What Is Imitation Learning Frequently Discussed in Autonomous Driving?
 01/14 2026
01/14 2026
 611
611
When delving into model learning for autonomous driving, the term "imitation learning" often surfaces. Imitation learning entails the model observing the actions of others and subsequently learning to replicate those actions. In the context of autonomous driving, imitation learning takes human drivers' behaviors under diverse road conditions as exemplars. It records the visual inputs and corresponding actions, then pairs these observations with the appropriate actions to create training data for developing a model.
Once trained, the model can strive to produce similar human-like actions in comparable scenarios. This learning approach obviates the need for engineers to manually craft rules for every conceivable situation or design intricate reward functions for machines to learn driving through trial and error in virtual settings. With high-quality "human demonstrations," the model can incorporate human "driving styles."
Imitation learning can be implemented through various methods. The most straightforward approach is behavior cloning, which treats the relationship between what experts perceive and execute as a supervised learning task. Its inputs encompass sensor data, front-view images, speed, etc., and the outputs are control variables such as steering wheel angle, throttle, and brake. Another method is inverse reinforcement learning, which doesn't directly learn "what to do" but instead infers a "latent objective function" or preferences from human behavior and then uses this objective to train the model. Additionally, there are more sophisticated variants like adversarial imitation and hierarchical imitation, which can partially mitigate the limitations in generalization and robustness of simple imitation learning.
What Are the Applications of Imitation Learning in Autonomous Driving?
In high-risk domains like autonomous driving, having models learn through "trial and error" in the real world is impractical. Imitation learning leverages existing human driving data to enable models to learn the behavior patterns of "qualified drivers" under safe conditions.
For numerous common scenarios, especially routine operations on urban roads or highways, imitation learning can instruct vehicles on how to smoothly change lanes, maintain a safe distance from the vehicle ahead, and keep a reasonable speed in congested areas. This "human-like driving" behavior enhances the passenger experience and boosts societal acceptance.
Moreover, imitation learning is relatively easy to implement in engineering and offers high training efficiency. As a form of supervised learning, it has clear training objectives, well-defined loss functions, and mature data processing pipelines. Consequently, it is the preferred method in early-stage research and development, as well as for exploring end-to-end perception-control systems.
Imitation learning can also integrate information from multimodal sensors (cameras, millimeter-wave radars, LiDAR, odometers, etc.) into a single network, directly mapping raw perception to control variables. This can significantly streamline the system architecture in certain applications.
Another advantage of imitation learning is its ability to preserve "human driving habits." Human drivers often execute safe and comfortable maneuvers in various situations, such as smooth acceleration and deceleration, reasonable avoidance, and decisions in line with social driving norms. Incorporating these behaviors into the model helps autonomous vehicles coexist more naturally with human drivers in mixed traffic environments, reducing the risk of misjudgment by other vehicles or pedestrians.
How to Train a Model Using Imitation Learning?
To train a model using imitation learning, one must first collect demonstration data, then perform data cleaning and annotation, followed by model training and testing in simulators or on closed roads, and finally conduct online improvements and validation.
The data collection phase isn't merely about amassing more scenarios or indiscriminately piling up various scenarios but rather about sourcing diverse and high-quality data. Scenarios such as day and night, rain and snow, elevated roads and urban congestion, and complex intersections must all be encompassed. During training, convolutional neural networks can be employed to process image inputs, and temporal information can be incorporated through recurrent structures or time windows, enabling the model to remember short-term dynamic changes.
Before deploying the model, its robustness must be verified through simulation and closed-loop testing. Performing well on static test sets doesn't guarantee stable performance in closed-loop driving, as each control action alters the subsequent state distribution, leading to error accumulation.
To address this, online correction mechanisms can be introduced, such as allowing experts to correct the model's actions during driving and adding these new "deviated state-expert action pairs" to the dataset for continued training. Techniques like DAgger (Dataset Aggregation) utilize this approach. Additionally, some technical solutions first use imitation learning to develop a "basic strategy" and then refine and constrain it with reinforcement learning or rule-based planning layers to enhance handling of rare or dangerous scenarios.
Of course, imitation learning doesn't imply a complete abandonment of rules. To ensure the safety of autonomous driving systems, many technical solutions adopt hybrid architectures where imitation learning handles rapid perception-decision mapping, the planning layer handles long-term path planning, and the rule module enforces hard safety constraints (such as absolute stopping conditions and minimum distance restrictions). This layered and hybrid strategy leverages the efficiency of imitation learning while compensating for its limitations in extreme situations through rule-based modules.
Limitations and Real-World Challenges of Imitation Learning
While imitation learning offers benefits, it also faces challenges such as limited generalization ability and error accumulation. Imitation models learn "what to do in seen states" and may struggle with rare scenarios not covered in the training set. In sequential decision-making problems, each model decision alters the future observation distribution, and even slight initial deviations can amplify into significant errors over time, known as distribution shift or error accumulation.
Imitation learning primarily learns from expert demonstrations, which are expected to be high-quality and representative. However, human drivers aren't infallible and may exhibit negligence, habitual errors, or inappropriate judgments in certain scenarios. If the model mechanically imitates these behaviors, it may learn poor driving habits. Especially in human society, moral and legal constraints can't be simply learned through imitation. Additional rules and explainability are needed to handle conflicts and demonstrate justifiable decision-making processes.
End-to-end imitation learning models also suffer from opaque internal decision-making processes, making their safety boundaries difficult to strictly define and verify. In critical areas like automotive safety, regulatory and certification systems require systems to have explainable logic or clear safety guarantees. Therefore, relying solely on data-driven imitation learning may face challenges in verifiability when dealing with complex and varied long-tail scenarios.
To make imitation learning sufficiently robust, it requires a broad coverage of high-quality demonstration data, which brings challenges such as high collection costs, difficult annotation, privacy, and compliance issues. Extreme weather, rare accidents, or complex interaction scenarios are inherently rare, and artificially creating these scenarios is risky. While simulation can supplement some data, the gap between simulation and reality affects model transferability. Therefore, data-related challenges can't be overlooked in imitation learning.
Final Thoughts
Imitation learning provides a crucial foundation for achieving human-like driving behavior in autonomous driving systems. However, its data-driven black-box nature has limitations in safety verification and generalization to long-tail scenarios. To effectively apply imitation learning, it should be placed within a hybrid system architecture that includes rule constraints, planning modules, and multiple safety redundancies. This ensures that while leveraging its efficient learning advantages, the system's overall behavior complies with explainable and verifiable safety norms.
-- END --
-
![]()
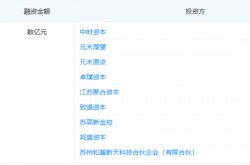
Jitian Xingzhou: A Pioneer in Optical Payloads Secures Hundreds of Millions in Series B Funding!
-
![]()
Orders Secured Through to the Second Half of the Year! The Rationale Behind the 'Surge' in Demand for This Company’s Optical-Grade Base Films
-
![]()
Beyond Patents: The Retail Rivalry of Insta360 and DJI Unfolds
-
![]()
180 Billion Market Cap Vanished! How Did Seres Fall So Far?
-
![]()
Blockbuster! Domestic storage takes the global double crown for the first time, from an AI company
-
![]()
China Spearheads Formulation! World's Pioneering Global Technical Regulation for Automated Driving Systems Greenlit and Unveiled
-
![]()
Farewell to Pulsed Support Policies: Three Major Auto Policy Directions from Multiple Departments Take Effect on the Same Day
-
![]()
Embercore AI’s Accelerated Funding: The Robot Industry’s Shift Toward ‘Learning Systems’