What Technologies Enable Autonomous Vehicles to Predict Their Surrounding Environment?
 10/10 2025
10/10 2025
 549
549
Why Does Autonomous Driving Necessitate "Prediction"?
For autonomous vehicles to operate safely, merely being aware of the present environment is insufficient; it is paramount to anticipate future events. For instance, a human driver not only observes the parking space ahead but also assesses whether the adjacent vehicle intends to change lanes or if a pedestrian is about to cross. Similarly, for autonomous vehicles, merely reporting the position and speed of objects would compel the planning module to react passively, potentially leading to emergency braking, abrupt turns, or passenger discomfort. The essence of prediction lies in providing the decision-making layer with advance notice of "potential future events," enabling the vehicle to proactively prepare and make decisions such as decelerating early, aborting a lane change, or gradually yielding, thereby converting unexpected events into manageable scenarios.
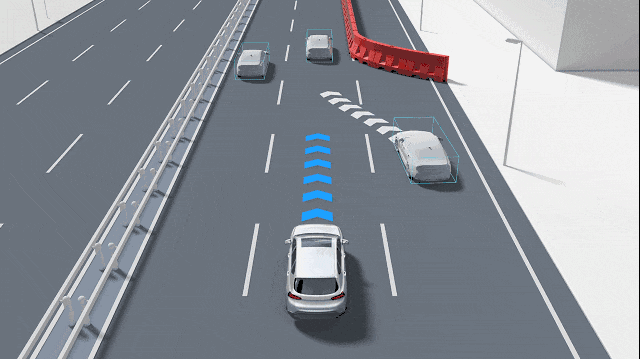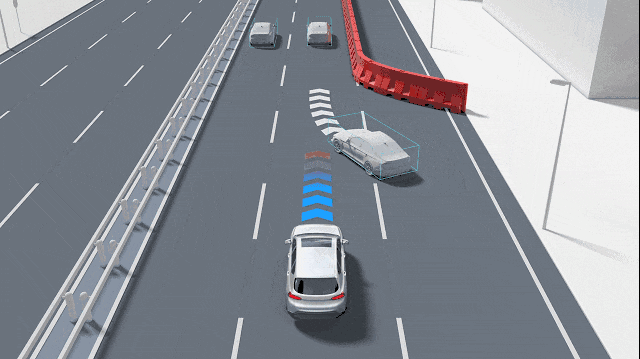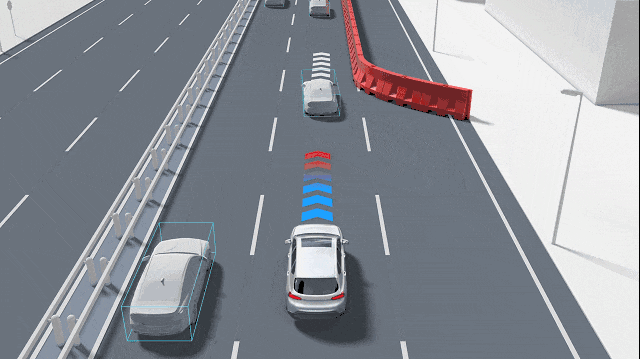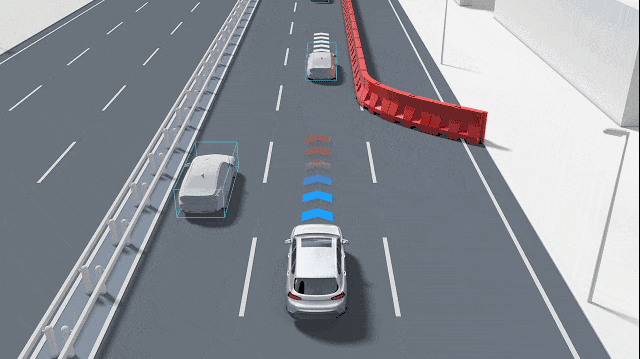
Prediction transcends merely enabling autonomous systems to "think"; the temporal scale of prediction is equally critical. Short-term predictions, spanning the next 1-2 seconds, can often be derived by extrapolating from current speed and direction to mitigate immediate risks like rear-end collisions. Predictions extending to 3-6 seconds or even up to 10 seconds necessitate an understanding of others' intentions, such as whether a vehicle ahead is about to merge or exit a ramp or if an oncoming cyclist is about to turn. These two types of predictions employ distinct techniques: short-term predictions rely more on physics and filtering, whereas long-term predictions hinge on comprehending road semantics and human-vehicle interactions. Prediction is not an optional feature but an essential capability for transforming "perception" into "anticipation of potential events."
How Does Autonomous Driving Perform Prediction?
To facilitate accurate predictions in autonomous vehicles, reliable input is indispensable. Cameras, radars, and LiDAR sensors "observe" surrounding objects, while tracking modules link the same target over time to form trajectories, informing the system of the target's current location, speed, and direction. High-definition maps play a pivotal role by providing information on lane positions, intersections, and pedestrian crossings, significantly narrowing down future possibilities. Without stable tracking and time synchronization, the foundation for prediction becomes precarious.

Several intuitive methods exist for achieving prediction. The simplest approach treats vehicles or pedestrians as physical entities moving in accordance with the laws of physics, extrapolating their future positions based on current speed and acceleration. This method is swift and stable, suitable for short-term decision-making. Another method, probabilistic/filtering-based, incorporates uncertainty by employing mathematical tools to maintain a distribution of possible states, providing greater stability in the presence of sensor noise or occlusions. A third approach leverages data-driven methods, particularly deep learning, which ingest historical trajectories, map information, and surrounding vehicle behaviors into models to directly output multiple possible future trajectories. These learning-based methods can capture strategic behaviors like yielding, lane changing, and bypassing but necessitate large volumes of training data.
In real-world traffic, participants often exhibit multiple potential actions. For example, at an intersection, a vehicle may proceed straight or turn left, a phenomenon known as multimodality. Consequently, prediction technologies typically do not provide a single "most likely" trajectory but rather several candidate trajectories with associated probabilities or even a probability distribution over trajectories. This approach enables the planner to weigh risks based on probabilities. While a certain trajectory may be the most probable, if another low-probability but high-risk trajectory could lead to a collision, the system will adopt a more cautious strategy. Additionally, the prediction system must discern between scenarios encountered during training (model familiarity) and those not (model uncertainty). If the model lacks confidence in the current scenario, the system should proactively become cautious, such as by decelerating or requesting human intervention.
A critical facet of prediction in autonomous driving systems is modeling interactions, as road participants influence one another. For instance, a vehicle intending to change lanes will observe the speed of adjacent vehicles, whose reactions will, in turn, affect its decision. Predicting each target independently often leads to inaccuracies, especially in congested urban environments where independent predictions may lack relevance. Current methods commonly "aggregate" information from surrounding objects to learn how they interact. Some employ attention mechanisms to weight influential objects, while others represent roads and vehicles as graph structures and utilize graph neural networks to propagate interaction information. In essence, interaction modeling is a pivotal step in aligning predictions with real-world behaviors.
Another significant detail in applying prediction technologies to real-world scenarios is how to represent information. Early systems often depicted scenes as bird's-eye-view grid images (BEV) and processed them with convolutional networks. While intuitive, this method is inefficient for representing long-distance road topologies. More recently, vector-based representations of lanes and intersections have gained popularity, combined with graph networks or vector-based Transformers, which conserve computational resources and better align with road structures. In practice, modular approaches are frequently chosen, where perception modules first produce structured information (objects, trajectories, map semantics), and prediction modules then utilize these clean inputs for judgment, facilitating validation and interpretability.
What Are the Practical Challenges of Deploying Prediction on Real Vehicles?
Deploying a prediction model from the laboratory to a real vehicle introduces numerous challenges. The first is latency: more complex models result in slower inference, which diminishes the decision-making time window and affects the ability to respond to sudden events. The second is computational power: onboard resources are constrained, necessitating trade-offs between accuracy and speed. The third is validation: relying solely on error metrics during model training is inadequate. Predictors must be evaluated within the entire perception-prediction-planning-control loop through simulations and road tests to assess how the vehicle system ensures safety when predictions are incorrect. Closed-loop evaluations are more effective than focusing solely on trajectory errors in identifying real-world risks.
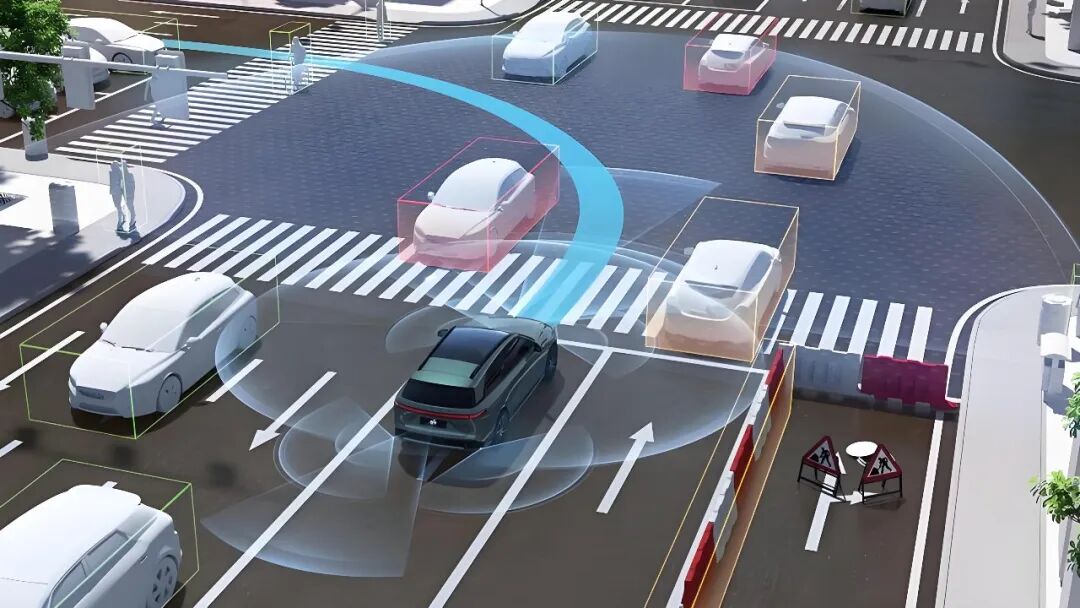
For prediction models, data is crucial yet challenging to obtain. Most perilous scenarios rarely occur, making it difficult to collect sufficient samples on real roads. To address this, many technical implementations utilize simulations to synthesize or amplify these rare scenarios for training and validation or perform scenario mining to extract complex scenarios from real data as key test cases. Additionally, annotation must be meticulous; trajectory labels require precise time alignment and positioning to prevent the model from learning incorrect patterns.
Prediction models also necessitate clear safeguarding strategies during runtime. The prediction module must align with the planning module on interfaces, such as the number of candidate trajectories, how confidence levels are expressed, and default actions when confidence is low. The autonomous driving system must detect input distribution shifts; if the current scenario differs significantly from training data, the system should automatically trigger more cautious strategies. Many accidents arise not from a single module's failure but from inconsistent risk understanding between modules, leading to cascading effects. Therefore, interface and degradation strategy designs must be considered at the system level from the outset.
Final Thoughts
Predicting future traffic environments is both a scientific and systems engineering challenge. It integrates physical laws, probabilistic theory, and large-scale data-driven methods while requiring rigorous engineering validation and runtime safeguarding to ensure safety. A truly deployable solution entails a prediction-planning loop capable of outputting multimodal candidates, providing credible confidence levels, and collaborating with the planner for risk-weighted decision-making.
-- END --
-
![]()
Enflame Tech's IPO Journey: Navigating Over 5.9 Billion Yuan in Losses and Soaring Debt in Q1 This Year
-
![]()
Trillion-Yuan Giant Li Shufu 'Streamlines': Could Levc Be the Casualty?
-
![]()
AI Competes for Electricity and Generates Power in the Gobi Desert
-
![]()
The First Batch of Victims of the AI Bubble: Programmers
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'






