Foreigners Can't Afford GPT, So They're All Coming to 'Freeload' Off Chinese Large Models
 03/02 2026
03/02 2026
 518
518
Farewell to Demographic Dividend: The Endgame of Computing Power is Electricity
Large models are shifting from 'IQ competition' to a 'factory floor' business.
According to a report by Financial China, the latest weekly data from OpenRouter shows that the top ten models on the platform generated approximately 8.7 trillion tokens in total, with Chinese models accounting for 5.3 trillion, or 61%.
The top three models in terms of token usage for the week were all domestic large models: Minimax M2.5, Kimi K2.5, and GLM-5, with usage changes of +197%, -20%, and +158% respectively compared to the previous week.
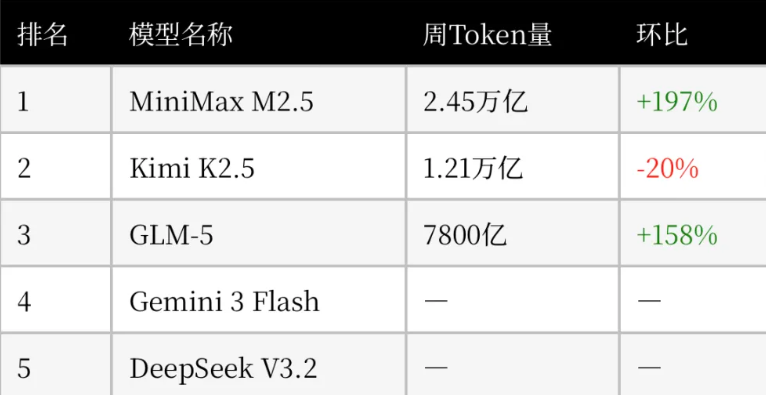
Among them, MiniMax M2.5 topped the list with 2.45 trillion tokens, followed by Kimi K2.5 with 1.21 trillion, while Zhipu GLM 5 and DeepSeek V3.2 ranked third and fifth respectively.
As the world's largest large model API aggregation platform, OpenRouter aggregates real usage demands from global developers, making its rankings the most hardcore 'barometer of computing power consumption' in the current AI industry.
Upon seeing domestic large models dominate the charts so aggressively, many people's first reaction is: Have domestic models caught up to GPT, Claude, and Gemini in terms of absolute capabilities?
The answer is clearly no. If we're talking about extremely complex logical reasoning or hardcore coding tasks, Silicon Valley's closed-source giants still represent the absolute technical ceiling.
So, if absolute intelligence hasn't caught up to North America's top models, why are domestic models dominating global usage? And what does this mean for the future of AI competition?
01
Large Models: Not Alchemy, But Assembly Lines
Domestic large model companies are using Yiwu's logic for small commodities to dimensionally reduce and outmaneuver Silicon Valley's cyber magic. The reason Chinese large models can dominate OpenRouter is simple: they're cheap.
Previously, pricing power for large models was in the hands of overseas giants. Take GPT-4o or Claude 3.5 Opus—powerful but expensive. Processing one million tokens typically cost several dollars or even over ten dollars.
During AI's initial hype phase, everyone gritted their teeth and accepted these prices. But once we entered the Agent era, everything changed.
The recent 'OpenClaw ban' that caused a stir in tech circles is the most vivid example of this computing cost crisis.
As a wildly popular open-source AI agent, OpenClaw can take over computers like a 'digital worker,' automatically processing files and even writing code. To save money, many geeks and developers came up with a 'brilliant' scheme: using code interfaces, they had OpenClaw 'freeload' off Google and Anthropic's $20/month personal subscription plans (like Claude Pro) instead of using the official expensive pay-per-use APIs.
The result was predictable. When AI transformed from a 'you ask, I answer' chatbox into an 'auto-planning, repeatedly executing digital worker,' every backend search, trial-and-error, correction, and loop burned tokens Crazy Burning (madly consumed tokens). This Agent-level Horror throughput (terrifying throughput) directly overwhelmed the supposedly 'unlimited' monthly plans.
Facing their depleted computing resources, Google and Anthropic took action. They urgently banned third-party tools from accessing subscription channels, with Google even permanently banning some high-frequency accounts.
The core logic behind these giants' drastic moves? They couldn't bear the computing costs anymore.
In the Agent era, if they kept letting everyone run automation tasks on $20/month plans, CSP giants would go bankrupt. But if they forced developers to use official APIs priced at over $10 per million tokens, the most advanced (and expensive) large models would stop being cutting-edge productivity tools and instead become profit-eating black holes, cornering countless AI applications and developers' business models.
Just as most industries faced a 'can't afford computing power' deadlock, they looked across the ocean and found Chinese large model companies had slashed prices to shockingly low levels.
Currently, excellent domestic models like DeepSeek, GLM, Kimi, or MiniMax have driven API call prices down to just $2-3 per million tokens.
Some vendors even offer long-term free access to models with million-level context or specific scales to Seize the developer ecosystem (seize developer ecosystems). This isn't just a '20% off' sale—it's a cost discontinuity by orders of magnitude.
Many might ask: Cheap is good, but what's the point if the model isn't smart? The reality is, most people overestimate the need for 'extreme intelligence' in real scenarios while underestimating the terrifying consumption of computing power from 'long-tail tasks.'
In the real business world and geek development circles, 90% of AI tasks don't require 'Einstein-level' intelligence.
Imagine daily AI use cases: translating a 100,000-word English web novel into Chinese; feeding AI dozens of PDF financial reports to extract all profit data; writing a few hundred lines of frontend code; or the current massive token consumer on OpenRouter—'roleplay' where players engage in thousands of rounds of chitchat with AI-controlled virtual characters.
These tasks share one trait: moderate logical depth but massive text throughput. For such 'blue-collar' cognitive work, top Chinese models don't just 'pass'—they excel.
It's like needing to input tens of thousands of shipping labels into a spreadsheet for your company. There's no need to hire a Nobel laureate (top closed-source model) at great expense when you can perfectly solve the problem with a group of diligent, down-to-earth, and extremely low-paid interns (cost-effective models).
Moreover, with distillation techniques, the gap between top closed-source and cost-effective models is at most half a step.
Thus, global developers rationally adopt a 'smart routing' strategy: route massive, tedious, error-tolerant basic tasks and long-text reading to cheap Chinese models; only when final complex logical judgments are needed or extremely difficult algorithm problems arise do they meticulously call GPT or Claude.
This is why domestic models dominate global usage.
02
The Computing Power Arms Race: Transformers Are the Trump Card
Cheap large models didn't fall from the sky.
Many assume domestic models' rock-bottom prices come from vendors 'burning money on subsidies.' But this underestimates Chinese engineers' terrifying ability to squeeze technology into practicality.
While Silicon Valley still believes in 'brute force miracles'—stacking trillion-parameter models—domestic companies have mastered the art of 'stinginess.'
In this arena, Chinese vendors demonstrate frighteningly strong manufacturing genes and engineering optimization capabilities.
Due to export bans, domestic large model companies can't easily buy tens of thousands of top-tier GPUs like Silicon Valley giants. Forced by 'computing poverty,' domestic engineers had no choice but to perform extreme micro-optimizations in engineering.
To reduce computing power consumption per inference, they pushed Mixture of Experts (MoE) to the extreme.
A massive model with hundreds of billions of parameters, when answering a simple daily question, would precisely activate only a 'expert network' of several billion parameters while keeping most networks dormant. It's like a giant factory no longer lighting up all workshops to produce one screw but precisely controlling production lines to drastically save computing and electrical power.
To handle million-level ultra-long contexts without running out of memory, Chinese engineers relentlessly optimized KV Cache at the framework level, compressing and packing massive data into limited memory with pixel-level precision. On relatively inferior hardware, they achieved ultra-long text processing capabilities rivaling or exceeding world leaders.
This near-pathological squeezing of underlying computing power, combined with China's extremely mature hardware adaptation engineering, slashed the physical costs of large model inference by orders of magnitude.
In contrast, North American giants across the ocean can't even engage in a price war if they wanted to—they're locked down by heavy physical infrastructure.
On this issue, Elon Musk predicted back in 2023: 'My prediction is we will go from... extreme silicon shortage today to... extreme electricity shortage within two years. That's roughly the trend of things.'
And reality bears this out. North America's aging power grids and lengthy environmental review approvals can't support the soaring electricity demands of new hyperscale data centers. Expensive industrial electricity, extremely high operational costs, and even unavailable high-voltage transformers—all become sunk costs averaged into every API call.
In other words, the 'expensiveness' of North America's top large models mostly pays for outdated infrastructure and high local costs.
Thus, when high physical costs meet infinite global demand for computing power, a new positioning for Chinese AI emerged.
Over the past 40 years, we've leveraged demographic dividends and a complete supply chain to become the 'world's factory' exporting physical goods globally. Today, as large models enter deep application territory, having bid farewell to demographic dividends, China is transforming into a 'world token factory' relying on world-class UHV power grids, extremely stable low-cost industrial electricity, and unparalleled engineering implementation capabilities.
Henceforth, the future global AI division of labor is clear: massive document close-reading, basic code generation, high-concurrency long-text translation, and virtual human chitchat will all flow as 'cyber OEM orders' through undersea cables to domestic large model clusters.
Once electrical energy is converted into tokens within AI chips, it sheds physical form. Unlike physical products requiring lengthy port loading and ocean freighter transport, tokens travel at light speed through undersea cables, reaching every corner of the world in milliseconds.
Thus, it's more accurate to say China is quietly taking over the lifeblood of AI applications through absolute cost and infrastructure advantages, rather than the world's geeks 'freeloading' off domestic models.
While Silicon Valley giants burn money No matter the cost (without regard for cost) to chase AGI's ultimate crown, mired in physical infrastructure quagmires, domestic large model companies have become new-era 'infrastructure maniacs,' using this endless stream of cheap tokens crossing mountains and seas to steadily build the most indispensable 'utilities' business of the global intelligence revolution.
- END -
-
![]()
Smartphone Prices Surge Amid Manufacturer Anxiety
-
![]()
Orbbec Soars to Record Heights, Eyes Further Capital Influx of 980 Million!
-
![]()
Tongding Interconnect Sets Up Shop in Shaoguan with 800 Million Yuan in Registered Capital
-
![]()
Before Kimi’s A-Share Debut, Zhipu Aims to Secure More 'Strategic Funding'
-
![]()
Innovative Leap | Fiber-Pluggable 1470nm Laser Source: Revolutionizing Precision Laser Weeding
-
![]()
73-Day Rapid Listing: Where Does Unitree's Wang Xingxing's 'Sense of Urgency' Come From?
-
![]()
AI Project Mindverse, Backed by Meituan, Faces Data Inflation Allegations Over Its Macaron Product
-
![]()
3000-word In-Depth Analysis | What Makes Physical AI So Magnetic? It Has Captivated Masayoshi Son, Jensen Huang, and Justin Sun All at Once







