Unified Multimodal Understanding and Generation! Meta&University of Hong Kong and Others Release Tuna: Unifying Visual Representation, Outperforming Show-o2 in Performance
 12/03 2025
12/03 2025
 665
665
Interpretation: The Future of AI Generation 
Highlights
Tuna, a native unified multimodal model adopting unified visual representation, achieves image/video understanding, image/video generation, and image editing within a single framework.
Extensive experiments demonstrate that Tuna's unified visual representation is highly effective, achieving SOTA performance in multiple multimodal understanding and generation tasks.
Comprehensive ablation studies prove that this paper's unified visual representation design outperforms existing methods, such as Show-o2 and other models adopting decoupled representations. 
 Figure 1 shows Tuna, a native unified multimodal model based on unified visual representation, supporting diverse multimodal understanding and generation capabilities, such as image and video understanding, image and video generation, and image editing.
Figure 1 shows Tuna, a native unified multimodal model based on unified visual representation, supporting diverse multimodal understanding and generation capabilities, such as image and video understanding, image and video generation, and image editing.
Summary Overview
Problems Addressed
Insufficient performance of existing Unified Multimodal Models (UMMs): Current UMMs employ a single type of visual encoder (e.g., VQ-VAE, MAR encoder) to handle understanding and generation tasks, often sacrificing the performance of one task at the expense of the other, resulting in inferior performance compared to decoupled models.
Challenges in unifying and balancing visual representation: How to encode visual inputs into a single, unified visual representation that can accommodate both understanding (semantically focused) and generation (detail-focused) task requirements is a core challenge in developing native UMMs.
Proposed Solution
Proposed Model: Tuna, a native unified multimodal model (native UMM) adopting unified visual representation.
Core Design: By directly connecting a VAE encoder (responsible for details/generation) and a Representation Encoder (responsible for semantics/understanding).
Purpose: To obtain a sufficiently expressive unified representation for simultaneous applicability to various multimodal tasks.
Processing Flow: These unified visual features are fused with text tokens and then processed by an LLM decoder, generating new text tokens and denoised images through autoregressive next-token prediction and flow matching.
Applied Technologies
Unified Visual Representation: Tuna's core technology, achieved by directly connecting a VAE encoder (e.g., VAE) with a Representation Encoder (e.g., SigLIP).
LLM Decoder: Used to process fused text and visual features.
Autoregressive Next-Token Prediction: Used to generate new text tokens.
Flow Matching: Used to generate denoised images.
Three-Stage Training: A specific three-stage training process is employed to optimize model performance.
Achieved Effects
Functional Unification: Tuna achieves various tasks such as image and video understanding, image and video generation, and image editing within a single framework.
Performance Improvement: Achieved SOTA in multimodal understanding and generation benchmarks:
Understanding Benchmark: Reached 61.2% on MMStar.
Generation Benchmark: Reached 0.90 on GenEval.
Method: Tuna
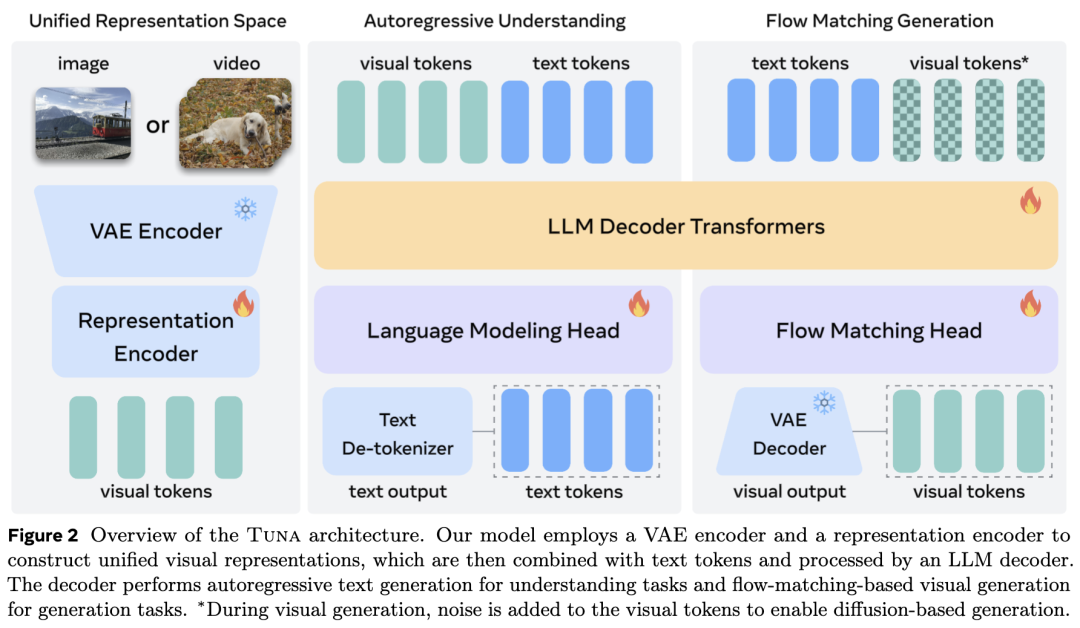
This section introduces Tuna, a native unified multimodal model that adopts unified visual representation across all multimodal understanding and generation tasks. It first outlines the key motivations for model design, followed by a detailed description of Tuna's architecture and training process. An overview of the entire framework is shown in Figure 2 below.
Motivation and Design Principles
Autoregressive vs. Diffusion: Text generation and image/video generation can be achieved through either autoregressive models or diffusion models. In practice, leading pure understanding models typically employ autoregressive models for text generation. On the other hand, state-of-the-art image and video generators use (latent space) diffusion models with flow matching.
Continuous vs. Discrete Visual Representation: Observations reveal that image and video generation models operating in continuous (e.g., KL-regularized) VAE latent spaces outperform those using discrete representations, as discretization leads to information loss and reduced fidelity. Similarly, multimodal understanding models often rely on continuous semantic features (e.g., CLIP features), indicating that continuous visual representations are inherently more effective for understanding and generation tasks.
Semantic Representations Benefit Visual Generation: Recent studies show that semantic features can enhance visual generation. For example, REPA demonstrated that diffusion Transformers benefit from aligning intermediate features with pre-trained representation encoders (e.g., DINOv2). Concurrent with this work, the RAE study used a frozen representation encoder to encode images into latent space representations, showing that pre-trained semantic features alone can effectively reconstruct input images.
VAE Latent Space Variables Can Support Understanding Tasks: This work observes that discrete and continuous VAE latent space variables initially designed for visual reconstruction can also support semantic understanding tasks. Recent methods such as UniTok and TokLIP have enhanced the semantic understanding capabilities of VQ-VAE latent space variables through contrastive learning. Other works have explored diffusion models based on continuous VAE latent space variables for semantic understanding and dense prediction tasks, including semantic segmentation, object recognition, and image retrieval.
Based on these observations, Tuna's design features the following key characteristics:
Tuna integrates an autoregressive model for text generation and a flow matching model for image/video generation.
Tuna builds its unified visual representation upon continuous VAE latent space variables, as these variables effectively support both understanding and generation tasks.
To further enhance performance, Tuna employs a representation encoder to extract higher-level features from VAE latent space variables, thereby improving the quality of understanding and generation.
Model Architecture
Unified Visual Representation As shown in Figure 2 above, Tuna uses a VAE encoder and a Representation Encoder to construct its unified visual representation. Given an input image or video, a 3D causal VAE encoder from Wan 2.2 is applied, performing spatial downsampling and temporal downsampling to produce latent space variables. Then, a noisy latent space variable is generated, where is the sampled time step, .
Next, the SigLIP 2 visual encoder (Patch size of 16, pre-trained resolution of 512) is used to extract semantic features from the VAE latent space variables. Due to the VAE encoder's downsampling, this work replaces SigLIP 2's original Patch embedding layer with a randomly initialized Patch embedding layer, forming a modified encoder . This ensures that the token sequence lengths of and are consistent. Finally, a two-layer MLP connector is applied to obtain the unified visual representation . During training, for visual generation tasks, is randomly sampled between ; for multimodal understanding tasks, is fixed so that always corresponds to clean latent space variables.
For video inputs, where ( is the batch size, is the number of latent frames, and are channels, height, and width, respectively), to prevent the representation encoder from processing overly long sequences, this work does not flatten all latent frames into a single sequence. Instead, it applies a window-based attention mechanism by reshaping the frame dimension into the batch dimension. Using einops notation, the unified visual representation can be expressed as:
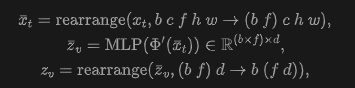
where is the hidden dimension of video tokens. This operation effectively allows to operate independently on each 4-frame window, significantly improving efficiency when processing video tokens.
LLM Decoder and Flow Matching Head
After obtaining the unified visual representation , a time step token representing the sampling time step is added before it. This visual token sequence is concatenated with language tokens, and the combined sequence is input into the LLM decoder (Qwen-2.5) for joint multimodal processing. Following standard UMM practice, as shown in Figure 3, a causal attention mask is applied to language tokens, and a bidirectional attention mask is applied to visual tokens within the LLM decoder layers.
For multimodal understanding tasks, the output of the LLM decoder is passed through a language modeling head to generate text token predictions. For visual generation and image editing, the complete token sequence is input into a randomly initialized flow matching head to predict the flow matching velocity. This head shares the LLM decoder architecture and incorporates time step conditioning through AdaLN-Zero, following the practices of Show-o2 and DiT. For generation and editing tasks, a multimodal 3D-RoPE is employed on the concatenated text-visual sequence to handle interleaved instructions and visual content.
Training Process
To effectively train this unified model, this work adopts a three-stage training strategy, gradually adapting each model component to understanding and generation tasks.
Stage 1: Unified Representation and Flow Matching Head Pre-training
In the first training stage, the goal is to adjust the semantic representation encoder to generate unified visual representations and establish a robust initialization for the flow matching head. To achieve this, the representation encoder and flow matching head are trained while freezing the LLM decoder, using two objectives: image captioning and text-to-image generation.
The image captioning objective aligns with the pre-training objectives of strong semantic encoders (e.g., SigLIP 2 and Qwen2.5-VL visual encoders). Image captioning has been shown to provide semantic richness comparable to contrastive learning, enhancing the visual understanding capabilities of the unified representation. Meanwhile, the text-to-image generation objective trains the flow matching head to generate images from text conditions, laying the foundation for subsequent image editing and text-to-video generation tasks. Additionally, this objective allows gradients to backpropagate to the representation encoder, further aligning the unified visual representation with understanding and generation tasks.
Stage 2: Full Model Continual Pre-training
In the second training stage, the LLM decoder is unfrozen, and the entire model is pre-trained using the same image captioning and text-to-image generation objectives as in Stage 1. During the later training steps of Stage 2, image instruction-following, image editing, and video description datasets are further introduced to expand the model's capabilities. This stage enables Tuna to perform more complex multimodal reasoning and generation tasks, bridging the gap between basic visual-text alignment and more advanced instruction-driven multimodal understanding and generation.
Stage 3: Supervised Fine-Tuning (SFT) Finally, in the third stage, supervised fine-tuning (SFT) is performed using a combination of image editing, image/video instruction-following, and high-quality image/video generation datasets, trained with a reduced learning rate. This stage further refines Tuna's capabilities, improving its performance and generalization across different multimodal understanding and generation tasks.
Experiments
This section provides a comprehensive evaluation of Tuna's performance on various multimodal tasks.
Experimental Setup
Tuna is built upon two LLMs of different scales: Qwen2.5-1.5B-Instruct and Qwen2.5-7B-Instruct. The training process is divided into three stages, involving optimization from the representation encoder and projection layer to the full model. Datasets including image captioning, text-to-image generation, image editing, and video-related datasets are used.
Main Results
Image Understanding This work evaluates Tuna on nine benchmarks, including MME, GQA, and MMMU. As shown in Table 1 below, both the 1.5B and 7B versions of Tuna achieve state-of-the-art (SOTA) results in almost all benchmark tests. Tuna is not only competitive with pure understanding models but also outperforms many composite UMMs and larger-scale UMMs, demonstrating the effectiveness of unified representation.
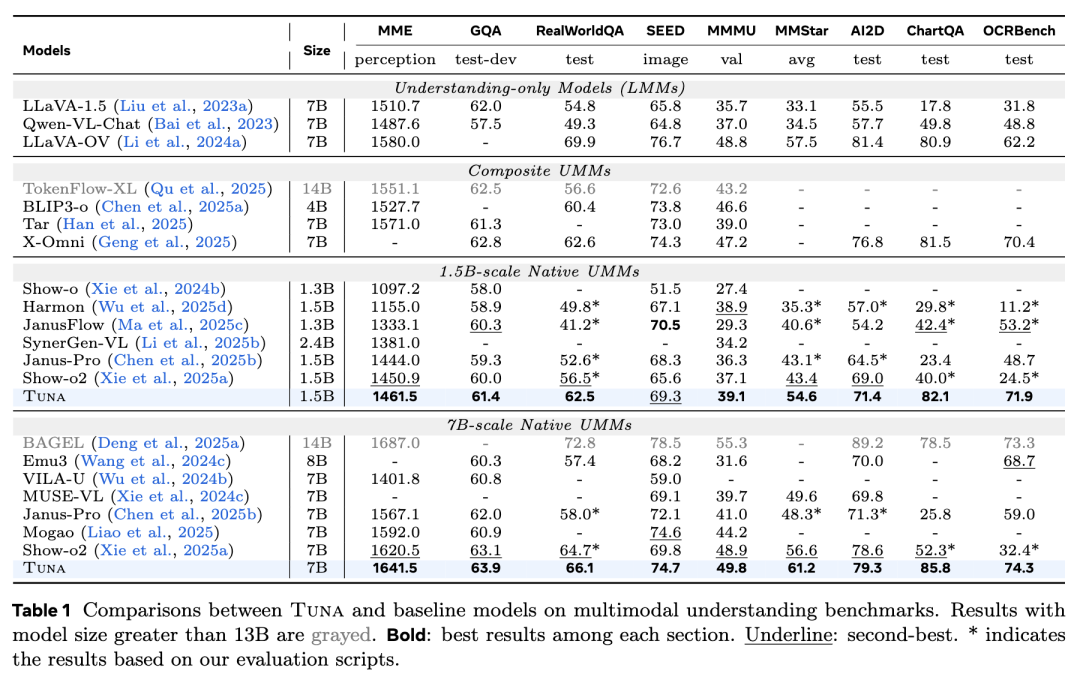
Image Generation Tuna is evaluated on three benchmarks: GenEval, DPG-Bench, and OneIG-Bench. The results are shown in Table 2 and Table 3 below. Tuna consistently outperforms existing methods, including Janus-Pro, BAGEL, and Mogao. Particularly in OneIG-Bench, Tuna demonstrates significant advantages in text rendering quality, indicating its strong semantic understanding capabilities when handling complex instructions containing visual text information.
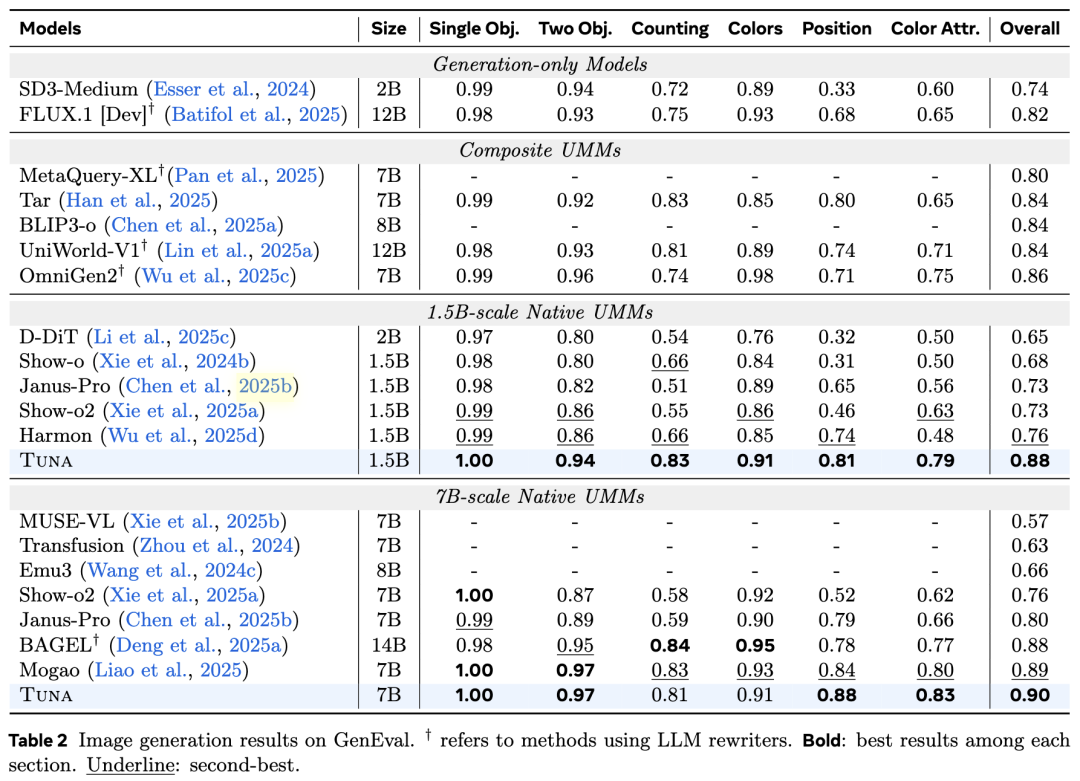
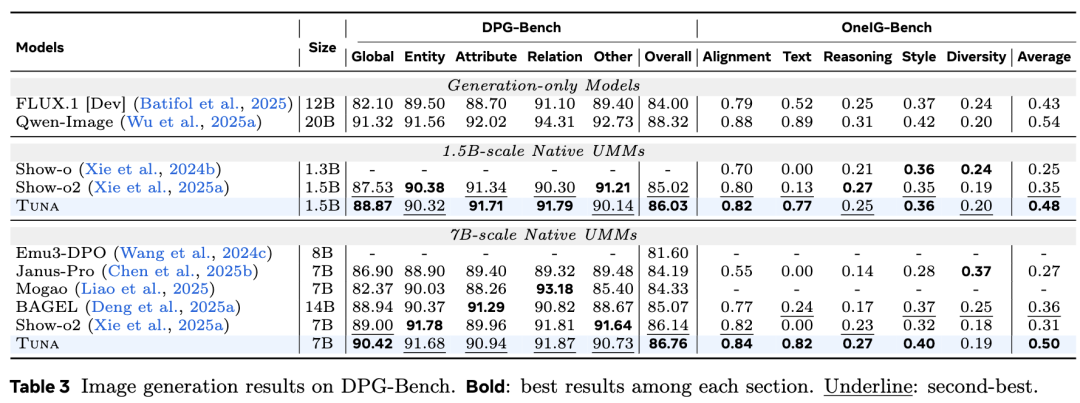
Image editing is evaluated using ImgEdit-Bench and GEdit-Bench. As shown in Table 4 below, Tuna achieves an overall score of 4.31 on ImgEdit-Bench, ranking highest among all UMMs and comparable to pure generative models like FLUX.1. On GEdit-Bench, Tuna scores the highest among all unified models. Figure 7 below displays qualitative results, showing that Tuna can accurately perform operations such as style transfer, environment changes, and object replacement.
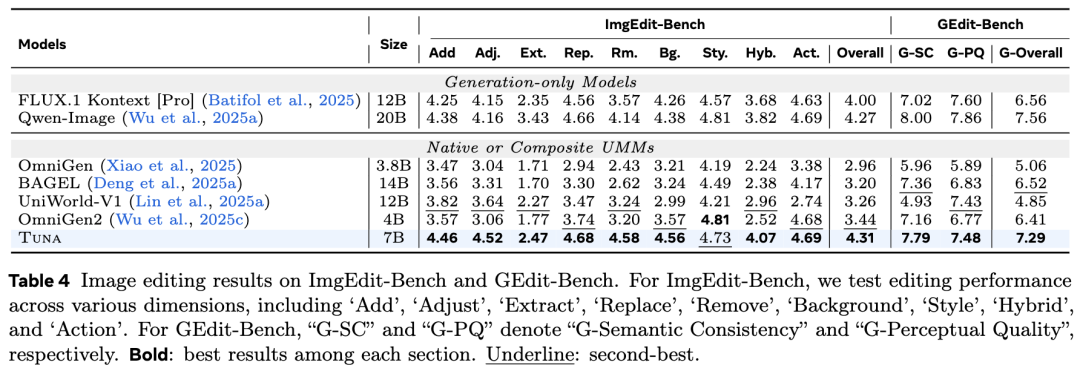

The evaluation results of video understanding on four video benchmarks, including MVBench and Video-MME, are shown in Table 5 below. Tuna outperforms Show-o2 on MVBench and Video-MME and demonstrates competitiveness on other benchmarks. Even with a 1.5B parameter model, its performance is comparable to larger pure understanding models.
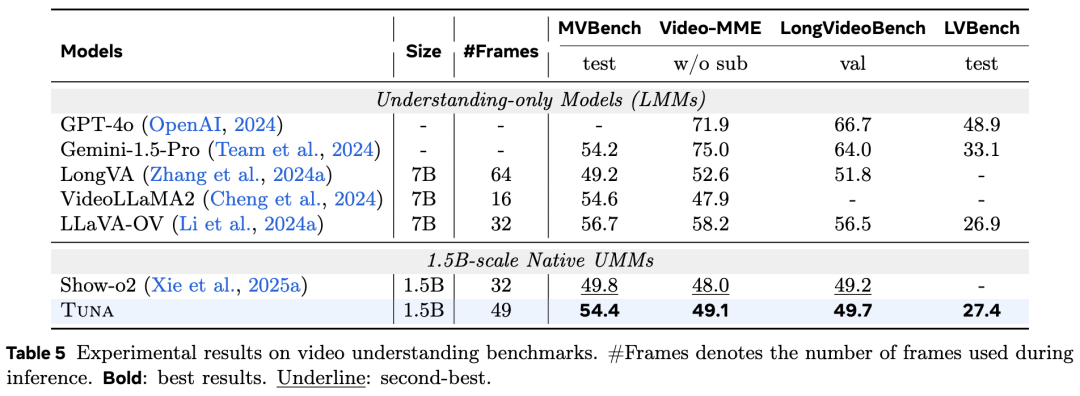
The evaluation results of video generation on VBench are shown in Table 6 below. Tuna achieves SOTA performance, surpassing all existing UMMs with video generation capabilities while using only a 1.5B parameter LLM decoder. Qualitative results, shown in Figure 8 below, demonstrate Tuna's ability to generate high-fidelity videos.

Ablation Experiments: Visual Representation Design
This work validates the effectiveness of the architecture and training strategy through a series of ablation experiments (as shown in Table 7 below):
Unified Representation vs. Decoupled Representation: The results show that Tuna's unified representation outperforms the decoupled setup (i.e., using different encoders for understanding and generation) on both understanding and generation tasks. The decoupled design leads to a significant performance drop in understanding tasks.
Choice of Representation Encoder: A stronger representation encoder (e.g., SigLIP 2 vs. SigLIP) leads to better performance. SigLIP 2 provides superior generation quality compared to DINOv3 while maintaining a smaller model size.
Understanding-Generation Synergy: Joint training enables Tuna to outperform models trained solely on understanding data in understanding tasks and models trained solely on generation data in generation tasks. This demonstrates that the unified visual representation design achieves mutual enhancement between tasks.
Comparison with Show-o2: Tuna's unified representation (directly extracting features from VAE latent space variables) outperforms the late-fusion strategy adopted by Show-o2 on all benchmarks.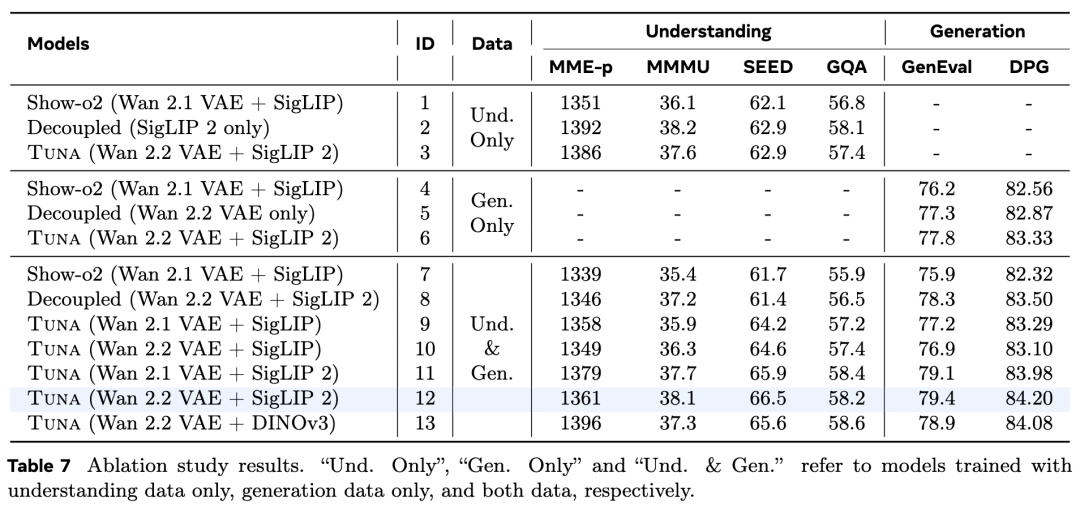
Discussion: Unified Representation Analysis
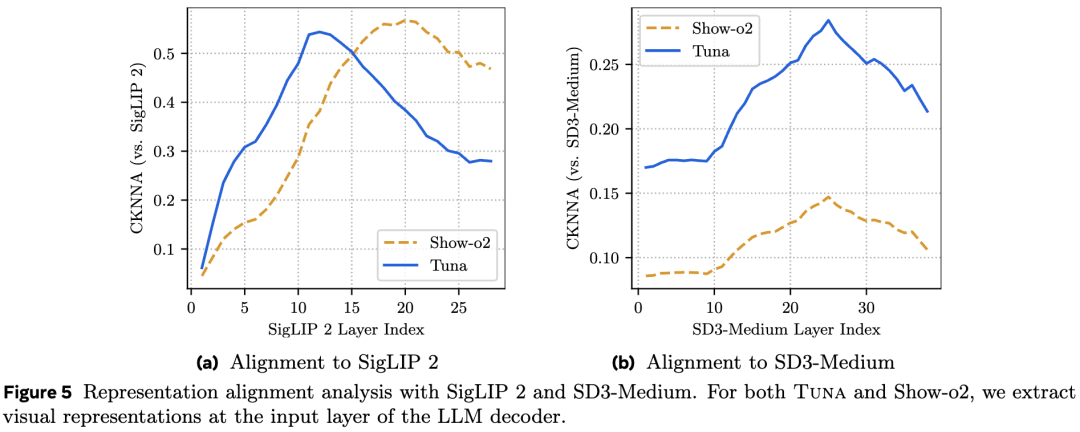
Through CKNNA score analysis (as shown in Figure 5 below), this work finds that Show-o2's features are heavily biased toward semantic understanding and show weak correlation with features from generative models. In contrast, Tuna's unified representation exhibits higher consistency with the intermediate features of SD3-Medium (a strong generative model), indicating that Tuna learns a more balanced unified representation suitable for both understanding and generation.
Qualitative Results
Figure 6 below demonstrates Tuna's advantages in image generation, particularly in compositional generation and text rendering (e.g., correctly spelling words and placing objects as instructed). In contrast, other models frequently make spelling errors or omit objects.

Conclusion
Tuna, a native unified multimodal model, constructs a unified visual representation space through a cascaded VAE encoder and representation encoder. Based on this unified representation, this work trains an LLM decoder and a flow matching head, achieving strong performance in image and video understanding, image and video generation, and image editing.
Tuna not only surpasses previous UMM baseline models but is also competitive compared to leading pure understanding and pure generative models. Ablation studies further demonstrate that: (1) Tuna's unified representation space outperforms Show-o2-style unified representations and decoupled representation designs; (2) within this framework, stronger pre-trained representation encoders consistently lead to better performance; (3) this unified visual representation design achieves mutual enhancement between understanding and generation.
References
[1] Tuna: Taming Unified Visual Representations for Native Unified Multimodal Models
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






