DeepSeek Frenzy: Nine Charts Unraveling the Transformation of the AI Computing Market
 02/18 2025
02/18 2025
 690
690
The DeepSeek craze is poised to bring significant shifts in three key segments: pre-training, post-training (fine-tuning), and inference.
Amidst the DeepSeek frenzy, the AI computing market is anticipated to undergo substantial changes by 2025.
Industry observers note that, contrary to initial speculations upon DeepSeek's emergence that its algorithmic optimizations might decrease demand in the AI computing market, after several weeks of development, the demand for computing power has witnessed a rapid short-term surge.
"In the past two weeks, the number of clients inquiring about purchasing AI servers capable of fully running the 671B DeepSeek R1 model has surged dramatically." On February 13, at the event where IDC and Inspur Information jointly released the "2025 China AI Computing Power Development Assessment Report" (hereinafter referred to as the "Report"), Liu Jun, Senior Vice President of Inspur Information, told Digital Frontline.
In this "Report," market analysis firm IDC and AI computing infrastructure giant Inspur Information provide an in-depth exploration of the changes instigated by DeepSeek in the AI computing market, the current market landscape, and share important trends for the AI computing market's development this year.
01
How will the AI computing market evolve by 2025 amidst the DeepSeek craze?
DeepSeek is a catalyst rejuvenating the market.
Consumer enthusiasm is high, and even among the elderly and children, many are aware of DeepSeek. B2B and G2B application explorations have significantly accelerated, with new waves of enterprises and institutions announcing their integration with DeepSeek daily.
The demand for computing power has soared in the short term. In the first week after the Spring Festival, domestic and foreign chip manufacturers intensified their adaptation efforts. According to industry insiders, adaptation on the inference side will be completed first, while the training side will take some time. Server manufacturers have also received numerous inquiries and purchase orders recently.
In the medium to long term, multiple industry insiders told Digital Frontline that this DeepSeek frenzy is expected to bring about substantial changes in the three key segments of pre-training, post-training (fine-tuning), and inference, propelling further development of the AI computing market.
On the pre-training front, there was a wave of pessimism last year as the Scaling Law was suspected of being on the verge of failure, and some large model enterprises gradually abandoned pre-training. However, with the DeepSeek paradigm taking effect, this trend is about to reverse, and some players may regain confidence to return to the battlefield.
"If DeepSeek uses algorithm optimizations to create a model with 10,000 cards that rivals the performance of a model trained with 100,000 cards, people will wonder what could be trained with 100,000 cards using DeepSeek's engineering model and technical architecture," said Zhou Zhengang, Vice President of IDC China. This serves as an incentive for all large model players globally.
On February 13, Sam Altman, CEO of OpenAI, announced on social platform X that OpenAI would launch a model named GPT-5 in the coming months, which will integrate a substantial amount of OpenAI's technologies. A few days later, on February 18, Musk officially released the Grok 3 large model.
On the post-training side, the efficiency improvements brought about by DeepSeek are strengthening this market. The "Report" shows that the Scaling Law is currently expanding from pre-training to post-training and inference stages. More computing power investments based on algorithmic innovations such as reinforcement learning and chain-of-thought can further significantly enhance the deep thinking capabilities of large models.
"On Hugging Face, there have been new versions fine-tuned and distilled based on DeepSeek emerging daily recently," Zhou Zhengang illustrated, noting that this will greatly boost the entire AI computing market.
The inference side is considered a market with immense potential in the industry. "DeepSeek is akin to the Watt moment. After Watt improved the steam engine, it achieved a stable power output, enabling the steam engine to enter various industries," said an industry insider. "Large models are like steam engines that, after being improved, can enter various industries."
"DeepSeek has ignited the enthusiasm of enterprise customers for deploying and integrating large models within their businesses. After experiencing the self-trial PoC stage, customers will consider how to achieve more batched deployments and applications in business scenarios," Liu Jun told Digital Frontline. They expect that the subsequent round of inference computing power procurement demand will be larger and last longer than this round.
The "Report" also summarizes this – based on the Jevons paradox phenomenon, the improvement in algorithm efficiency brought about by DeepSeek has not suppressed the demand for computing power. Instead, with the addition of more users and scenarios, it promotes the popularization and application of large models, reconstructs industrial innovation paradigms, and drives the construction of data center, edge, and end-side computing power.
Data shows that the scale of China's AI computing power market reached $19 billion in 2024 and is expected to reach $25.9 billion in 2025, with a year-on-year growth rate of 36.2%. It will further increase to $55.2 billion by 2028.
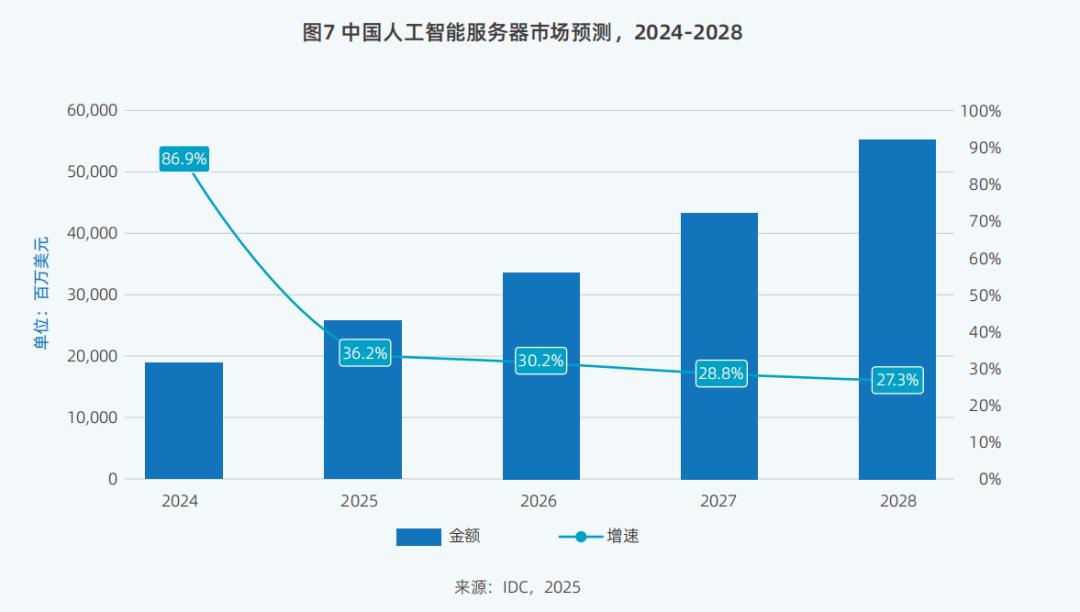
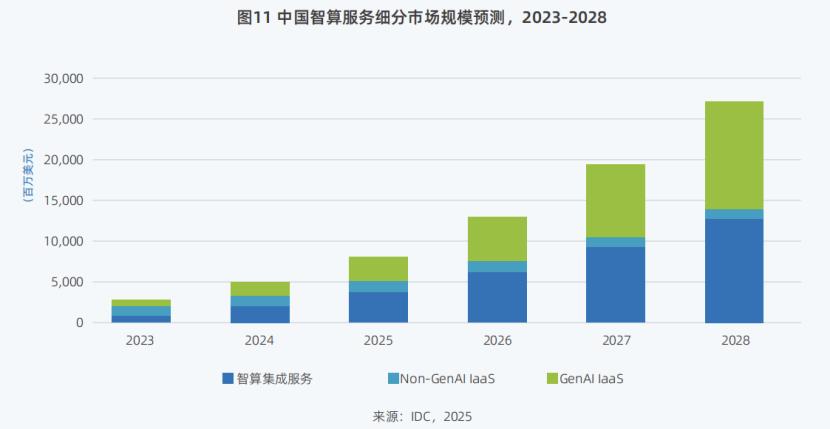
The AI computing services market will also grow rapidly. In 2024, the overall scale of China's AI computing services market reached $5 billion and is expected to increase to $26.691 billion by 2028, with a five-year compound annual growth rate of 57.3% from 2023 to 2028.
Among them, the AI computing integrated services market (i.e., the privatized deployment market) and the GenAI IaaS market are two important incremental markets in the future, with five-year compound annual growth rates reaching 73% and 79.8%, respectively. It is estimated that by 2028, the market share of AI computing integrated services will reach 47%, and the market share of GenAI IaaS will reach 48%.
02
From Quantity Pursuit to a More Efficient System
Another key point in the "Report" that deserves the industry's attention is that to address the issues of insufficient high-performance computing power supply and low computing power utilization during the deployment of large models, it is necessary not only to "expand capacity" but also to "increase efficiency".
Expanding capacity is straightforward, i.e., increasing the supply of computing power. On this front, last year, there was a wave of enthusiasm for AI computing in the industry, with high enthusiasm for the construction of AI computing centers across the nation, resulting in many large AI computing orders. According to incomplete statistics from Digital Frontline, there were over 460 AI computing center-related projects in the public bidding market in 2024, with at least 62 orders exceeding 100 million yuan.
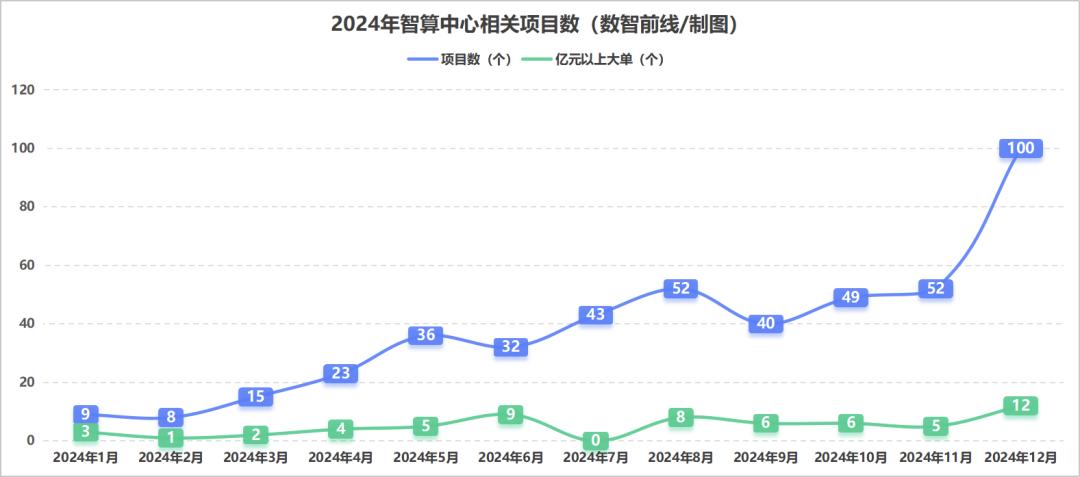
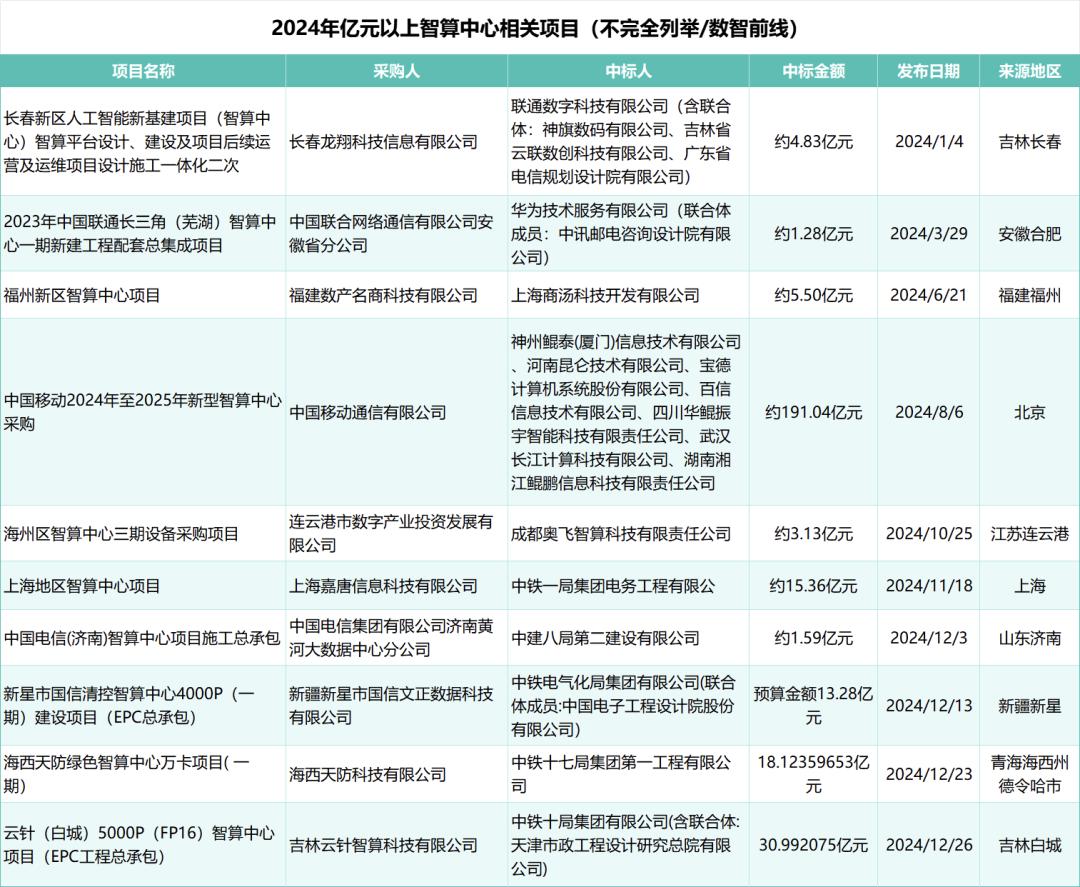
From a market-wide perspective, the "Report" predicts that from 2023 to 2028, the five-year compound annual growth rates of China's intelligent computing power scale and general computing power scale will reach 46.2% and 18.8%, respectively, significantly higher than the previously expected values of 33.9% and 16.6%.
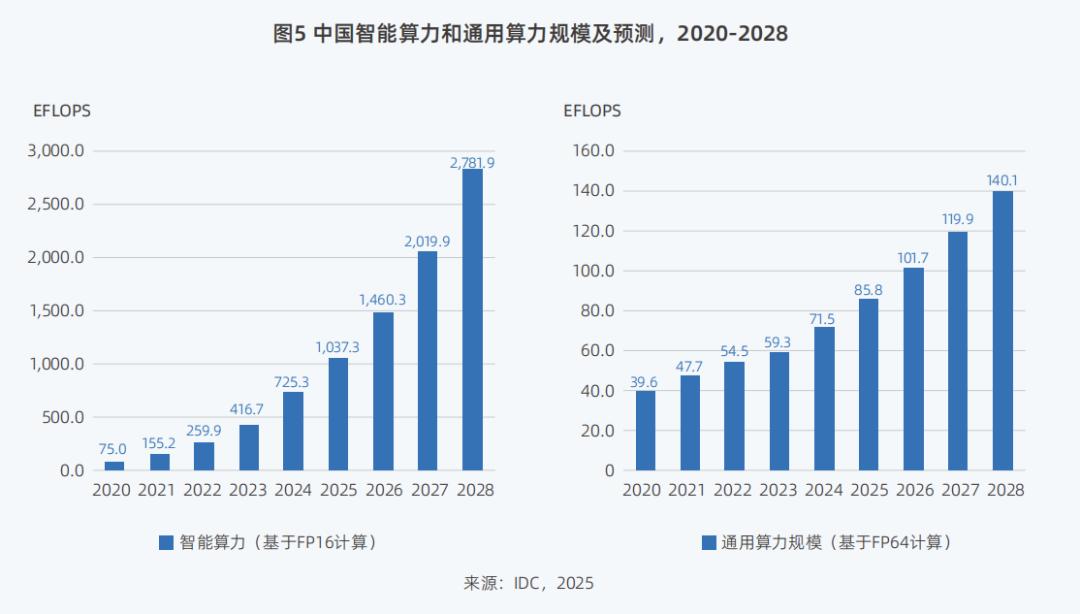
In terms of "increasing efficiency," in addition to reducing computing power costs, it also involves reducing energy consumption, which is crucial for the deployment of large models and the realization of a commercial closed loop.
The "Report" proposes four key initiatives for "increasing efficiency".
First, build based on usage and plan AI infrastructure construction with applications as the orientation to avoid resource waste. This applies not only to enterprises privatizing and deploying their own AI infrastructure but also aligns well with the current construction of AI computing centers.
Previously, many AI computing centers suffered from low utilization rates. Since last year, some AI computing centers have primarily considered the local industrial structure during the initial planning phase and conducted resource planning with applications as the orientation. For instance, different regions may have distinct industries such as manufacturing, animation, robotics, autonomous driving, and the low-altitude economy, which have varying demands for AI computing scale, and the ratio between different chips may also differ.
In recent weeks, multiple AI computing centers across the nation have officially announced the deployment and launch of DeepSeek, such as the Henan Airport AI Computing Center, Wuxi Taihu Yixin AI Computing, and Nanjing AI Computing Center. The application wave driven by DeepSeek may bring new opportunities to AI computing centers.
"But this also requires considerable effort and is not as simple as running a DeepSeek API," Liu Jun told Digital Frontline. Industry enterprises must integrate AI into their own industries and business data. This process requires a plethora of tools and services for targeted optimization. "For example, if it takes two seconds to output one character, it would be difficult for users to accept."
Second, improve model-computing efficiency and reduce computing power overhead. In this regard, DeepSeek has set a benchmark. It significantly enhances performance and efficiency through innovative fusion of FP8, MLA (Multi-head Latent Attention), and MoE (Mixture of Experts) architectures.
Some of these ideas are directions that the industry has collectively explored after encountering difficulties in the development of large models.
"Since last year, people have discovered that for models based on the Dense architecture, evolving to train a model with over 500 billion or 1 trillion parameters requires computing power, time, and data volumes that are currently unachievable under current technological conditions," Liu Jun recalled. They conducted an assessment and found that in such a scenario, it would require 200,000 cards for one year of training to achieve high-quality training of a trillion-parameter Dense model.
Therefore, since last year, the industry has unanimously turned to exploring the MoE approach to achieve higher-quality models through more efficient computing power investments. For example, DeepSeek has adopted the MoE architecture since V2, and Mistral overseas has also previously released MoE architecture models.
In May last year, Inspur Information released Source 2.0-M32, which also adopted the MoE concept. By proposing and adopting the "Gated Network Based on Attention Mechanism" technology, it constructs a mixture of experts model with 32 experts, significantly improving model computing power efficiency. The computing power resources required for training and inference per token are only 1/19 of those required by Llama-70B.
"The industry was already doing similar work before, but DeepSeek has given us a clearer signal," Liu Jun said. "In the next stage, people will shift from simply pursuing an increase in quantity, such as how many cards they have bought, to pursuing how to become a more efficient system."
Third, optimize the computing power infrastructure architecture. For example, adopt advanced computing architectures to enhance the performance of single computing nodes and improve computing efficiency. Optimize the memory hierarchy to reduce data transmission latency and enhance data processing speed. Utilize intelligent scheduling algorithms to reasonably allocate computing tasks and optimize cluster management to ensure efficient resource utilization.
Fourth, enhance data support and reduce invalid computations. For instance, by establishing high-quality datasets and constructing unified data storage and access interfaces, data flow and sharing can be simplified, providing robust support for AI model training.
The "Report" also shows that within the next 18 months, to introduce large models into production, in addition to hardware upgrades being the primary investment target for enterprises, expenditures on software and services will also be the main expenditure direction for enterprises' generative AI projects.
"Starting from 2024, users' investment growth in software has been accelerating. With the continuous surge of the application trial wave brought about by DeepSeek, the development of corresponding software and services, as well as customized solutions, will increase," said Zhou Zhengang, Vice President of IDC China.
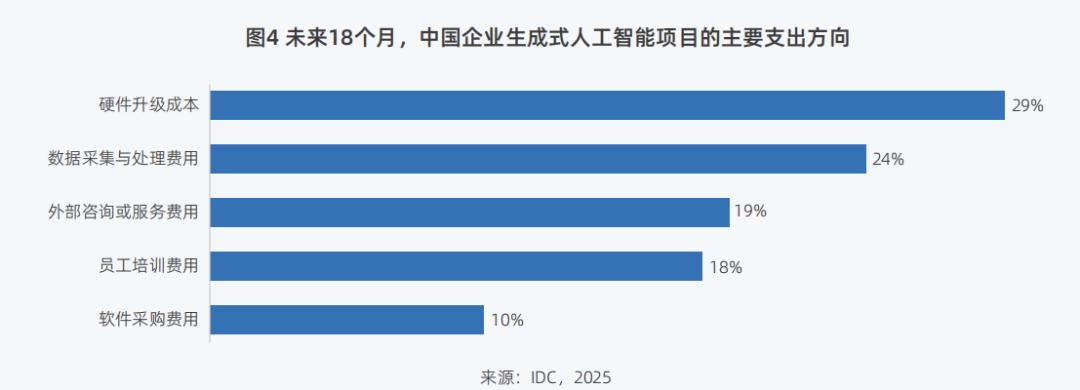
Against this backdrop, customers require more full-stack support. In response to these needs, Inspur Information currently provides a full chain and full-stack AI technology service, ranging from AI server computing hardware, the "Source" large model, the AI station computing power scheduling platform, to the EPAI large model landing tool.
03
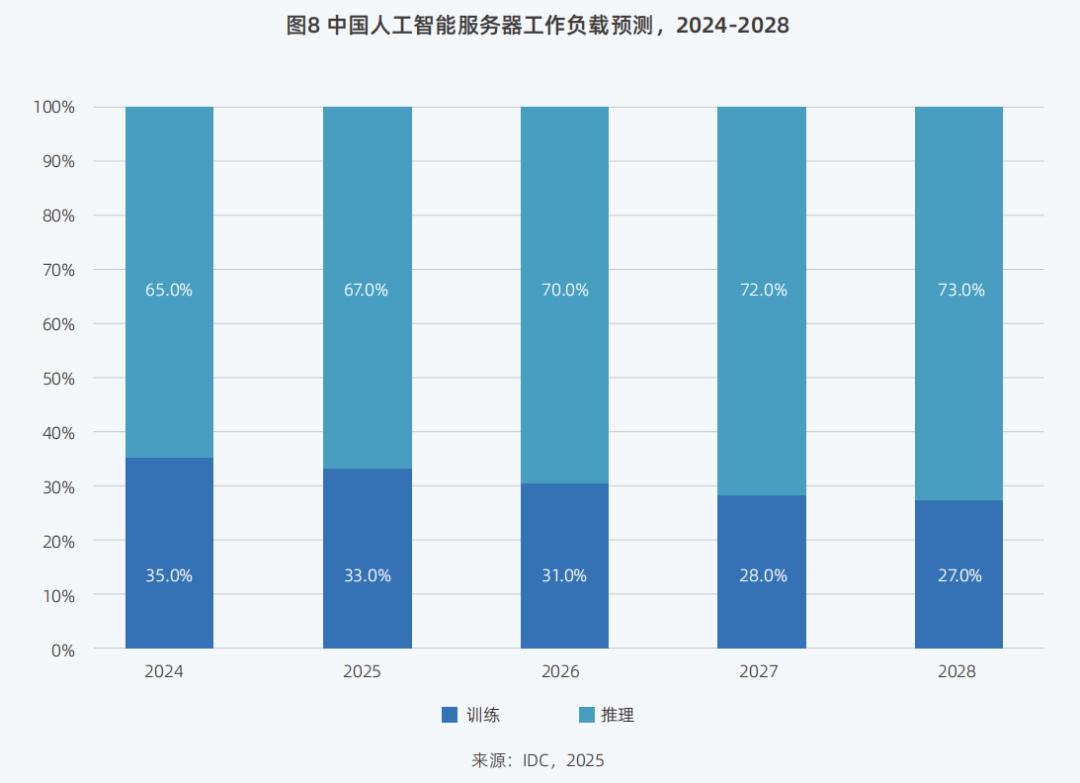
Inference Market Boom: Inference Workload Share to Reach 73% by 2028
The "Report" also proposes an important trend: inference computing power is expected to experience a significant surge, with the share of inference workloads reaching 67% by 2025. "Currently, almost all purchase demands we receive are for inference," Liu Jun, Senior Vice President of Inspur Information, told Digital Frontline.
Currently, 42% of Chinese enterprises have begun preliminary testing and key proof-of-concept validation of large models, and 17% have introduced the technology into the production stage and applied it to actual businesses.
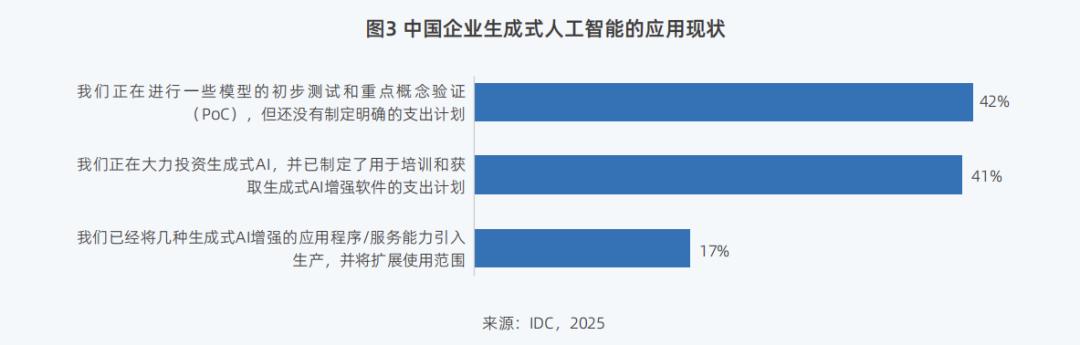
Correspondingly, by 2024, domestic inference workloads accounted for 65% while training workloads held 35% of the market share. The "Report" anticipates that by 2028, the share of inference workloads will surge to 73%, significantly outpacing the 27% share of training computing power.
In response to this trend, major cloud computing providers and public cloud operators have accelerated their efforts, swiftly announcing support for DeepSeek model invocation or deployment, and engaging in fierce price competitions to capture market share.
For private clouds or privatized deployments, industry analysts foresee this market segment becoming a pivotal driver for the growth of inference computing power. An insider from the AI computing industry remarked, "Enterprises will establish their own small AI computing centers, deploying either 1 to 10 servers (with up to 100 cards) or 10 to 20 servers (scaling up to 100 cards)."
Liu Jun further informed Digital Frontline that for enterprise customers, purchasing private computing power in the range of 1 to 20 units would be an appropriate scale in the near future.
"However, this transition will be gradual. Companies won't hastily purchase a large number of machines without careful consideration," Liu Jun emphasized. Initially, enterprises should start by acquiring a select number of AI servers to establish an environment and conduct Proof of Concept (PoC) for their specific business needs. Once it is verified to be highly beneficial for their operations, they will then scale up significantly.
IDC Vice President Zhou Zhengang projected that, against this backdrop, the "open-source + integrated machine model" is likely to witness explosive demand in the coming period.
"In recent years, demand for integrated machines has been relatively low because, while suitable for inference, they might lack sufficient computing power for training. Moreover, inference could often be addressed through services, eliminating the need for local deployment of such machines. However, following the introduction of DeepSeek, the market demand for integrated machines has surged notably. Recently, numerous companies have reached out to us, eager to understand the scale of this market," Zhou Zhengang shared with Digital Frontline.
Inspur's recently launched MetaBrain R1 inference server, on February 11, has also garnered significant attention from various enterprises. Through system innovation and software-hardware co-optimization, this product can deploy and run the DeepSeek R1 671B model on a single machine.
"Why emphasize its capability to run on a single machine? Because current solutions can be cumbersome. When the model size is substantial, using four machines to accommodate it can be a significant hurdle for customers to adapt. In contrast, with a single machine, users can simply turn it on, install the model, and immediately utilize Chatbox and CherryStudio, significantly easing the process of trying out the full-fledged 671B model," Liu Jun explained.
Coincidentally, China Telecom Tianyi Cloud and Lenovo Baying have also recently unveiled integrated machines leveraging technologies like DeepSeek. The competition for inference computing power has already commenced.
"In the realm of inference scenarios, what users primarily concern themselves with is the quality of their experience and the number of tokens they can obtain per yuan, while ensuring a satisfactory user experience," Liu Jun told Digital Frontline. User experience and cost-effectiveness will ultimately determine the survival of computing power vendors in the inference market.
In his opinion, the focus of inference currently lies in solving two key issues: first, how to fit and run the model with fewer machines, and second, whether the speed of generating tokens is sufficiently fast.
"Much of our work revolves around these two aspects," Liu Jun elaborated, providing an example. They adopt a strategy of separating planning and decoding (PD separation) to decouple and deploy the two crucial stages of inference—prefilling and decoding. By establishing a separated computing resource pool, they can reduce computing time, lower costs, and enhance resource utilization.
Whether at the inference or training end, the intelligent computing market, as a vital underpinning for the implementation of large models, will maintain rapid growth in the years ahead. As we approach the tipping point of application explosion, maintaining enthusiasm while avoiding blind aggression remains the most prudent course of action for the present.
-
![]()
Hardware is the skeleton, AI is the soul, and data integrates the two
-
![]()
China’s AI Industry: A Unified Pivot Towards Monetization?
-
![]()
New Progress! Infineon Completes Acquisition of ams OSRAM's Non-Optical Sensor Business
-
![]()
35 Million Bet on an Optical Future! Tengjing Technology Makes a Move in AR
-
![]()
Why World Models Get Stuck on Construction Roads in Autonomous Driving Applications
-
Alibaba Initiates Cultural Transformation: Is Jack Ma Making a Strategic Comeback?
-
Tianfeng Heads to Hong Kong for IPO with RMB 3.8 Billion in Funds: Xingyu's Cross-Border Foray into Embodied AI Faces Uncertain Future
-
![]()
Mengshi Auto’s High-End Aspirations Dashed: Huawei Partnership Fails to Revive Sales, New Model’s Entry Price Dips Below 300,000 Yuan





