Electricity Costs Only Account for 5%, So What's Really Consuming Computing Power Costs?
 03/30 2026
03/30 2026
 611
611

Recently, a set of data center cost analysis charts disclosed by MetaX during an industry sharing session has drawn widespread attention from industry insiders.
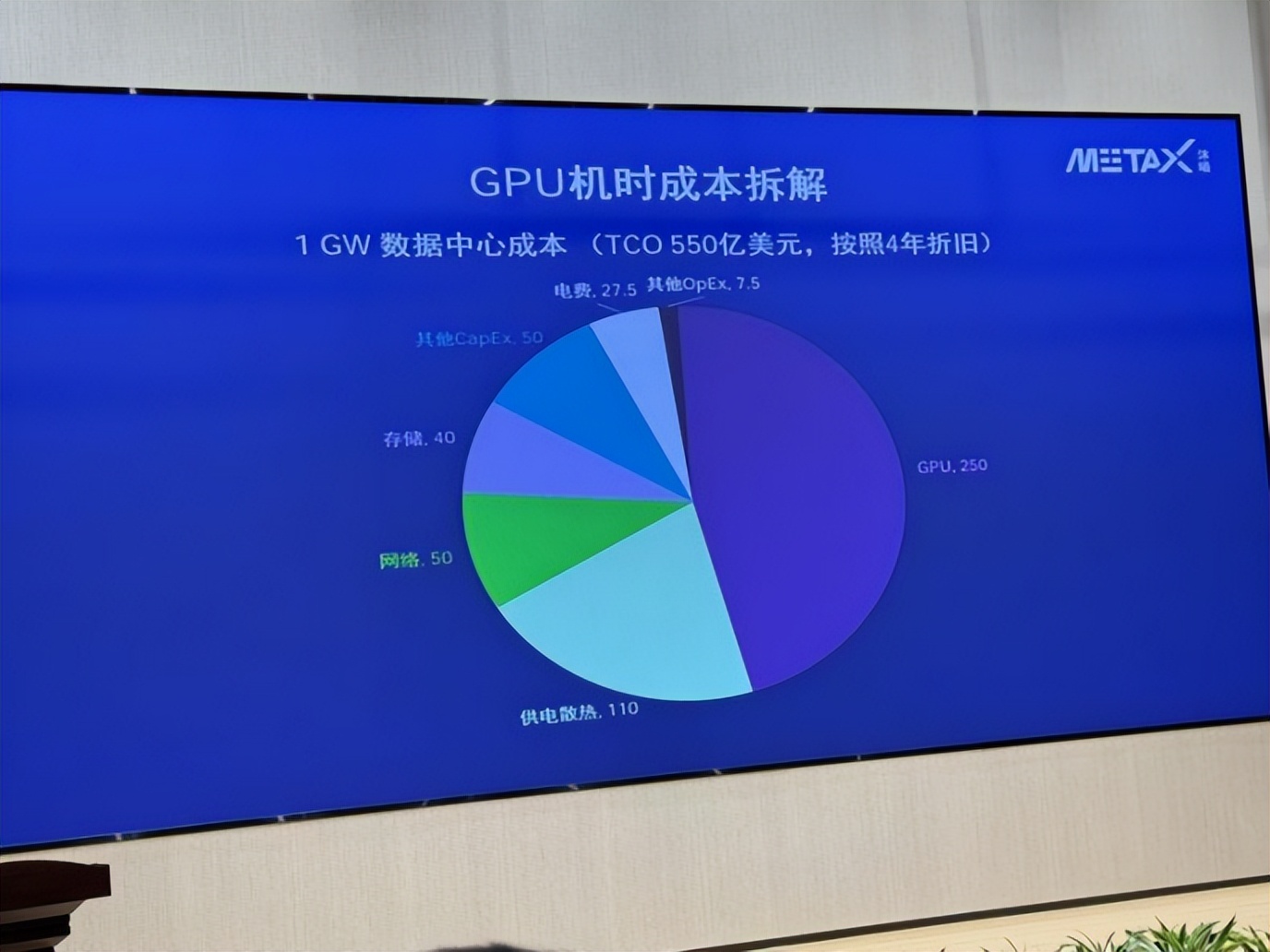
This chart breaks down the costs of a 1GW data center—with a total cost of ownership (TCO) of $55 billion, spread over four years of depreciation, GPU chips account for $25 billion, power supply and cooling $11 billion, networking $5 billion, and storage $4 billion. What about electricity costs? $2.75 billion, accounting for 5%.
This single chart overturns a 'rosy narrative' that has been circulating in the industry for nearly two years. It was often said that China's electricity prices are cheaper than those in Europe and the United States, giving us an edge in the AI era. With large models being so power-hungry, low electricity prices would provide a sustained advantage. However, MetaX's chart tells a different story: In the cost structure of hyperscale computing power centers, electricity costs account for a very low proportion of the overall TCO and have a limited impact on total costs. The real big-ticket item is the GPU, which you simply cannot avoid.
01
Where Does the Money Go in a $55 Billion Data Center?
Let's break down the costs in more detail.
The $55 billion in the chart is based on a full-cycle estimate for a 1GW data center over four years. Why four years? Because that's the typical depreciation cycle for GPUs, and many large internet companies actually use shorter cycles—three years or even two and a half years. This isn't conservative accounting; it's the reality of technological iteration: When a new generation of GPUs is released, the cost per unit of computing power and energy efficiency of the previous generation immediately become uncompetitive.
Of the $55 billion, GPU procurement accounts for $25 billion, or 45%. And that's just the cost of the chips. The power supply and cooling systems account for $11 billion, or 20%. This might sound like 'infrastructure,' but in reality, more than half of the cost is driven by the power consumption of GPUs—a single H100 consumes 700 watts, and the next generation of B-series GPUs will exceed 1,000 watts. With tens of thousands of cards stacked together, the complexity of the power supply and cooling systems far exceeds that of traditional data centers.
Networking accounts for $5 billion, and storage $4 billion. Together, these two areas add up to $9 billion, or 16%. The networking in hyperscale clusters isn't like the routers we use at home; it's a 'capillary network' of hundreds of kilometers of fiber optics and dozens of layers of switches, with costs and complexity growing exponentially with the number of GPUs.
The four major hardware segments add up to $45 billion, accounting for 82% of the total costs. Electricity costs? $2.75 billion, or 5%. Other operational and maintenance costs account for $750 million, or less than 1.5%.
So you see, cheap electricity is almost negligible in this ledger. Even if you cut electricity prices in half, you'd only save a few billion dollars—barely a ripple in the $55 billion total.
What really determines your costs is which GPUs you use, how many you use, how you connect them into a cluster, and how you power and cool them—and none of these can be solved by being 'cheap.'
In the cost equation of AI computing power, the weight of resource endowments is far less significant than imagined. What truly matters are technology and the supply chain.
02
Why Are GPU Prices 'Stuck'?
So here's the question: Can GPU prices come down? And if they can, would that solve most of the cost problem?
The answer is: Yes, they can come down, but it's difficult to reduce them significantly in the short term, and the room for price cuts isn't in China's hands.
The cost structure of an AI chip is far more complex than most people imagine. Let's start with the most intuitive (intuitive) aspect: process technology. Currently, flagship AI chips all use 4nm or 5nm processes, such as TSMC's N4P and N5. How much does it cost to tape out a single run? Three to five hundred million dollars, minimum. This isn't design fees; it's money paid directly to the foundry. And this cost is sunk—if the tape-out fails, the money is gone; if it succeeds, yield ramp-up takes several quarters.
Then there's HBM (High-Bandwidth Memory). An H100 is paired with 80GB of HBM3, and the cost of the memory alone accounts for more than 40% of the total chip cost. How concentrated is the HBM market? SK Hynix dominates, with Samsung close behind and Micron catching up. HBM capacity expansion has far lagged behind demand for AI chips, so HBM prices have been rising for years. No matter how well you design your GPU, if you can't get HBM or it's too expensive, the overall chip cost won't come down.
Then there's advanced packaging. Nearly all AI chips now use CoWoS, a technology firmly controlled by TSMC. The tightness of CoWoS capacity has been the biggest bottleneck in the AI chip supply chain for the past two years. The speed at which TSMC expands capacity directly determines the shipment rhythms of NVIDIA, AMD, and all self-developed AI chip vendors.
These three segments—advanced process technology, HBM, and advanced packaging—account for the majority of the BOM cost of AI chips, and each is monopolized by a tiny number of suppliers. Domestic GPU design companies, even if they catch up in design capabilities, still face the same supply chain realities. Tape-outs require TSMC or Samsung (or domestic advanced process lines still catching up), HBM currently relies almost entirely on Korean manufacturers, and advanced packaging is also dominated by TSMC. This means that the material costs of domestic GPUs are unlikely to be lower than NVIDIA's for some time and may even be higher due to smaller purchase volumes and weaker bargaining power.
More critically, NVIDIA's GPUs are not just chips; they are complete systems. From NVLink interconnects to InfiniBand networking, from the CUDA software stack to the entire developer ecosystem, NVIDIA has spent over a decade building a 'software-hardware integration' barrier. When you buy an NVIDIA GPU, a large portion of what you're paying for is 'certainty'—certainty that it will work, certainty that it will meet performance targets, and certainty that it can be deployed quickly. This 'certainty' premium is hard to avoid in the early stages.
03
The Window Is Open, But the Challenges Are Bigger
So what about domestic GPUs? Is there no chance?
Quite the opposite. The period from 2025 to 2026 could be the most critical opportunity window for domestic GPUs in recent years. The reason is simple: U.S. export controls on China are constantly tightening.
This pressure has objectively opened a 'forced adoption' window for domestic GPUs. In the past, domestic AI companies chose NVIDIA for optimal performance and ecosystem reasons; now, that optimal choice is being artificially cut off, and domestic GPUs have gone from 'backup' to 'must-have.'
What we're seeing is that since the second half of 2025, several leading domestic internet companies and operators have accelerated the deployment of domestic computing power clusters. Huawei's Ascend 910B and subsequent models have begun Large scale implementation (scaled deployment) in some scenarios; MetaX, Biren, and Suiyuan Intelligence Chip are actively pushing their products into production environments; Baidu Kunlun and Alibaba Pingtouge's self-developed chips are also being used at scale internally.
But the challenges are equally clear.
The first is the performance gap. Domestic GPUs are quickly catching up in single-card computing power, but they still lag behind NVIDIA in cluster efficiency, interconnect bandwidth, and software stack maturity. A 3,000-card domestic cluster might only deliver 60-70% of the effective computing power of an equally sized NVIDIA cluster. This means that to complete the same training task, you'd need more cards, longer periods, and more complex parallel optimization—all of which translate into higher costs.
The second is the 'invisible threshold' of the software ecosystem. CUDA has accumulated a massive developer ecosystem over more than a decade. Algorithm engineers learn CUDA in school, open-source community model code defaults to running on CUDA, and various operator libraries, tuning tools, and distributed frameworks are all benchmarked against CUDA. Domestic GPU vendors now all have to build their own software stacks—Huawei has CANN, MetaX has MXMACA, Biren has BIRENSUPA—but ecosystem building takes time and investment, and it requires users to 'take an extra step.'
The third is the 'ceiling' of the supply chain. Domestic GPU manufacturing currently relies mainly on domestic advanced process lines, which still lag behind TSMC in capacity, yield, and maturity. In HBM, no domestic manufacturer can yet mass-produce products above HBM2E, so this segment still relies on Korean suppliers in the short term. This means that even if domestic GPU designs improve, the degree of supply chain autonomy and controllability remains limited.
Going back to MetaX's cost breakdown chart, there's actually another hidden message: The space for cost optimization isn't just in the GPUs themselves. Power supply and cooling account for $11 billion, or 20%. If you could reduce this by 30%, that's $3.3 billion in savings—more than the total electricity cost. How? Liquid cooling is currently the most certain path.
Traditional air-cooled data centers have a PUE (Power Usage Effectiveness) of 1.4-1.5, while liquid cooling can achieve below 1.1. This means not only lower electricity costs but also significantly reduced initial investment in power supply and cooling systems. With GPU power consumption exceeding 1,000 watts, air cooling is approaching its physical limits, and liquid cooling is going from 'optional' to 'mandatory.' Since the second half of 2025, the penetration rate of liquid cooling solutions in new intelligent computing centers built by major domestic operators and cloud providers has noticeably increased. The direct result of this trend is that the proportion of power supply and cooling in TCO is expected to drop from 20% to 15% or even lower.
Networking accounts for $5 billion, or 9%. In hyperscale clusters, networking costs grow superlinearly with the number of GPUs. Why? Because GPUs need high-speed interconnects, and traditional Ethernet isn't efficient at solving 'elephant flow' and 'many-to-one' problems. NVIDIA's NVLink and InfiniBand have formed barriers largely because of their advantages in cluster interconnects. But in 2025, a noteworthy trend is that Ethernet-based hyperscale interconnect solutions are maturing, and the Ultra Ethernet Consortium (UEC) is giving the industry hope for reducing networking costs. If this path succeeds, the proportion of networking costs in TCO could be further compressed.
Storage accounts for $4 billion, or 7%. AI training requires massive small-file read/write operations and high-bandwidth throughput, scenarios where traditional distributed file systems are inefficient. Since 2025, several domestic storage vendors have made noteworthy explorations in AI-native storage—through software-hardware collaborative optimization (collaborative optimization), they can reduce storage node configuration requirements while maintaining performance, thus compressing costs.
But these system-level optimizations all share a common underlying logic: They require a deep understanding and control of GPU clusters. It's not just about stacking a bunch of GPUs together; it's about vertical integration from chips to systems, from hardware to software.
This is exactly why we see that whether it's NVIDIA, Google, or Amazon, they're all moving toward 'cloud-chip-device' integration. Google's TPU was designed from the start for its deep learning framework, TensorFlow; Amazon's Trainium and Inferentia are deeply tied to AWS services; Microsoft, while buying a lot of NVIDIA GPUs, is also developing its own chips and collaborating deeply with NVIDIA at the system level.
The situation is similar in China. One of Huawei Ascend's advantages is that it combines chip design capabilities with communications technology accumulate (accumulation), allowing for deep optimization at the chip interconnect and cluster networking levels. Alibaba Pingtouge and Baidu Kunlun are also deeply collaboration (synergized) with their respective cloud businesses for the same reason.
04
There Are No Shortcuts
Looking back at that chart, its value isn't just in breaking down the cost structure; it's in breaking down a mindset.
The idea that 'relying on low electricity prices can achieve breakthroughs in the AI computing power race' gained traction because it fit an old logic of 'trading resources for advantages.' In some past industries, catching up was indeed achieved through resource endowments. But the AI computing power race is fundamentally a technology-intensive, capital-intensive, and system-intensive industry, where the weight of resource endowments is greatly diluted.
Where does true competitive advantage come from? It comes from breakthrough capabilities in core GPU technologies, from supply chain control over key segments like advanced packaging and HBM, from long-term accumulation in the software ecosystem, from innovation in system-level architecture, and from continuous evolution in business models and operational efficiency.
None of these are easy, and none can be achieved by being 'cheap.'
Over the past two to three years, domestic intelligent computing center construction has developed rapidly, with many projects following the traditional IDC model in investment thinking—focusing on campus construction, hardware deployment, and computing power leasing. However, the business logic of AI computing power differs significantly from that of traditional IDCs: GPU hardware iterates quickly, depreciation cycles are short, and project returns are highly dependent on computing power utilization. If GPUs are treated merely as standardized leasing resources without underlying algorithm optimization, cluster scheduling, and operational capabilities, the high hardware investment may not effectively translate into sustained, stable returns and could lead to significant asset pressure.
Fortunately, the industry is returning to rationality. Since the second half of 2025, we've seen that whether it's internet giants or operators, computing power investments have become more pragmatic—no longer just about 'stacking cards,' but more focused on actually usable effective computing power, on the cost per unit of computing power, and on the optimization space for software-hardware collaboration (collaboration).
There are no shortcuts. This may sound cliché, but in the AI computing power race, it remains the cruel yet real underlying logic.
-
![]()
AI Giants Start Borrowing to Fuel Computing Power Race
-
ByteDance Initiates Largest B2B Structural Adjustment, This Time It's Truly Different
-
![]()
Let's Talk About Kingsoft Office's Mid-Year Outlook and the True Strength of Its AI-Powered Office Solutions
-
Despite 150 Million Users, Struggles Persist: AIShige Faces Tough Competition from Seedance and Kling in AI Video Monetization
-
![]()
Ensuring Safe Gear Shifting in the Automotive Industry: Transitioning from 'Product Oversight' to 'Full-Chain Governance'
-
![]()
Net Profit Soars to $133.7 Billion! Azure Revenue Tops $100 Billion, with AI Fueling Microsoft's Growth
-
![]()
Before 6G Hits the Market, the U.S. Forges a 'Rules Alliance': What Challenges Await Chinese IoT Enterprises?
-
![]()
Intelligent Driving's 'Little Blue Light' Faces Ban: Night Glare and Cut-in Risks Prompt Official Action





