AI Daji Emerges: Unveiling How Teams Like Google DeepMind Utilize the 'Curiosity Reward' Mechanism to Enable AI to Proactively Explore User Traits in Multi-turn Dialogues
 04/28 2025
04/28 2025
 898
898
Introduction: An adept dialogue agent regards each interaction as a pivotal opportunity to deepen its understanding of the user.
Full text is approximately 3600 words, estimated reading time is 10 minutes.
In today's fast-evolving landscape of artificial intelligence, chatbots have transcended their roles as mere question-and-answer tools. They are now extensively utilized in education, healthcare, fitness, and other sectors, striving to offer users bespoke interactive experiences. However, traditional dialogue models often adopt a one-size-fits-all approach, making it challenging to accurately cater to the unique needs of each individual user. How can AI dynamically learn user preferences during dialogues to achieve truly personalized interactions?
Recently, a study titled "Enhancing Personalized Multi-Turn Dialogue with Curiosity Reward," jointly published by Google DeepMind, the University of Washington, and other institutions, has presented an intriguing solution: leveraging the 'curiosity reward' mechanism to empower AI to actively explore user traits in multi-turn dialogues, thereby achieving a genuinely personalized interactive experience. This research opens up new avenues for personalized dialogue systems in education, healthcare, and beyond. Let's delve into the allure of this groundbreaking work!

Innovation: A Novel Paradigm for Curiosity-Driven Personalized Dialogue
Traditional large language models (LLMs) typically rely on a singular reward function in dialogues, seeking universal answers that "apply to everyone." While this method ensures a certain level of helpfulness and safety, it overlooks individual user differences. For instance, in educational scenarios, some individuals prefer learning through stories, while others favor hands-on practice; in fitness recommendations, some lean towards outdoor running, while others only wish to practice yoga at home. Existing models often necessitate extensive user history data to achieve personalization, which is often impractical in real-world applications—what about new users? What about users whose preferences evolve over time?
This research introduces a revolutionary framework that incorporates intrinsic motivation, enabling AI to actively "curios" about user needs during dialogues. The core innovation lies in devising a curiosity reward mechanism for AI, encouraging it to reduce uncertainty about user traits by posing questions or adjusting dialogue styles. In other words, AI is no longer passive in its responses but acts like an astute detective, continuously gathering clues during the dialogue, inferring your preferences, personality, or needs, and tailoring its responses accordingly.
Specifically, the research team incorporated an additional reward signal based on multi-turn reinforcement learning. This signal hinges on the AI's belief update about the user type: when the AI more accurately infers user traits through dialogue, it receives a reward. This mechanism allows the AI to learn how to "smartly" ask questions during dialogues, such as inquiring, "Do you prefer listening to stories or doing experiments?" in educational contexts, thereby swiftly identifying the user's learning style. Simultaneously, it addresses the sparse signal and data imbalance issues of traditional RLHF in personalized tasks by combining sparse final rewards (external rewards) with round-by-round intrinsic rewards.
The research also introduced potential-based reward shaping to ensure that this curiosity reward does not alter the AI's ultimate goal but accelerates its learning process.
The paper defines multiple reward functions, such as 'Differential Accuracy' based on prediction accuracy and 'Differential Entropy' based on information entropy. These designs enhance the AI's efficiency in exploring user traits.
The most notable aspect of this method is that it does not rely on extensive user history data or pre-built user personas. Even when encountering new users, the model can learn in real-time during the dialogue and dynamically adjust its strategy. This 'online personalization' capability significantly expands the application potential of dialogue AI in education, healthcare, and other fields. For instance, in educational scenarios, the model can adapt teaching methods based on students' learning styles; in fitness recommendations, it can tailor exercise plans according to users' lifestyle habits and physical conditions.
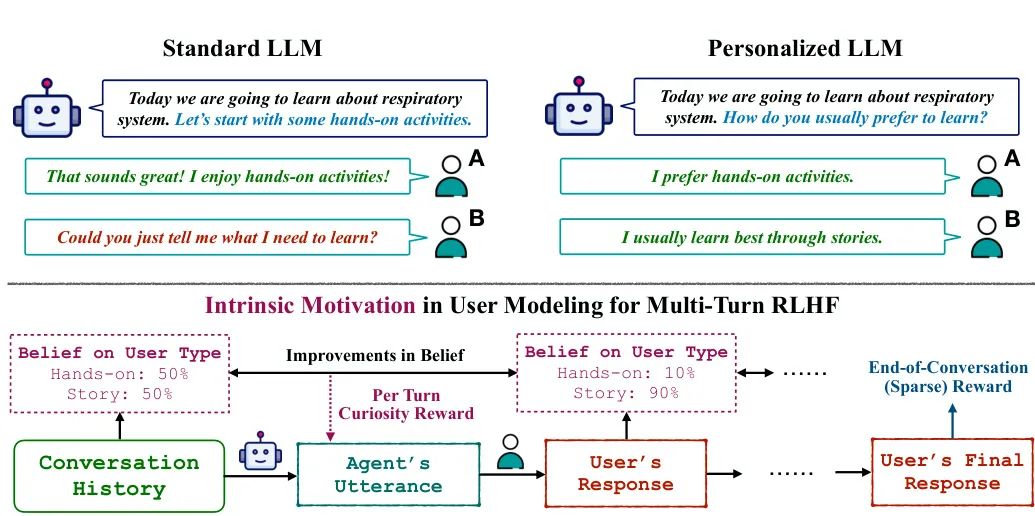
Figure 1: The traditional model (top left) treats all users uniformly, overlooking individual differences; whereas the new method (top right) employs curiosity rewards to enable AI to actively learn user preferences and adapt during dialogues. The image illustrates how the AI updates its belief about the user type through each round of dialogue, achieving personalized interaction.
Experimental Methods
To validate the effectiveness of this method, the research team conducted in-depth experiments in two highly personalized scenarios—educational dialogue and fitness recommendation. They not only designed sophisticated reward models but also constructed diverse datasets and evaluation systems to ensure the reliability and universality of the experimental results.
Experimental Scenarios and Datasets: The Dual Challenges of Education and Fitness
The research team chose two scenarios highly reliant on personalization for their experiments: educational dialogue and fitness recommendation. These scenarios not only cover application needs across different fields but also place stringent demands on the model's adaptability and generalization capabilities.
In the educational dialogue scenario, the research utilized a simulated dataset provided by Shani et al. (2024) to create a virtual teacher-student dialogue environment. Students were simulated by the pre-trained Gemma 2B model, randomly exhibiting lecture-based or hands-on learning styles. The model's task was to dynamically adjust teaching strategies based on student feedback, such as explaining knowledge points through storytelling or designing experiments. To assess the model's personalization ability, the research team employed the Gemma 7B model as a 'user classifier' to predict students' learning styles in real-time and compute intrinsic rewards based on improvements in prediction accuracy.
In the fitness recommendation scenario, the research team newly designed a dataset to simulate interactions between health consultants and users. The dataset encompassed 20 user attributes, including age, personality, physical condition, etc., with 5 attributes directly influencing the recommended exercise strategy (such as outdoor sports or indoor yoga). User backstories were generated through the Gemini 1.5 Pro model to ensure that simulated user responses were realistic and consistent. The model needed to progressively infer user needs through multiple rounds of dialogue and recommend the most suitable exercise plan.
Reward Model: An Incentive Mechanism Combining Internal and External Rewards
The crux of the research lies in the design of the reward model. Traditional RLHF typically relies solely on external rewards, i.e., the overall score given by the user at the end of the dialogue. However, this reward signal is often too sparse to guide the model in making personalized decisions early in the dialogue. To address this, the research team introduced an intrinsic motivation-based reward mechanism, specifically encompassing the following forms:
Differential Accuracy: Rewards the model for enhancing the prediction accuracy of user characteristics after each round of dialogue. This reward encourages the model to gradually converge on the user's true preferences by asking questions or adjusting strategies. Differential Log Accuracy: Based on the logarithmic increment of prediction accuracy, emphasizing relative improvements in prediction precision. Differential Entropy: By reducing the entropy (uncertainty) of the model's beliefs about user characteristics, it incentivizes the model to explore more informative dialogue strategies.
These intrinsic rewards are realized through potential-based reward shaping theory, ensuring that they do not alter the model's optimal strategy while markedly accelerating the learning process.
Furthermore, the research compared non-differential rewards (such as rewards directly based on prediction accuracy) and found that differential rewards can effectively prevent the model from prolonging the dialogue to obtain more rewards, thereby ensuring dialogue efficiency and quality.
Evaluation Methods: Rigorous Multi-dimensional Testing
To comprehensively measure the model's performance, the research team designed two evaluation dimensions: personalization ability and dialogue quality. Personalization ability is assessed by comparing the model's prediction accuracy of user characteristics and its ability to adjust strategies based on user preferences. Dialogue quality focuses on the model's expression clarity, interactivity, and overall fluency. The evaluation process utilizes the high-performance Gemini 1.5 Pro model for automated scoring, calculating the model's win rate through pairwise comparisons to ensure the objectivity of the results.
Additionally, the research introduced baseline models for comparison, including a standard multi-turn dialogue RLHF model (without intrinsic rewards) and a script-based AI agent based on decision trees. These baselines helped verify the unique contributions of the intrinsic reward mechanism.
Experimental Results
The experimental results unequivocally demonstrate the immense potential of the 'curiosity reward' mechanism.
Personalization Ability
In the educational dialogue scenario, the model with intrinsic rewards significantly outperformed the baseline model in terms of personalization ability. Table 1 showcases the win rate comparison of different reward mechanisms, with all accuracy-based intrinsic rewards (DiffAcc, Acc, DiffLogAcc) substantially surpassing the baseline model, with DiffAcc achieving a win rate of 75.25%. This indicates that the model can more swiftly identify students' learning styles and adjust teaching strategies, such as crafting narrative teaching content for students who prefer storytelling.
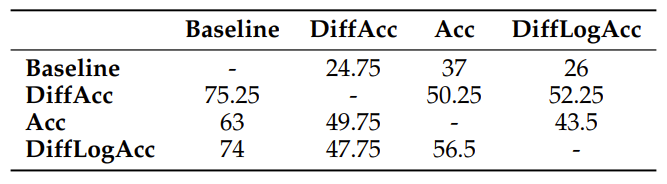
Table 1: Win rate percentage in pairwise comparisons of personalization aspects. Among all reward types, the model proposed in this paper surpasses the baseline model in conducting personalized dialogues.
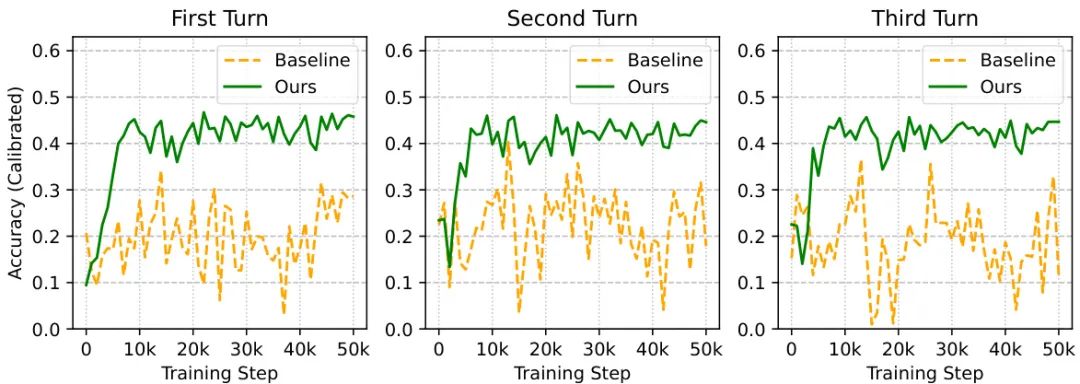
Figure 2: User modeling performance in educational dialogue. The figure contrasts the user preference prediction accuracy of the baseline model and the model with DiffAcc reward in the first three rounds of educational dialogue. The horizontal axis represents training steps, and the vertical axis represents calibrated prediction accuracy. The model with intrinsic rewards exhibits stronger user modeling ability from the outset, whereas the baseline model relies on students actively expressing their preferences.
In the fitness recommendation scenario, the model also delivered impressive results. Figure 3 illustrates the model's probability distribution gradually converging to the correct user type through multiple rounds of dialogue. For instance, by posing targeted questions (such as 'Do you prefer outdoor or indoor sports?'), the model can quickly ascertain the user's lifestyle and physical condition, thereby recommending the most suitable exercise strategy. In contrast, the baseline model struggled in complex user modeling tasks, finding it difficult to effectively extract key information.
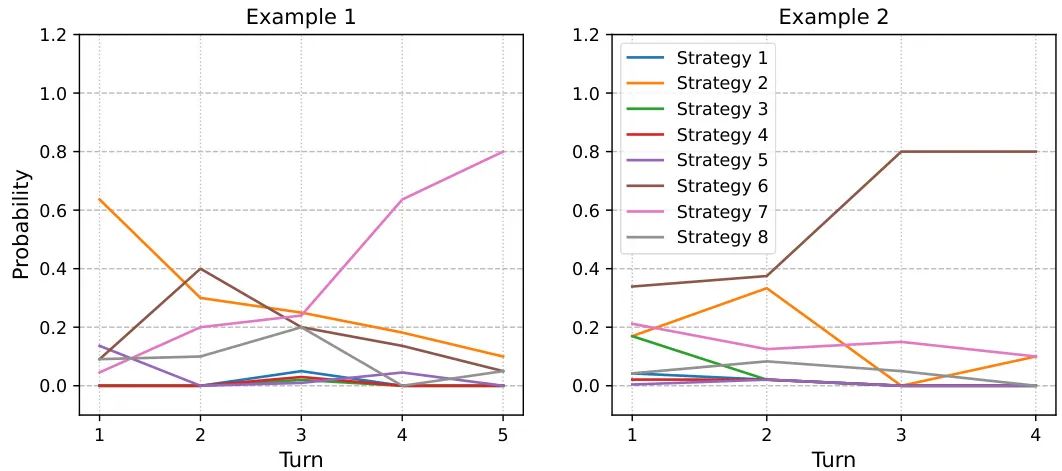
Figure 3: User type prediction in fitness recommendations. The figure shows that in the fitness recommendation scenario, the model progressively improves its prediction accuracy of user types through multiple rounds of dialogue. The horizontal axis represents dialogue rounds, and the vertical axis represents the predicted probability distribution, indicating that the model gradually converges to the correct exercise strategy.
Dialogue Quality
Regarding dialogue quality, the study found that the model based on Differential Log Accuracy (DiffLogAcc) performed optimally in educational dialogue, with a win rate of 57.5%, even surpassing the baseline model. This signifies that intrinsic rewards not only enhance personalization ability but also optimize dialogue fluency and user experience to a certain extent. In contrast, non-differential rewards (such as Acc) slightly degrade dialogue quality by encouraging the model to prolong the dialogue, highlighting the superiority of the differential reward design.
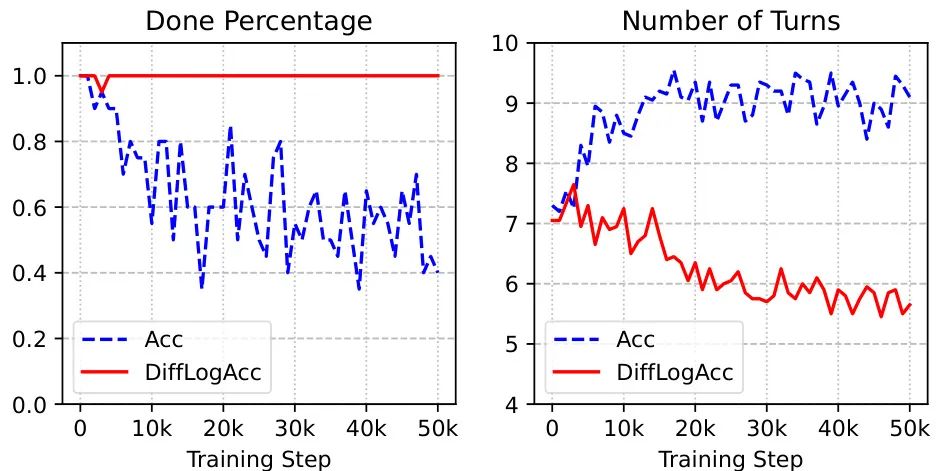
Figure 4: Impact of differential vs. non-differential rewards on dialogue quality and length. Non-differential rewards prompt the model to tend to prolong the dialogue, whereas differential rewards effectively control dialogue length, improving efficiency and quality (with higher task completion).
Insights into Reward Design
The research also deeply analyzed the impact of different reward designs:
Differential vs. Non-differential Rewards: Differential rewards avoid the AI unnecessarily extending the dialogue by only rewarding the increment in belief updates, ensuring dialogue quality. Accuracy vs. Entropy Rewards: When external rewards do not account for user differences, accuracy rewards (based on real user types) perform more consistently. Entropy rewards excel on certain user types but may falter on others due to 'controlling behavior' (forcing users to exhibit a certain type). Future Prospects: Endless Possibilities for Personalized AI
This research pioneers a novel approach to the personalized evolution of dialogue AI. By incorporating 'curiosity rewards,' the model not only enhances its comprehension of users but also displays a more spontaneous adaptability and affability during interactions. Nonetheless, the study also highlights the current method's limitations, emphasizing the necessity to refine the modeling of intricate user traits and addressing potential performance constraints in specific contexts due to its reliance on the quality of user engagement.
Looking ahead, the research team aims to delve into more sophisticated dialogue settings, including open-ended casual conversations and multi-party interactions, to further substantiate the method's generalizability. Additionally, integrating zero-shot user profiling with privacy-preserving technologies will pave the way for a safer and more efficient personalized experience. As these technologies advance, it is envisioned that future dialogue AI will embody a 'considerate companion,' deeply understanding users and offering unparalleled convenience and comfort across education, healthcare, entertainment, and beyond.
Conclusion
From the conception of 'curiosity rewards' to its successful application in education and fitness scenarios, this research underscores the immense promise of AI in the realm of personalized dialogue, while envisioning a future where intelligent interactions are more human-centric. As the research team asserts, "A superior conversational agent should view each interaction as an opportunity to gain insight into the user."
Let us eagerly anticipate how this 'curiosity' will continue to illuminate the expansive universe of AI-human communication! We invite you to share your perspectives on this groundbreaking work in the comments section below~
-- End --
-
![]()
MathWorks: Generative AI Holds Great Potential, Yet a Trusted Toolchain is Essential for Flawless Operation
-
![]()
Small Earphones, Big Business
-
![]()
Volkswagen Slashes 100,000 Jobs, Mercedes-Benz Axes Year-End Bonuses: What’s Ailing German Auto Titans?
-
![]()
Doubao Can No Longer Offer Free Services to 345 Million Users: China's Era of Free AI Is Drawing to a Close
-
![]()
How Can Chinese Small Home Appliances Conquer Southeast Asia Through 'Dimensional Competition'?
-
![]()
Why are top intelligent driving players betting on reinforcement learning?
-
![]()
June 2026 Automobile Complaint Index Rankings: Persistent Problems Ignite Grievances Among Long-term Vehicle Owners
-
![]()
Avita Takes Another Stab at HKEX Listing: Facing the Urgency of Sustaining Operations Amid 11.2 Billion Yuan Loss Over Three Years