Tearing Down NVIDIA's Compute Fortress
 03/23 2026
03/23 2026
 586
586

"The AI industry is using the 'wrong tool'."
As Cerebras founder Andrew Feldman made this bold claim, NVIDIA was dominating a trillion-dollar market with its GPUs.
Was Andrew Feldman bluffing? Cerebras is attempting to answer this question with a dinner-plate-sized, 900,000-core wafer-scale engine (WSE-3), offering a solution where "one chip equals one cluster."
Cerebras believes that the core bottleneck in deep learning has never been raw compute power but rather the memory wall encountered when data crosses chip boundaries.
In March 2026, Oracle mentioned during its earnings analyst call that it was deploying Cerebras chips, listing it alongside NVIDIA and AMD as a core accelerator supplier. This "casual mention" was seen by the industry as a significant signal of Cerebras entering the procurement vision (procurement vision means "procurement radar") of hyperscale enterprises.
01
How Cerebras is Challenging NVIDIA—and Succeeding
Founded in 2016 by Andrew Feldman (former co-founder of SeaMicro, later acquired by AMD), Cerebras has introduced the WSE-3, the largest AI chip to date, spanning 46,255 square millimeters and integrating 4 trillion transistors. With 900,000 AI-optimized cores, it delivers 125 PFLOPS of AI compute, boasting 19 times more transistors and 28 times greater compute power than NVIDIA's B200.
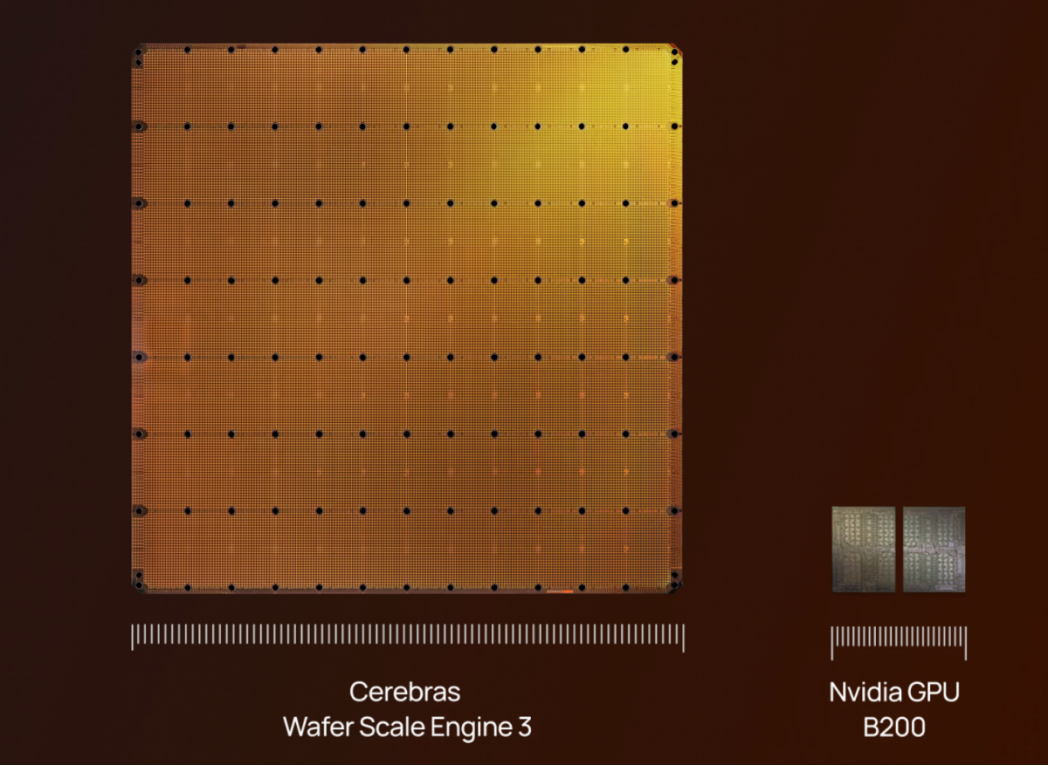
The WSE-3 features 44GB of on-chip SRAM and 21PB/s of memory bandwidth, completely shattering traditional memory bottlenecks. Its wafer-scale interconnect architecture provides 27PB/s of internal bandwidth, 206 times faster than the latest NVLink.
Up to 2,048 systems can be combined, delivering 256 EFLOPS of AI compute. AI developers can train models with up to 24 trillion parameters without dealing with the complexities of multi-GPU scheduling and parallel strategies.
Traditional GPUs (like the B200) must continuously fetch data from off-chip HBM memory, limited by HBM bandwidth—a key reason for the rapid rise of HBM storage alongside AI's large model boom. This approach passively mitigates performance bottlenecks caused by separating compute and storage by strengthening off-chip transmission capabilities.
Cerebras places 44GB of high-speed memory directly beside its 900,000 AI cores, eliminating the need for off-chip data transfers and physically erasing transmission delays.
In January 2026, Cerebras signed a multi-year partnership with OpenAI, committing to provide 750 megawatts of inference compute, with deployment scaled in phases from 2026 to 2028 under a contract exceeding $10 billion. Officially dubbed the "world's largest high-speed AI inference deployment," OpenAI highlighted reducing inference latency for ChatGPT's real-time responses as a core goal.
On March 13, 2026, AWS announced a multi-year collaboration with Cerebras, deploying Cerebras CS-3 systems in AWS data centers to provide inference services via Amazon Bedrock. This marked the first time a mainstream hyperscale cloud platform deployed non-GPU AI accelerators within its own data centers.
David Brown, VP of Compute Services at AWS, stated, "This disaggregated architecture lets each system excel at what it does best, resulting in inference performance an order of magnitude faster than any current solution."
Industry analyst firm Futurum noted in its assessment that this partnership "marks a new era—inference architectures are becoming independent, with specialized chips replacing monolithic GPU deployments for latency-sensitive tasks."
02
Trading Area for Performance: Is It Unbeatable?
Artificial Analysis's benchmarks show the Cerebras CS-3 achieving 2,522 tokens/second on Meta's Llama 4 Maverick (400B parameters), outpacing NVIDIA's Blackwell B200 at 1,038 tokens/second—a 2.4x lead. The gap widens further with smaller models like Llama 3.1 8B: Cerebras reaches ~1,800 t/s versus NVIDIA H100's ~90 t/s, a 20x difference.
For token-based cloud pricing, DeepSeek V3 costs $0.20/million tokens for input and $0.50/million tokens for output on Cerebras, offering highly competitive pricing. By September 2025, Cerebras had expanded to five new data centers in North America and Europe, launching simultaneously on AWS Marketplace to enter enterprise procurement channels.
The AI industry is shifting from "training-centric" to "inference-centric," where latency is critical. Scenarios like conversational AI (ChatGPT), multi-step agents (Agentic AI), and real-time code generation demand strict tokens/second requirements. The AI inference market is projected to grow from $106.2 billion in 2025 to $255 billion by 2030 (CAGR ~19%).
While these benchmarks highlight Cerebras's speed and cost advantages in inference, declaring a "complete dominance" would be premature.
NVIDIA's most potent weapon isn't hardware but its mature CUDA ecosystem. Developers switching to Cerebras must adapt to proprietary compilers, and current support for advanced AI features like dynamic control flow remains incomplete. This migration cost is a core barrier for enterprises. With millions of AI engineers globally trained on CUDA, transitioning to Cerebras entails learning curves. Analysts note that AWS Bedrock's integration strategy aims to minimize this gap by reducing developers' direct exposure to hardware differences—if Cerebras can be used without code changes, the ecosystem gap's impact diminishes significantly.
The CS-3 consumes 50kW per system, far exceeding single GPU servers. Traditional data centers with space and power constraints face physical infrastructure limitations when deploying such equipment.
Meanwhile, NVIDIA isn't standing still. Beyond rapid Blackwell iterations, it acquired core assets from inference startup Groq and launched NIM inference microservices to solidify its inference market position.
Groq's chips, dubbed LPUs (Language Processing Units), target LLM inference scenarios, prioritizing "fast, predictable, low-cost" large model inference over general-purpose training and graphics rendering. In many LLM inference scenarios, computational costs and energy consumption per token are significantly lower than traditional GPU clusters (due to high on-chip bandwidth, reduced external memory access, and inference-optimized instruction flows).
Built on the Tensor Streaming Processor (TSP) architecture, the hardware minimizes unpredictability by removing caches, multi-level out-of-order execution, and other mechanisms, enabling compilers to statically schedule instructions and data paths for "assembly-line-style" predictable execution.
The first-gen LPU features ~230MB of on-chip SRAM and 80TB/s of internal bandwidth, dwarfing typical GPU HBM external bandwidth (~8TB/s). This reduces external memory accesses, lowering latency and boosting energy efficiency.
For many enterprises, training costs are one-time investments, while inference (daily token volumes) represents long-term capital expenditures. Groq's approach lowers long-term cost curves, making large-scale commercial LLM services more sustainable. For NVIDIA, acquiring Groq adds a lever for optimizing long-term inference costs beyond "selling training cards once." Simply put, NVIDIA can now offer more competitive inference solutions in TCO and energy efficiency, not just by stacking more GPUs.
03
Cerebras's Risks
From a product perspective, Cerebras's choice to fabricate an entire 300mm wafer as a single chip means any defect can render it unusable, exposing the company to extreme manufacturing yield risks. Traditional GPUs can mitigate this by "cutting and discarding defective areas" across smaller chips.
Commercially, Cerebras must navigate customer concentration risks.
While Cerebras claims many head ( head means "top-tier") clients use its products—such as Notion integrating Cerebras as the underlying inference engine for real-time enterprise search (serving millions of enterprise users) and Cerebras becoming the fastest inference provider for OpenAI's latest safety model, enabling real-time AI security policy judgments (e.g., content moderation, document classification, agent safeguards)—revenue data reveals that G42 (UAE) accounted for 87% of H1 2024 revenue under a $1.43 billion contract. Despite new contracts, geopolitical shifts affecting G42 (e.g., tighter U.S. AI chip export controls to the UAE) could severely impact revenue. Although G42 was removed from Cerebras's investor list, it remains the largest single customer.
Delivery pressures loom large. Despite securing major orders, Cerebras may struggle to meet manufacturing demands. With OpenAI's 750MW deployment and AWS partnership ramping up, Cerebras faces immense capacity expansion pressure from 2026–2028. The company has allocated significant Series H funding to expand U.S.-based manufacturing, but delivery timelines remain the biggest execution uncertainty.
04
Final Thoughts
Cerebras isn't the only company attempting to breach NVIDIA's compute fortress. SambaNova, another "non-GPU AI chip" contender, also aims to solve GPU memory wall issues but with a starkly different approach. SambaNova's core innovation lies in its reconfigurable dataflow architecture (RDU) paired with a three-tier memory system, achieving near-monolithic-chip efficiency on standard chips.
The three-tier memory includes SRAM (on-chip, ultra-fast, small capacity), HBM (high-bandwidth, medium-speed, large capacity), and DDR (low-speed, ultra-large capacity). This setup allows SambaNova systems to handle models far exceeding on-chip SRAM capacity (3TB per rack) while reducing kernel invocation counts via "operator fusion," sharply cutting latency. Benchmarks show SambaNova SN40L achieving 9x faster speeds at low batch sizes and 4x faster at high batch sizes versus NVIDIA H200 on Llama 3.3 70B, with 5.6–2.5x better energy efficiency.
SambaNova's low power consumption is its core selling point for power-constrained data centers. Despite a $5 billion valuation after its 2021 Series D led by SoftBank Vision Fund 2, reports emerged in 2025 of SambaNova seeking buyers. Intel once proposed a $1.6 billion acquisition, but negotiations failed.
While Cerebras and SambaNova started on equal footing, capital sentiment now diverges: Cerebras commands a $20+ billion valuation, while SambaNova searches for new financiers.
NVIDIA's fortress persists. As an AI startup CTO aptly summarized after benchmarking all three: "We tested both SambaNova and Cerebras. Both outpace NVIDIA in inference speed. But our entire codebase is CUDA-based, our engineers know CUDA, and our cloud budgets include negotiated NVIDIA discounts. Switching means rewriting code, retraining staff, and renegotiating contracts—for ~30% better performance, that's not cost-effective."
In a winner-takes-all market, being 10% better isn't enough—you need to be 10x better, with a clear path to market adoption.
-
![]()
Tariffs Can't Stop Chinese Cars—EU Starts Rewriting the Rules: From Anti-Subsidy Duties to 'Made in Europe' and Beyond
-
![]()
May Auto Sales Insight: Joint Ventures Falter, New Entrants Rise, with Exports Lending Support?
-
![]()
Model Substitution, Data Vending, and Remote-Control Backdoors! Ministry of State Security Alerts to Risks in 'AI Relay Platforms'
-
![]()
Zhao Ming Departs, IPO Postponed, AI Phones Underperform—Can Honor Still Live Up to Its Name?
-
![]()
Explosion of Recording Hardware! Four Major Product Categories Compete for New AI Entry Points, with Agent Capabilities Becoming Standard
-
![]()
China’s LEO Satellite Internet Achieves Strategic Progress: Over 100 Additional Satellites Set for Launch
-
![]()
Musk Sustains $88 Billion Loss in AI Pursuit, Now Rents GPUs to Rivals, Anticipating $500 Billion Revenue Over Three Years
-
![]()
Report | Token Economics: Envisioning a New Path for RMB Internationalization