Empowering Large Models with 'Eyes': The Transformative Potential of Visual Language Models
 05/28 2025
05/28 2025
 831
831
Produced by ZhiNengZhiXin
Visual Language Models (VLMs) are emerging as a pivotal component in the evolution of artificial intelligence. By seamlessly integrating large language models (LLMs) with visual encoders, VLMs transcend the confines of traditional computer vision, enabling them to leverage natural language as a versatile interface for deep comprehension and dynamic generation of images, videos, and text.
This paradigm shift broadens the horizon of AI applications. We delve into the foundational architecture and operational principles of VLMs, dissect the underlying mechanisms and practical challenges fueling their enhanced capabilities, and explore their pivotal roles in industrial implementations and future advancements.

Part 1
From 'Seeing' to 'Comprehending'
Historically, the progress of computer vision models has been hampered by the rigid coupling between inputs and tasks.
Whether identifying cats and dogs, recognizing license plates, or scanning documents, these models, predominantly built on Convolutional Neural Networks (CNNs), are trained and optimized on specific datasets, rendering them ill-equipped to adapt to changes in tasks or scenarios. Traditional models struggle with flexible migration and lack the ability to grasp the semantic content of visual information.
VLMs, however, merge visual encoders with LLMs, empowering AI to not merely 'see' but also 'comprehend' and even 'communicate'.
Rather than a novel model, VLMs represent a multimodal intelligence framework that processes multi-source data through a unified language interface, blurring the boundaries between vision and language and ushering the closed world of computer vision into the open paradigm of generative AI.
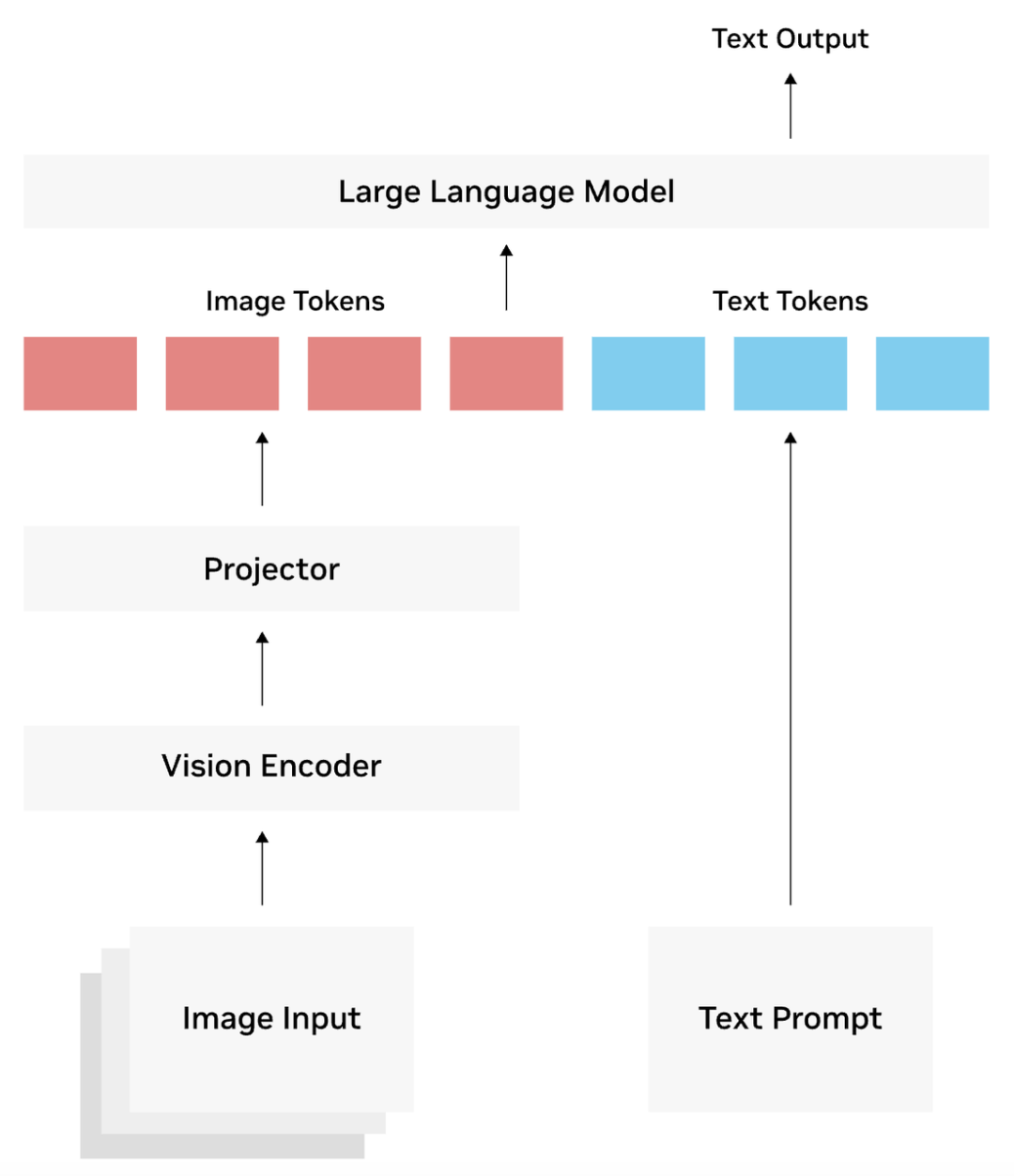
The core architecture of VLMs comprises three essential components: visual encoders (e.g., CLIP), projectors, and large language models (e.g., LLaMA, GPT).
The visual encoder converts images or videos into feature vectors, which the projector transforms into language 'tokens' comprehensible by the LLM. Subsequently, the LLM generates natural language outputs, such as dialogues, answers, and summaries. This design not only facilitates cross-modal understanding but also achieves efficient 'zero-shot learning'—even in unfamiliar image scenarios, VLMs can provide intelligent responses with minimal prompting. From image question answering to document analysis, video summarization, and image reasoning, VLMs are swiftly replacing multiple specialized models. Developers simply need to provide text prompts to activate corresponding visual capabilities, shifting the AI application threshold from model training to language expression, drastically simplifying deployment complexity.
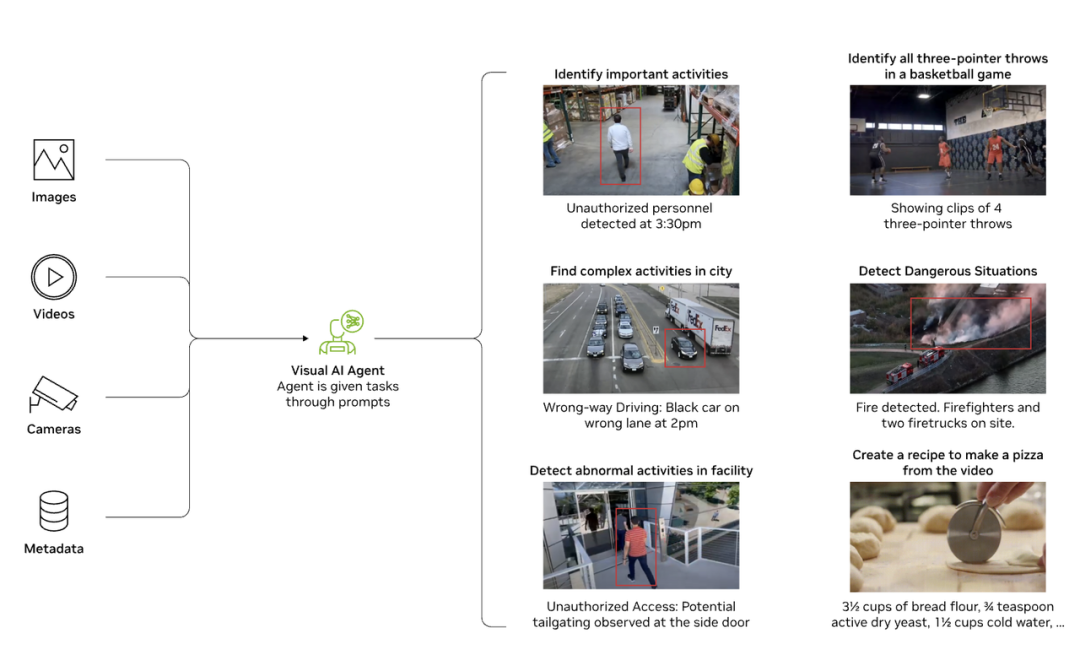
The versatility and adaptability of VLMs have established them as a new infrastructure across diverse industries, spanning education, healthcare, logistics, and manufacturing.
◎ In warehousing management, VLM-integrated visual agents can autonomously detect equipment failures, inventory shortages, and even draft incident reports.
◎ In traffic management, VLMs comprehend surveillance video content, identify risk events, and autonomously generate handling recommendations.
◎ In educational settings, they decipher handwritten math problems and generate step-by-step solutions. This intertwined capability of vision and language forms the cornerstone for future AI platforms to attain generalized intelligence.
The robust capabilities of VLMs are rooted in their intricate training mechanisms. Model training broadly encompasses two stages: pre-training and supervised fine-tuning.
◎ The pre-training stage primarily aligns the semantic representations among the visual encoder, projector, and LLM, ensuring a consistent language space for understanding images and language. Training data typically comprises hundreds of millions of image-text pairs or interleaved image-text sequences, reinforcing the model's fusion capabilities across modalities.
Post-pre-training, the model often lacks specific task proficiency, necessitating the supervised fine-tuning stage. This involves using specific task prompts and expected response data, such as image question answering and object counting, to teach the model how to provide accurate responses based on input instructions.
Finally, some enterprises or organizations employ the PEFT (Parameter-Efficient Fine-Tuning) method to swiftly adapt to specific industry tasks on small-scale data, crafting customized vertical VLMs.
Part 2
Empowering Key Applications with Visual Language Models
In industrial automation, VLMs are integrated into factory monitoring systems, transforming into 'visual agents' with event detection and decision support capabilities.
For instance, in automated warehouses, VLMs not only recognize specific events (like material falls and shelf vacancies) but also summarize operating procedures, pinpoint anomaly sources, and generate natural language reports for managerial review. This ability to 'verbalize what is seen' significantly reduces the cost and time of manual monitoring.
In public safety, VLMs' video understanding capabilities are extensively utilized in intelligent transportation.
For example, a traffic system camera records video at an intersection, and VLMs analyze vehicle behavior within the frame, detect events like illegal parking, accidents, and pedestrians crossing red lights, and generate real-time semantic descriptions. Furthermore, it performs comparative analysis across multiple cameras, reviews the behavioral chain before and after accidents, and aids traffic management departments in swift response.
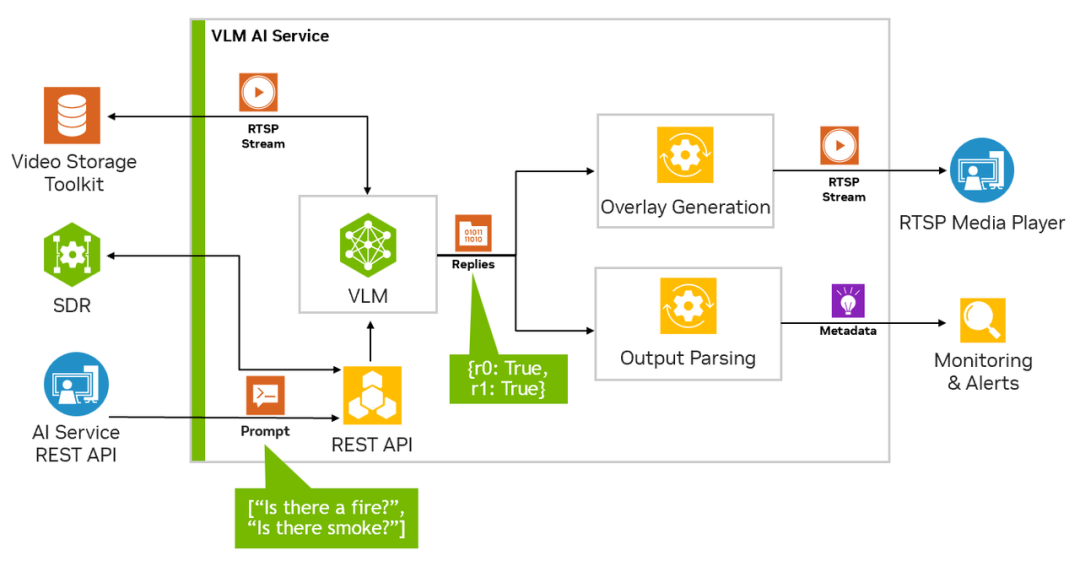
Traditional computer vision systems predominantly rely on CNNs for image classification, detection, or segmentation.
However, their tasks are static and singular, and they cannot be guided by language instructions. For example, a cat and dog recognition model cannot respond to queries like 'Is this cat lying on the windowsill or the sofa?'
In contrast, VLMs leverage a three-stage structure of visual encoder + projector + LLM, enabling AI to process visual inputs akin to humans using language, thereby tackling more complex and flexible tasks.
This capability stems from the multimodal alignment during model training: the visual encoder interprets images, the LLM comprehends text, and the projector bridges image tokens with language semantics.
Through training on vast image-text paired datasets, the model gradually learns to convert visual perception into language expression, enabling it to execute not only traditional CV tasks but also language-driven tasks such as question answering, explanation, and reasoning.
Another pivotal advantage of VLMs is their prompt-driven zero-shot capability. Traditional models often require labeled new datasets for training to undertake new tasks, like 'identifying risky behaviors in an office environment'.
In contrast, VLMs need only a prompt such as 'Please indicate whether there is any behavior that does not comply with safety regulations in this photo' to reason based on existing knowledge.
Summary
The advent of visual language models has not only revolutionized how we process images and text but is also redefining the essence of 'intelligence'. From security to industry and transportation, VLMs are continuously pushing the boundaries of application and replacing multiple isolated vision models, a trend that warrants our continuous attention.
-
![]()
Market Share Dilemma: DJI vs. Insta360—Is It '40-40' or '60-30'?
-
![]()
Market Share Dilemma: DJI vs. Insta360 – A '40-40 Split' or '60-30 Split'?
-
![]()
It's Kunlunxin's Turn to Play
-
![]()
Is the New Performance Peak Just the Starting Point? What Will Be Crystal-Optech's Next Destination?
-
![]()
Goertek Pours 69 Million Yuan into Elite Precision: Ramping Up Optical Precision Manufacturing and R&D Capabilities
-
![]()
Avatr Attempts HKEX Listing Again, With 20,000 Vehicles Sold in First Five Months
-
![]()
NVIDIA Announces 10-Fold Production Capacity Increase in 2 Years, Disrupting the Energy Storage Industry
-
![]()
AI Enters the Second Half: Models Are No Longer Scarce, What’s Truly Scarce Are Computing Power, Scenarios, and Trust