Mind-Blowing! Single Card Generates Minute-Long Videos in Real-Time: Peking University & ByteDance Jointly Launch 14B Large Model Helios, Outpacing 1.3B Models in Speed
 03/17 2026
03/17 2026
 496
496
Decoding the Future of AI-Generated Content

Key Highlights
Robustness Against Drift in Long Videos: Helios can generate minute-level videos with strong temporal coherence without relying on common drift-prevention heuristics such as self-forcing, error banks, or keyframe sampling. This is achieved through a novel training strategy that explicitly simulates drift and eliminates repetitive motions.
Real-Time Generation: The model achieves real-time speed without using standard acceleration techniques like KV caching, sparse/linear attention, or quantization. This is primarily attributed to deep compression of historical and noise contexts, reduced sampling steps, and infrastructure-level optimizations.
Efficient Training: Helios can be trained without parallel or sharded frameworks, allowing batch sizes comparable to image diffusion models while fitting up to four 14B models into 80 GB of GPU memory. Helios introduces a unified input representation that natively supports text-to-video (T2V), image-to-video (I2V), and video-to-video (V2V) tasks. To address the lack of standardized evaluation in real-time long video generation, HeliosBench, a comprehensive open-source benchmark, has been released.




Summary at a Glance
Problems Addressed
In the field of video generation, mainstream models typically generate only 5-10 second short videos with long generation times, making real-time performance difficult to achieve and even harder to scale to longer video durations without content drift. While some methods claim to enable real-time infinite video generation, they often rely on 1.3B models with limited capacity, restricting their ability to represent complex motions and retain high-frequency details. Additionally, existing methods frequently depend on drift-resistant heuristics like self-forcing during training and inference, significantly increasing training costs. The robustness against drift is closely tied to the clip length used during training, leading to severe drift issues outside the training scope.
Proposed Solution
Helios proposes a 14B model solution aimed at achieving real-time long video generation while addressing drift and efficiency issues. The specific approaches include:
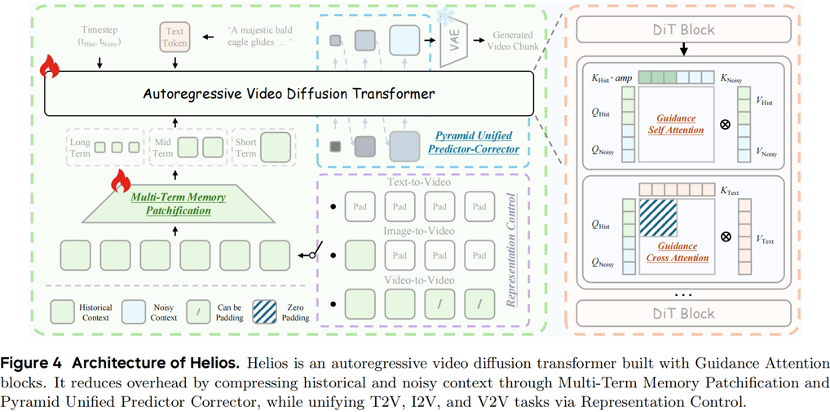
Unified History Injection: Treating long video generation as an infinite video continuation problem, historical context is efficiently injected into the noise context through representation control and guidance attention, transforming a bidirectional pre-trained model into an autoregressive generator.
Easy Anti-Drifting: By analyzing typical drift patterns (positional drift, color drift, and recovery drift), a simple yet effective training strategy is proposed to explicitly simulate drift during training and eliminate the root causes of repetitive motions (e.g., through Relative Rotational Positional Encoding (Relative RoPE)).
Deep Compression Flow: Historical and noise contexts are significantly compressed through Multi-Term Memory Patchification and Pyramid Unified Predictor Corrector, reducing sampling steps and substantially lowering computational costs and memory consumption.
Infrastructure-Level Optimization: Optimization measures are introduced to further accelerate inference and training while reducing memory consumption, enabling the training of 14B models without parallel or sharded frameworks.
Technologies Applied
Helios integrates multiple advanced technologies, including:
Autoregressive Diffusion Model: As the core architecture, Helios is a 14B autoregressive diffusion model.
Unified Input Representation: Through unified input representation, the model natively supports text-to-video (T2V), image-to-video (I2V), and video-to-video (V2V) tasks.
Relative Rotational Positional Encoding (Relative RoPE): Used to address positional drift and repetitive motions.
First-Frame Anchor: The first frame is retained as a global visual anchor during training and inference to mitigate color drift.
Frame-Aware Corrupt: Enhances model robustness against imperfect histories by simulating historical drift.
Multi-Term Memory Patchification: Compresses historical context through hierarchical context windows.
Pyramid Unified Predictor Corrector: A multi-scale sampler used to reduce redundancy and computational load in noise contexts.
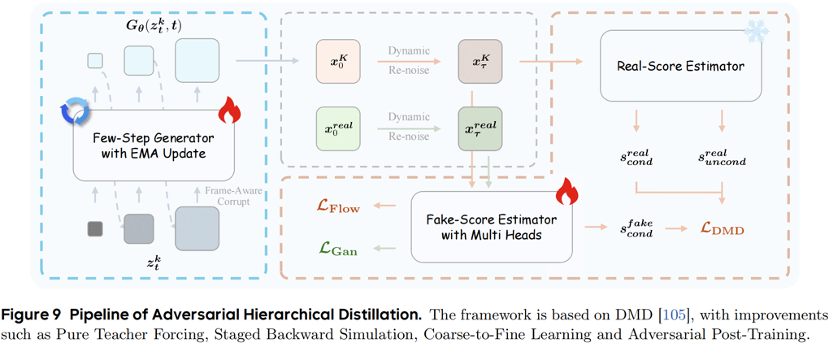
Adversarial Hierarchical Distillation: A pure teacher-forcing method that reduces sampling steps from 50 to 3.
Infrastructure-Level Optimization: Includes Triton-optimized kernels like Flash Normalization and Flash RoPE.
Achieved Results
Helios achieves significant breakthroughs in performance:
Real-Time Performance: On a single NVIDIA H100 GPU, Helios achieves real-time video generation at 19.5 FPS, even outpacing some 1.3B models.
Minute-Level Video Generation: Capable of generating minute-long videos while maintaining high quality and strong temporal coherence, effectively overcoming traditional drift issues.
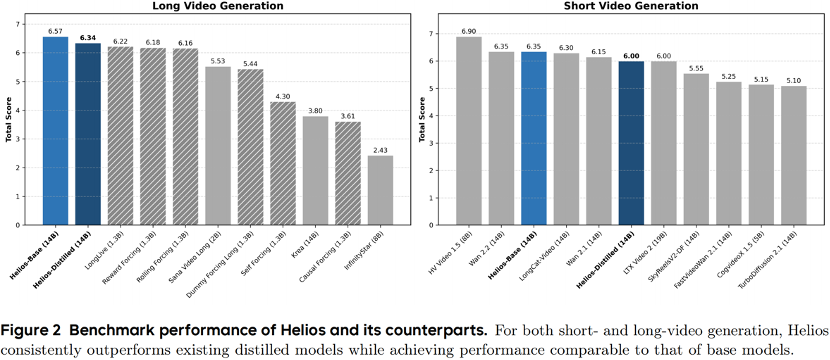
High-Quality Output: Helios consistently outperforms existing methods in both short and long video generation, excelling in visual quality, text alignment, and motion dynamics.
Training Efficiency: Achieves training of 14B models without parallel or sharded frameworks, with batch sizes comparable to image models.
Open Benchmark: Releases HeliosBench, a test set containing 240 prompts covering four duration ranges from ultra-short to long videos, to drive further community development and standardized evaluation.
Helios
Over the past year, Diffusion Transformers have significantly advanced video generation, even demonstrating potential as "world models." However, as demands for video quality rise, a critical pain point remains for all developers and creators: it's too slow! Mainstream large video models struggle to achieve real-time generation and are often limited to 5-10 second durations. Even generating these short clips can require tens of minutes of rendering time! This is a nightmare for game engines or interactive generation applications.
But today, this stalemate has been completely broken!
Research teams from Peking University, ByteDance, Canva, and Chengdu Anu Intelligence have jointly launched a groundbreaking large model—Helios. This is the industry's first 14B video generation large model capable of running in real-time at an astonishing 19.5 FPS on a single NVIDIA H100 GPU!
It not only supports minute-level ultra-long video generation but also matches the visual quality of powerful foundational large models.
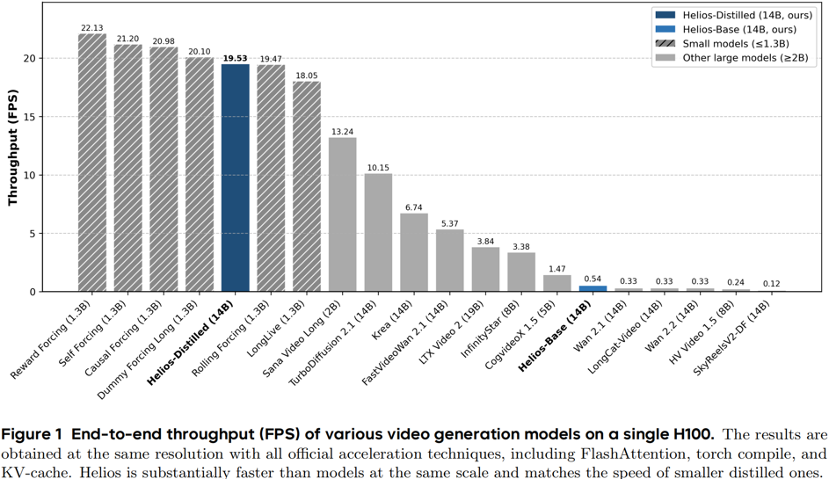
Breaking the Mold: Three-Dimensional "Unconventional" Disruption
Why is Helios considered revolutionary? Because most current methods claiming "real-time infinite generation" rely on small 1.3B models (e.g., based on Wan2.1 1.3B). The limited capacity of small models restricts their ability to express complex motions, often resulting in blurred high-frequency details.
Helios, with its massive 14B parameter count, achieves breakthroughs in three critical dimensions:
1. Ultimate Speed Acceleration: Fast Without Conventional Boosts To achieve real-time generation, existing models typically use standard acceleration techniques like KV-cache, sparse/linear attention mechanisms, or quantization. However, Helios completely abandons these conventional approaches.
The team proposes "Deep Compression Flow," which drastically reduces redundancy in historical contexts through "Multi-Term Memory Patchification" and redundancy in noise contexts through "Pyramid Unified Predictor Corrector." This sharply reduces the number of tokens input to DiT, lowering computational costs to levels comparable to or even lower than 1.3B models.
Even more aggressive, they introduce "Adversarial Hierarchical Distillation," using only an autoregressive model as the teacher to reduce sampling steps from the traditional 50 to just 3.
2. Long-Duration Fidelity: Say Goodbye to Long Video "Collapse" What's the biggest fear in generating long videos? "Drifting"! As videos lengthen, Screen position (positional drift) begins to wander, colors mutate, and quality degrades into a blur. Previously, drift prevention required extremely time-consuming self-forcing or error-bank strategies.
Helios offers a more elegant "Easy Anti-Drifting" solution:
Eliminating Repetitive Motions: Using "Relative Rotational Positional Encoding (Relative RoPE)" resolves conflicts between RoPE periodicity and multi-head attention, eliminating repetitive motions at their source.
Stabilizing Global Colors: The "First-Frame Anchor" mechanism retains the first frame as a global visual anchor during training and inference, effectively mitigating color mutations.
Simulating Real Errors: "Frame-Aware Corrupt" actively adjusts exposure, adds noise, or blurs historical frames during training, allowing the model to adapt to imperfect histories in advance and significantly improving fault tolerance.

3. Ultimate Memory Optimization: Fitting 4 x 14B Models on a Single 80G GPU! Training a 14B video model typically requires massive parallel computing clusters and complex sharding frameworks. However, the Helios team has performed extreme optimizations at the infrastructure level.
Astonishingly, they achieved fitting up to four 14B models into a single 80GB GPU without using any parallel or sharded frameworks! This allows the model to train with batch sizes comparable to image diffusion models, significantly lowering computational barriers.
Hexagonal Warrior: Excelling in Both Short and Long Video Generation, the All-Powerful Helios for T2V/I2V/V2V Tasks. Helios is a versatile model that natively supports multiple tasks. Through unified input representation control, if all historical context is zero, the model performs text-to-video generation (T2V); if only the last frame is non-zero, it performs image-to-video generation (I2V); otherwise, it performs video-to-video generation (V2V).
To validate Helios's capabilities, the research team specifically constructed the evaluation benchmark HeliosBench for real-time long video generation, which includes 240 prompts covering different length dimensions.
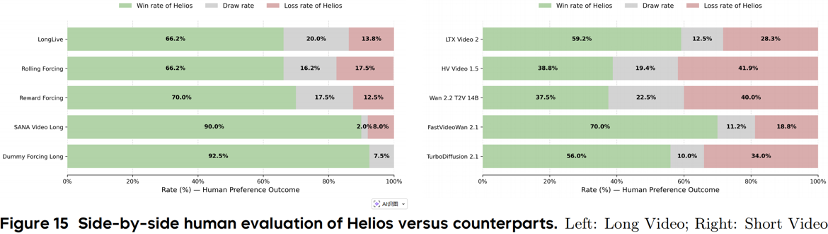
The experimental results were no surprise: Helios consistently outperformed previous advanced methods in both short and long video generation. It not only operates at lightning speed but also excels in visual quality, text alignment, and motion dynamics.
Fully Open-Source! A Celebration for the Community.
In an era dominated by closed-source large models, the open-source spirit of the Helios team is truly inspiring. The team supports multiple inference backends, including NPU, Diffusers, vLLM, and SGLang, from Day 0, and has fully open-sourced the training/inference code and model weights.
Conclusion: Reshaping the Video Generation Landscape and Ushering in a New Era of 'Real-Time World Models'.
The emergence of Helios breaks the long-standing curse of computational power versus quality. With its hardcore achievements, it proves to the world that a video large model with a hundred billion parameters (14B) can achieve faster real-time inference (19.5 FPS) on a single H100 card than a smaller 1.3B model through ultimate (extreme) algorithm and system collaborative optimization (collaborative optimization), and easily handle minute-level ultra-long generation! It perfectly accomplishes the three core tasks of text-to-video (T2V), image-to-video (I2V), and video-to-video (V2V) generation within a unified framework, drastically lowering the barrier for high-quality long video generation from 'requiring extremely expensive computational clusters' to 'runnable on a single card.' This is not just a showcase of underlying technology but also a ticket to the future. Imagine real-time interactive video generation, next-generation dynamic game engines, and even true 'real-time world models (World Models)' becoming within reach thanks to Helios's breakthrough.
References
[1] Helios: Real Real-Time Long Video Generation Model
-
![]()
Zhao Ming Departs, IPO Postponed, AI Phones Underperform—Can Honor Still Live Up to Its Name?
-
![]()
Explosion of Recording Hardware! Four Major Product Categories Compete for New AI Entry Points, with Agent Capabilities Becoming Standard
-
![]()
China’s LEO Satellite Internet Achieves Strategic Progress: Over 100 Additional Satellites Set for Launch
-
![]()
Musk Sustains $88 Billion Loss in AI Pursuit, Now Rents GPUs to Rivals, Anticipating $500 Billion Revenue Over Three Years
-
![]()
Report | Token Economics: Envisioning a New Path for RMB Internationalization
-
![]()
Trends丨Gartner's Latest Forecast: These Seven Transformations Will Reshape the Technology Landscape Over the Next Five Years
-
Betting on Embodied AI: Bosch's New Game Plan in China
-
![]()
WeChat Collaborates with Huawei/Honor/Xiaomi on A2A: Is This the Dawn of AI Integration?






