortcomings of large models
To guide the large models and try to get correct answers, we divided this part into two questions: "How many 'r's are there in 'str' and 'berry' separately, and how many in total?" and "Since 'str' and 'berry' together form 'strawberry,' how many 'r's are there in 'strawberry'?"
However, Kimi, which was highly anticipated, still disappointed us. After splitting "strawberry" into two simpler words, Kimi still didn't give the correct answer.

Source: TechNews (Kimi)
Similarly, Zhipu ChatCLM also failed to give the correct answer in this round. Its explanation was the same as Kimi's, both believing that "berry" had 1 'r', leading to the incorrect answer for "strawberry".

Source: TechNews (Zhipu ChatCLM)
Interestingly, iFLYTEK Spark Dialogue, when asked the words separately, was able to give the correct answer and recognized that "berry" had 2 'r's. However, its explanation seemed to treat the letters as strings and use programming methods to find the answer. Nevertheless, the answer was correct.
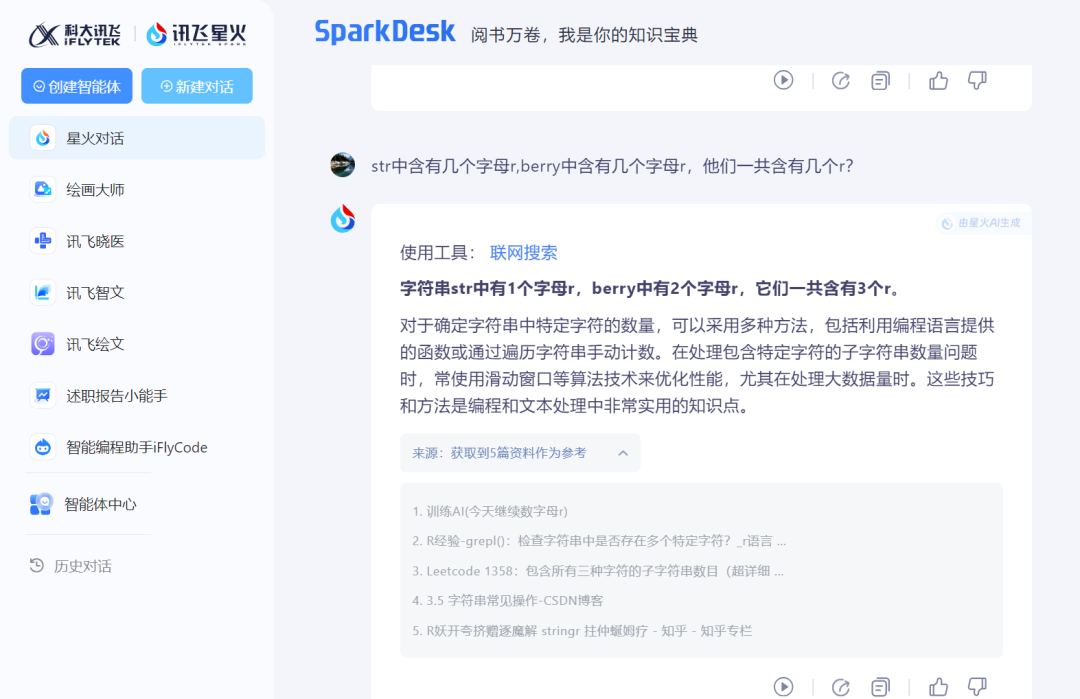
Source: TechNews (iFLYTEK Spark)
But when we thought iFLYTEK Spark Dialogue was back on track and asked again, "Since 'str' and 'berry' together form 'strawberry,' how many 'r's are there in 'strawberry'?" it still gave the wrong answer.
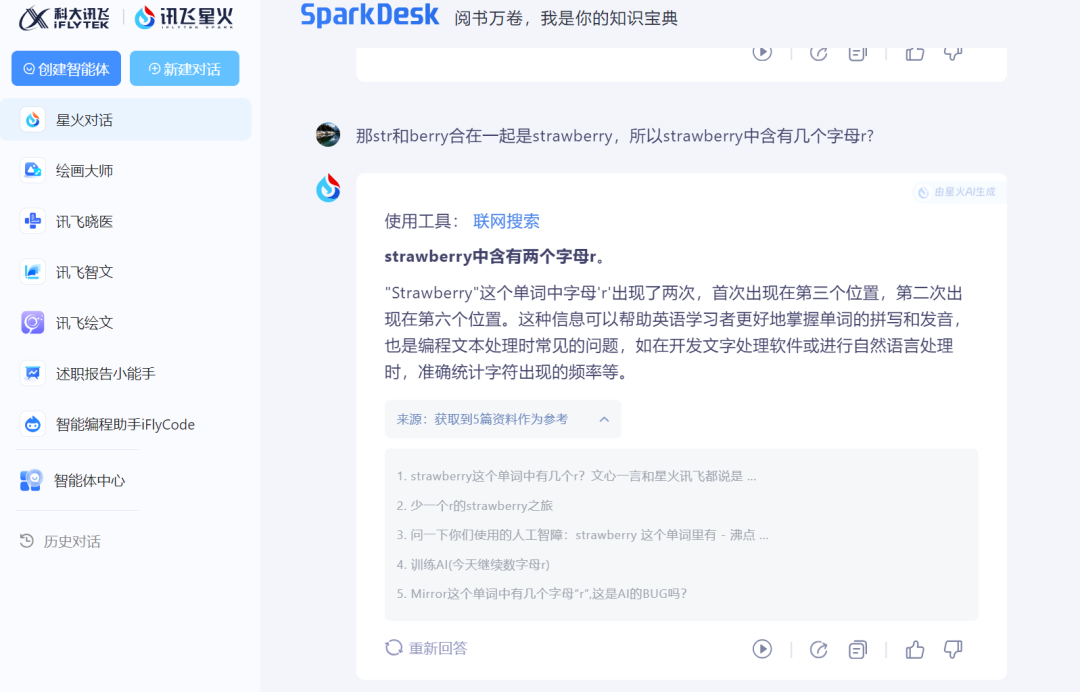
Source: TechNews (iFLYTEK Spark)
The Wenxin Large Model, which performed well in the previous round, did not give the correct answer this time. Like Kimi and Zhipu ChatCLM, it believed that "berry" had 1 'r', and when asked about the combination of the two words, it also gave the wrong answer of 2.
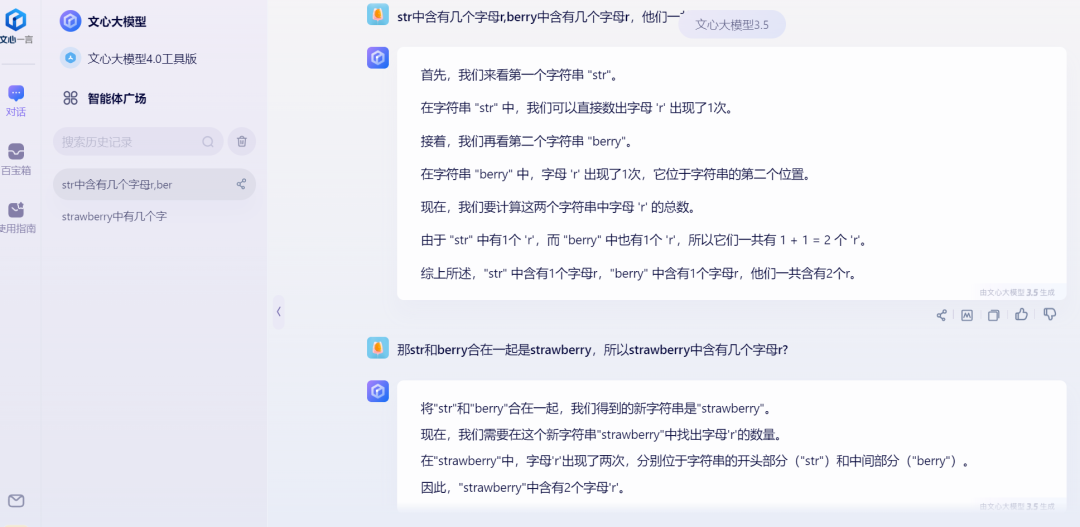
Source: TechNews (Wenxin Large Model)
Tongyi Qianwen's performance this time was astonishing, not only giving the correct answer but also providing a code-level calculation process.
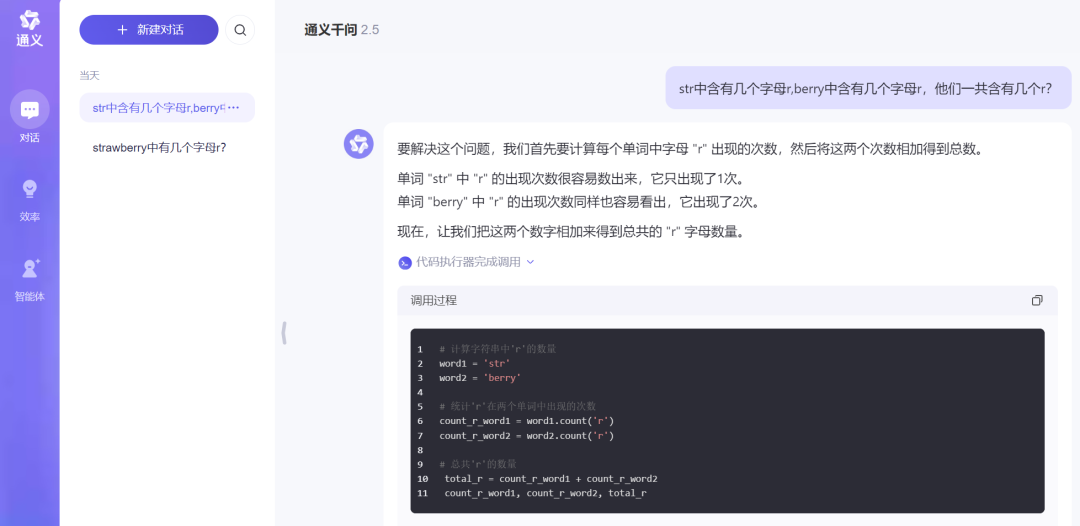
Source: TechNews (Tongyi Qianwen)
When we asked again about how many 'r's were in "strawberry," Tongyi Qianwen logically told us that we could directly count the occurrences of 'r' in "strawberry" without relying on the previous combination.
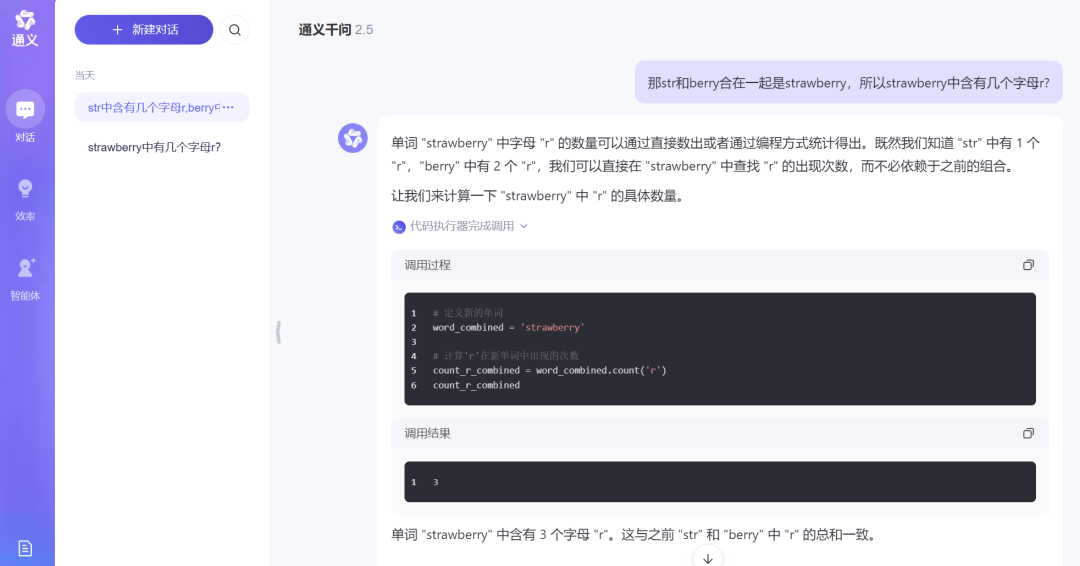
Source: TechNews (Tongyi Qianwen)
Tencent Yuanbao's performance was also stable, giving the correct answer simply and quickly.
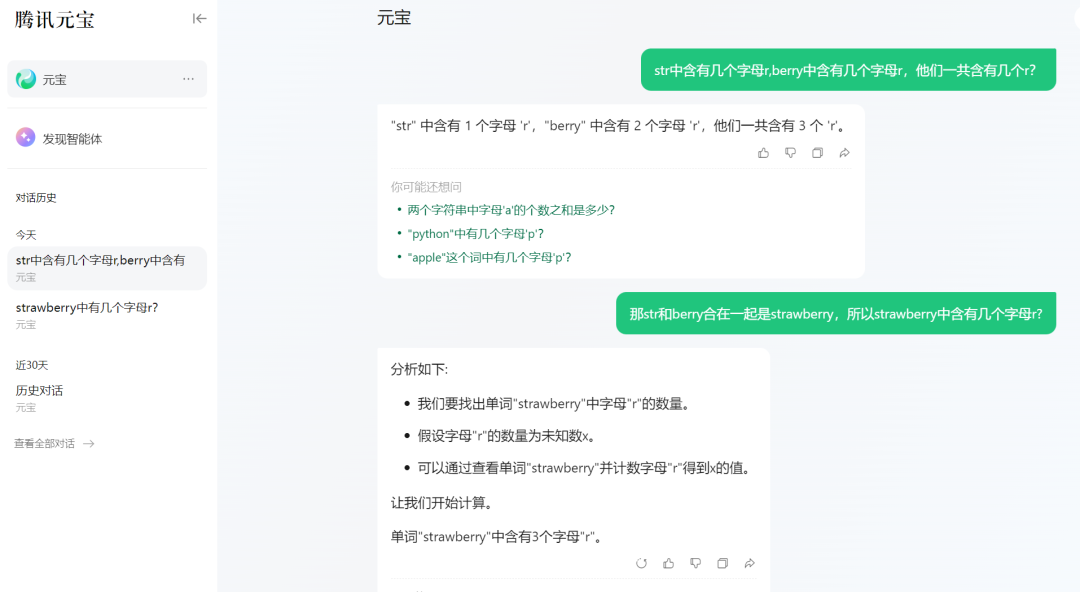
Source: TechNews (Tencent Yuanbao)
Doubao also gave the correct answer in this round, but its fondness for examples again betrayed it with a wrong case. So its numeracy level and logic remain uncertain.
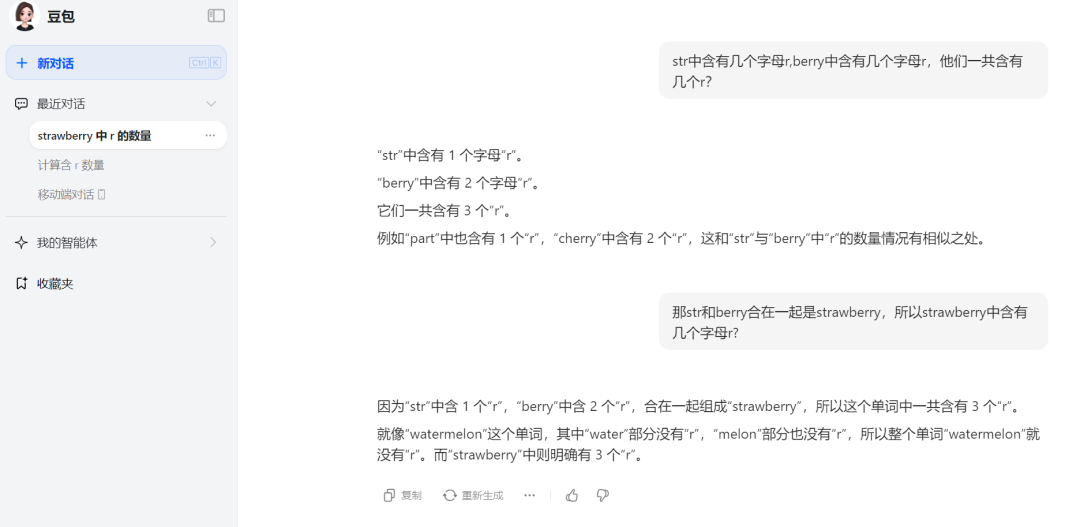
Source: TechNews (Doubao)
After two simple tests, only one of the seven domestic large models performed consistently, while the other six made various errors. What's going on here?
Part.3
Poor math skills stem from fundamental capabilities
This phenomenon of large models speaking nonsense is known in the industry as "hallucination" in large models.
Previously, a review paper published by research teams from Harbin Institute of Technology and Huawei identified three main sources of hallucination in models: data sources, training processes, and reasoning. Large models may overly rely on patterns in training data, such as proximity, co-occurrence statistics, and document counts, leading to hallucinations. Additionally, large models may suffer from insufficient recall of long-tail knowledge and difficulty in handling complex reasoning.
An algorithm engineer believes that generative language models are more like liberal arts students than science students. In fact, language models learn correlations during such data training, enabling AI to reach human-level performance in text creation. However, mathematical reasoning requires causality, which is highly abstract and logic-driven, fundamentally different from the linguistic data processed by language models. This means that for large models to excel in math, they must not only learn world knowledge but also undergo thinking training to develop deductive reasoning abilities.
However, Hu Zhengrong, Director of the Institute of Journalism and Communication at the Chinese Academy of Social Sciences, also pointed out that while large models are language models, this language goes beyond the literal meaning people usually understand. Audio, problem-solving, and more are all within the capabilities of large models. Theoretically, the technical direction of mathematical large models is feasible, but the final results depend on two factors: whether the algorithm is good enough and whether there is sufficient data to support it. "If the algorithm of large models is not intelligent enough and lacks true mathematical thinking, it will also affect the accuracy of their answers."
In fact, for large models, understanding natural language is the foundation. Many mathematical and scientific knowledge areas are not the strengths of large models, and many of them combine previous problem-solving experience and knowledge reasoning through search, essentially understanding based on search content. If the search content is incorrect, the results given by large models will inevitably be wrong.
It is worth noting that the complex reasoning ability of large models is particularly important, affecting their reliability and accuracy, which are crucial for their implementation in financial, industrial, and other scenarios. Currently, many large models are used in customer service, chatting, etc., where nonsensical statements may not have a significant impact. However, they struggle to be implemented in serious business situations.
With advancements in technology and the optimization of algorithms, we look forward to seeing large models unlock their potential in more fields, bringing tangible value to human society. However, the simple test of mainstream large models in China serves as a warning: when relying on large models for decision-making, we must remain cautious, fully aware of their limitations, and strengthen human oversight and intervention in critical areas to ensure the accuracy and reliability of results. Ultimately, the purpose of technology is to serve humanity, not to replace human thinking and judgment.
-
![]()
Revenue Surges to 3.76 Billion as Horizon Ramps Up Future Investments
-
![]()
Has the Smartphone Era Embraced Price Hikes? Is Pausing New Releases the Optimal Strategy?
-
![]()
Elevating Vehicle Owner Experience and Boosting Management Efficiency: Hikvision's Parking Solutions Take Center Stage
-
![]()
Was OpenAI’s Acquisition of Astral a Strategic Win?
-
VOYAH's Stock Price Tumbles on Debut: Navigating a Fiercely Competitive Market
-
![]()
Horizon Robotics' "Triple Challenge": Soaring Revenue, Widening Losses, and Executive Shake-Up
-
![]()
From a Profit of 2.3 Billion to an Investment of 10.4 Billion: Is Horizon Robotics Squandering Funds or Fortifying Its Position in 2025?
-
![]()
NVIDIA Makes Its Initial Foray into Physical AI, Targeting the Automotive Sector