Can VLA and World Models Be Integrated for Autonomous Driving?
 01/13 2026
01/13 2026
 525
525
As Vision-Language-Action (VLA) and World Models garner increasing attention in autonomous driving, these two technologies have become key research and development priorities for many original equipment manufacturers (OEMs). VLA focuses on integrating perception, semantic reasoning, and action generation into a single large model for end-to-end decision-making. Meanwhile, World Models emphasize constructing dynamic simulations and predicting future states of the physical environment within the system to enhance foresight (anticipation, retained as pinyin for contextual accuracy) and response capabilities in complex scenarios. The question arises: Can these two technologies be deeply integrated to enable autonomous driving systems to exhibit smarter and more reliable driving behaviors?
What Are VLA and World Models?
In autonomous driving, VLA represents an end-to-end approach that unifies "perception," "understanding," and "execution" into a single large model. VLA systems capture visual information from the road surface via sensors like cameras and convert it into high-dimensional features. These features are then processed by an extended vision-language model (originally designed for text and image understanding) to perform semantic reasoning within the model. This allows the system to not only identify lane lines, pedestrians, and traffic signs but also analyze complex situations such as pedestrian intentions and traffic rule priorities. The model's output is directly translated into specific control instructions, such as steering, acceleration, or braking.
The defining characteristic of VLA is its integration of multiple modules traditionally found in autonomous driving systems—perception, prediction, planning, and control—into a cohesive "see-think-do" process. It aims to achieve a complete decision-making chain, from image input to action output, through a unified network.
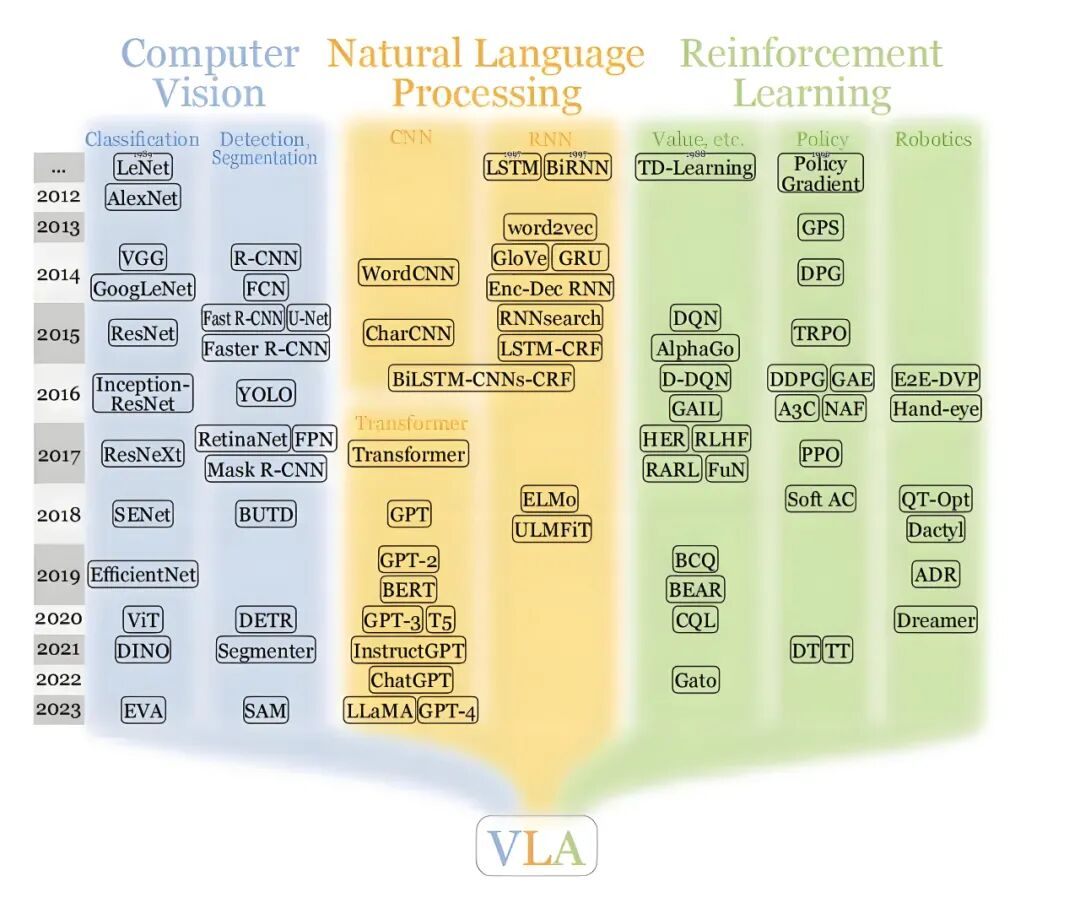
Image Source: Internet
In contrast, the World Model adopts a fundamentally different approach. Rather than simply combining perception and control into a single model, it constructs a "dynamic simulator" of the external physical environment within the system. This enables the autonomous driving system not only to perceive the current environment but also to internally simulate possible future scenarios. By learning the dynamic patterns of the environment, the World Model predicts how other vehicles, pedestrians, and traffic signals will behave, providing deeper support for decision-making. The essence of the World Model lies in establishing an understanding of the world and causal relationships within the model, rather than merely reacting to current visual inputs. It emphasizes future deduction and prediction capabilities.
The Fundamental Differences Between the Two Approaches
If autonomous driving is likened to "human driving," traditional modular solutions divide the driving task into multiple stages: one component observes the road (perception), another analyzes traffic conditions (understanding and prediction), a third makes decisions (planning), and the final component executes operations (control). VLA integrates these stages as much as possible into a single unified model, enabling it to generate action outputs directly from visual inputs and assist decision-making through language or semantic reasoning within the model.
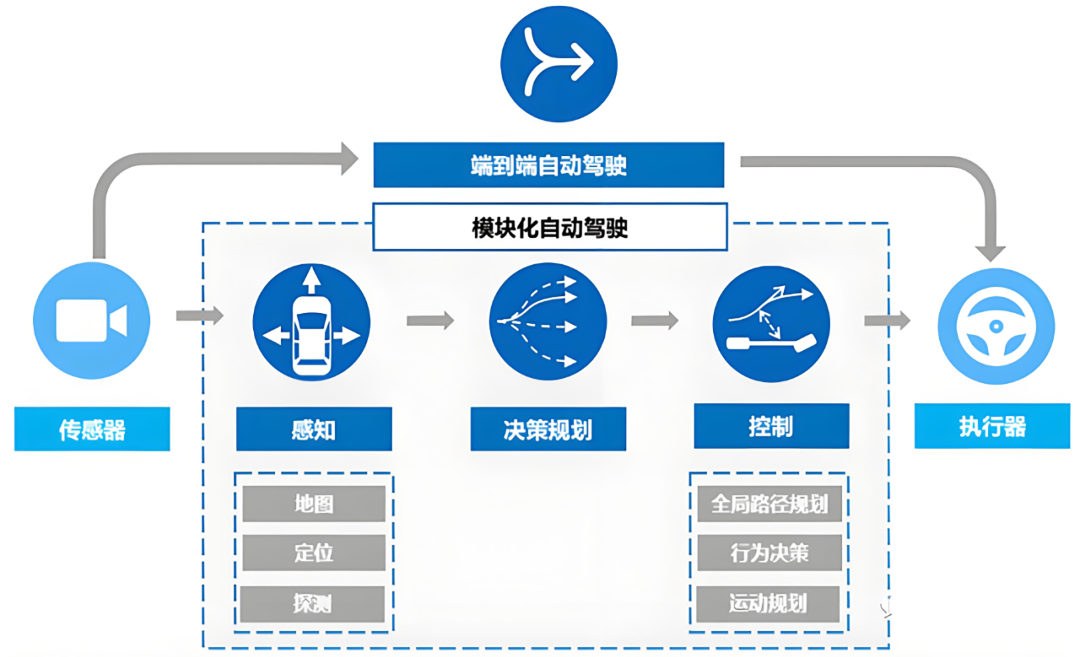
Differences Between Modular and End-to-End Approaches. Image Source: Internet
The World Model approach, on the other hand, involves setting up an invisible "deduction blackboard" within the system to continuously simulate road condition changes over the next few seconds or even longer. These predictions are then fed back to the decision-making module, enabling the autonomous driving system to possess forward-looking capabilities.
From a technical perspective, the core of VLA lies in integrating perception, reasoning, and action generation within a unified model framework. Its advantage is its ability to handle complex semantic understanding tasks while producing more natural and intuitive outputs. In contrast, the core of the World Model is to establish an understanding of environmental states and dynamic patterns within the model, thereby supporting multi-step future predictions based on the current state.
VLA and World Models differ in their focus. VLA emphasizes end-to-end mapping from "perception to action" and high-level semantic reasoning, while the World Model focuses on simulating environmental dynamics and deducing future scenarios. VLA follows a chain-like processing flow of "image → language → action," whereas the World Model prioritizes "internal environmental model construction and prediction deduction." These are not mutually exclusive technological routes but rather complement and reinforce different capability dimensions of the autonomous driving system.
The Possibility of Integration in Practical Applications
VLA and World Models are not isolated technological paths. Technical evidence suggests that the predictive capabilities of World Models can be combined with VLA's "perception-reasoning-action" capabilities to form a complementary relationship, thereby enhancing the overall performance of autonomous driving systems.
A typical integration approach involves training the VLA model not only to generate action outputs but also to predict changes in environmental states. This effectively embeds the capabilities of the World Model into the VLA's training objectives. For example, the DriveVLA-W0 framework proposed by institutions such as the Institute of Automation, Chinese Academy of Sciences, utilizes the World Model to predict future views, providing denser training signals for the VLA model.
Traditional VLA models are primarily trained through supervised learning using collected action data. However, due to the low dimensionality and sparse information of action signals, the supervision signals are limited. By introducing the World Model, the model is also required to predict future images, forcing it to learn environmental dynamic patterns internally. This improves data utilization efficiency and model generalization capabilities while retaining VLA's end-to-end output capabilities.
Additionally, some technical solutions propose promoting unity between the two at the architectural level by designing integrated models that simultaneously encompass vision, language, action, and dynamic prediction. Such architectures enable the system to possess both strong scene understanding and action planning capabilities, as well as future state prediction, through shared internal representations. These integrated models have demonstrated superior performance compared to single methods in some simulation testing or robot control tasks. Although most of these studies are still in the experimental stage, they provide proof of concept for combining VLA and World Models at the principle level.
Why Integration Brings Advantages
One of the core challenges in autonomous driving is the complexity and uncertainty of the environment. Driving conditions are constantly changing, with various vehicles, pedestrians, traffic lights, and road conditions all influencing decision-making. Relying solely on current perception for decision-making makes it difficult to cope with complex changes that may occur in the next few seconds. This is where the internal prediction advantage of the World Model becomes crucial. The World Model enables the system not only to "see the present" but also to "imagine what might happen next," supporting more robust planning.
Furthermore, semantic understanding and high-level reasoning are essential in autonomous driving. Vehicles must interpret traffic signs, judge pedestrian intentions, and adhere to traffic rules—tasks that require higher-level cognitive abilities. VLA excels in this regard by leveraging the reasoning capabilities of large vision-language models to map visual inputs into a semantic space, enabling the autonomous driving system to possess stronger abstract understanding capabilities.
If the World Model is likened to an "internal simulator" capable of predicting the future, and VLA to a "brain" capable of understanding scene semantics and rules, their combination enables the autonomous driving system to both anticipate the future and make appropriate actions based on semantic understanding. This integration allows the system to make more robust and reliable judgments and controls in complex scenarios.
Challenges and Difficulties in Technological Integration
Integrating the World Model into VLA requires significantly more computational resources and data support during the training process. Training the World Model relies on learning environmental dynamic patterns from massive video sequences and driving the formation of internal representations by predicting future frames or states. This necessitates extremely large-scale video data and powerful computational resources. Given that training autonomous driving systems already imposes high resource requirements, their combination further raises the training threshold.
The integrated model structure also becomes more complex. Within VLA, there are originally two major components: perception and reasoning. Now, with the addition of the dynamic prediction component from the World Model, the internal representations must be suitable for both high-level semantic tasks and future predictions. The requirements for internal representations from these two tasks are not entirely consistent, increasing the design difficulty.
Real-time performance and onboard deployment pose additional challenges. While large models and integrated World Model predictions may perform well in laboratory settings, real-time operation in actual vehicles imposes strict latency constraints and computational power limitations. This requires careful consideration of model compression and deployment strategies in environments with limited computational resources during the design phase. Otherwise, even if theoretically feasible, practical implementation will be difficult.
Final Remarks
Although VLA and World Models have different focuses, they can provide complementary capabilities for autonomous driving systems. VLA primarily addresses whether the system can "understand semantics and make reasonable actions" in complex traffic scenarios, while the World Model compensates for the system's ability to deeply understand environmental dynamic patterns and predict and deduce risks before they occur.
By integrating these two capabilities into a single architecture, autonomous driving decisions will no longer rely solely on current perception results but will be based on a comprehensive understanding of scene semantics, dynamic evolution, and future expectations. This transformation signifies that autonomous driving is evolving from a "high-performance perception system" toward a truly intelligent agent with environmental understanding and causal reasoning capabilities. This represents a crucial milestone for achieving high reliability and large-scale deployment.
-- END --
-
![]()
Jitian Xingzhou: A Pioneer in Optical Payloads Secures Hundreds of Millions in Series B Funding!
-
![]()
Orders Secured Through to the Second Half of the Year! The Rationale Behind the 'Surge' in Demand for This Company’s Optical-Grade Base Films
-
![]()
Beyond Patents: The Retail Rivalry of Insta360 and DJI Unfolds
-
![]()
180 Billion Market Cap Vanished! How Did Seres Fall So Far?
-
![]()
Blockbuster! Domestic storage takes the global double crown for the first time, from an AI company
-
![]()
China Spearheads Formulation! World's Pioneering Global Technical Regulation for Automated Driving Systems Greenlit and Unveiled
-
![]()
Farewell to Pulsed Support Policies: Three Major Auto Policy Directions from Multiple Departments Take Effect on the Same Day
-
![]()
Embercore AI’s Accelerated Funding: The Robot Industry’s Shift Toward ‘Learning Systems’