Another Blockbuster in the Open-Source Image Generation Community! Nanyang Technological University & StepGen Release iMontage: Unlocking New "Many-to-Many" Generation Capabilities!
 12/01 2025
12/01 2025
 677
677
Interpretation: The Future of AI-Generated Content

Key Highlights
iMontage's unified model can handle a variable number of input/output frames, effectively bridging video generation and high dynamic range image generation.
It constructs a task-agnostic temporal diverse data pipeline and combines multi-task training paradigms to ensure learnability across heterogeneous tasks and temporal structures, achieving powerful many-to-many generalization capabilities.
Through extensive experiments with variable parameters, the model's exceptional performance is validated across mainstream image generation and editing tasks. Massive visual results and comprehensive evaluation metrics show that this model reaches SOTA levels in the open-source community, with some effects even rivaling commercial models.
Summary Overview
Problems Addressed
Limited Dynamic Range: Pre-trained video models, due to their continuous training data, lack dynamic diversity and richness in generated content.
Capability Barriers: There is a gap between video generation models and image generation/editing tasks, lacking a unified framework capable of handling multi-input-multi-output image tasks.
Prior Preservation: When extending model capabilities to the image domain, how to avoid destroying valuable temporal priors (motion consistency) learned from video data.
Proposed Solution
Core Framework: Introduces iMontage, a unified framework capable of processing variable-length image set inputs and outputs.
Core Method: Reconstructs powerful pre-trained video models into versatile image generators.
Key Technical Points:
Adopts a sophisticated and low-intrusion model adaptation strategy.
Designs a task-agnostic temporal diverse data pipeline.
Incorporates multi-task training paradigms.
Applied Technologies
Pre-trained Video Models: Serve as the foundation, providing strong temporal coherence priors.
Model Adaptation/Fine-Tuning Techniques: Migrate video model capabilities to image tasks in a low-intrusion manner.
Multi-Task Learning: Unifies learning of various image generation and editing tasks within a single model.
Customized Data Construction: Creates heterogeneous, temporally diverse datasets suitable for training this unified model.
Achieved Effects
Exceptional Performance: Excels in multiple mainstream multi-input-multi-output tasks, achieving strong cross-image contextual consistency.
Expanded Dynamic Range: Generates scenes with extraordinary dynamic tension that breaks traditional boundaries, significantly enhancing content diversity.
Strong Generalization: Through multi-task training and diverse data, the model possesses powerful many-to-many generalization capabilities.
Industry-Leading: Reaches SOTA levels in the open-source community, with some effects rivaling commercial models.
Methodology
Model Design
Network Architecture. As shown in Figure 2 below, this paper adopts a hybrid-to-single-stream multimodal diffusion Transformer, paired with a 3D VAE for images and a language model for text instructions. All components are initialized from HunyuanVideo: MMDiT and 3D VAE are taken from the I2V checkpoint, and the text encoder is taken from the T2V checkpoint. Reference images are encoded separately by the 3D VAE and then patchified into tokens; text instructions are encoded into text tokens by the language model. Following the I2V paradigm, this paper concatenates clean reference image tokens with noisy target tokens and inputs them into the image branch blocks. By constructing variable-length attention maps on its image tokens, supplemented by prompt engineering guidance, this paper trains the model to adapt to variable numbers of input/output frames. During training, the VAE and text encoder are frozen, and only MMDiT undergoes full-parameter fine-tuning.
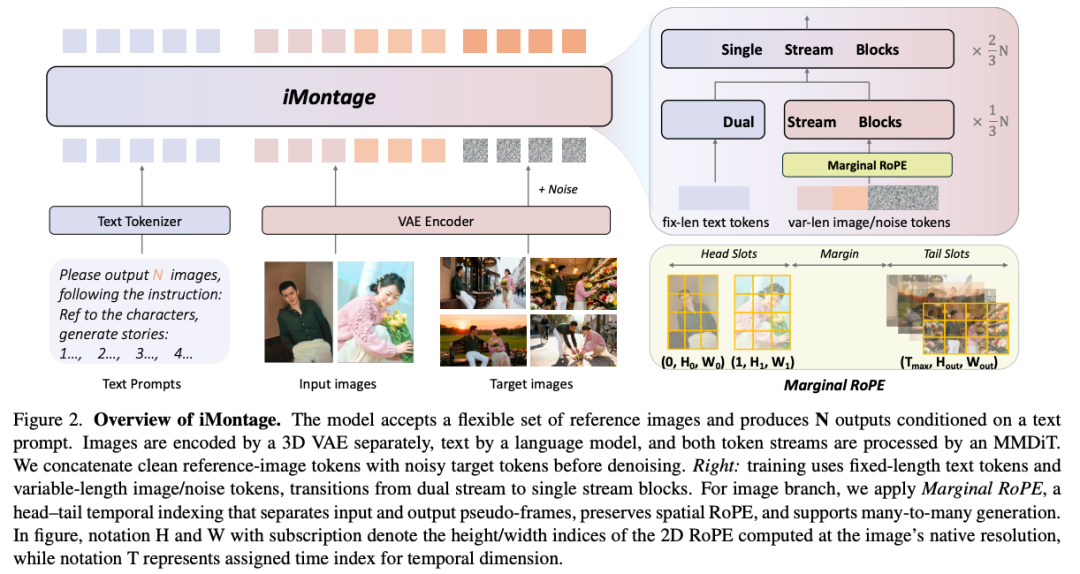
Positional Encoding. The key goal is to enable Transformer perception of multiple images without interfering with original positional geometry. This paper adopts a simple yet effective strategy: treating all input/output images as pseudo-frames on a timeline, assigning each frame a unique temporal index while maintaining its native spatial resolution and 2D positional encoding unchanged. Specifically, this paper retains the pre-trained spatial RoPE and introduces a separable temporal RoPE with per-frame index offsets, providing cross-image ordering cues while maintaining spatial distribution. Inspired by L-RoPE, this paper assigns input images to earlier temporal positions and output images to later positions. In practice, this paper allocates a 3D RoPE with 32 temporal indices, reserving for inputs and for outputs, leaving a wide temporal gap between them. This head-tail layout reduces positional interference between inputs and targets, empirically promoting more diverse output content while maintaining temporal coherence.
Prompt Engineering. This paper employs a pure text instruction interface driven by a powerful LLM encoder, without requiring masks or auxiliary visual embeddings. To unify heterogeneous tasks, this paper pairs a set of generic prompts with task-specific templates. For generic prompts, this paper (i) prepends system-level guidance: "Please output X images according to the instructions:"; (ii) adopts an interleaved multimodal format, explicitly marking image positions in prompts through text placeholders.
Dataset Construction
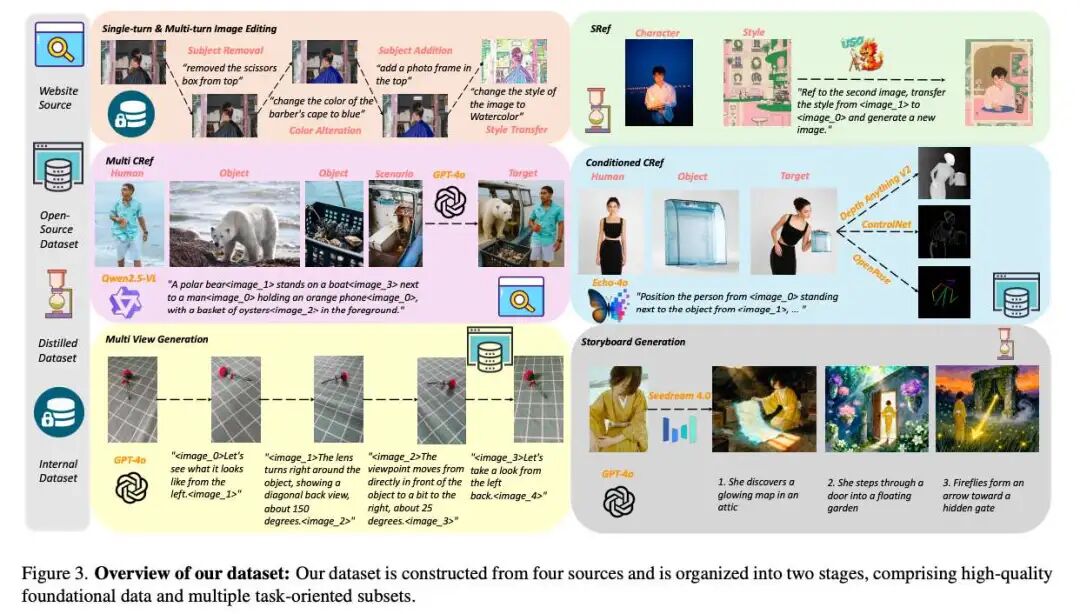
This paper divides data construction into two stages: pre-training datasets and supervised fine-tuning datasets. An overview of dataset construction is shown in Figure 3 below.
Pre-training Datasets
This paper divides pre-training data into two pools: image editing pools and video frame pair pools, both sourced from internal corpora. The image editing pool covers most single-image editing tasks, providing paired (input, edited) images along with detailed, fine-grained instructions specifying operations. The video frame pair pool contains high-quality frame pairs extracted from videos (with associated captions), included after rigorous quality screening. This paper further optimizes video frame pairs through the following filtering criteria:
For frame pairs from the same clip, this paper applies optical flow estimators for motion filtering: calculating average motion magnitude for each sample, prioritizing or weighting high-motion instances to increase their proportion. To enhance dynamic diversity, this paper concatenates clips from the same source video and re-crops them (without relying on motion or camera change heuristics), generating cross-transition frame pairs and alleviating quasi-static content bias.
The filtered dataset contains 5 million image editing pairs and 15 million video frame pairs, providing supervisory signals for high dynamic content generation and robust instruction following.
Multi-Task Datasets
This paper's multi-task datasets are constructed based on tasks, covering one-to-one to many-to-many tasks. The data construction process for each task is as follows:
Multi-Conditional References. This paper crawls web posts to collect reference images of people, objects, and scenes. Person images are filtered to single-shot views using detectors; object/scene images require no additional filtering. VLM generates conditional reference prompts by randomly combining source data, GPT-4o generates corresponding images, and VLM scores and filters candidate samples. This process yields approximately 90,000 high-quality samples.
Conditional References. Unlike the conditional reference dataset, this paper collects data from the open-source dataset Echo-4o. This paper applies classic ControlNet to generate control maps for target images: using OpenPose[5] to generate person poses for composite images, DepthAnything-V2 to generate depth maps for target images, and adopting the Lineart model as an edge detector. This paper adds these conditional pairs to Echo-4o, creating a new conditional reference dataset of approximately 50,000 samples.
Style References. This paper constructs style reference data following the conditional reference approach: crawling person posts and filtering person images using VLM aesthetic scores[1] as content references, collecting hand-drawn illustrations from open-source resources as style references. Using a subject-style model, this paper randomly pairs content and style to generate images, then VLM scores the outputs and checks for identity consistency with content images to prevent style leakage. This process yields 35,000 samples.
Multi-Round Editing. This task requires generating multiple responses simultaneously according to instructions, with sub-step instructions covering all editing tasks in the pre-training image editing dataset. This paper extracts data from internal datasets, collecting approximately 100,000 samples.
Multi-View Generation. This paper constructs a multi-view dataset from the open-source 3D corpus MVImageNet V2. For each base sample, 1-4 additional viewpoints are randomly selected, and GPT-4o describes relative camera motion between adjacent images in continuous order, providing concise supervision for multi-view generation. This paper collects approximately 90,000 samples.
Storyboard Generation. Storyboard generation is closely related to narrative generation settings but emphasizes high diversity between panels, such as dramatic scene changes and cross-image character action differences. Leveraging the recent commercial foundation model Seedream4.0, this paper distills high-quality supervisory signals from its outputs to construct instruction-image sequences for training. Starting from internal character image datasets, this paper applies face detection and NSFW filters to obtain full-face character reference images. Subsequently, instruction templates are designed to guide Seedream4o in generating semantically rich, dynamically changing scenes and multi-panel stories. Generated images are annotated with descriptions by GPT-4o, producing concise storyboard (instruction, image) pairs as supervisory signals. This paper collects approximately 29,000 samples.
Training Scheme
This paper adopts a three-stage training strategy, dynamically mixing the aforementioned constructed datasets: including a large-scale pre-training stage, a supervised fine-tuning stage, and a high-quality annealing stage:
Pre-training Stage. This stage uses the pre-training dataset for training to instill instruction-following capabilities and adapt the model to high dynamic content. Since this paper initializes from pre-trained backbone networks, this paper abandons progressive resolution scheduling[7,16,18]; instead, adopting an aspect ratio-aware resolution bucketing strategy: for each sample, selecting the best-matching size from a set of 37 standard resolutions and adjusting accordingly. Batch size in this stage is dynamically adjusted based on sequence length, balancing token budgets across different resolutions to achieve smoother and more stable optimization.
Supervised Fine-Tuning Stage. This paper explores the optimal approach for unifying highly variable multi-tasks in this stage. This paper's strategy can be summarized as follows: • Mixed Training: Full-task joint training. Training all tasks together in a single mixed pool. • Phased Training: Curriculum learning. A two-stage plan: first training three many-to-one tasks, then adding three multi-output tasks for continued mixed training. • Cocktail-Style Mixed Training: Difficulty-sorted fine-tuning. This paper observes significant training difficulty differences across tasks, prompting this paper to conduct mixed training according to difficulty. In practice, starting with the simplest task, then introducing the next simplest task while reducing the sampling weight of the first task, continuously adding one more difficult task each time and gradually adjusting the mixing weights until the hardest task is incorporated and receives the largest training share.
Ultimately, this paper selects the cocktail-style mixed training strategy, with detailed discussions in the ablation study. In all mixed training, this paper applies weights according to each task's data volume to ensure equal treatment of all tasks. This stage allows input images to adopt different resolutions while fixing output resolutions for convenience. Due to variable input image resolutions, this paper sets a single-GPU batch size of 1 throughout the supervised fine-tuning stage.
High-Quality Stage. In image and video generation, it is widely observed that concluding training with a small batch of high-quality data improves final fidelity[39,64,71]. This paper adopts this strategy: selecting high-quality subsets for each task through a combination of manual review and VLM assistance, followed by a brief unified fine-tuning across all tasks after supervised fine-tuning. In this stage, this paper anneals the learning rate to zero.
All experiments are conducted on 64 NVIDIA H800 GPUs. Each training stage employs a constant learning rate, with training objectives following flow matching.
Experiments
As a unified model, iMontage demonstrates strong performance across various tasks, even comparable to fixed input/output models. Note that this paper's model requires only a single inference pass, defaulting to 50 diffusion steps. For clarity, this paper organizes results by input-output cardinality: divided into one-to-one editing, many-to-one generation, and many-to-many generation.
One-to-One Editing
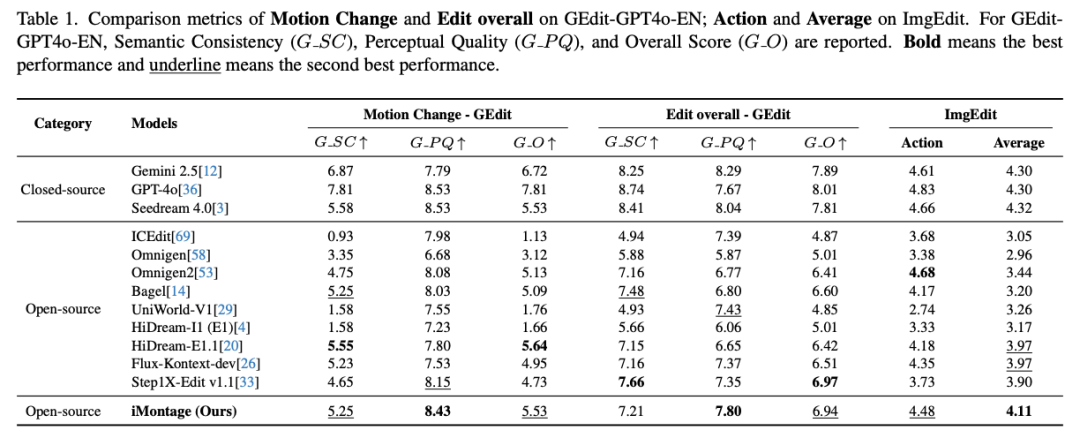
This paper reports competitive quantitative metrics and striking qualitative results in instruction-based image editing tasks. This paper compares against twelve strong baseline models, including native image editing models, unified multimodal large language models, and powerful closed-source products. Average metrics on the GEdit benchmark and ImgEdit benchmark are shown in Table 1. Except for closed-source and commercial models, iMontage outperforms other models on both benchmarks, demonstrating strong performance.
This paper also reports metrics for motion-related subtasks in Table 1. This paper's method exhibits superior motion-aware editing capabilities, with strong temporal consistency and motion priors. These gains align with expectations: this paper inherits strong world dynamic knowledge from large pre-trained video backbone networks and reinforces it through pre-training on high-dynamic video-frame corpora. Visual results for one-to-one image editing are shown in Figures 6 and 7 below.


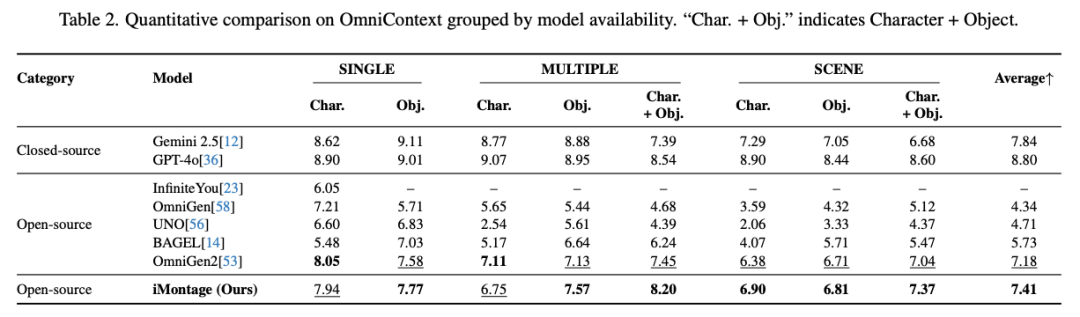
Many-to-one Generation
The core challenge of multi-input lies in retaining all content while achieving harmonious fusion. Results are reported on the OmniContext benchmark, designed to comprehensively evaluate model contextual generation capabilities. This paper compares metrics against seven baseline models, with detailed metrics provided in Table 2 below. Representative results are visualized in the supplementary materials, demonstrating iMontage's ability to handle diverse tasks while preserving source image context. Challenging cases are selected to emphasize control and fidelity: in multi-conditional reference tasks, the model fuses multiple reference cues without altering core content while faithfully following complex instructions by generating high-detail backgrounds; in conditional reference tasks, the model respects conditional signals while preserving character details (a common challenge for generative models); in style reference tasks, the paper includes both scene-centric and character/object-centric inputs to showcase strong style transfer capabilities while maintaining style and identity.
Many-to-many Generation
Generating multiple outputs while maintaining consistency is highly challenging. This paper further raises standards by requiring cross-output content consistency and temporal coherence. To assess capabilities, three distinct tasks are considered:
Multi-view Generation. This simulates camera rotation, rendering new perspectives from a single reference image using natural language descriptions of camera motion. This temporally continuous setting investigates whether models preserve identity, geometry, materials, and background context during perspective changes. Identity/structural consistency across views is reported, with long rotation arcs visualized to emphasize continuity. All visual results are shown in Figure 10 below.

Multi-round Editing. Most image editors support multi-round processes through sequential inference but often suffer from drift issues (overwriting non-target content). This paper treats multi-round editing as a content preservation task: given an initial image and a sequence of editing instructions, the model should localize changes while maintaining other parts. All visual results are shown in Figure 7 above.
Storyboard Generation. This represents the most comprehensive setting: temporally, models must generate smooth, continuous trajectories while handling highly dynamic transitions (e.g., hard cuts, large camera or subject movements, and scene changes); spatially, content consistency must be maintained by preserving identity, layout, and fine-grained appearance across all outputs.
As visualized in the supplementary materials, iMontage generates coherent and highly diverse results for all three settings in a single forward pass. To our knowledge, this is the first model to unify these tasks within a single model and single inference.
To better quantify multi-output capabilities, a quantitative study is conducted under the storyboard setting, comparing our method against two unified systems (OmniGen2 and UNO) and one narrative-focused baseline (StoryDiffusion). We focus on two dimensions: identity preservation and temporal coherence. The former measures how well each generated character matches reference identities (particularly full-body details like clothing, skin tone, and hairstyle), while the latter captures cross-frame consistency between generated images. For evaluation, the tested OmniGen2 and UNO models are optimized via UMO[11] to improve quality metrics like identity preservation. For metrics, DINO and CLIP feature similarity and a VLM scoring system are adopted. Comparison scores are provided in Table 3 below, with visual comparisons shown in Figure 4 below.
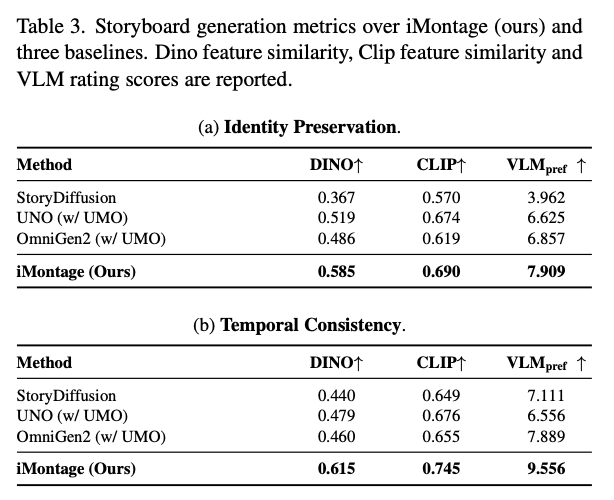

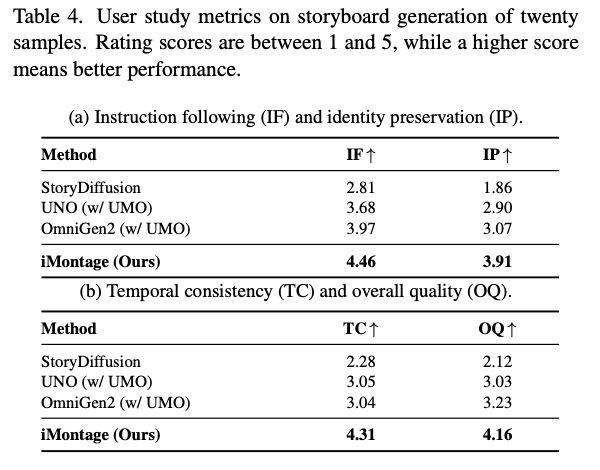
Additionally, for a more comprehensive evaluation, a user study with 50 professional participants is conducted. Comparison metrics are provided in Table 4 below. Our method achieves the best performance in both instruction following and identity preservation, significantly outperforming the baselines.
Ablation Study
RoPE Strategy. We first ablate the RoPE strategy design: the default marginal RoPE assigns inputs to the beginning of the temporal index range and outputs to the end, leaving gaps in between; the control strategy, uniform RoPE, distributes all images evenly across the timeline. We conduct ablation studies on a subset of the pretraining dataset (with only a small amount of data) using identical settings. It is observed that uniform RoPE converges later under the same number of training steps. Figure 5 below shows visual results from the RoPE ablation study.

Training Scheme. As previously mentioned, we ablate three supervised fine-tuning strategies: in mixed training, the training loss oscillates violently and is unstable, with the model drifting to simpler tasks even with inverse size reweighting after several updates; we concurrently conduct experiments with phased training (grouping by task type) and cocktail-style mixed training (organizing plans by task difficulty). Cocktail-style mixed training achieves robust results across all tasks and demonstrates significant advantages in difficult settings, substantially outperforming phased training. We conduct comparative experiments with equal training steps on multi-conditional reference tasks, showing that cocktail-style mixed training achieves a 12.6% improvement on OmniContext.
Conclusion
iMontage—a unified many-to-many image generation model capable of creating highly dynamic content while preserving temporal and content consistency. Extensive experiments demonstrate iMontage's superior capabilities in image generation.
iMontage still has limitations: first, constrained by data and computational resources, we have not explored long-context many-to-many settings, with the model currently exhibiting optimal quality at up to four inputs and four outputs; second, some capabilities remain restricted. Detailed categorizations and failure cases are provided later, along with discussions incorporating more concurrent works. Next, we identify expanding long-context supervision, improving data quality, and broadening task coverage as primary directions for future work.
References
[1] iMontage: Unified, Versatile, Highly Dynamic Many-to-many Image Generation
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






