From large LLM models to small SLM models and then to TinyML, this field is expected to grow 31 times and spawn new business models
 11/11 2024
11/11 2024
 687
687
This is my 349th column article.
Is there a bubble in Generative AI (GenAI)? This question has increasingly become a hot topic in the industry. Currently, global investment in AI infrastructure has reached a manic scale of hundreds of billions of dollars, yet there is still no clear answer as to how large models can achieve profitability.
Amidst varying opinions, one area that is often underestimated is Edge AI. As an emerging field, Edge AI is vastly different from Cloud AI. Methods that work in data centers may not necessarily apply to industrial edge platforms such as security cameras, robotic arms, or automobiles.
Due to constraints on space, power consumption, budget, data security, and real-time requirements, there is no one-size-fits-all solution in Edge AI. This means that no single solution can meet the needs of all AI applications, and transitioning from Cloud AI to Edge AI requires the development of entirely new models.
According to research firm Counter Points, the computational power of future AIoT modules will see exponential growth. It is estimated that the number of modules equipped with Neural Processing Units (NPU) will reach 31 times the current level within the next seven years, spurring a surge of innovative applications.
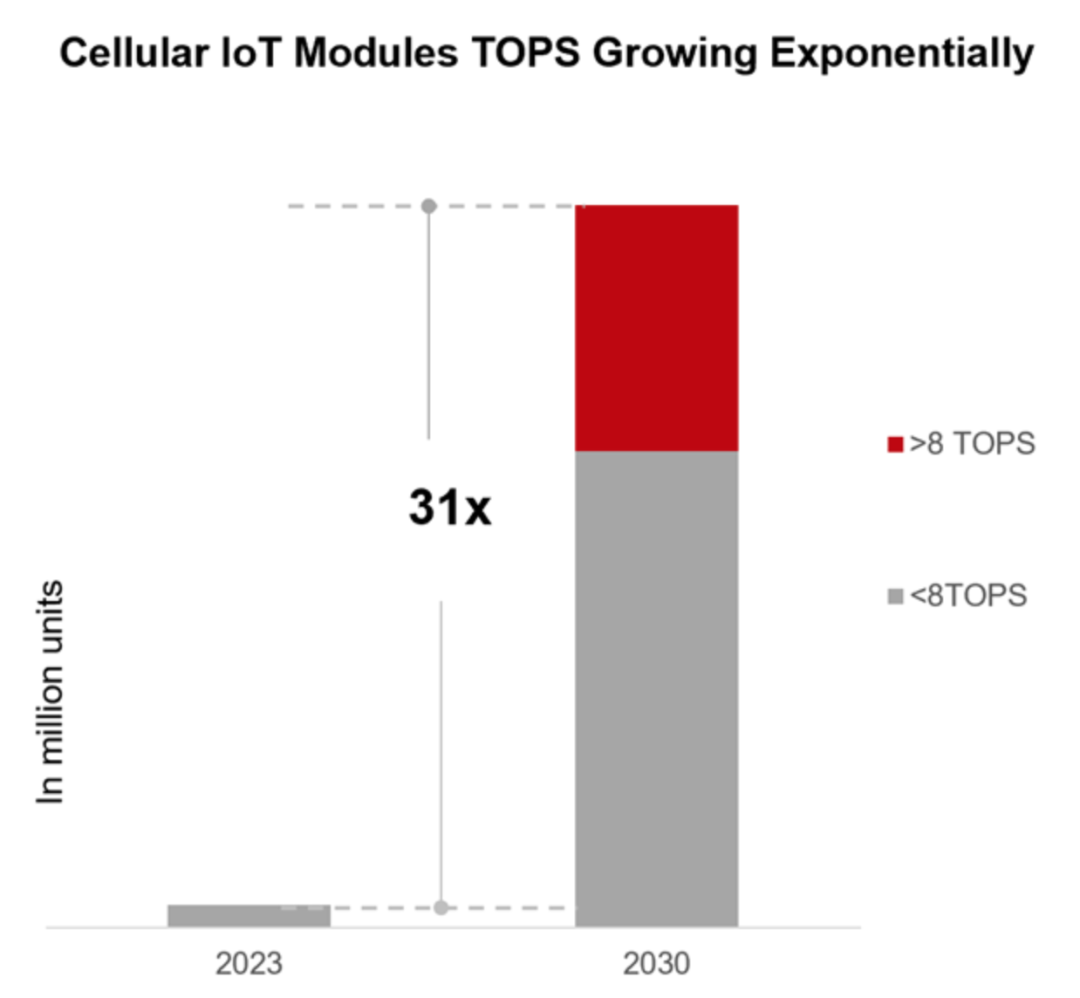
Faced with the booming Edge AI market, this article will provide an in-depth analysis. The author believes that the rise of Edge AI will spawn new business models, and Decentralized Physical Infrastructure Network (DePIN) may be an effective solution to help Edge AI avoid profitability challenges.
TinyML, SLM, and LLM: The "Troika" of Federated Language Models
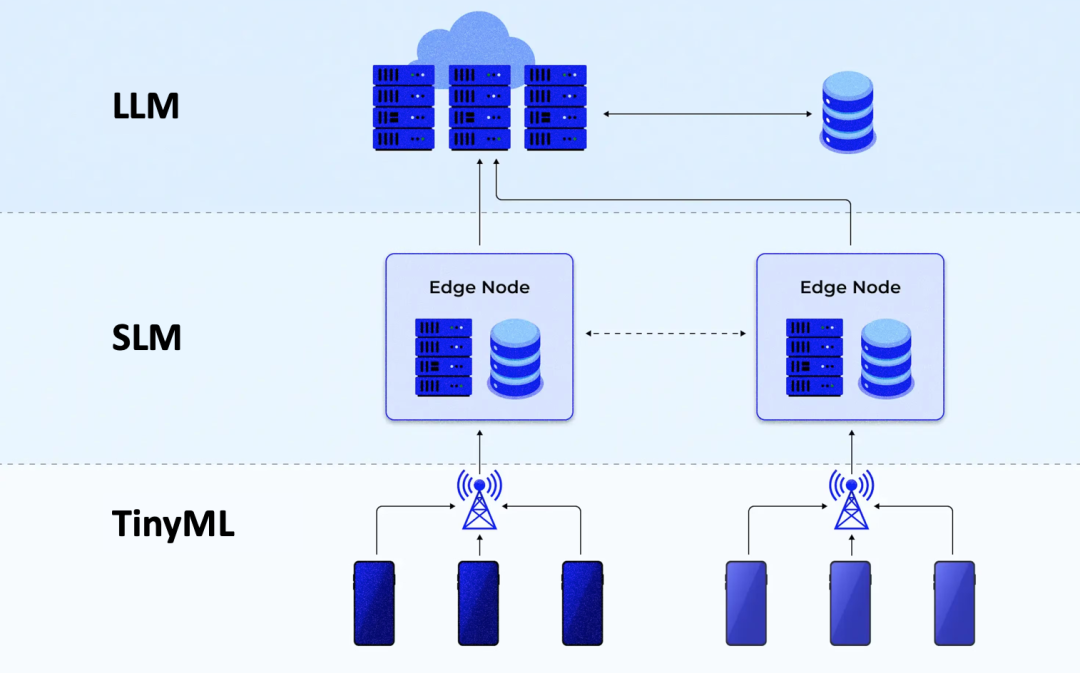
In the world of AI, the terminal, edge, and cloud play distinct roles. Their differences in form, function, and application scenarios are so significant that they can be viewed as entirely different entities.
Based on this understanding, industry insiders have proposed the concept of "Federated Large Models," aiming to deploy AI models of different sizes on the cloud, edge, and terminal layers to perform related tasks.
On the terminal side, Tiny Machine Learning (TinyML) is on the rise. TinyML is a technology that optimizes machine learning models to run efficiently on resource-constrained devices such as microcontrollers. These models are typically compact and computationally efficient, capable of tasks like speech recognition and sensor data analysis.
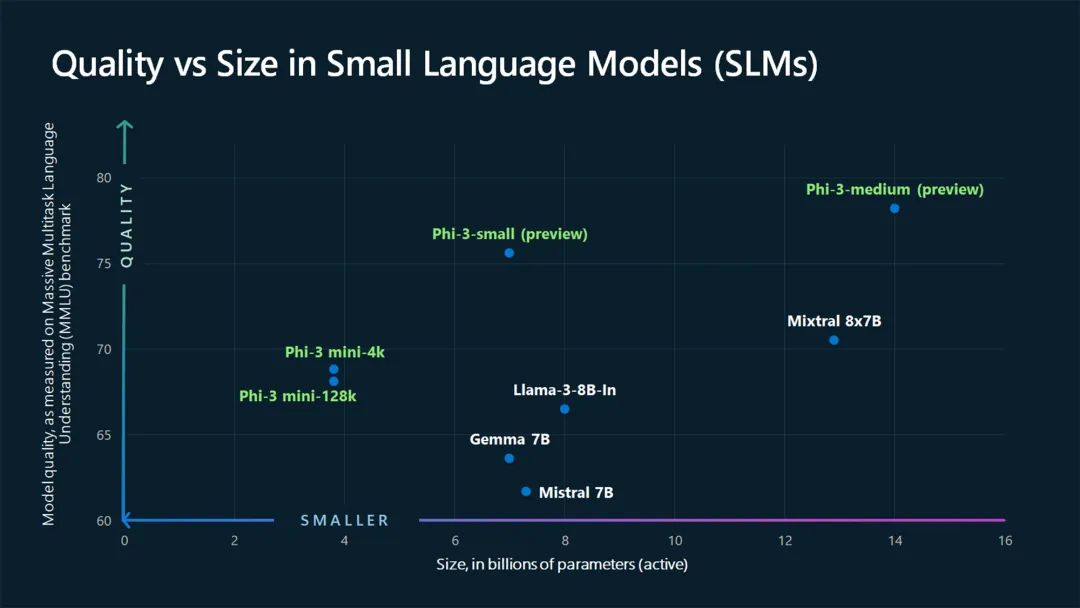
The protagonist on the edge side is the Small Language Model (SLM). SLM refers to lightweight neural network models with fewer than 10 billion parameters. Compared to large models, SLM achieves natural language processing (NLP) with fewer parameters and computational resources (as shown in the image below). Additionally, SLMs are often tailored to specific tasks, applications, or use cases.
As for the cloud, Large Language Models (LLM) are undoubtedly the frontrunners. LLM is a powerful deep learning algorithm capable of performing various NLP tasks. Thanks to massive training data and the use of multiple Transformer models, LLM possesses astonishing abilities to recognize, translate, predict, and even generate text.
The proposal of "Federated Language Models" aims to fully utilize TinyML, SLM, and LLM technologies, bringing tangible value to enterprises while ensuring privacy and security.
TinyML, with its ultra-low cost and power consumption, is ideally suited for use on resource-limited devices such as IoT terminals and wearable hardware.
SLM can be seen as a "miniature" version of LLM. Compared to large models like GPT-4 with millions or billions of parameters, SLM operates on a much simpler scale. Optimized SLMs can efficiently handle relatively simple tasks without consuming extensive computational resources.
Although not as large as LLM, SLM plays a significant role in practical applications. From text generation and question answering to language translation, SLM can handle various tasks, albeit with slightly inferior accuracy and versatility.
SLM's advantages also lie in its fast training and inference speeds. It strikes a delicate balance between performance and resource efficiency. The reduced number of parameters makes SLM training more economical and efficient, while offloading processing workloads to edge devices further reduces infrastructure and operational costs.
BrainChip's practice demonstrates that combining TinyML and SLM can achieve remarkable results: a 50-fold reduction in model parameters, a 30-fold reduction in training time, a 5,000-fold reduction in multiply-accumulate operations (MAC), and even improved accuracy. The improvement in performance and power efficiency is proportional to model efficiency.
According to Tirias Research, if by 2028, 20% of LLM workloads are offloaded from data centers using hybrid processing with TinyML and SLM within edge devices and terminal hardware, data center infrastructure and operational costs will decrease by $15 billion, and overall power consumption will drop by 800 megawatts.
From Cloud to Edge: The Inevitable Path of GenAI Migration
With the continuous development of AI technology, more and more AI models are migrating from cloud data centers to edge devices. Behind this trend are considerations of cost, real-time performance, and security.
Running AI models in the cloud, although leveraging the powerful computing resources of data centers, often faces issues such as high costs, network latency, and data security risks. In contrast, deploying neural network models on edge devices through optimization techniques like model compression, known as edge computing, promises to significantly reduce costs and latency while improving data security without compromising performance.
However, for many edge application scenarios, simply "shrinking" data center solutions is not the best choice. In critical sectors such as healthcare, automotive, and manufacturing, edge AI applications typically focus on real-time processing of sensor data, placing higher demands on model size, accuracy, and execution efficiency.
This has given rise to the concept of "EdgeGenAI," which refers to generative AI executed on devices. Increasingly, hardware is demonstrating EdgeGenAI capabilities, with chip vendors like Qualcomm and NVIDIA showcasing the potential to run models like Stable Diffusion and LLaMA on mobile devices, signifying the arrival of EdgeGenAI.
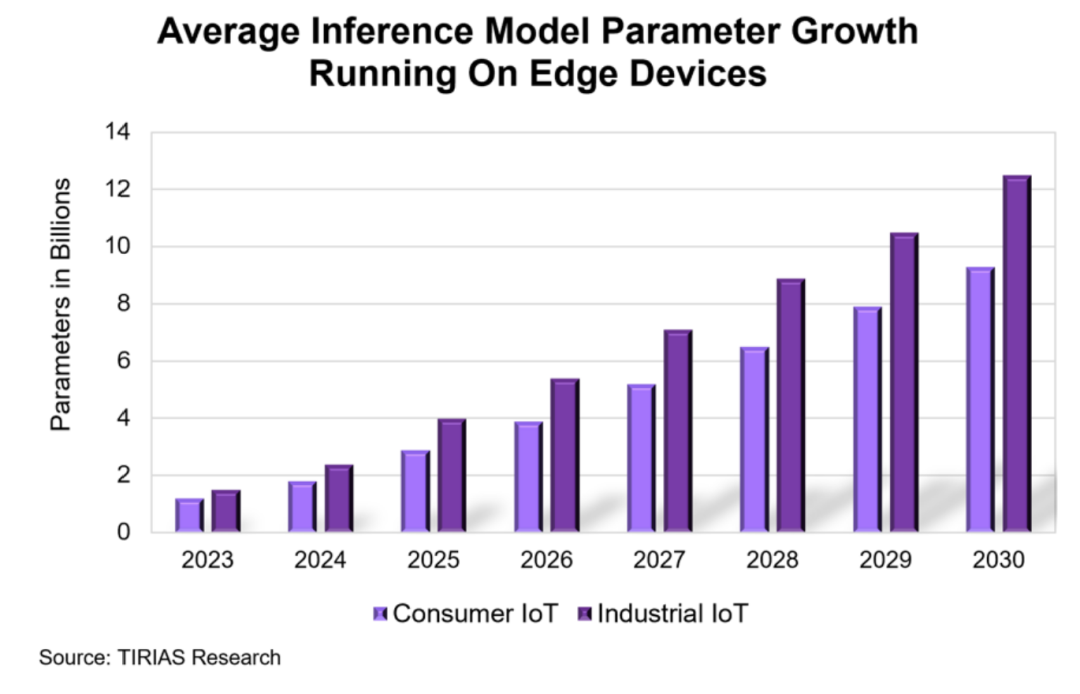
According to Tirias Research, with the continuous optimization of AI model compression and the increasing computing power of terminal and edge devices, more GenAI models will be able to perform inference and execution on device ends. This means that the scale of models suitable for edge processing will continue to increase over time, expanding the local AI processing capabilities of devices.
Simultaneously, the average size of inference model parameters carried by consumer and industrial IoT devices is also growing. To assess the development prospects and total cost of ownership (TCO) of GenAI, Tirias Research has subdivided and modeled different categories of devices, as shown in the image below.
The study found that processing AI tasks locally on devices can not only significantly reduce response latency and enhance user experience but also effectively mitigate data privacy and security concerns. By reducing or eliminating data interactions with the cloud, sensitive data and GenAI-generated results can be securely protected at the device level, drastically lowering the risks of privacy breaches and cyberattacks.
However, not all GenAI applications are suitable for full on-device processing. Limited by chip computing power, memory capacity, and power budget, many large models still cannot be efficiently executed on a single device.
The proposal of "Federated Large Models" comes at an opportune time to address this issue.
By Reasonably allocate computing tasks between devices and the cloud , This hybrid computing mode reduces latency 、 While protecting privacy , Being able to fully utilize the computing advantages of the cloud 。
For example, in image generation applications, the initial image can be quickly generated on the device, while subsequent enhancements and optimizations are handled by the cloud. In scenarios requiring the integration of multi-source data, such as real-time map updates, combining local information with cloud models can also achieve synergistic effects. In some industry applications involving proprietary data, such as industrial and medical fields, security considerations may necessitate completing some sensitive computation tasks in the cloud.
Based on this, edge AI is poised for explosive growth. According to Counter Point, by 2030, IoT modules equipped with AI computing power will account for 25% of overall shipments, far exceeding the 6% in 2023.
In the automotive sector, AI assistants are reshaping the autonomous driving experience through voice interaction, navigation guidance, and entertainment control. In retail, smart POS terminals equipped with AI modules leverage capabilities such as palm print or facial recognition and behavior analysis to aid in customer insights, inventory management, and risk prevention. In smart home scenarios, routers integrated with AI functionality are poised to become the hub for subsystems like lighting, security, and energy management. Additionally, drones, industrial handheld devices, service robots, and other fields will also become major application areas for edge AI chips.
DePIN Empowers Edge AI, Pioneering a New Profit Model

In the commercialization of AI, the path to profitability for Large Language Models (LLM) has always been a focus of attention.
Although generative AI startups frequently secure high-value funding and reach record-high valuations (as shown in the image below), converting technological advantages into sustained and stable revenue remains an unresolved challenge.
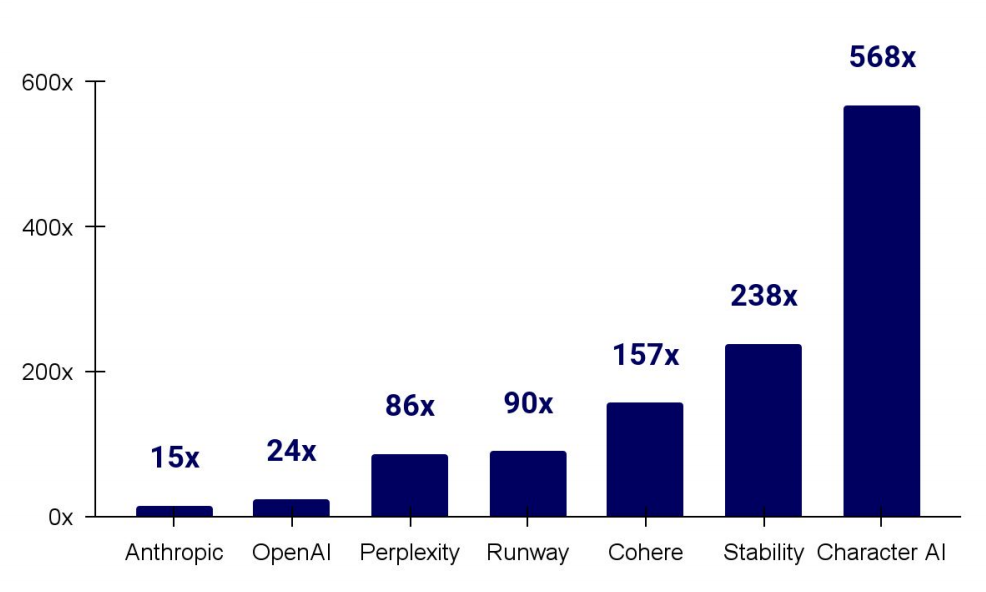
Meanwhile, as AI models continue to migrate to the edge, the market demand for embedded AI devices is growing rapidly. In this context, the combination of Decentralized Physical Infrastructure Network (DePIN) and edge AI offers a novel solution to this challenge.
The core concept of DePIN is to connect physical devices scattered around the globe through blockchain technology and token economics, forming a decentralized resource-sharing network. In this network, device owners can rent out idle computing, storage, bandwidth, and other resources to demanders in exchange for token incentives. Demanders, in turn, can obtain the required infrastructure services at lower costs and with higher flexibility.
Introducing the DePIN model into the edge AI domain can significantly promote the popularization and application of AI devices.
On the one hand, device manufacturers can join the DePIN community, pre-install AI devices into the decentralized network, and sell device usage rights through resource sharing rather than one-time hardware sales. This "device-as-a-service" model significantly reduces upfront procurement costs for users and enhances the ease of use of edge AI.
On the other hand, AI model providers can also utilize the DePIN network to provide trained models to device owners in the form of APIs and earn tokens based on usage. This pay-as-you-go mechanism significantly reduces the inference costs of edge AI, making high-quality AI services affordable for small and medium-sized enterprises and individual developers.
The case of a pet smart collar manufacturer provides a vivid example of DePIN empowering edge AI. The manufacturer plans to introduce smart collars into the DePIN community, constructing a decentralized pet data-sharing network. Leveraging the collar's built-in activity monitoring and location tracking capabilities, massive amounts of pet behavior data will be collected and circulated, serving as an important data source for training pet AI models. Pet owners can selectively share this data and receive token incentives.
This decentralized AI paradigm not only significantly improves the real-time performance and privacy of data processing but also provides continuous data support for the development and optimization of pet AI models.
Simultaneously, the manufacturer also plans to open up the edge computing power of the collar, allowing third-party developers to deploy pet AI models onto the collar for scenario-based AI applications such as abnormal behavior detection, emotion recognition, and security zone warnings. This "plug-and-play" open ecosystem greatly unleashes the imagination of edge AI, spawning a host of pet-centric innovative applications and services.
The combination of DePIN and edge AI not only opens up new sales channels and profit models for device manufacturers but also builds a decentralized infrastructure for massive data aggregation and rapid model deployment for AI enterprises.
Closing Thoughts
With the maturity of technologies such as TinyML and SLM, AI models are migrating from the cloud to the edge on a large scale, giving rise to new application forms like EdgeGenAI. Through optimization techniques such as model compression and hybrid computing, models with billions of parameters can now efficiently run on terminal devices like smartphones. In the era of intelligent connectivity, edge AI will empower industries such as automotive, retail, and home furnishing, creating tremendous commercial value.
However, the current edge AI ecosystem still faces challenges such as high device costs, high development thresholds, and single profit models. The introduction of the decentralized physical network DePIN is expected to effectively solve the commercialization dilemma of edge AI by connecting AI devices to a resource-sharing network, establishing a pay-as-you-go mechanism, and constructing an open ecosystem.
References:
-
![]()
Total Investment Hits Nearly 3.28 Billion! Goertek Launches Mass Production of 12-Inch Transparent Substrate Wafer for AR Glasses’ Micro-Nano Optical Components
-
![]()
Why Is This Precision Optical Film Leader Worth Reevaluating with a Tens of Millions Procurement?
-
![]()
AI Costs Plummet by 90% Over Nine Years: Key Insights from Davos You Shouldn’t Miss
-
Doubao, Your Late-Night AI Companion, Now Eyes Profitability
-
![]()
SRC Empowers SEER Intelligence to Reach a Market Cap of Tens of Billions, Yet Fails to Sustain Profitability
-
![]()
China’s Embodied AI Industry Faces Fierce Domestic Competition, Making Overseas Expansion Essential for Survival
-
![]()
32.8 Billion Yuan Investment! Goertek’s 12-Inch AR Glasses Optical Wafer Base in Lingang Begins Operations
-
![]()
How Far is the All-New Li Auto L8 from Being the Best Five-Seat SUV with In-House Full-Stack Development?






